






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Vipra Singh
编译:ronghuaiyang
导读
现在,请跟随我们一起踏上另一段探索之旅,进入高级RAG技术的迷人世界。
欢迎回到我们关于高级检索增强生成(RAG)技术系列的最新篇章!在本系列的前九部分中,我们深入探讨了RAG,解析了检索机制与生成模型之间的精妙互动。从掌握生成模型的基础知识到通过大型语言模型(LLMs)探索前沿技术,我们覆盖了广阔的概念与方法领域。现在,请跟随我们一起踏上另一段探索之旅,进入高级RAG技术的迷人世界。
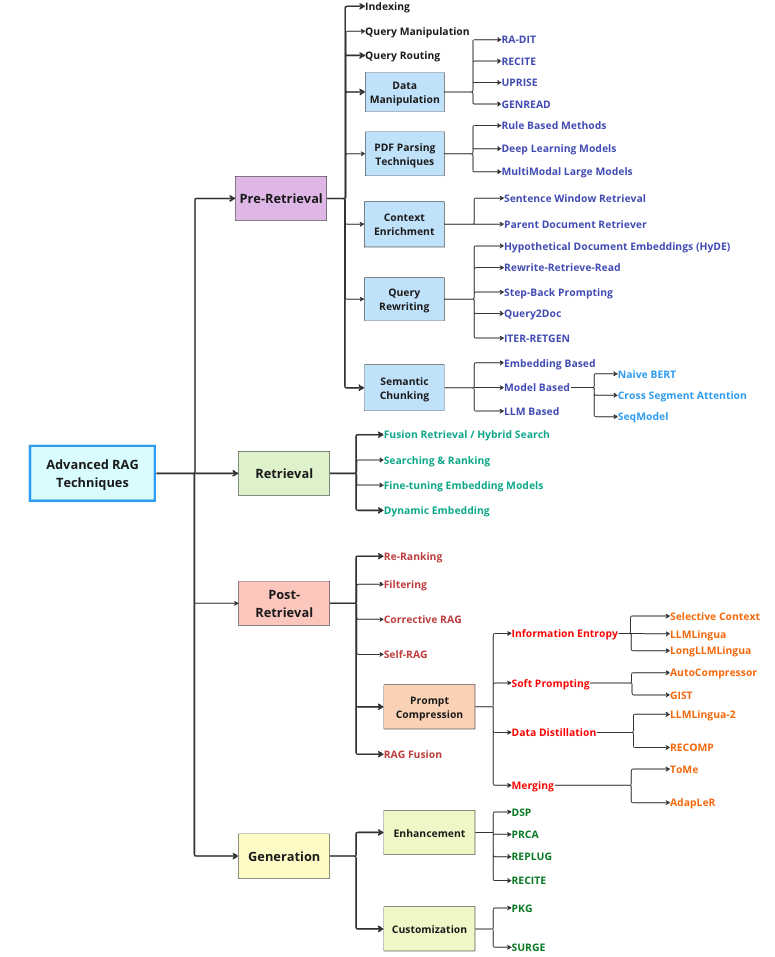
一份最近的调查报告对检索增强生成(RAG)进行了总结,提出了三种近期演变的范式:
简单RAG
高级RAG
模块化RAG
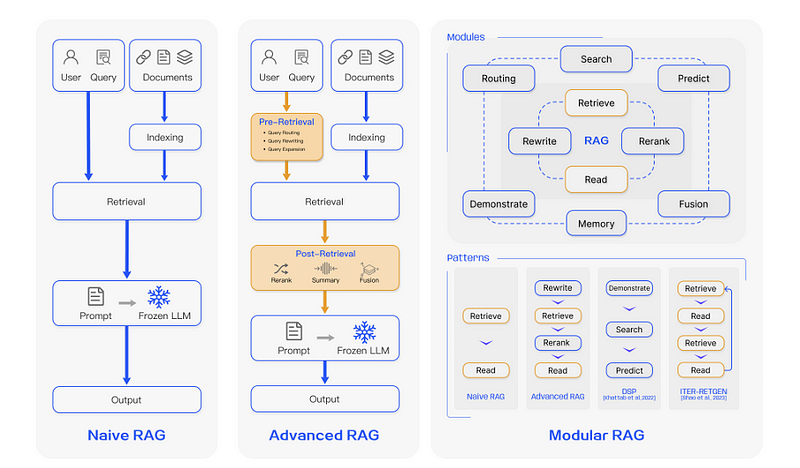
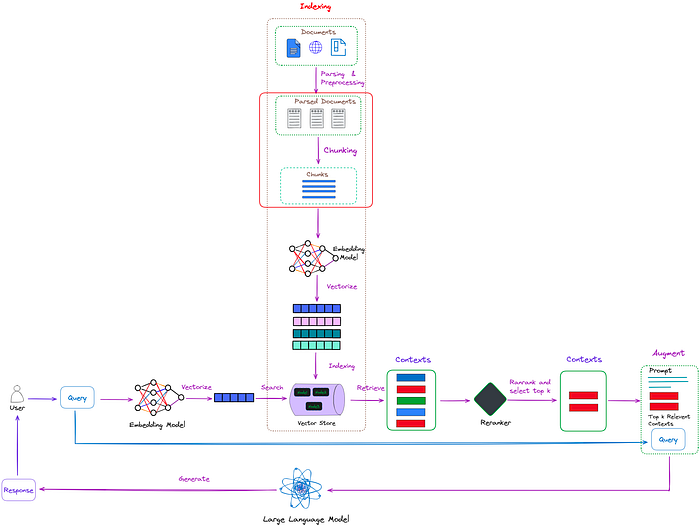
RAG过程应用于问题回答的一个典型实例,主要包含三个步骤。1)索引。文档被分割成片段,编码为向量,并存储在向量数据库中。2)检索。根据语义相似性,检索与问题最相关的Top k个片段。3)生成。将原始问题和检索到的片段一起输入到LLM中,生成最终答案。
Naive RAG
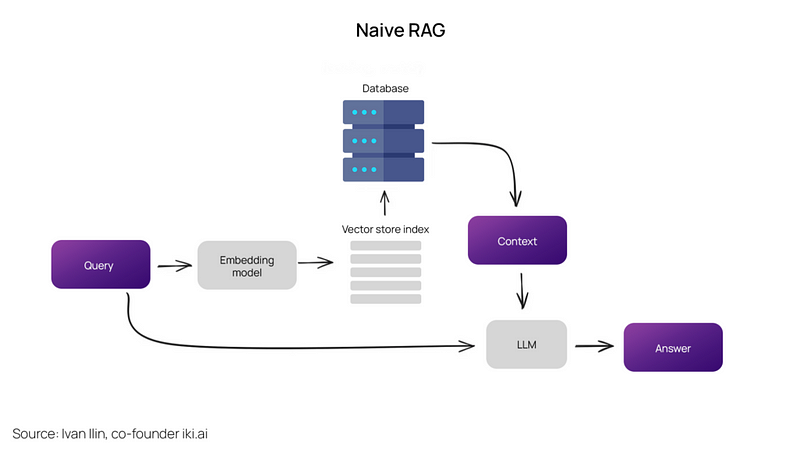
标准的RAG流程包括将文本分割成片段,使用Transformer编码器模型将这些片段嵌入到向量中,对这些向量进行索引,随后为LLM构造一个提示。这个提示指导模型根据用户的查询,在搜索阶段收集的上下文中生成回复。
在运行时,使用相同的编码器模型将用户的查询向量化,利用这个向量对索引进行搜索,找出排名前k的结果,从数据库中提取相应的文本片段,并将它们作为上下文输入到LLM的提示中。
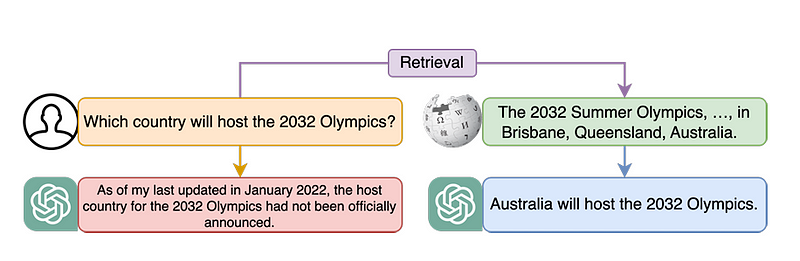
下面是RAG如何增强ChatGPT的一个例子。
现在,让我们来看看简单RAG存在的问题。
Naive RAG的问题
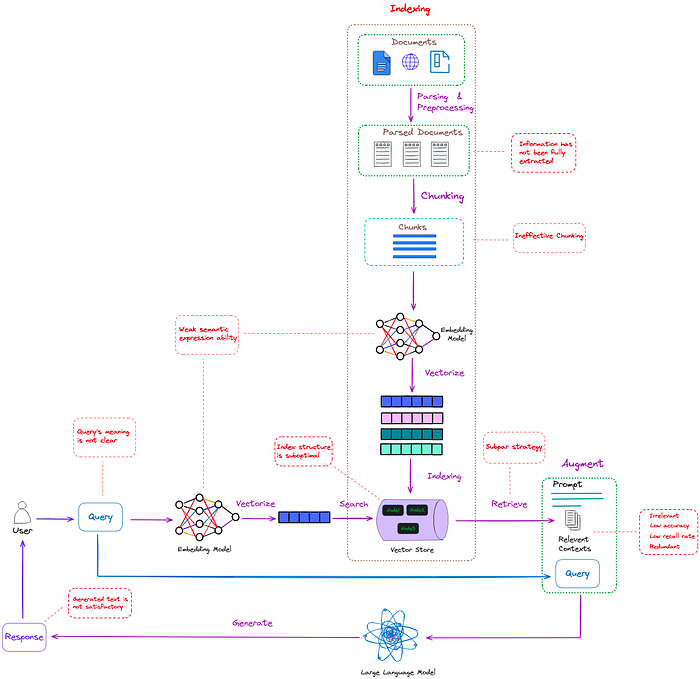
如上图所示,简单RAG在上述三个步骤中都存在问题(红色虚线框),有很大的优化空间。
索引
信息抽取不完整,因为它未能有效处理PDF等非结构化文件中图像和表格内的有用信息。
分割过程采取“一刀切”的策略,而不是根据不同文件类型的特点选择最优策略。这导致每个片段包含不完整的语义信息。此外,它忽略了文本中现有的标题等重要细节。
索引结构不够优化,导致检索功能效率低下。
嵌入模型的语义表示能力较弱。
检索
回忆的上下文相关性不足,准确度低。
较低的召回率阻止了所有相关段落的检索,从而妨碍了LLM生成全面答案的能力。
查询可能不准确,或者嵌入模型的语义表示能力较弱,导致无法检索到有价值的信息。
检索算法有限,因为它没有结合不同类型的方法或算法,如关键词、语义和向量检索的结合。
多个检索的上下文含有相似信息,造成生成答案中的内容重复。
生成
有效整合检索到的上下文与当前生成任务可能难以实现,导致输出不一致。
过度依赖生成过程中的增强信息存在高风险。这可能导致输出仅仅重复检索到的内容,而没有提供有价值的信息。
LLM可能会生成错误、不相关、有害或带有偏见的响应。
需要注意的是,这些问题的原因可能是多方面的。例如,如果给用户的最终回应包含无关内容,这可能不仅仅是因为LLM的问题。根本原因可能是PDF文档提取不精确,或者嵌入模型无法准确捕捉语义,等等。
转向高级RAG
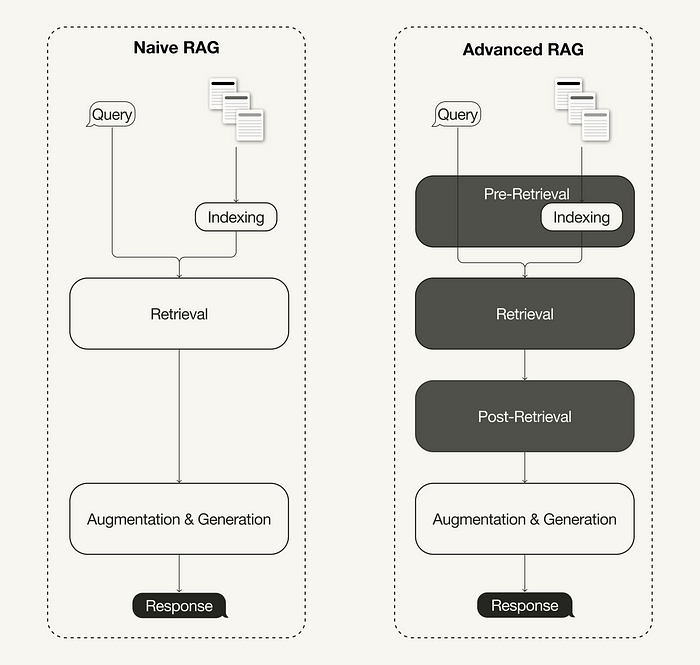
随着基础RAG局限性的显现,推动了更复杂系统的开发。高级RAG模型融合了更复杂的检索技术,更好地整合检索到的信息,并通常具备迭代优化检索和生成过程的能力。
高级RAG的关键特征:
高级检索算法(如语义搜索、情境理解)。
