







更详细的推导,可以参考这篇博客:一维搜索、最速下降(梯度下降)与牛顿法(拟牛顿法)
1.求解最优步长的方法:

f
(
x
)
f(x)
f(x)可以理解为目标函数,损失函数。我们的目标是最小化这个损失函数,最小化大多通过迭代得到,那么每一步迭代更新的步长也很重要,知道每一点的函数值下降最快的方向后(负梯度方向),还需要选取最优的步长,可以使得损失函数每一步迭代下降更快。
如果我们不想求解最优步长,那么就只需要设定固定步长即可,但是这样做的话,迭代更新较慢,也有可能取不到(全局或局部)最优解,而是在最优解附近。后面的例子,我们会讨论固定步长的劣势。
每一步的最优步长
λ
k
\lambda{_k}
λk 由求解式
λ
k
=
a
r
g
m
i
n
f
(
x
k
+
λ
d
k
)
\color{red}\lambda{_k}=arg min f(x_k+λd_k)
λk=argminf(xk+λdk)得到,是一种精确步长的搜索方式。
即,由
x
0
x_0
x0到
x
1
x_1
x1的更新步长为
λ
0
\lambda{_0}
λ0,由
x
1
x_1
x1到
x
2
x_2
x2的更新步长为
λ
1
\lambda{_1}
λ1,… ,由
x
k
−
1
x_{k-1}
xk−1到
x
k
x_k
xk的更新步长为
λ
k
−
1
\lambda{_{k-1}}
λk−1。
d
k
d_k
dk 是在
x
k
x_k
xk 点时的搜索方向,如果是梯度下降法时,我们的方向就变成了
d
k
=
−
∇
f
(
x
k
)
d_k =−∇f(x_k)
dk=−∇f(xk),(梯度方向是函数值增长最快的方向,梯度下降就是负梯度方向,即函数值减小最快的方向)。
求解这个式子,就需要把
f
(
x
k
+
λ
d
k
)
f(x_k+λd_k)
f(xk+λdk)看做是
λ
\lambda
λ的函数,令:
g
(
λ
)
=
f
(
x
k
+
λ
d
k
)
\color{red}g(\lambda)=f(x_k+λd_k)
g(λ)=f(xk+λdk)
那么
f
(
x
k
+
λ
d
k
)
f(x_k+λd_k)
f(xk+λdk)取极小值,就是
g
′
(
λ
)
=
0
\color{red}g'(\lambda)=0
g′(λ)=0 时,求解
λ
\lambda
λ 。
由于
f
(
x
)
,
x
k
,
∇
f
(
x
k
)
f(x),x_k,∇f(x_k)
f(x),xk,∇f(xk)已知,所以
f
′
(
x
k
+
λ
d
k
)
f'(x_k+λd_k)
f′(xk+λdk)中只有
λ
\lambda
λ一个未知数,那么
g
′
(
λ
)
=
f
′
(
x
k
+
λ
d
k
)
=
0
\color{red}g'(\lambda)=f'(x_k+λd_k)=0
g′(λ)=f′(xk+λdk)=0
可以求解出
λ
\lambda
λ。
例子:
一维度函数
f
(
x
)
=
(
x
+
1
)
2
\color{red}f(x)=(x+1)^2
f(x)=(x+1)2,在初始值
x
0
=
0
x_0=0
x0=0时,梯度即一阶导
∇
f
(
x
0
)
=
2
x
0
+
2
=
2
\nabla{f(x_0)}=2x_0+2=2
∇f(x0)=2x0+2=2
d
0
=
−
∇
f
(
x
0
)
=
−
2
d_0=-\nabla{f(x_0)}=-2
d0=−∇f(x0)=−2
f
(
x
1
)
=
f
(
x
0
+
λ
d
0
)
=
(
x
0
+
λ
d
0
+
1
)
2
=
(
1
−
2
λ
)
2
\begin {aligned} f(x_{1})&=f(x_0+\lambda{d_0})\\ &=(x_0+\lambda{d_0}+1)^2 \\ &=(1-2{\lambda})^2\\ \end {aligned}
f(x1)=f(x0+λd0)=(x0+λd0+1)2=(1−2λ)2
f
′
(
x
0
+
λ
d
0
)
=
2
(
1
−
2
λ
)
∗
(
−
2
)
