







当前市场上有许多智能对话助手,包括ChatGPT、Bing AI Chat等。但无一例外的是,这些产品,都需要您连接互联网。
在边缘设备上部署类似模型,以实现无需联网、低延迟的智能对话助手,这一需求尚未得到充分满足。
最近,正在 Jetson 上探索相关应用,期待在离线和低延迟方面取得一些突破,欢迎感兴趣的朋友一起交流。
昨天把本地大模型部署好了,并实现了 GPU 加速推理:
接下来,妙不可言的部分来了。
语音识别-ASR和语音合成-TTS,也要在边缘设备上完成,一个完全懂你的小助手,应将你的个人隐私牢牢守护。
本次分享,就给大家盘点:几款亲测好用的,ASR和TTS离线部署方案。
1. 离线语音识别ASR
1.1 faster-whisper
Whisper 相信大家都不陌生,由 OpenAI 开发,已经更新到 v3。
faster-whisper 则是用 CTranslate2 重新实现 Whisper,加速比达到4倍,需要的内存更少。
为了实现 Jetson GPU 加速推理,首先尝试了 Jetson Containers 提供的镜像,不过构建失败。
参考:https://github.com/dusty-nv/jetson-containers/tree/master/packages/speech/faster-whisper
无奈之下,找到了 faster-whisper-server 这个项目,服务端提供 OpenAI 兼容的 API。
尽管 docker 镜像提供 GPU 支持,但在 Jetson 中用不了,只能选择 CPU 方式部署:
docker run -d -p 3003:8000 --volume whisper:/root/.cache/huggingface --restart unless-stopped --name whisper fedirz/faster-whisper-server:latest-cpu
然后,下载模型权重,并上传到 docker 容器中:
sudo apt-get install git-lfs
git clone https://hf-mirror.com/Systran/faster-whisper-small
docker cp faster-whisper-small/ whisper:/root/.cache/huggingface/
git clone https://hf-mirror.com/Systran/faster-whisper-tiny
docker cp faster-whisper-tiny/ whisper:/root/.cache/huggingface/
倒是可以跑起来,但 small 模型推理太慢,而 tiny 模型,中文识别又太拉跨,最终只能放弃。
1.2 VOSK
支持 pip 一键安装:
pip install vosk
也可以选择服务端部署:https://alphacephei.com/vosk/server
docker run -d -p 2700:2700 --name vosk alphacep/kaldi-cn:latest
模型列表:https://alphacephei.com/vosk/models
其中支持中文的模型如下:
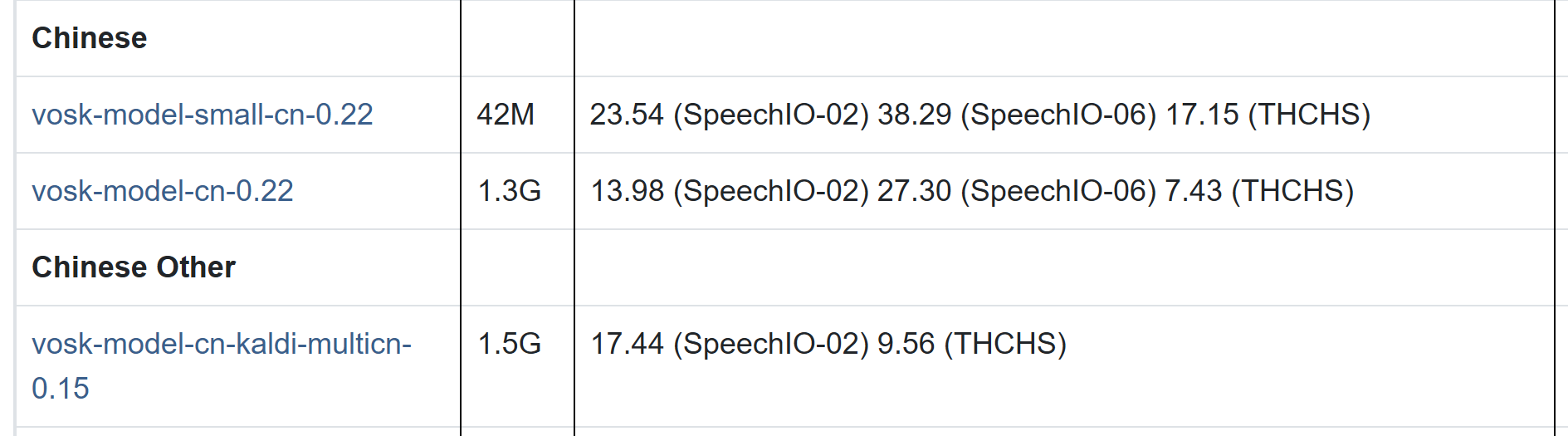
小模型大概需要 300M 内存,而大模型最多需要 16G 内存。测试了小模型,给大家看下效果:
如果 是 关于 生活 或者 娱乐 方面 请 随时 高质 我 会 经历 提供 上官 的 建议 和 信息
没法用啊!