改进的检索数据整合,通常伴有情境和相关性加权。
迭代精炼能力,允许提高准确性和相关性。
纳入反馈循环和学习机制以实现持续改进。
高级RAG范式包含了一系列旨在解决基础RAG已知局限性的技术。RAG的基础工作流程始于创建包含外部资源的索引。该索引充当基础,通过基于特定查询的检索模型来检索相关信息。最后一步涉及一个生成器模型,它将检索到的信息与查询相结合,生成所需的输出。
RAG范式在该领域内组织研究,提供了一个简单却强大的框架来提升LLM性能。RAG的核心在于其搜索机制,这是生成高质量结果的关键。因此,从检索的角度来看,该范式被划分为四个主要阶段:预检索、检索、后检索和生成。
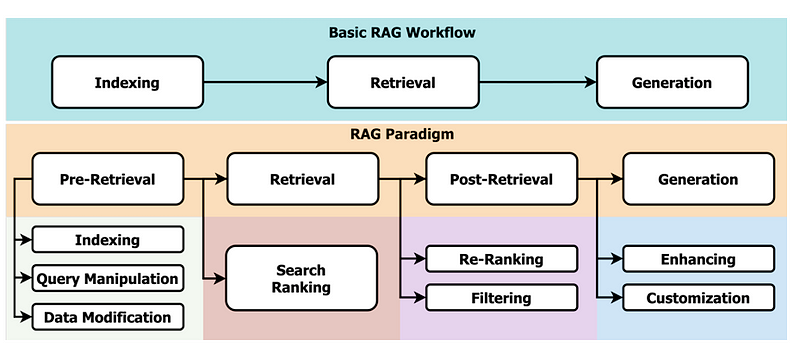
预检索优化
预检索优化专注于数据索引优化和查询优化。数据索引优化技术旨在以有助于我们提升检索效率的方式存储数据,具体包括:
索引: 流程始于索引建立,它构建了一个有序系统,以实现信息的快速和准确检索。索引的具体方式取决于任务和数据类型。例如,句级索引对于问题回答系统有益,可以精确定位答案;而文档级索引更适合于总结文档,帮助理解其主要概念和思想。
查询操作: 完成索引后,进行查询操作以调整用户查询,使其与索引数据更好地匹配。这包括查询重写,重新表述查询以更贴近用户意图;查询扩展,通过同义词或相关术语扩展查询,以捕获更多相关结果;以及查询规范化,解决拼写或术语差异,确保查询的一致性匹配。
数据修改: 这也是提升检索效率的关键。这一步骤包括预处理技术,如去除无关或冗余信息,以提高结果质量;同时通过元数据等额外信息丰富数据,以增强检索内容的相关性和多样性。

检索优化
检索阶段的目标是识别最相关的上下文。通常,检索基于向量搜索,计算查询与索引数据之间的语义相似性。因此,大多数检索优化技术围绕着嵌入模型展开:
搜索与排序: 检索阶段是搜索和排序的结合。它侧重于从数据集中选择和优先排列文档,以提升生成模型输出的质量。这一阶段运用搜索算法在索引数据中导航,寻找与用户查询相匹配的文档。在识别出相关文档后,初步排序过程开始,根据文档与查询的相关性对其进行排序。
微调嵌入模型针对特定领域的上下文定制嵌入模型,特别适用于具有进化或罕见术语的领域。例如,
BAAI/bge-small-en是一种高性能的嵌入模型,可以进行微调。动态嵌入根据单词的使用上下文进行适应,与静态嵌入不同,静态嵌入为每个单词使用单一向量。例如,OpenAI的
embeddings-ada-02是一种先进的动态嵌入模型,能够捕捉上下文理解。
除了向量搜索外,还有其他的检索技术,比如混合搜索,通常指的是结合向量搜索与基于关键词的搜索的概念。如果我们的检索需要精确的关键词匹配,这种检索技术会很有用。
后检索优化
后检索阶段旨在优化最初检索到的文档,以提升文本生成的质量。这一阶段包括重排序和过滤,各自旨在优化文档选择,以便于最终的生成任务。
提示压缩通过去除不相关部分和突出重要上下文来缩短整体提示长度。
重排序: 在重排序步骤中,之前检索到的文档被重新评估、评分和重组。目的是更准确地突出与查询最相关的文档,降低不太相关文档的重要性。这一步骤涉及引入额外的指标和外部知识源来提高精确度。在这种情况下,可以有效地利用预训练模型,尽管它们的效率较低,但准确性更高,因为候选文档数量有限。
过滤: 这一过程旨在移除未达到指定质量或相关性标准的文档。这可以通过几种方法实现,如设定最低相关性得分阈值,排除低于一定相关水平的文档。此外,利用来自用户反馈或先前相关性评价的信息有助于调整过滤过程,确保只有最相关的文档被保留用于文本生成。
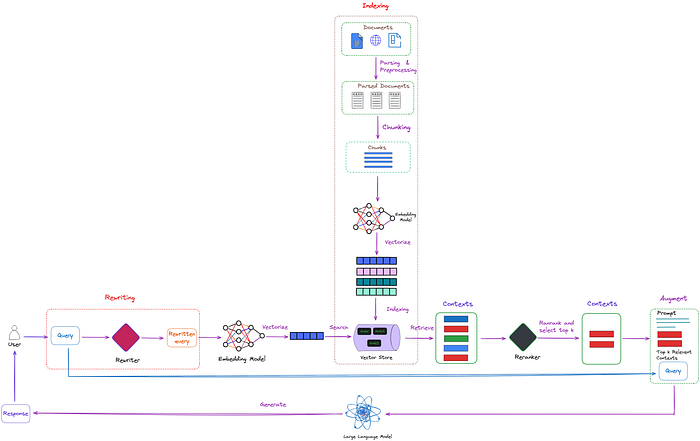
高级RAG技术
现在我们将更深入地探讨高级RAG技术的概览。下面是一个示意图,描绘了核心步骤和所涉及的算法。为了保持图示的可读性,省略了一些逻辑循环和复杂的多步骤代理行为。
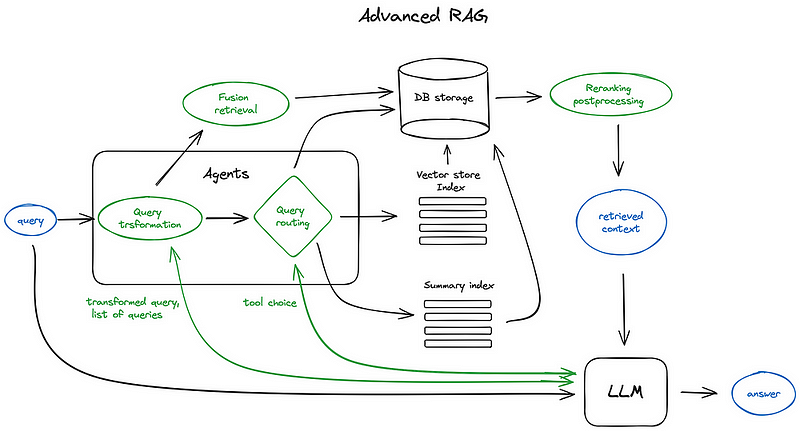