=
0
f'(x_0+\lambda{d_0})=2(1-2{\lambda})*(-2)=0
f′(x0+λd0)=2(1−2λ)∗(−2)=0
解得:
λ
=
0.5
\color{red}\lambda =0.5
λ=0.5,从而得到了
x
0
x_0
x0到
x
1
x_1
x1 的最优步长。
那么就可以求得
x
1
=
x
0
+
λ
d
0
=
0
+
0.5
∗
(
−
2
)
=
−
1
x_1=x_0+λd_0=0+0.5*(-2)=-1
x1=x0+λd0=0+0.5∗(−2)=−1
这就是迭代。
继续下一次迭代:
x
1
=
−
1
,
∇
f
(
x
1
)
=
0
,
d
1
=
0
x_1=-1,\nabla{f(x_1)}=0,d_1=0
x1=−1,∇f(x1)=0,d1=0,那么
x
1
=
x
0
+
λ
∗
d
1
=
x
0
+
λ
∗
0
=
x
0
x_1=x_0+\lambda *d_1=x_0+\lambda*0=x_0
x1=x0+λ∗d1=x0+λ∗0=x0
我们看到,
x
1
=
x
0
\color{red}x_1=x_0
x1=x0,就是说,下一次更新的点还在
x
0
x_0
x0就是没更新了,在看前面在
x
1
x_1
x1处的梯度
∇
f
(
x
1
)
=
0
\color{red}\nabla{f(x_1)}=0
∇f(x1)=0,就是不会再更新了,已经找到了最优点,就是
x
1
=
−
1
x_1=-1
x1=−1。到这里,仅仅做了一次迭代就达到了最优点,是因为我这里设置的函数为二次多项式,比较简单,一次就能求出最优解。实际情况中其他比较复杂的函数不会这么一次就迭代完成。
我们验证一下,
x
=
−
1
x=-1
x=−1是不是
f
(
x
)
=
(
x
+
1
)
2
f(x)=(x+1)^2
f(x)=(x+1)2的最小值点呢?
对
f
(
x
)
f(x)
f(x)求导
f
′
(
x
)
=
0
f'(x)=0
f′(x)=0,解得
x
=
−
1
x=-1
x=−1。所以前面的迭代法求得的结果是准确的。
最优步长 对比 固定步长:
那么,如果我们在每个点
x
k
x_k
xk处都设置固定步长为
λ
=
0.1
\lambda=0.1
λ=0.1 的话,那么:
x
1
=
x
0
+
λ
∗
d
0
=
0
+
0.1
∗
(
−
2
)
=
−
0.2
x_1=x_0+\lambda*d_0=0+0.1*(-2)=-0.2
x1=x0+λ∗d0=0+0.1∗(−2)=−0.2
f
(
x
1
)
=
(
−
0.2
+
1
)
2
=
0.64
f(x_1)=(-0.2+1)^2=0.64
f(x1)=(−0.2+1)2=0.64
比最优步长得到的函数值0还大很多,需要继续迭代:
d
2
=
−
1.6
d_2=-1.6
d2=−1.6
x
2
=
x
1
+
λ
∗
d
2
=
−
0.2
+
0.1
∗
(
−
1.6
)
=
−
0.36
x_2=x_1+\lambda*d_2=-0.2+0.1*(-1.6)=-0.36
x2=x1+λ∗d2=−0.2+0.1∗(−1.6)=−0.36
f
(
x
2
)
=
(
−
0.36
+
1
)
2
=
0.6
4
2
=
0.4096
f(x_2)=(-0.36+1)^2=0.64^2=0.4096
f(x2)=(−0.36+1)2=0.642=0.4096
x
2
=
−
0.36
x_2=-0.36
x2=−0.36处的损失函数值变成了0.4096进一步缩小,再往后迭代几次可能也得不到最优解
x
∗
=
−
1
x^*=-1
x∗=−1,而是在-1附近徘徊,我这里不再向后推算,明白原理即可,感兴趣的自己往后推算。
下面这个是最速下降法的性质,即前后两次迭代的梯度向量方向正交,并不是求解步长 λ \lambda λ。
根据求导公式,
y
=
f
(
a
+
b
∗
x
)
y=f(a+b*x)
y=f(a+b∗x)对
x
x
x求导,得到
y
′
=
f
′
(
a
+
b
∗
x
)
∗
(
b
∗
x
)
′