1.3 sherpa-onnx
Sherpa 是一个使用 PyTorch 的开源语音推理框架,专注于端到端模型,包括 Transducer 和 CTC。
而 Sherpa-onnx 的推理后端则是基于 ONNX。
ONNX 可是个大宝贝,它为 PyTorch、TensorFlow、Paddle 等各种深度学习框架下训练的模型提供了统一入口。
Sherpa-onnx 提供了 GPU 支持,但只支持Linux/Windows x64。
Jetson 是 Armv8,显然用不了。
怎么安装使用?
# 推荐 pip 一键安装
pip install sherpa-onnx
然后,前往https://github.com/k2-fsa/sherpa-onnx/releases/tag/asr-models下载模型。
官方上线了最新的 sensevoice 模型,中文识别效果非常棒,推理速度也 OK,推荐使用:
curl -SL -O https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17.tar.bz2
拿到模型后,在项目目录sherpa-onnx/python-api-examples/中提供了示例代码。
这里可以封装成类,方便调用:
class LocalSpeech:
def __init__(self, device_index=0):
model_dir = "/home/jetson/projects/voiceapi/models/sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17"
self.recognizer = sherpa_onnx.OfflineRecognizer.from_sense_voice(
model=f'{model_dir}/model.int8.onnx',
tokens=f'{model_dir}/tokens.txt',
use_itn=True)
def asr_sensevoice(self, filename='data/audios/tts.wav'):
audio, sample_rate = read_wave(filename)
stream = self.recognizer.create_stream()
stream.accept_waveform(sample_rate, audio)
self.recognizer.decode_stream(stream)
return stream.result.text.strip()
我这里测试了推理耗时,供大家参考:
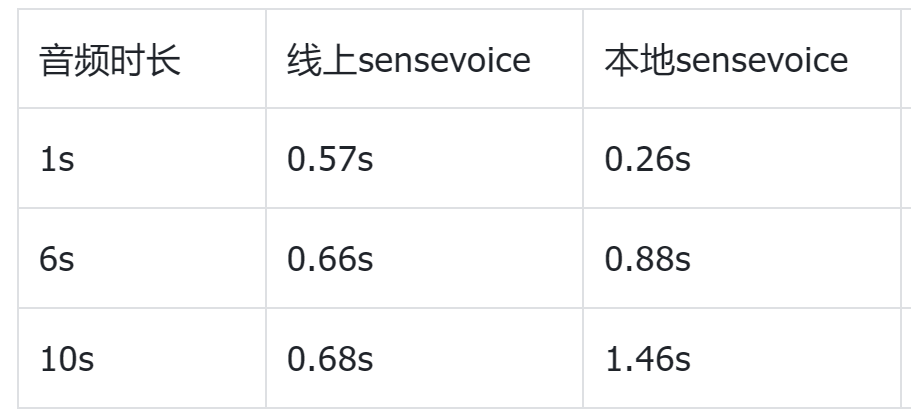
其中,线上版是在服务端部署的 sensevoice 模型,GPU 推理;本地sensevoice 就是上述代码中用的本地 onnx 模型,CPU 推理。
因为正常语音对话的音频时长不超过 5s,因此本地推理的耗时,完全可以接受。
2. 离线语音合成TTS
2.1 Piper
Piper 是一个快速、本地的文本转语音系统,专为树莓派4优化。已广泛用于各种需要语音合成的项目中。
听起来就很棒!
