







6.1 估计模型
估计:当信号肯定存在时根据测量值和某种准则确定信号的数量特征的过程称为估计

参量估计:
- 最大似然估计
- 最大后验概率估计
- 贝叶斯估计
- 最小二乘估计
- 线性最小均方误差估计
- 线性递推估计
波形估计
- 线性最小均方误差估计
- 维纳滤波器
- 卡尔曼滤波器
6.2 最大似然估计(ML)
观测样本: x i = θ + n i x_i=\theta +n_i xi=θ+ni其中 θ \theta θ为被估参量
似然函数:N次观测后, θ \theta θ出现时,x的条件密度函数
最大似然方程: ∂ f ( X / θ ) ∂ θ = 0 θ = θ ∗ = θ ^ M L \frac{\partial f(X / \theta)}{\partial \theta}=0\,\,\theta=\theta^{*}=\hat{\theta}_{M L} ∂θ∂f(X/θ)=0θ=θ∗=θ^ML
- 没有利用先验知识,性能比贝叶斯估计差
- 适用与 θ \theta θ为未知非随机参量、为随机参量但先验概率未知、为计算后验概率难于计算似然函数
- 当观察数据足够多时,性能最优
6.3 最大后验概率估计(MAP)
观测样本: x i = θ + n i x_i=\theta +n_i xi=θ+ni
单样本后验概率: P ( θ / x i ) P(\theta / x_i) P(θ/xi)
样本矢量后验概率:N次观测后: P ( θ / X ) = P ( θ ) f ( X / θ ) f ( X ) P(\theta / X)=\frac{P(\theta) f(X / \theta)}{f(X)} P(θ/X)=f(X)P(θ)f(X/θ)
最大后验估计方程: ∂ P ( θ / X ) ∂ θ = 0 θ = θ ∗ = θ ^ M A P \frac{\partial P(\theta / X)}{\partial \theta}=0\,\theta=\theta^{*}=\hat{\theta}_{M A P} ∂θ∂P(θ/X)=0θ=θ∗=θ^MAP
- 先验概率 P ( θ ) P(\theta) P(θ)为均匀分布时,MAP等价于ML
6.4 贝叶斯估计
估计误差: θ ~ = θ − θ ^ ( X ) \widetilde{\theta}=\theta-\hat{\theta}(X) θ =θ−θ^(X)真实值-估计值(多次估计)
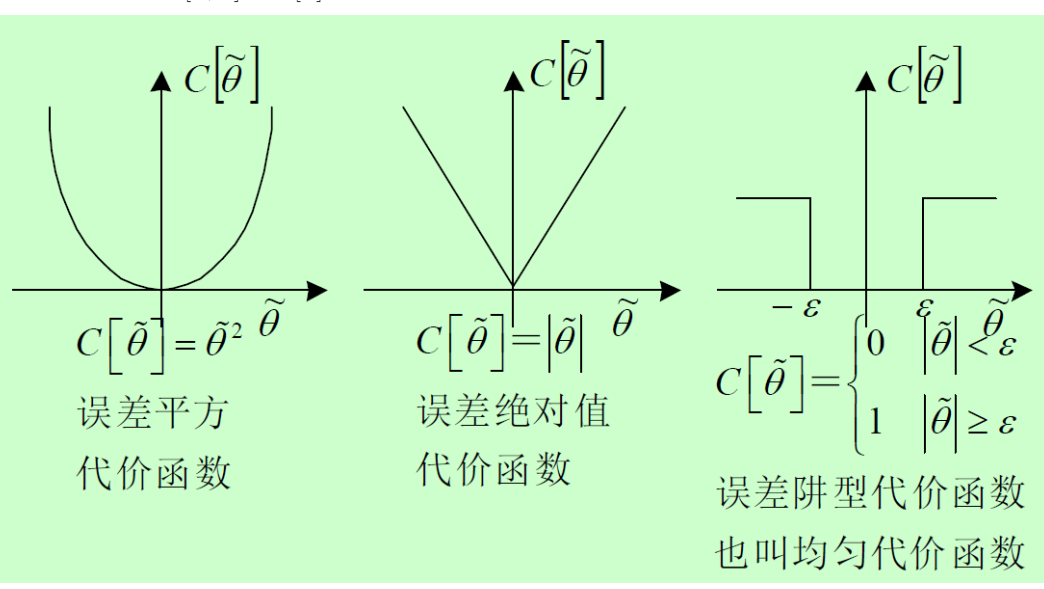
损失代价函数: C [ θ , θ ^ ] 或 C [ θ ~ ] ≥ 0 C[\theta,\hat \theta]或C[\widetilde{\theta}]\ge0 C[θ,θ^]或C[θ ]≥0
观测与估计的联合密度函数:
f ( X , θ ˉ ) = f ( X / θ ˉ ) 似然函数 p ( θ ˉ ) 先验概率 = f ( θ ˉ / X ) 后验概率 f ( X ) f(X, \bar{\theta})={f(X / \bar{\theta})}{\text {似然函数 }} {p(\bar{\theta})}{\text {先验概率}}={f(\bar{\theta} / X)}{\text {后验概率 }}f(X) f(X,θˉ)=f(X/θˉ)似然函数 p(θˉ)先验概率=f(θˉ/X)后验概率 f(X)