方案中的绿色元素是后续讨论的核心RAG技术,蓝色元素代表文本。并非所有高级RAG理念都易于在一个方案中可视化,例如,各种扩大上下文的方法就被省略了——我们将在后面逐步深入探讨。
现在,我们来讨论这些技术。
预检索技术
PDF解析
对于RAG而言,从文档中提取信息是不可避免的场景。确保从源头高效地提取内容对于提升最终输出的质量至关重要。
不应低估这一过程。在实施RAG时,解析过程中信息提取的不足会导致PDF文件中所含信息的理解和利用受到限制。
下图展示了解析过程在RAG中的位置:
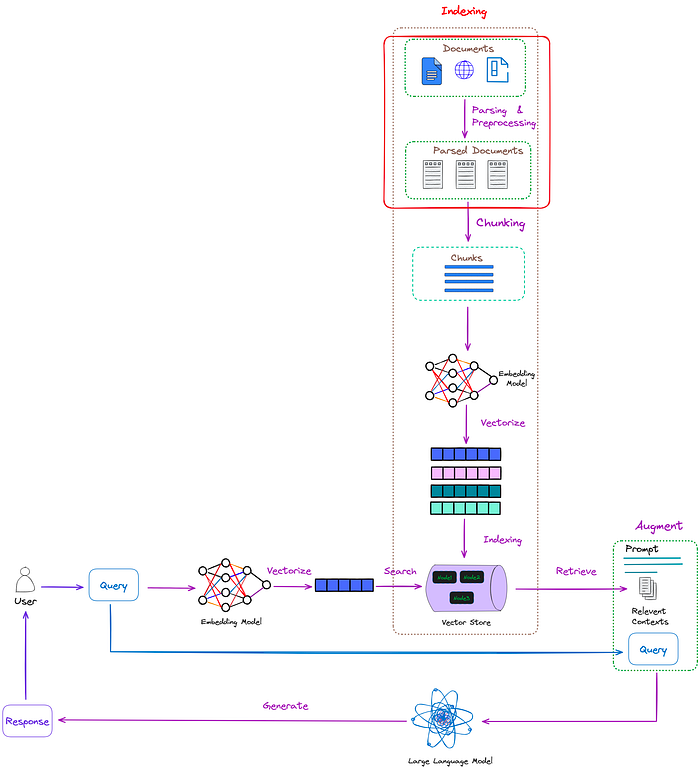
在实际工作中,非结构化数据远比结构化数据更为普遍。如果这些海量数据无法被解析,它们的巨大价值就无法得到体现。
在非结构化数据中,PDF文档占据了大多数。有效处理PDF文档也能极大地辅助管理其他类型的非结构化文档。
本文主要介绍解析PDF文件的方法。它提供了算法和建议,用于有效解析PDF文档并尽可能多地提取有用信息。
解析PDF的挑战
PDF文档是无结构文档的典型代表,然而,从PDF文档中提取信息是一个充满挑战的过程。
与其说PDF是一种数据格式,不如说它更像是一系列打印指令的集合。一个PDF文件由一系列指示组成,告诉PDF阅读器或打印机如何在屏幕上或纸上显示符号。这与HTML和docx等文件格式形成对比,后者使用诸如<p>, <w:p>, <table>和<w:tbl> 等标签来组织不同的逻辑结构,如下面的图所示:
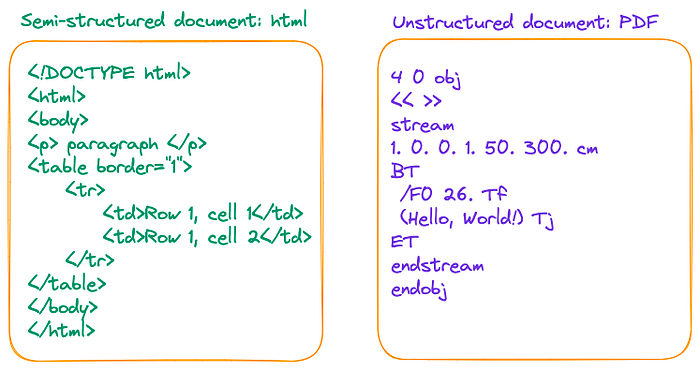
解析PDF文档的难点在于精确提取整个页面的布局,并将内容,包括表格、标题、段落和图像,转化为文档的文本表示。 这个过程涉及到处理文本提取的不准确性、图像识别以及表中行-列关系的混淆等问题。
如何解析PDF文档
通常,有三种方法来解析PDF:
基于规则的方法,其中根据文档的组织特征确定每一部分的样式和内容。然而,这种方法的泛化能力有限,因为PDF的类型和布局多种多样,不可能用预定义的规则覆盖所有情况。
基于深度学习模型的方法,例如结合物体检测和OCR模型的流行解决方案。
基于多模态大型模型解析复杂结构或在PDF中提取关键信息的方法。
基于规则的方法
最具代表性的工具之一是pypdf,这是一种广泛使用的基于规则的解析器。它是LangChain和LlamaIndex中解析PDF的标准方法。
下面是尝试使用pypdf解析论文“Attention Is All You Need”第6页的例子。原始页面如下图所示:

代码如下:
import PyPDF2
filename = "1706.03762.pdf"
pdf_file = open(filename, 'rb')
reader = PyPDF2.PdfReader(pdf_file)
page_num = 5
page = reader.pages[page_num]
text = page.extract_text()
print('--------------------------------------------------')
print(text)
pdf_file.close()执行结果为 (后面省略了):
(py) $ pip list | grep pypdf
pypdf 3.17.4
pypdfium2 4.26.0
(py) pypdf_test.py
--------------------------------------------------
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations
for different layer types. nis the sequence length, dis the representation dimension, kis the kernel
size of convolutions and rthe size of the neighborhood in restricted self-attention.