y'=f'(a+b*x)*(b*x)'
y′=f′(a+b∗x)∗(b∗x)′,
即
y
′
=
f
′
(
a
+
b
∗
x
)
∗
b
y'=f'(a+b*x)*b
y′=f′(a+b∗x)∗b
那么
g
′
(
λ
)
=
f
′
(
x
k
+
λ
d
k
)
=
0
\color{red}g'(\lambda)=f'(x_k+λd_k)=0
g′(λ)=f′(xk+λdk)=0 是对
λ
\lambda
λ求导,则:
g
′
(
λ
)
=
∇
f
(
x
k
+
λ
k
d
k
)
T
∗
d
k
=
0
g'(\lambda)=\nabla f(x_k+λ_kd_k)^T*d_k=0
g′(λ)=∇f(xk+λkdk)T∗dk=0
可得:
−
∇
f
(
x
k
+
1
)
T
∇
f
(
x
k
)
=
0
\color{red}-\nabla f(x_{k+1})^T\nabla f(x_k)=0
−∇f(xk+1)T∇f(xk)=0
2.梯度下降法 和 最速下降法:
相同点:都是让迭代点沿着负梯度方向前进,保证函数的“最速”下降;
不同点:在于步长 λ \lambda λ的取值:
- 梯度下降法的步长 λ \lambda λ是定值,由工程师指定;
- 最速下降法的步长 λ \lambda λ是通过求解得到最优步长,它能使迭代更快收敛。
因此梯度下降法只是最速下降法中的一种特殊形式。
使用最速下降法得到的迭代路线往往是呈现一个之字形的走势。而当迭代点越靠近极小点,其移动的步长较小,严重影响到了收敛的速度。虽然从局部来看,每次选择的方向都是函数值下降最快的方向,但是从全局来看,锯齿现象导致当距离极小点较近时需要绕不少弯路才能收敛,反而收敛较慢。
因此,在计算的前中期使用梯度下降,而在接近极小点时使用其他算法进行迭代,会是更理想的方案。
3.牛顿法迭代法:
牛顿法迭代法:基本思想是利用二阶泰勒展开在极小点附近来近似目标函数,最终解出极小点的一个近似值。
4.梯度下降法 或 牛顿法 进行最优化的步骤:
要最小化目标函数 f ( x ⃗ ) f(\vec{x}) f(x),也就是要找到某个点 x k ⃗ \vec{x_k} xk使得 f ( x ⃗ ) f(\vec{x}) f(x)最小,即 m i n f ( x ⃗ ) min f(\vec{x}) minf(x)。
这里 x k ⃗ \vec{x_k} xk头上打箭头表示 x x x是多维点,就是向量。因为实际问题中很少会是一维点的。
一般都是使用迭代法更新求最优值
x
∗
⃗
\vec{x^*}
x∗:
4.1.方法1:使用梯度下降法进行更新迭代:
-
步骤1:给一个初始值 x 0 ⃗ \vec{x_0} x0,和精度阈值 ϵ \epsilon ϵ,并令 k = 0 k=0 k=0;
-
步骤2:更新迭代计算:
如果步长 λ \lambda λ 需要计算,就在这里进行计算,得到这一步迭代的最优步长;
计算梯度 ∇ f ( x k ) \nabla f(x_k) ∇f(xk)后,按照下式进行迭代更新 x ⃗ \vec{x} x:
x k + 1 = x k − λ ∇ f ( x k ) x_{k+1}=x_{k}-\lambda\nabla f(x_k) xk+1=xk−λ∇f(xk) -
步骤3:判断迭代停止条件:
若梯度模 ∣ ∣ ∇ f ( x k ) ∣ ∣ < ϵ ||\nabla f(x_k)||< \epsilon ∣∣∇f(xk)∣∣<ϵ,(梯度特别小的点基本就是局部或者全局最优点),则停止迭代。
梯度模是类似下面这样计算: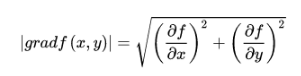
zhz:这里迭代停止条件也可以使用:1.连续10次更新得到的 f ( x k ) f(x_k) f(xk)差值 ∣ ∣ f ( x k + 1 ) − f ( x k ) ∣ ∣ < ϵ ||f(x_{k+1})-f(x_k)||< \epsilon ∣∣f(xk+1)−f(xk)∣∣<ϵ;2.达到多少次迭代后。 -
步骤4:另 k = k + 1 k=k+1 k=k+1,转至步骤2;