条件风险: R ( θ ˉ ‾ / X ) = ∫ C ( θ ˉ , θ ˉ ‾ ) f ( θ ˉ / X ) d θ ˉ R(\overline{\bar{\theta}} / X)=\int C(\bar{\theta}, \overline{\bar{\theta}}) f(\bar{\theta} / X) d \bar{\theta} R(θˉ/X)=∫C(θˉ,θˉ)f(θˉ/X)dθˉ,观测后多次x的风险,代价*后验积分
平均风险: R ( θ ˉ ‾ ) = E [ R ( θ ˉ / X ) ] = ∬ C [ θ ˉ , θ ˉ ] f ( X , θ ˉ ) d θ ˉ d X R(\overline{\bar{\theta}})=E[R(\bar{\theta} / X)]=\iint C[\bar{\theta}, \bar{\theta}] f(X, \bar{\theta}) d \bar{\theta} d X R(θˉ)=E[R(θˉ/X)]=∬C[θˉ,θˉ]f(X,θˉ)dθˉdX对所有多次观测求平均
贝叶斯估计:平均风险最小 ∂ ∂ θ ˉ ^ R ( θ ˉ ‾ / X ) = 0 \frac{\partial}{\partial \hat{\bar{\theta}}} R(\overline{\bar{\theta}} / X)=0 ∂θˉ^∂R(θˉ/X)=0
min R ( θ ˉ ‾ ) = min R ( θ ˉ ‾ / X ) \min R(\overline{\bar{\theta}})=\min R(\overline{\bar{\theta}}/X) minR(θˉ)=minR(θˉ/X)对于给定X,风险与条件风险相同
平方误差代价函数下的贝叶斯估计
条件风险: R ( θ ^ / X ) = ∫ − ∞ ∞ ( θ − θ ^ ) 2 f ( θ / X ) d θ R(\hat{\theta} / X)=\int_{-\infty}^{\infty}(\theta-\hat{\theta})^{2} f(\theta / X) d \theta R(θ^/X)=∫−∞∞(θ−θ^)2f(θ/X)dθ
对估计量求导: 2 θ ^ ∫ − ∞ ∞ f ( θ / X ) d θ − 2 ∫ − ∞ ∞ θ f ( θ / X ) d θ = 0 2 \hat{\theta} \int_{-\infty}^{\infty} f(\theta / X) d \theta-2 \int_{-\infty}^{\infty} \theta f(\theta / X) d \theta=0 2θ^∫−∞∞f(θ/X)dθ−2∫−∞∞θf(θ/X)dθ=0,其中第一项积分为1
解得贝叶斯估计量: θ ^ M S ( X ) = ∫ − ∞ ∞ θ f ( θ / X ) d θ = E [ θ / X ] \hat{\theta}_{M S}(X)=\int_{-\infty}^{\infty} \theta f(\theta / X) d \theta=E[\theta / X] θ^MS(X)=∫−∞∞θf(θ/X)dθ=E[θ/X]