Layer Type Complexity per Layer Sequential Maximum Path Length
Operations
Self-Attention O(n2·d) O(1) O(1)
Recurrent O(n·d2) O(n) O(n)
Convolutional O(k·n·d2) O(1) O(logk(n))
Self-Attention (restricted) O(r·n·d) O(1) O(n/r)
3.5 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the
order of the sequence, we must inject some information about the relative or absolute position of the
tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the
bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel
as the embeddings, so that the two can be summed. There are many choices of positional encodings,
learned and fixed [9].
In this work, we use sine and cosine functions of different frequencies:
PE(pos,2i)=sin(pos/100002i/d model)
PE(pos,2i+1)=cos(pos/100002i/d model)
where posis the position and iis the dimension. That is, each dimension of the positional encoding
corresponds to a sinusoid. The wavelengths form a geometric progression from 2πto10000 ·2π. We
chose this function because we hypothesized it would allow the model to easily learn to attend by
relative positions, since for any fixed offset k,PEpos+kcan be represented as a linear function of
PEpos.
...
...
...
基于PyPDF检测的结果,我们观察到它将PDF中的字符序列串行化为一个长序列,而不保留结构性信息。换句话说,它将文档的每一行视为由换行符“`\n`”分隔的序列,这导致无法准确识别段落或表格。这一局限性是基于规则方法的固有特性。
基于深度学习模型的方法
该方法的优势在于它能够准确识别整个文档的布局,包括表格和段落。它甚至能够理解表格内的结构。这意味着它可以将文档分割成定义明确、完整的信息单元,同时保持预期的意义和结构。
然而,也存在一些局限。对象检测和OCR阶段可能耗时较长。因此,建议使用GPU或其他加速设备,并采用多进程和多线程进行处理。
这种方法涉及目标检测和OCR模型,我已经测试了几种代表性开源框架:
Unstructured:它已经被集成到langchain。使用
hi_res策略和infer_table_structure=True时,表格识别效果良好。但是,fast策略表现不佳,因为它没有使用目标检测模型,错误地识别了许多图像和表格。Layout-parser:如果我们需要识别复杂的结构化PDF,建议使用最大的模型以获得更高的准确性,虽然可能会稍微慢一些。此外,看起来Layout-parser的模型在过去两年中没有更新。
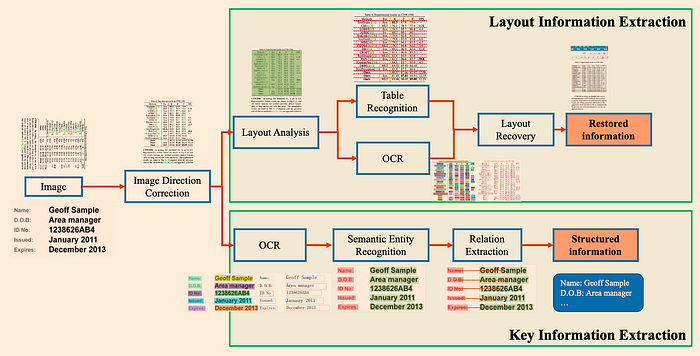
PP-StructureV2:使用多种模型组合进行文档分析,性能高于平均水平。架构如下图所示:
上下文增强
这里的概念是在为了提高搜索质量而检索更小片段的同时,添加周围上下文供LLM进行推理。有两种选择——通过围绕较小检索片段的句子来扩展上下文,或者递归地将文档拆分为包含较小子片段的多个较大父片段。
句子窗口检索
在这个方案中,文档中的每个句子都被单独嵌入,这为查询到上下文余弦距离搜索提供了极高的准确性。为了在检索到最相关的单个句子后更好地进行推理,我们通过在检索到的句子前后各扩展k个句子来扩大上下文窗口,然后将这个扩展后的上下文发送给LLM。
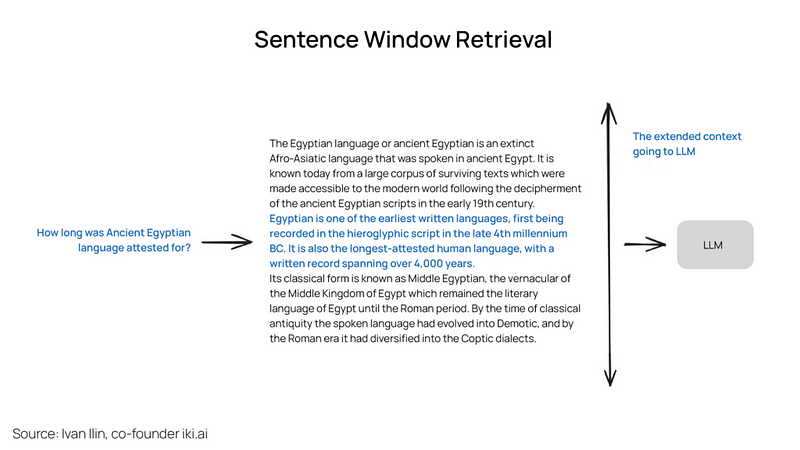
蓝色部分是在索引中搜索时找到的句子嵌入,而整个黑色加绿色的段落被送入LLM,以便在对提供的查询进行推理时扩大其上下文。
自动合并检索器(即父文档检索器)
这里的想法与句子窗口检索器非常相似——搜索更细粒度的信息,然后在将这些上下文传递给LLM进行推理之前,扩展上下文窗口。文档被拆分成更小的子块,这些子块指向更大的父块。
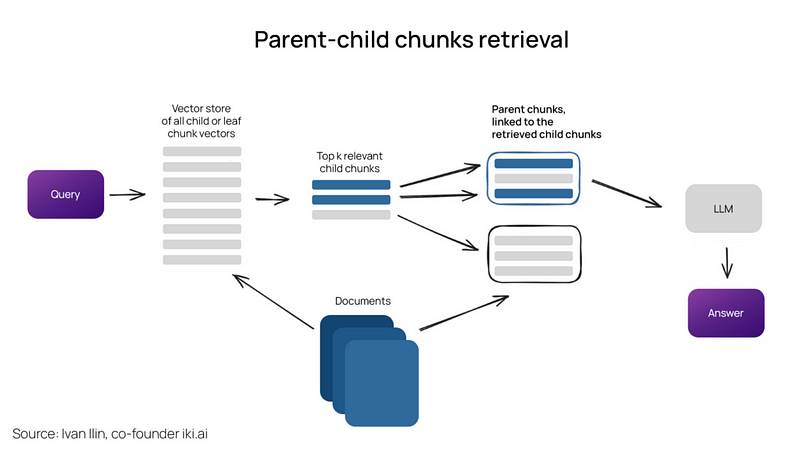
