






Background:
There are three library types for Tophat: fr-unstranded, fr-firststrand and fr-secondstrand. The description for these three from Tophat' documentation is list below:
| Library Type | Examples | Description |
| fr-unstranded | Standard Illumina | Reads from the left-most end of the fragment (in transcript coordinates) map to the transcript strand, and the right-most end maps to the opposite strand. |
| fr-firststrand | dUTP, NSR, NNSR | Same as above except we enforce the rule that the right-most end of the fragment (in transcript coordinates) is the first sequenced (or only sequenced for single-end reads). Equivalently, it is assumed that only the strand generated during first strand synthesis is sequenced. |
| fr-secondstrand | Ligation, Standard SOLiD | Same as above except we enforce the rule that the left-most end of the fragment (in transcript coordinates) is the first sequenced (or only sequenced for single-end reads). Equivalently, it is assumed that only the strand generated during second strand synthesis is sequenced. |
Based on my understanding,
(1) fr-unstranded is for non-strand-specific reads, and the other for strand-specific ones;
(2) fr-firststrand: for paired-end reads, the right-end of the pair is firstly sequenced (in the first round of PCR), followed by the left-end (in the second round of PCR), in other words, the first read of the fragment contains the sequence of the antisense strand and sit in the 3' end of the fragment and the second read is of the sense strand and 5' end; for single-end reads, the reads is the sequence of the sense strand (positive);
(3) fr-secondstrand: for paired-end reads, the left-end of the pair is firstly sequenced (in the first round of PCR), followed by the right-end (in the second round of PCR), in other words, the first read of the fragment contains the sequence of the sense strand and sit in the 3' end of the fragment and the second read is of the antisense strand; for single-end reads, the reads is the sequence of the antisense strand (negative);
Following graph shows the difference of the paired-end reads in these three types:
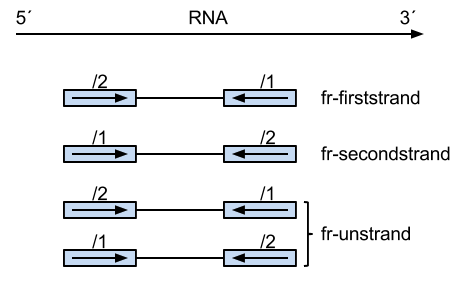 ps: "/1" means the read we get first from the fragment, and the read id, such as "seq***_1", has the same meaning.
ps: "/1" means the read we get first from the fragment, and the read id, such as "seq***_1", has the same meaning.
How to tell the library type from our law data?
Approach 1: map our reads (preprocessed read is prefered, in other words, the adapters have been removed) to the genome using UCSC genome browser with BLAT or using IGV, and tell whether the reads mapped to sense strand or antisense strand. More details can be found in: http://onetipperday.blogspot.sg/2012/07/how-to-tell-which-library-type-to-use.html,
Approach 2: map these reads with tophat using fr-firststrand and fr-second-strand respectively, and look at the file called "junctions.bed". Choose the parameter with more junctions found. More details can be found in: http://ccb.jhu.edu/software/tophat/faq.shtml#library_type















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