- 贝叶斯估计量=给定X下 θ \theta θ的条件均值、后验均值
- 风险=均方误差
- 平方误差代价函数下的贝叶斯估计又称最小均方误差估计
绝对误差代价函数下的贝叶斯估计
条件风险: R ( θ ^ / X ) = ∫ − ∞ ∞ ∣ θ − θ ^ ∣ f ( θ / X ) d θ R(\hat{\theta} / X)=\int_{-\infty}^{\infty}|\theta-\hat{\theta}| f(\theta / X) d \theta R(θ^/X)=∫−∞∞∣θ−θ^∣f(θ/X)dθ
贝叶斯估计量:后验概率密度中值
- 绝对误差代价函数下的贝叶斯估计又称条件中值估计
阱型误差代价函数下的贝叶斯估计
条件风险: R ( θ ^ / X ) = ∫ − ∞ θ ^ − ε f ( θ / X ) d θ + ∫ θ ^ + ε ∞ f ( θ / X ) d θ R(\hat{\theta} / X)=\int_{-\infty}^{\hat{\theta}-\varepsilon} f(\theta / X) d \theta+\int_{\hat{\theta}+\varepsilon}^{\infty} f(\theta / X) d \theta R(θ^/X)=∫−∞θ^−εf(θ/X)dθ+∫θ^+ε∞f(θ/X)dθ
贝叶斯估计量:后验概率密度众数,即最大后验概率
- 阱型误差代价函数下的贝叶斯估计又称MAP估计
贝叶斯估计量的不变性
约束条件1:
- 代价函数y轴对称
- 代价函数下凸
- 后验概率密度对条件均值对称
约束条件2:
- 代价函数y轴对称
- 代价函数非减
- 后验概率密度对条件均值对称,且为单峰函数
以上两种条件下,最小均方误差、条件中值、MAP估计等价,为贝叶斯估计
估计量的无偏性
对于确知参量,保证估计均值相等即无偏
对于随机参量,保证估计均值与参量均值相等即无偏
E ( θ ^ N ) = θ , 对于非随机参量 E ( θ ^ N ) = E ( θ ) , 对于随机参量 \begin{aligned}&E\left(\hat{\theta}_{N}\right)=\theta, \quad \text { 对于非随机参量 } \\&E\left(\hat{\theta}_{N}\right)=E(\theta), \text { 对于随机参量 }\end{aligned} E(θ^N)=θ, 对于非随机参量 E(θ^N)=E(θ), 对于随机参量
均值的无偏无法保证实际每一次估计均为无偏
条件无偏估计:
非随机参量估计: E { θ ^ N } = ∫ θ ^ N ( X ) f ( X / θ ) d X = θ E\left\{\hat{\theta}_{N}\right\}=\int \hat{\theta}_{N}(X) f(X / \theta) d X=\theta E{θ^N}=∫θ^N(X)f(X/θ)dX=θ
估计*似然的积分为确知即无偏