文档被拆分成层次化的块,然后最小的叶块被发送到索引。在检索时,我们检索k个叶块,如果有n个块指向同一个父块,我们就用这个父块替换它们,并将其发送到LLM进行答案生成。
在检索时首先获取较小的块,然后如果在检索到的前k个块中有超过n个块链接到同一个父节点(较大的块),我们用这个父节点替换传给LLM的上下文——就像自动将几个检索到的块合并成一个较大的父块,因此得名此方法。需要注意的是——搜索只在子节点索引中进行。
查询重写
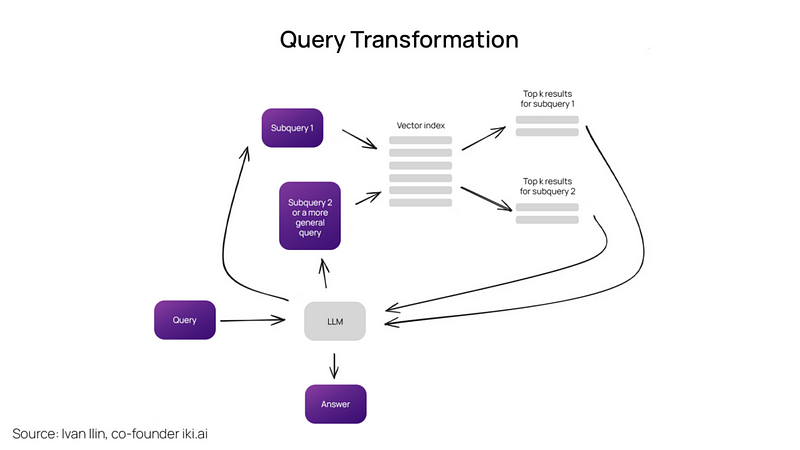
在检索增强生成(RAG)中,我们经常会遇到用户原始查询的问题,比如措辞不准确或缺乏语义信息。例如,像“2020年的NBA冠军是洛杉矶湖人队!告诉我什么是LangChain框架?”这样的查询,如果直接搜索,可能会从LLM得到不正确或无法回答的响应。
因此,将用户查询的语义空间与文档的语义空间对齐至关重要。查询重写技术可以有效地解决这个问题。它在RAG中的作用如下图所示:
从位置的角度来看,查询重写是一种检索前的方法。请注意,这个图表大致描绘了查询重写在RAG中的位置。在下一节中,我们将看到一些算法可能会改进这一过程。
查询重写是使查询和文档语义对齐的关键技术。例如:
假设文档嵌入(HyDE) 通过假设文档将查询和文档的语义空间对齐。
重写-检索-阅读 提出了一种框架,不同于传统的检索和阅读顺序,专注于查询重写。
Step-Back Prompting 允许LLM根据高层次的概念进行抽象推理和检索。
Query2Doc 使用来自LLM的少量提示创建伪文档。然后,它将这些伪文档与原始查询合并,构建一个新的查询。
ITER-RETGEN 提出了一种将先前生成的结果与前一个查询相结合的方法。随后检索相关文档并生成新结果。这个过程重复多次以达到最终结果。
让我们深入探讨这些方法的细节。
假设文档嵌入(HyDE)
论文“Precise Zero-Shot Dense Retrieval without Relevance Labels”提出了一种基于假设文档嵌入(HyDE)的方法,主要过程如下图所示:
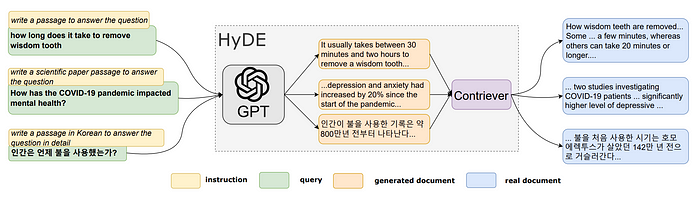
以下是HyDE模型的示意图。显示了文档片段。HyDE在不改变底层GPT-3和Contriever/mContriever模型的情况下,服务于所有类型的查询。

总之,尽管HyDE引入了一种新的查询重写方法,但它确实存在一些局限性。它并不依赖于查询嵌入的相似性,而是强调一个文档与另一个文档之间的相似性。然而,如果语言模型对主题不够熟悉,可能不会总是产生最佳结果,这可能导致错误增加。
重写-检索-阅读
这个想法来源于论文“Query Rewriting for Retrieval-Augmented Large Language Models”。它认为,原始查询,特别是在现实世界场景中,可能并不总是适合LLM进行检索的最佳选择。
因此,论文建议我们应该首先使用LLM来重写查询。然后应该进行检索和答案生成,而不是直接从原始查询检索内容并生成答案,如图4(b)所示。
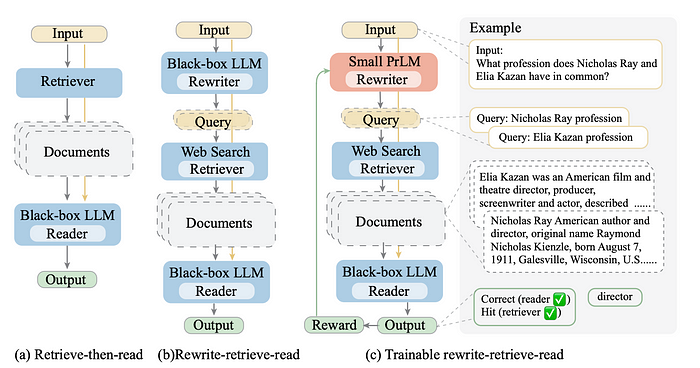
为了说明查询重写如何影响上下文检索和预测性能,请考虑以下示例:“2020年的NBA冠军是洛杉矶湖人队!告诉我LangChain框架是什么?”这个查询通过重写被准确地处理。
Step-Back Prompting
STEP-BACK PROMPTING是一种简单的提示技巧,它使LLM能够进行抽象,从包含具体细节的实例中提炼出高层次的概念和基本原理。其核心思想是定义“回退问题”,即从原始问题衍生出的更为抽象的问题。
例如,如果一个查询包含大量细节,LLM很难检索到相关事实来解决任务。如下面图中的第一个例子所示,对于物理问题“如果温度增加2倍,体积增加8倍,理想气体的压力P会发生什么变化?”当直接对问题进行推理时,LLM可能会偏离理想气体定律的第一原则。
同样,由于具体时间范围的限制,“Estella Leopold在1954年8月至11月期间去了哪所学校?”这个问题直接回答起来很困难。
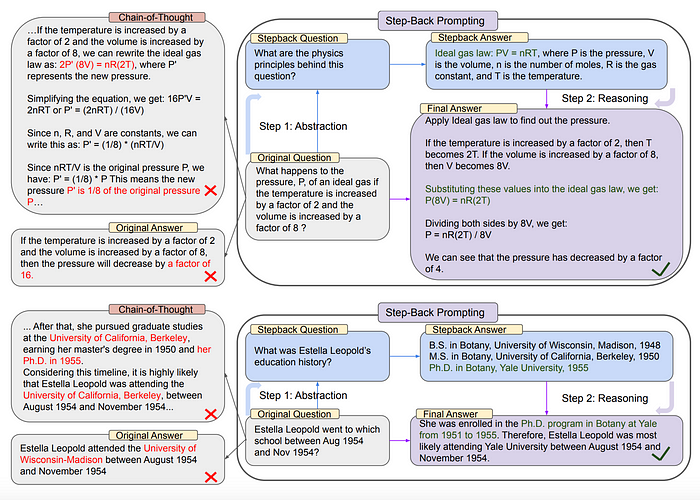
上图展示了通过概念和原则引导的两步抽象和推理的STEP-BACK PROMPTING。顶部:一个高中物理MMLU的例子,其中通过抽象检索到了理想气体定律的第一原则。底部:一个来自TimeQA的例子,其中教育历史的高层次概念是抽象的结果。左边:PaLM-2L未能回答原始问题。Chain-of-Thought提示在中间推理步骤中遇到了错误(突出显示为红色)。右边:通过STEP-BACK PROMPTING,PaLM-2L成功地回答了问题。
在这两个例子中,提出一个更广泛的问题可以帮助模型有效地回答特定的查询。我们不必直接问“Estela Leopold在某个特定时间去了哪所学校”,而是可以询问“Estela Leopold的教育历史”。
这个更宽泛的主题涵盖了原始问题,并能提供所有必要的信息来推断“Estela Leopold在某个特定时间去了哪所学校。”值得注意的是,这些更宽泛的问题通常比原始的具体问题更容易回答。
