










本文主要整理和参考了李宏毅的强化学习系列课程和莫烦python的强化学习教程
本系列主要分几个部分进行介绍
- 强化学习背景介绍
- SARSA算法原理和Agent实现
- Q-learning算法原理和Agent实现
- DQN算法原理和Agent实现(tensorflow)
- Double-DQN、Dueling DQN算法原理和Agent实现(tensorflow)
- Policy Gradients算法原理和Agent实现(tensorflow)
- Actor-Critic、A2C、A3C算法原理和Agent实现(tensorflow)
一、什么是强化学习(Reinforcement Learning, RL)
1.1强化学习背景
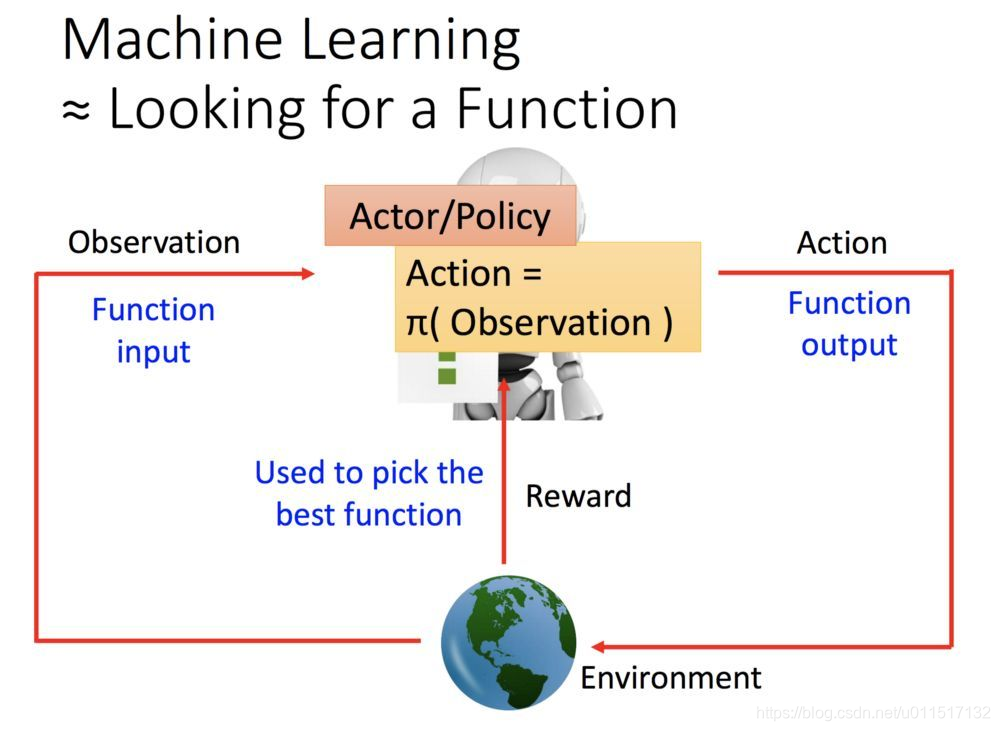
强化学习(RL)由两个部分组成,一个是环境environment,一个是代理agent。其中环境就是学习者所处的环境,agent可以理解为处在环境中的学习方法。agent会观察当前的environment得到当前环境的state(observation),并进一步选择需要执行的动作action,由于执行action,environment会发生改变,并且给agent一个奖励reward。这就是environment和agent的交互作用。
可以知道environment是实现就给定的,agent的作用是根据给定的environment即state(observation)选定要执行的动作。强化学习的主要功能就是让agent学习尽可能好的动作action,使其后续获得的奖励尽可能的大。(注意是后续一系列奖励,而不是执行动作后的局部奖励)