随机参量估计: E { θ ^ N } = ∬ θ ^ N ( X ) f ( X , θ ) d X d θ = E ( θ ) E\left\{\hat{\theta}_{N}\right\}=\iint \hat{\theta}_{N}(X) f(X, \theta) d X d \theta=E(\theta) E{θ^N}=∬θ^N(X)f(X,θ)dXdθ=E(θ)
估计*似然的二重积分为实际均值即无偏
渐进无偏:
非随机: lim N → ∞ E { θ ^ N } = θ \lim _{N \rightarrow \infty} E\left\{\hat{\theta}_{N}\right\}=\theta limN→∞E{θ^N}=θ
随机: lim N → ∞ E { θ ^ N } = E ( θ ) \lim _{N \rightarrow \infty} E\left\{\hat{\theta}_{N}\right\}=E(\theta) limN→∞E{θ^N}=E(θ)
有偏估计:
非随机:估计偏差: E { θ ^ N } − θ = b N ( θ ) ≠ 0 E\left\{\hat{\theta}_{N}\right\}-\theta=b_{N}(\theta) \neq 0 E{θ^N}−θ=bN(θ)=0
随机:估计偏差: E { θ ^ N } − E ( θ ) = b N ( θ ) ≠ 0 E\left\{\hat{\theta}_{N}\right\}-E(\theta)=b_{N}(\theta) \neq 0 E{θ^N}−E(θ)=bN(θ)=0
估计一致性(N无穷,误差不可能大)
随观测次数增加,使得估计尽可能无偏(均方误差不断减小)
一致估计,数学表达为(其中 ε \varepsilon ε为任意小正数):
非随机: lim N → ∞ P { ∣ θ ^ N − θ ∣ > ε } = 0 \lim _{N \rightarrow \infty} P\left\{\left|\hat{\theta}_{N}-\theta\right|>\varepsilon\right\}=0 limN→∞P{∣∣∣θ^N−θ∣∣∣>ε}=0
随机: lim N → ∞ P { ∣ θ ^ N − E ( θ ) ∣ > ε } = 0 \lim _{N \rightarrow \infty} P\left\{\left|\hat{\theta}_{N}-E(\theta)\right|>\varepsilon\right\}=0 limN→∞P{∣∣∣θ^N−E(θ)∣∣∣>ε}=0
无条件一致估计: lim N → ∞ P { ∣ E ( θ ^ N ) − θ ∣ > ε } = 0 \lim _{N \rightarrow \infty} P\left\{\left|E\left(\hat{\theta}_{N}\right)-\theta\right|>\varepsilon\right\}=0 limN→∞P{∣∣∣E(θ^N)−θ∣∣∣>ε}=0
均方一致估计: lim N → ∞ E [ ( θ ^ N − θ ) 2 ] = 0 \lim _{N \rightarrow \infty} E\left[\left(\hat{\theta}_{N}-\theta\right)^{2}\right]=0 limN→∞E[(θ^N−θ)2]=0