从这种抽象中得出的推理有助于防止上图(左)中描述的“思维链”中的中间步骤出现错误。
总之,STEP-BACK PROMPTING涉及两个基本步骤:
抽象:最初,我们提示LLM提出关于高层次概念或原则的宽泛问题,而不是直接回应查询。然后,我们检索有关该概念或原则的相关事实。
推理:LLM可以根据关于高层次概念或原则的事实推断出原始问题的答案。我们称之为抽象推理。
Query2doc
Query2doc: Query Expansion with Large Language Models介绍了query2doc。它使用来自LLM的几个提示生成伪文档,然后将它们与原始查询结合,创建一个新的查询,如下面图所示:
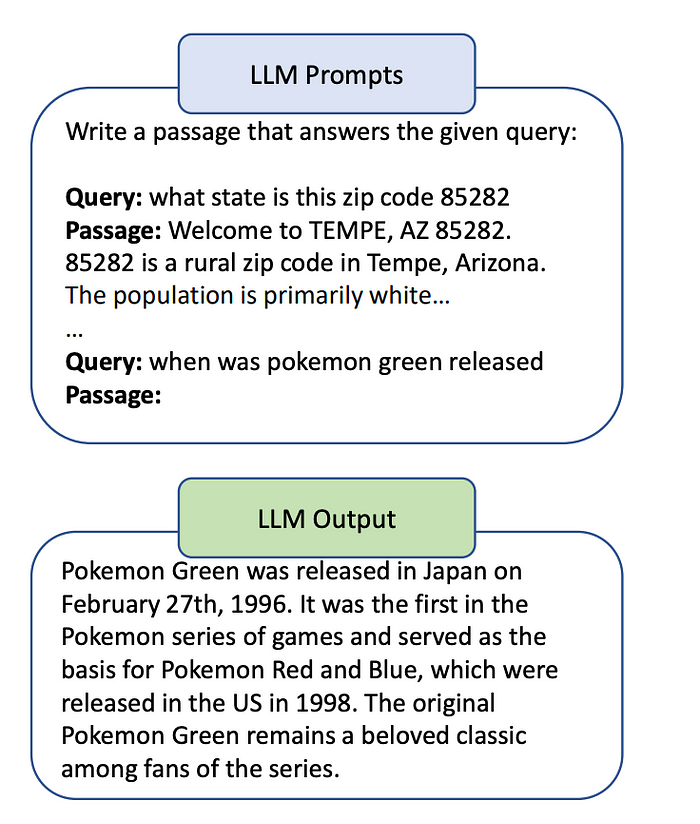
上图展示了query2doc的少量示例提示。出于空间原因,我们省略了一些上下文示例。
在密集检索中,新查询,标记为q+,是原始查询(q)和伪文档(d’)的简单串联,由[SEP]分隔:q+ = concat(q, [SEP], d’)
Query2doc认为,HyDE隐含地假设真实文档和伪文档用不同的词汇表达了相同的语义,这可能对某些查询不成立。
Query2doc与HyDE的另一个区别在于,Query2doc训练了一个监督的密集检索器,如论文中所述。
目前,在Langchain或LlamaIndex中尚未发现query2doc的复现。
ITER-RETGEN
ITER-RETGEN方法利用生成的内容指导检索。它在Retrieve-Read-Retrieve-Read流程中迭代实施“检索增强生成”和“生成增强检索”。

ITER-RETGEN迭代执行检索和生成。在每一次迭代中,ITER-RETGEN利用上一次迭代的模型输出作为特定的上下文,帮助检索更多相关知识,这可能有助于改善模型生成(例如,在此图中纠正Hesse Hogan的身高)。为了简洁起见,我们只在此图中展示了两次迭代。实心箭头连接查询与检索到的知识,虚线箭头表示检索增强生成。
如上图所示,对于给定的问题q和检索语料库D = {d},其中d代表一个段落,ITER-RETGEN连续执行T次检索生成。
在每次迭代t中,我们首先使用上一次迭代的生成yt-1,将其与q结合,检索出最相关的k个段落。接下来,我们提示LLMM生成一个输出yt,该输出将检索到的段落(表示为Dyt-1||q)和q融入提示中。因此,每一次迭代可以公式化如下:
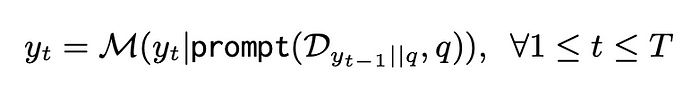
最后的输出yt将作为最终响应生成。
与Query2doc类似,目前在Langchain或LlamaIndex中尚未找到ITER-RETGEN的复现。
语义切片
在解析文档之后,我们可以获得结构化或半结构化的数据。当前的主要任务是将它们分解成更小的片段以提取详细特征,然后将这些特征嵌入以表示其语义。它在RAG中的位置如下面图所示。
最常见的切片方法是基于规则的,采用诸如固定切片大小或相邻切片重叠的技术。对于多级文档,我们可以使用Langchain提供d的RecursiveCharacterTextSplitter。这允许定义多级分隔符。
然而,在实际应用中,由于预定义规则的刚性(切片大小或重叠部分的大小),基于规则的切片方法很容易导致检索上下文不完整或包含噪声的切片大小过大的问题。
因此,对于切片,最优雅的方法显然是基于语义进行切片。语义切片旨在确保每个切片包含尽可能多的语义独立信息。
本文探讨了语义切片的方法,解释了它们的原理和应用。我们将介绍三种类型的方法:
基于嵌入的方法
基于模型的方法
基于LLM的方法
基于嵌入的方法
LlamaIndex和Langchain都提供了一种基于嵌入的语义切片器。算法的思想或多或少是相同的。
基于模型的方法
简单的BERT
回想BERT的预训练过程。设计了一个二元分类任务,Next Sentence Prediction(NSP),用来教会模型两个句子间的关系。这里,同时输入两个句子到BERT,模型预测第二个句子是否跟在第一个句子后面。
我们可以将这一原理应用于设计一个简单的切片方法。对于一个文档,将其分割成句子。然后,使用滑动窗口将两个相邻的句子输入到BERT模型中进行NSP判断,如下图所示:

如果预测得分低于预设阈值,表明这两句话之间存在较弱的语义关系。这可以作为文本的分割点,如上图中句子2和句子3之间的示例所示。
这种方法的优点是无需训练或微调即可直接使用。
然而,这种方法在确定文本分割点时只考虑前后句子,忽略了更远片段的信息。此外,该方法的预测效率相对较低。
跨段注意力
论文Text Segmentation by Cross Segment Attention提出了关于跨段注意力的三种模型,如下图所示:
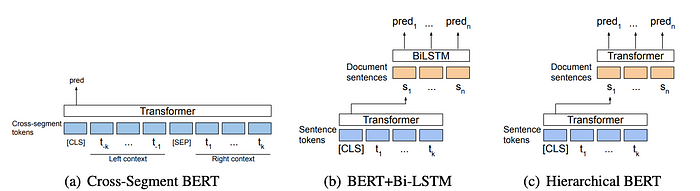
在跨段BERT模型(左图)中,我们向模型输入潜在段落分割点周围的局部上下文:左侧和右侧各k个token。在BERT+Bi-LSTM模型(中图)中,我们首先使用BERT模型对每个句子进行编码,然后将句子表示输入到Bi-LSTM中。在层次BERT模型(右图)中,我们首先使用BERT对每个句子进行编码,然后将输出的句子表示输入到另一个基于变换器的模型中。