4.2.方法2:使用牛顿法即 二阶泰勒展开式 更新迭代:
- 步骤1:给一个初始值 x 0 ⃗ \vec{x_0} x0,和精度阈值 ϵ \epsilon ϵ,并令 k = 0 k=0 k=0;
- 步骤2:更新迭代计算:
计算牛顿方向: - ∇ 2 f ( x k ) − 1 ∇ f ( x k ) {\nabla}^2 f(x_k)^{-1} \nabla f(x_k) ∇2f(xk)−1∇f(xk)后,按照下式进行迭代更新 x ⃗ \vec{x} x:
x k + 1 = x k − ∇ 2 f ( x k ) − 1 ∇ f ( x k ) x_{k+1}=x_{k}- {\nabla}^2 f(x_k)^{-1} \nabla f(x_k) xk+1=xk−∇2f(xk)−1∇f(xk)
或者也加上步长 λ \lambda λ,就变成了阻尼牛顿法,这里需要使用求解最优步长 λ \lambda λ的方法:
x k + 1 = x k − λ ∇ 2 f ( x k ) − 1 ∇ f ( x k ) x_{k+1}=x_{k}- \lambda{\nabla}^2 f(x_k)^{-1} \nabla f(x_k) xk+1=xk−λ∇2f(xk)−1∇f(xk) - 步骤3:判断迭代停止条件:
梯度模是类似下面这样计算:
若梯度模 ∣ ∣ ∇ f ( x k ) ∣ ∣ < ϵ ||\nabla f(x_k)||< \epsilon ∣∣∇f(xk)∣∣<ϵ,(梯度特别小的点基本就是局部或者全局最优点),则停止迭代。
zhz:这里迭代停止条件也可以使用:1.连续10次更新得到的 f ( x k ) f(x_k) f(xk)差值 ∣ ∣ f ( x k + 1 ) − f ( x k ) ∣ ∣ < ϵ ||f(x_{k+1})-f(x_k)||< \epsilon ∣∣f(xk+1)−f(xk)∣∣<ϵ;2.达到多少次迭代后 - 步骤4:另 k = k + 1 k=k+1 k=k+1,转至步骤2;
这里贴上阻尼牛顿法的更新步骤:


4.3.比较两种方法的异同
比较上面两种方法,步骤2开始使用不同方法来迭代更新。对于两种方法的迭代公式,可以看出,方法2牛顿法迭代公式中黑塞矩阵的逆 ∇ 2 f ( x k ) − 1 \nabla^2f(x^k)^{-1} ∇2f(xk)−1相当于方法1梯度下降法迭代公式的步长 λ \lambda λ,这样两个公式就一样了。当然,我们也可以在方法2牛顿法中也加上步长 λ \lambda λ,这样,其实是由黑塞矩阵的逆 ∇ 2 f ( x k ) − 1 \nabla^2f(x^k)^{-1} ∇2f(xk)−1和 λ \lambda λ共同决定。
对于方法1梯度下降的步长 λ \lambda λ,可以人为设定一个定值,也可以使用最速下降法中的一维搜索寻求最优步长,让算法迭代快速收敛。使用一维搜索的话,就可以参考前面的 a r g m i n f ( x k + λ d k ) \color{red}arg min f(x_k+λd_k) argminf(xk+λdk) 求解步长 λ \lambda λ。
一般认为方法2牛顿法可以利用到曲线本身的信息,比方法1梯度下降法更容易收敛(迭代更少次数)。
如下图,是一个最小化一个目标方程的例子,红色曲线是利用牛顿法迭代求解,绿色曲线是利用梯度下降法求解:

4.4.疑问:实际工程中,什么时候使用梯度下降法呢?什么时候用到牛顿法呢?
如果需要训练神经网络模型,那么可以使用梯度下降法。如果需要实时计算得到最优解的话,梯度下降法需要迭代,那么每一帧数据都迭代的话,如果耗时比较久,就不合适了,如果耗时很短,可以试试。
实际工程中,什么时候用到牛顿法呢?它能保证实时吗?它能用在神经网络吗?还有,特征维度特别大的时候,计算黑塞矩阵就会有维度灾难,计算的代价特别大,可以考虑使用PCA降维?或者不直接计算黑塞矩阵(见阻尼牛顿法的蓝色字体的介绍)?


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