而且,安装使用也非常方便:
pip install piper-tts
或者从项目主页直接下载对应架构下已经编译好的安装包,解压即用:
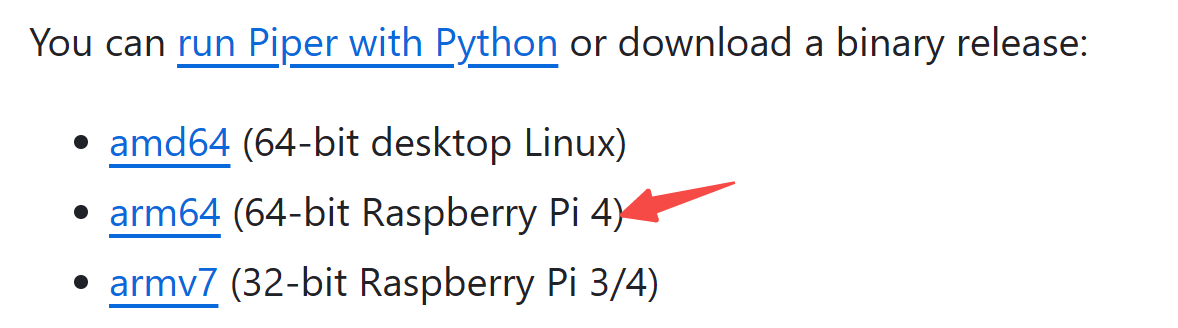
然后,从https://github.com/rhasspy/piper/blob/master/VOICES.md找到对应的音色,每个音色包括 .onnx 和 .onnx.json 两个文件。
遗憾的是中文音色只有两个:

测试了看看吧:
echo '你好,你是哪位啊' | ./piper --model zh_CN-huayan-medium.onnx --output_file 1.wav
2.2 sherpa-onnx
sherpa-onnx 也提供了 TTS 方案。
https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models提供了所有模型列表。
不过这些模型的推理延迟差异很大,其中 vits-icefall-zh-aishell3 最快。
我这里也测试了不同方案的推理耗时,供大家参考:
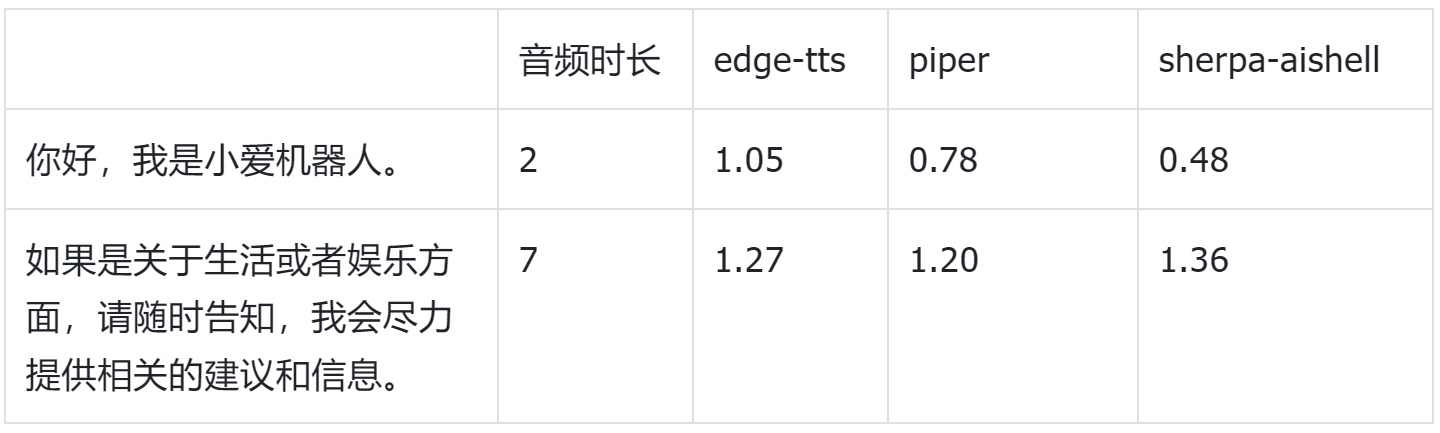
其中,edge-tts 是线上方案。
不过,piper 和 sherpa-onnx 的音质远不如 edge-tts,尤其是表现在机械、没有情感。
其实,有情感的 TTS,在 chattts 和 cosyvoice 等开源方案中都已实现,只是无法在 jetson 上部署,因为二者还不支持 arm 架构。
3. 流式 ASR + TTS
参考:https://github.com/ruzhila/voiceapi
voiceapi 基于 sherpa-onnx,提供了一个简单的语音识别/合成API,支持流式数据。
写在最后
本文为离线低延迟的语音解决方案,提供了几种思路。
其中,有情感的 TTS 本地部署,还有待进一步探索,欢迎感兴趣的朋友一起交流。
如果对你有帮助,欢迎点赞收藏备用。
为方便大家交流,新建了一个 AI 交流群,欢迎对AIoT、AI工具、AI自媒体等感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