上图(a)展示了跨段BERT模型,它将文本分割定义为逐句分类任务。潜在分割点的上下文(两侧的k个token)被输入到模型中。与[CLS]对应的隐藏状态被传递给softmax分类器,以决定在潜在分割点处是否进行分割。
论文还提出了另外两种模型。一种使用BERT模型获取每个句子的向量表示。然后,将多个连续句子的这些向量表示输入到Bi-LSTM(图(b))或另一个BERT(图©)中,以预测每个句子是否是文本分割边界。
当时,这三种模型达到了最先进的结果,如以下图所示
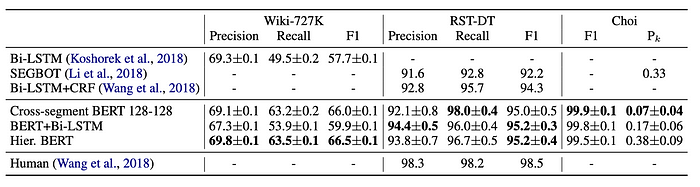
然而,到目前为止,只发现了这篇论文的训练实现。尚未发现可用于推断的公开模型。
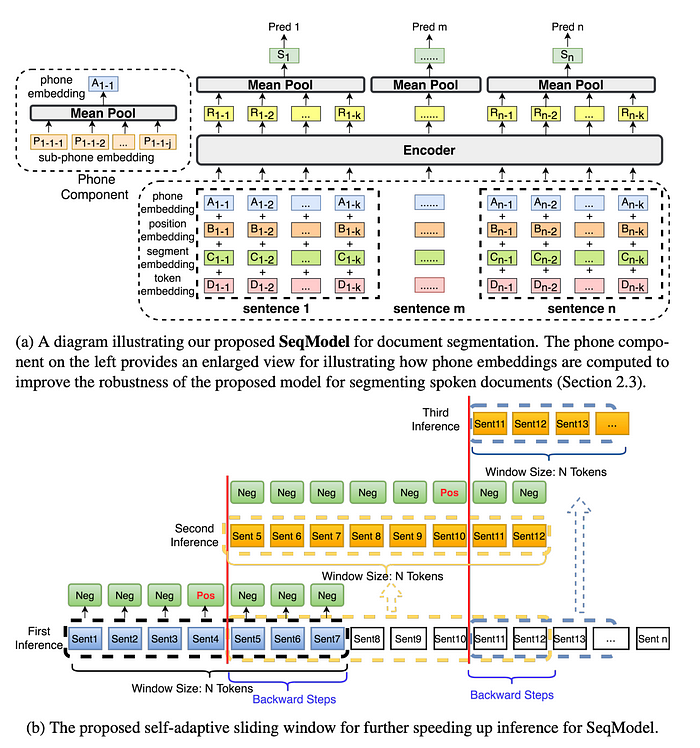
SeqModel
跨段模型独立向量化每个句子,没有考虑到更广泛的上下文信息。在SeqModel中提出了进一步的改进,详情请见论文“Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation”。
SeqModel使用BERT同时编码多个句子,先在计算句子向量之前建模更长上下文内的依赖关系。然后预测每句话后是否进行文本分割。此外,该模型利用自适应滑动窗方法来提高推断速度,而不牺牲准确性。SeqModel的示意图如以下图所示:
基于LLM的方法
论文Dense X Retrieval: What Retrieval Granularity Should We Use?引入了一种新的检索单元,称为命题。命题被定义为文本中的原子表达,每个都封装了一个独特的事实,并以简洁、自包含的自然语言格式呈现。
那么,我们如何获得这种所谓的命题呢?在论文中,这是通过构建提示和与LLM交互实现的。
LlamaIndex和Langchain都已经实现了相关的算法,以下演示使用LlamaIndex。
总的来说,使用LLM构建命题的这种切片方法已经实现了更精细的切片。它与原始节点形成了一种从小到大的索引结构,从而为语义切片提供了一种新思路。
然而,这种方法依赖于LLM,成本相对较高。
如果条件允许,可以持续关注并监控基于LLM的方法。
数据修改
增强检索双重指导调优(RA-DIT)和RECITation增强生成(RECITE)强调通过内部数据修改进行增强。
RA-DIT区分了LLM和检索器的微调数据集,旨在加强LLM的情境理解能力和检索器与查询的对齐能力。
而RECITE则利用段落提示和合成的问题-段落对来增加其生成的背诵和响应的多样性和相关性。这种方法旨在扩大模型的知识库并提高其响应的准确性。
改进零样本评估的通用提示检索(UPRISE)和生成而非检索(GENREAD)针对外部数据的精炼。
UPRISE将原始任务数据转换为结构化格式,并细化提示的选择,以改善检索结果。
相比之下,GENREAD使用的基于聚类的提示方法从问题生成文档并将它们聚类以消除无关数据,用各种上下文洞察丰富输入。这种技术旨在通过提供更丰富的信息集来提升生成模型的性能。
此外,KnowledGPT致力于通过实体链接在原始文本数据中添加结构化、语义丰富的信息。这个丰富过程不仅使数据结构更加紧密,使其更容易接受查询,而且提高了模型的检索效率。它利用精确的链接知识来增强模型的理解力及其生成相关响应的能力,从而改善其整体表现。
查询路由
查询路由是LLM驱动决策的关键步骤,根据用户查询决定下一步行动——选项通常包括总结、执行针对某些数据索引的搜索,或尝试多种不同路径,然后将输出综合为单一答案。
查询路由器也用于选择索引,或者更广泛地说,选择要发送用户查询的数据存储——无论是我们有多个数据源,例如,经典的向量存储和图形数据库或关系数据库,还是我们有一个索引层次结构——对于多文档存储,一个相当典型的案例是一个摘要索引和另一个文档片段向量的索引。
定义查询路由器包括设置它可以做出的选择。路由选项的选择是通过LLM调用完成的,返回的结果以预定义的格式用于将查询路由到给定索引,或者,如果我们正在谈论同族行为,到子链或甚至其他代理,如下图的\多文档代理方案所示。
LlamaIndex和LangChain都支持查询路由器。
检索技术
融合检索/混合搜索
这是一个相对较老的想法,即结合两全其美——传统的基于关键词的旧式搜索——像tf-idf这样的稀疏检索算法,或是搜索行业标准的BM25——以及现代的语义或向量搜索,并将它们在一个检索结果中结合起来。唯一的技巧在于正确地组合具有不同相似度分数的检索结果——这个问题通常借助互惠排名融合算法解决,重新排序检索结果以供最终输出。
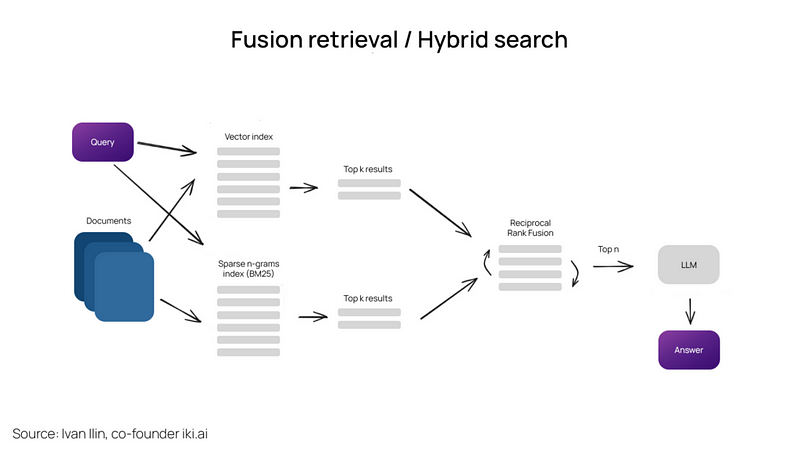
在LangChain中,这是通过Ensemble Retriever类实现的,它结合了我们定义的一系列检索器,例如faiss向量索引和基于BM25的检索器,并使用RRF进行重新排序。
在LlamaIndex中,这是以非常类似的方式完成的。
混合或融合搜索通常能提供更好的检索结果,因为结合了两种互补的搜索算法,同时考虑了查询与存储文档之间的语义相似性和关键词匹配。
后检索技术
提示压缩
RAG流程可能会遇到两个问题:
大型语言模型(LLM)通常具有上下文长度限制。因此,输入文本越长,处理过程就越耗时且成本越高。