RL让agent学习尽可能好的ction就是寻找一个函数
a
=
π
(
s
)
a=π(s)
a=π(s)使的
a
a
a的总奖励最大:
2.1强化学习分类
根据不同的分列方法可以将强化学习算法分成不同的种类:
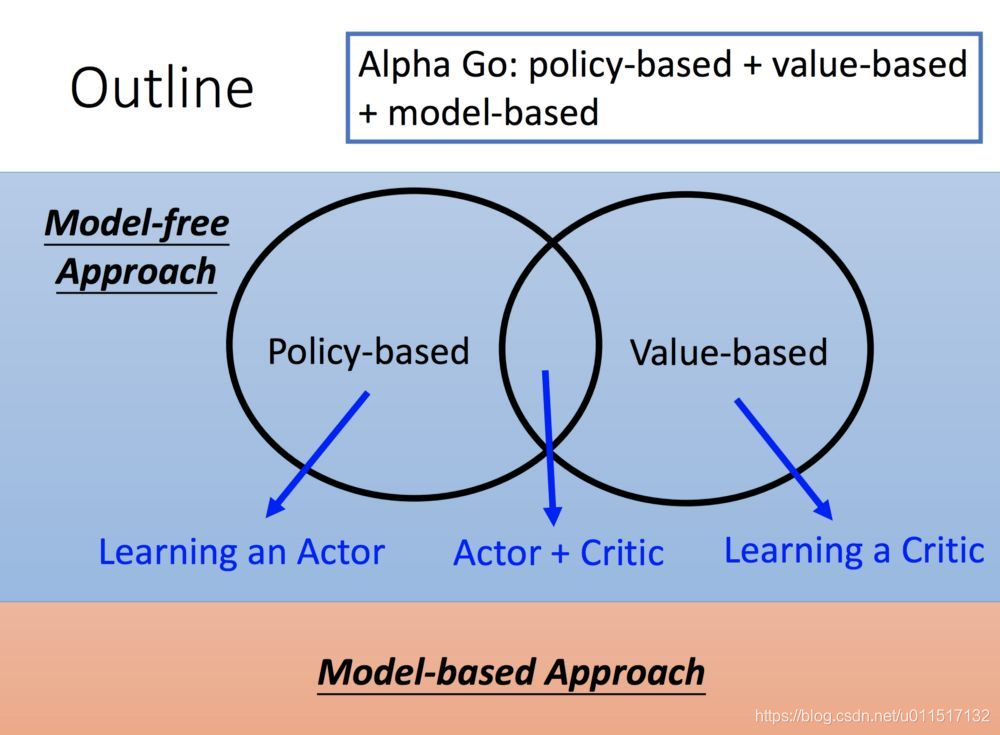
1.基于概率(policy-based)和基于价值(value-based)
基于概率是强化学习中最直接的一种, 他能通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同. 而基于价值的方法输出则是所有动作的价值, 我们会根据最高价值来选着动作, 相比基于概率的方法, 基于价值的决策部分更为铁定, 毫不留情, 就选价值最高的, 而基于概率的, 即使某个动作的概率最高, 但是还是不一定会选到他.(来自莫烦python)
policy-based是根据动作的概率
π
(
)
:
S
−
>
A
π():S->A
π():S−>A选择动作
value-based是根据动作的价值选择动作,其中状态s下,动作a的价值可表示为
Q
(
s
,
a
)
Q(s,a)
Q(s,a)

其中policy-based中的典型算法有Policy Gradients,value-based的典型算法有Q-learning、SARSA、DQN,两者重合的典型模型有AC、A2C、A3C
2.在线学习(on-policy)和离线学习(off-policy)
所谓在线学习(on-policy), 就是指我必须本人在场, 并且一定是本人边玩边学习, 学习者与环境必须产生实际的交互。而离线学习(off-policy)是你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则。
on-policy的典型算法是SARSA, off-policy的典型算法是Q-learning、DQN。
on-policy是的学习者必学进行完一系列实际动作后才能产生样本,这样效率往往较慢。off-policy可以从以往的经验或别人的动作开学习,效率往往比较高。

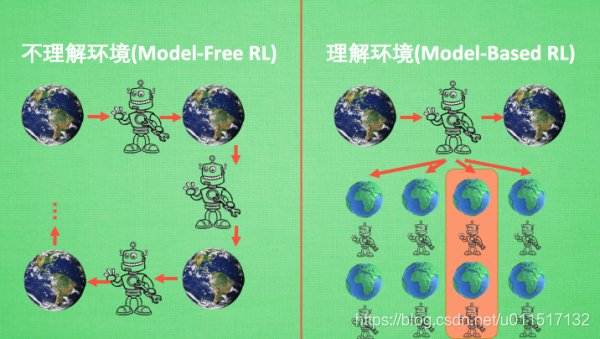
3.model-based和model-free
可以将所有强化学习的方法分为理不理解所处环境,如果我们不尝试去理解环境, 环境给了我们什么就是什么. 我们就把这种方法叫做 model-free, 这里的 model 就是用模型来表示环境, 那理解了环境也就是学会了用一个模型来代表环境, 所以这种就是 model-based 方法.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









