









贝叶斯推断方法 —— 从经验知识到推断未知
机器学习基础算法python代码实现可参考: zlxy9892/ml_code
1 什么是贝叶斯
在机器学习领域,通常将监督学习 (supervised learning) 划分为两大类方法:生成模型 (generative model) 与判别模型 (discriminative model),贝叶斯方法正是生成模型的代表 (还有隐马尔科夫模型)。在概率论与统计学中,贝叶斯定理 (Bayes' theorem) 或称为贝叶斯法则 (Bayes' law or Bayes' rule) 表达了一个事件发生的概率,而确定这一概率的方法是基于与该事件相关的条件先验知识 (prior knowledge)。例如,如果患癌症是与人的年龄相关的,那么使用贝叶斯方法,我们可以利用患癌症人群的年龄分布这个先验知识评判一个人患癌症的概率,这相比于不利用年龄信息去判断一个人是否患癌症会聪明得多。可见,上述过程是贝叶斯定理的一种实际应用,通常我们称之为:贝叶斯推断 (Bayesian inference)。
2 贝叶斯定理
开始谈贝叶斯定理之前,必须首先从条件概率 (conditional probability) 说起。所谓条件概率,就是在一个事件发生的情况下,去判断另一个相关联的事件发生的概率,或者简单说,就是指在事件 B 发生的情况下,事件 A 发生的概率。通常记为 ![]() 。接下来对贝叶斯公式做一个简单的推导,根据概率知识,我们可以求得
。接下来对贝叶斯公式做一个简单的推导,根据概率知识,我们可以求得 ![]() 为:
为:

同样的,有些统计学家更倾向于将其作为一个概率公理 (as an axiom of probability),记为:

因此,可以得到:

由此,推导出了大名鼎鼎的贝叶斯公式:

这也是条件概率的计算公式。
3 一个小例子 (狗与盗窃)
住在一座别墅里的一家人,在过去的 20 年中,发生了 2 次盗窃,这家人养了一只狗,这只狗平均每周晚上叫 3 次,而且,当发生盗窃时,这只狗会叫的概率是 0.9,那么问题是:在这只狗叫的情况下,发生盗窃的概率是多少?
我们假设 A 事件是狗晚上叫,则 ![]() ,
,
假设 B 事件是发生盗窃,则  ,
,
我们还知道,当 B 事件发生的条件下,A 事件发生的概率  。因此,根据贝叶斯公式,我们推断得到,狗叫时,发生盗窃的概率,即
。因此,根据贝叶斯公式,我们推断得到,狗叫时,发生盗窃的概率,即 :

4 朴素贝叶斯法解决分类问题
根据上述的基本介绍与例子的引入,对贝叶斯定理有了初步的认识。那么接下来的重点就在于,如何根据这一定理,去解决机器学习中的分类问题。
4.1 基本方法
与所有机器学习问题的基本框架一样,假设我们有输入的特征向量 ![]() ,输出的类别标记 (class label)
,输出的类别标记 (class label) ![]() 。
。
![]() 分别为输入空间
分别为输入空间 上的随机变量,
是
和
的联合概率分布。训练数据集为:

由![]() 独立同分布产生。
独立同分布产生。
朴素贝叶斯方法通过训练数据集学习这个联合概率分布![]() 。具体而言,它需要学习两个部分,第一是先验概率分布:
。具体而言,它需要学习两个部分,第一是先验概率分布:
第二是条件概率分布:

(注意:这里 ![]() 的上标
的上标 ![]() 是表示输入的维度,总共有
是表示输入的维度,总共有 维)。
这里,对于条件概率 ![]() 来说,由于它涉及关于
来说,由于它涉及关于 ![]() 所有属性的联合概率,有指数级数量的参数,直接根据样本出现的频率来估计将会遇到严重的困难。例如,假设样本包含 d 个属性且都是二值的,则样本空间将有
所有属性的联合概率,有指数级数量的参数,直接根据样本出现的频率来估计将会遇到严重的困难。例如,假设样本包含 d 个属性且都是二值的,则样本空间将有 种可能的取值,在现实应用中,这个值往往远大于训练样本数量,也就是说,很多样本取值在训练集中根本没有出现,直接使用频率来估计
显然不可行,因为 “未被观测到” 与 “出现概率为零” 通常是不同的。
为了避开上述障碍,朴素贝叶斯法 (naive Bayes) 采用了 “属性条件独立性假设”,对已知的类别,假设所有属性相互独立,换言之,假设每个属性独立地对分类结果发生影响。由此,条件概率可以重写为:

可以看出,这一假设使朴素贝叶斯法变得很简单,但同时也会牺牲一定的分类准确率。
再回到贝叶斯定理,我们的目标是给定一个 ![]() ,推断其后验概率分布
,推断其后验概率分布 ![]() ,即该条数据属于每个类的概率是多少,然后选择概率最大的类别作为
,即该条数据属于每个类的概率是多少,然后选择概率最大的类别作为 的类输出。那么将贝叶斯定理结合属性条件独立性假设,可以得到:

由于对所有类别来说![]() 相同,因此贝叶斯判定准则可写为:
相同,因此贝叶斯判定准则可写为:

这就是朴素贝叶斯分类器的表达式。
4.2 朴素贝叶斯法的参数估计
实际在机器学习的分类问题的应用中,朴素贝叶斯分类器的训练过程就是基于训练集![]() 来估计类先验概率
来估计类先验概率 ![]() ,并为每个属性估计条件概率
,并为每个属性估计条件概率 。这里就需要使用极大似然估计 (maximum likelihood estimation, 简称 MLE) 来估计相应的概率。
令 ![]() 表示训练集
表示训练集 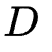 中的第
中的第 类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类别的先验概率:
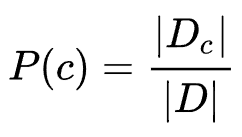
对于离散属性而言,令 ![]() 表示
表示 ![]() 中在第
中在第 个属性上取值为
的样本组成的集合,则条件概率
可估计为:

对于连续属性可考虑概率密度函数,假定 ![]() ,其中
,其中 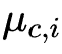 和
和 分别是第
类样本在第
个属性上取值的均值和方差,则有:

4.3 算法流程
好了,上述理论化比较严重,现在我们开始梳理一下用贝叶斯方法进行机器学习分类任务的整体流程,我归纳为如下的示意图:
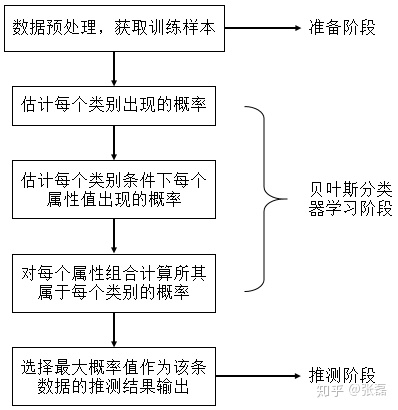
贝叶斯方法流程
4.4 拉普拉斯平滑
在直接使用极大似然估计法时,需要注意,若某个属性值在训练集中没有与某个类同时出现,则直接基于之前的公式进行概率估计,再进行判别将出现问题。例如,当我们判断一个人是否感冒,给出的属性包含:年龄={少年,中年,老年};是否头痛={是,否},如果当前我们的训练集中没有包含少年人群的数据,此时,如果来了一个新的数据是少年且头痛,那么:
![]() ,
,
上式等于 0 的原因就是我们的训练数据集中没有年龄 = 少年的数据,然而,经验告诉我们,少年且头痛也是很有可能感冒的,这显然不太合理。
为了避免其他属性携带的信息被训练集中未出现的属性值 “抹去”,在估计概率值时通常需要进行 “平滑” (smoothing),我们常用 “拉普拉斯修正” (Laplacian correction)。具体来说,令 ![]() 表示训练集
表示训练集 ![]() 中可能的类别数 (例如上述示例中类别包含感冒和不感冒,则
中可能的类别数 (例如上述示例中类别包含感冒和不感冒,则 ),
表示第
个属性可能的取值数,则类别先验概率和条件概率分别修正为:

这样,我们举的例子中,

而此时,对于任何输入数据,推测的概率值永远会大于 0。显然,拉普拉斯修正避免了因训练集不充分而导致概率估值为零的问题,并且在训练集变大时,修正过程所引入的先验 (prior) 的影响也会逐渐变得可忽略,使得估计值逐渐趋向于实际概率值。
4.5 实际的应用方式
在现实任务中朴素贝叶斯分类器有多种使用方式。例如:
- 若任务对预测速度要求较高,则对给定的训练集,可将朴素贝叶斯分类器涉及的所有概率估值事先计算好存储起来,这样在进行预测时只需要 “查表” 即可进行判别;
- 若任务数据更替频繁,则可采用 “懒惰学习” (lazy learning) 方式,先不进行任何训练,待收到预测请求时再根据当前数据集进行概率估值;
- 若数据不断增加,则可在现有估值的基础上,仅对新增样本的属性值所涉及的概率估值进行计数修正即可实现增量学习。
5 参考文献与相关资料
- Mitchell TM. Chapter3: Generative and discriminative classifiers: Naive bayes and logistic regression
- 书籍:Hastie T et al. 2001 The Elements of statistical learning. Data mining, Inference, and Prediction. 中译本:[统计学习基础 数据挖掘 推理与预测]
- wiki 上关于统计学习理论框架的介绍 https://en.wikipedia.org/wiki/Statistical_learning_theory
- 关于 Bayes 定理叙述地比较好的博客 [阮一峰的网络日志]
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