估计有效性
相对概念,估计的均方误差越小,估计越有效,当估计满足克拉美-罗不等式的等号时,估计为最小均方误差估计
6.5 最小二乘估计
最小二乘估计不需要统计前提知识
观测式: x i = θ + n i x_{i}=\theta+n_{i} xi=θ+ni
估计量: θ \theta θ估计为 θ ^ \hat \theta θ^
!测量误差: θ ~ i = x i − θ ^ \tilde{\theta}_{i}=x_{i}-\hat{\theta} θ~i=xi−θ^
误差平方和: J ( θ ~ ) = ∑ i = 1 N θ ~ i 2 = ∑ i = 1 N ( x i − θ ^ ) 2 J(\widetilde{\theta})=\sum_{i=1}^{N} \widetilde{\theta}_{i}^{2}=\sum_{i=1}^{N}\left(x_{i}-\hat{\theta}\right)^{2} J(θ )=∑i=1Nθ i2=∑i=1N(xi−θ^)2
最小二乘估计就是要使得误差平方和最小,有 θ ^ L S = 1 N ∑ i = 1 N x i \hat{\theta}_{L S}=\frac{1}{N} \sum_{i=1}^{N} x_{i} θ^LS=N1∑i=1Nxi
高斯噪声下,最大似然估计等价于最小二乘估计
估计的比较:

6.6 正交原理与波形估计
正交原理:若 E [ θ ^ θ ~ ] = 0 E[\hat{\theta} \widetilde{\theta}]=0 E[θ^θ ]=0则称估计量 θ ^ \hat \theta θ^与估计误差 θ ~ \widetilde{\theta} θ 正交,正交原理相当于参量估计里解析法要求的偏导为0
波形估计:根据已知 x ( t ) x(t) x(t)
- 使用滤波器估计 s ( t ) s(t) s(t)
- 预测 s ( t + τ ) s(t+\tau) s(t+τ)
- 平滑 s ( t − τ ) s(t-\tau) s(t−τ)
波形的线性最小均方误差估计
估计量: y ^ ( t ) = L { x ( ξ ) : ξ ∈ I } , x ( ξ ) 的线性组合。 \hat{y}(t)=L\{x(\xi): \xi \in I\}, x(\xi) \text { 的线性组合。 } y^(t)=L{x(ξ):ξ∈I},x(ξ) 的线性组合。
估计误差: y ~ ( t ) = y ( t ) − y ^ ( t ) \widetilde{y}(t)=y(t)-\hat{y}(t) y (t)=y(t)−y^(t)
均方误差: E [ y ~ ( t ) 2 ] = E [ ( y ( t ) − y ^ ( t ) ) 2 ] E\left[\widetilde{y}(t)^{2}\right]=E\left[(y(t)-\hat{y}(t))^{2}\right] E[y (t)2]=E[(y(t)−y^(t))2]
最小均方误差条件: E [ y ~ ( t ) x ( ξ i ) ] = 0 E\left[\widetilde{y}(t) x\left(\xi_{i}\right)\right]=0 E[y (t)x(ξi)]=0 //测量和估计误差正交
相关性: R x y ( τ ) = E [ x ( t ) y ( t + τ ) ] R_{xy}(\tau)=E[x(t)y(t+\tau)] Rxy(τ)=E[x(t)y(t+τ)]
- 随着时间间隔增大,自相关降低,均方误差增大
- 估计性能取决于相关函数
- 对于高斯噪声这种无相关性的随机过程,无法估计
6.7 维纳滤波器
维纳滤波器基本思想:寻求线性滤波器最佳传递函数,使得输出波形为作为输入波形的估计时的均方误差达到最小
使得:
min
{
E
[
y
~
(
t
)
2
]
}
=
min
{
E
[
y
(
t
)
−
x
(
t
)
⊗
h
(
t
)
]
2
}
\min \left\{E\left[\tilde{y}(t)^{2}\right]\right\}=\min \left\{E[y(t)-x(t) \otimes h(t)]^{2}\right\}
min{E[y~(t)2]}=min{E[y(t)−x(t)⊗h(t)]2}
求 h ( t ) h(t) h(t)
同样使用正交原理,得到
当 R y x ( τ ) = ∫ t − b t − a R x x ( τ − λ ) h ( λ ) d λ R_{y x}(\tau)=\int_{t-b}^{t-a} R_{x x}(\tau-\lambda) h(\lambda) d \lambda Ryx(τ)=∫t−bt−aRxx(τ−λ)h(λ)dλ时,均方误差最小
积分上下限取0和正无穷时,称为维纳霍夫方程,系统传递函数在小于0时为0,为因果系统
分析非因果系统维纳滤波器可以帮助分析因果系统,非因果下易于计算
对于非因果系统:
H ( ω ) = S y x ( ω ) S x x ( ω ) = S s s ( ω ) S s s ( ω ) + S n n ( ω ) H(\omega)=\frac{S_{y x}(\omega)}{S_{x x}(\omega)}=\frac{S_{s s}(\omega)}{S_{s s}(\omega)+S_{n n}(\omega)} H(ω)=Sxx(ω)Syx(ω)=Sss(ω)+Snn(ω)Sss(ω)
噪声的自功率谱密度在小频段被滤波器放大,较大频段被滤波器抑制
6.8 卡尔曼滤波器
适用条件:离散线性滤波问题
优势:
- 数据存储量小
- 递推算法易于实现
- 可推广至非平稳随机过程
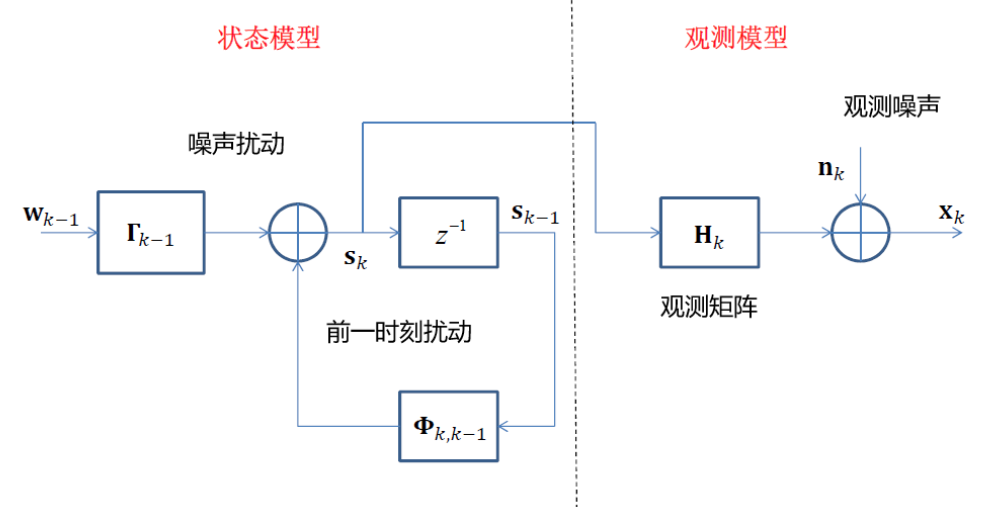
信号模型:
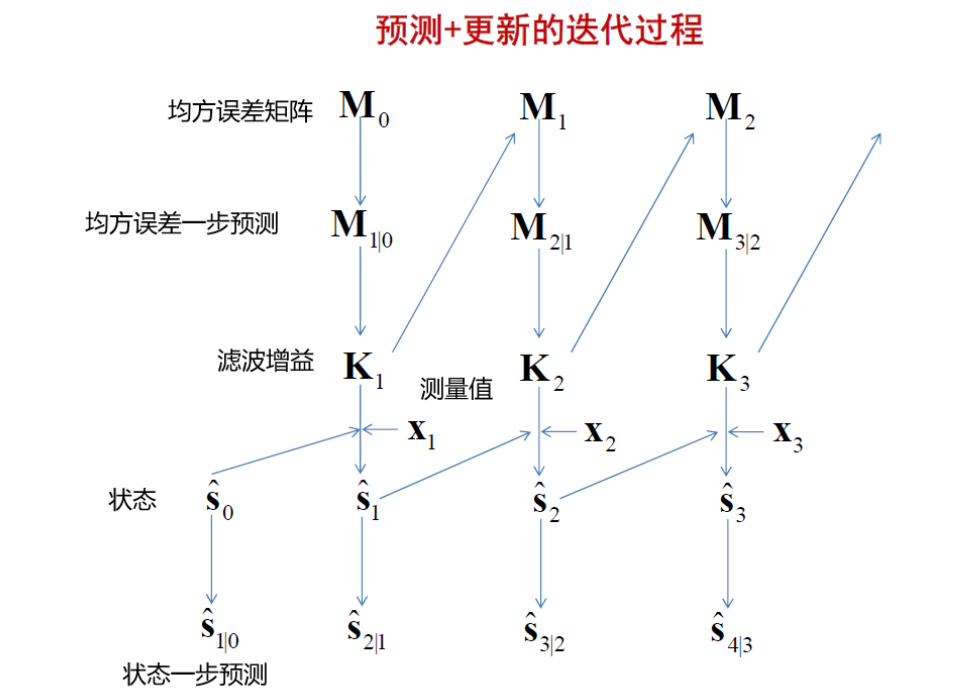
卡尔曼滤波递推流程:
- 使用均方误差矩阵更新均方误差一步预测
- 由均方误差一步预测计算滤波增益
- 使用滤波增益更新均方误差矩阵
- 根据上一步状态、滤波增益、实际测量更新状态
- 更新状态一步预测















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