检索到的上下文并不总是有用的。可能存在较大的片段中只有小部分与答案相关。在某些情况下,可能需要结合多个片段来回答特定问题。即使进行了重新排序,这个问题仍然存在。
LLM的提示压缩是一种解决这些问题的方法。本质上,目标是从提示中保留关键信息,使输入标记更具价值。这种方法提高了模型的性能并降低了成本。正如下图右下角所示。
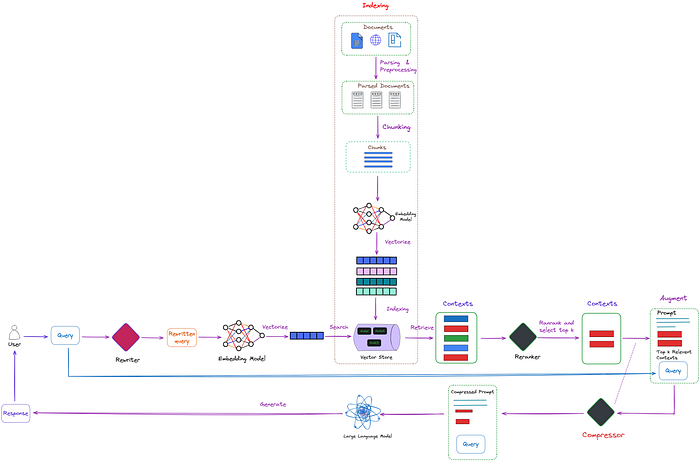
RAG中的提示压缩(右下角)。如紫色虚线所示,一些压缩器也可以直接应用于检索到的上下文中
值得注意的是,如上图中的紫色虚线所示,一些压缩器也可以直接应用于检索到的上下文中。
总体而言,提示压缩方法可以分为四大类:
基于信息熵的方法,如Selective Context,LLMLingua,LongLLMLingua。这些方法使用小型语言模型来计算原始提示中每个令牌的自信息或困惑度。然后删除困惑度较低的令牌。
基于软提示调优的方法,如AutoCompressor和GIST。这些方法需要对LLM参数进行微调以适应特定领域,但不能直接应用于黑盒LLM。
首先,从LLM进行数据蒸馏,然后训练模型生成更具可解释性的文本摘要。这些可以在不同的语言模型之间转移,并应用于不需要梯度更新的黑盒LLM。代表性方法有LLMLingua-2和RECOMP。
基于令牌合并或令牌剪枝的方法,如ToMe和AdapLeR。这些方法通常需要模型微调或在推理过程中生成中间结果。
鉴于第四种类型的方法最初是为ViT或BERT等较小的模型提出的,本文将介绍前三类方法中代表性算法的原理。
选择上下文
下图展示了LLM无需完整上下文或全部对话历史即可响应用户查询。即使省略了相关信息,LLM仍能产生预期的响应。这可能归因于LLM从上下文线索和预训练期间获得的先验知识中推断缺失信息的能力。

因此,有可能通过过滤掉较少信息含量的内容来优化上下文长度,而不会影响性能。这是Selective Context的关键洞见。
Selective Context使用小型语言模型(SLM)来确定给定上下文中词汇单元(如句子、短语或令牌)的自信息。然后,它利用这些自信息来评估它们的信息量。通过有选择地保留自信息较高的内容,Selective Context为LLM提供了更精简、更高效的上下文表示,而不会影响它们在不同任务上的表现。
LLMLingua
LLMLingua指出,Selective Context常常忽视了压缩内容间的相互联系以及LLM与用于提示压缩的小型语言模型之间的关联。LLMLingua正是针对这些问题提出了精确解决方案。
具体来说,如下面的图所示,LLMLingua使用预算控制器来动态分配不同的压缩比例给原始提示的不同组件,如指令、演示和问题。它还进行粗粒度、演示级别的压缩,以保持高压缩比下的语义完整性。此外,LLMLingua引入了token级迭代算法,用于细粒度的提示压缩。
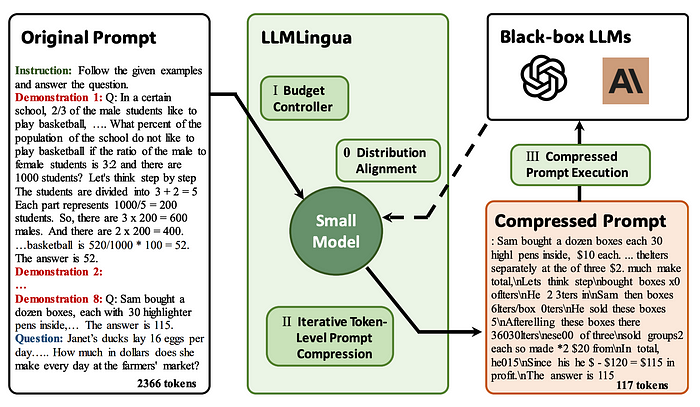
与Selective Context相比,LLMLingua在考虑token之间的条件依赖关系的同时,能更有效地保留提示中的关键信息。它可以将提示压缩20倍。
迭代token级提示压缩(ITPC)
使用困惑度进行提示压缩存在一个固有限制:独立性假设。这个假设将提示中的每个token视为独立的。换句话说,一个token出现的概率只依赖于前一个token,与其他token无关。
这一假设的问题在于,它忽略了自然语言中token之间通常存在的复杂依赖关系,这些依赖关系对于理解上下文和保持语义完整性至关重要。
这种忽略可能导致在压缩过程中丢失关键信息。例如,在高压缩比的情况下,如果一个令牌在上下文中提供了关键的推理步骤或逻辑连接,仅仅根据其困惑度来决定是否保留这个token可能会导致推理过程的不完整。
为了解决这个问题,LLMLingua引入了迭代token级提示压缩(ITPC)算法。这种方法不再仅仅依赖于token的独立概率,而是在提示压缩过程中更精确地评估每个token的重要性。它通过迭代处理提示中的每个片段,并考虑当前上下文中每个token的条件概率,从而有助于更好地保留token之间的依赖关系。
下图详细展示了ITPC的步骤:
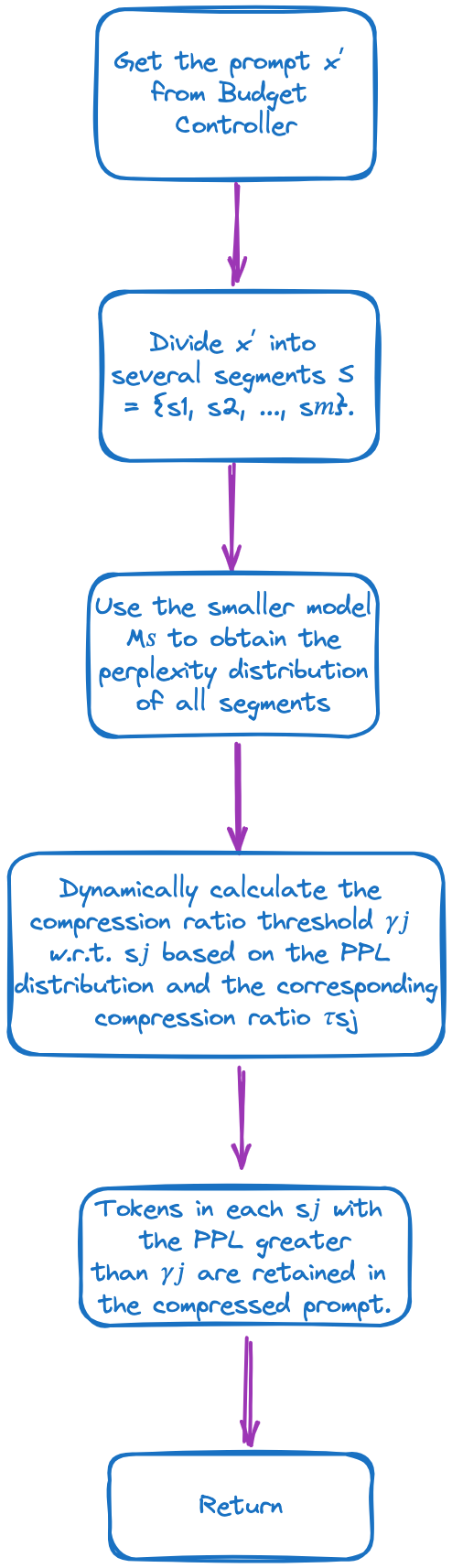
通过这一过程,ITPC算法能够在保持提示语义完整性的前提下有效压缩提示的长度,从而降低LLM的推理成本。
指令调优
上图(提出的LLMLingua方法框架)展示了指令调优也是LLMLingua中的一个关键步骤。其目的是最小化用于压缩提示的小型语言模型与LLM之间的分布差异。
下图展示了指令调优的步骤:
LongLLMLingua
LLMLingua 的问题在于,在压缩过程中没有考虑到用户的提问,这可能导致保留了一些无关紧要的信息。
LongLLMLingua着眼于解决这一问题,通过在压缩过程中融入用户的提问来优化处理。
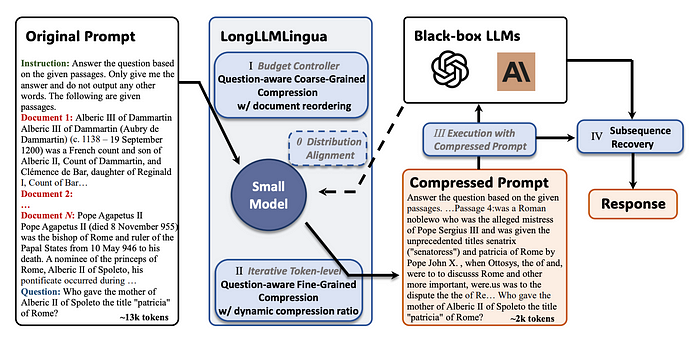
正如上图所示,LongLLMLingua提出四个新组件来增强LLMs对关键信息的感知:
问题意识的粗粒度和细粒度压缩
文档重排序机制
动态压缩比
子序列恢复算法
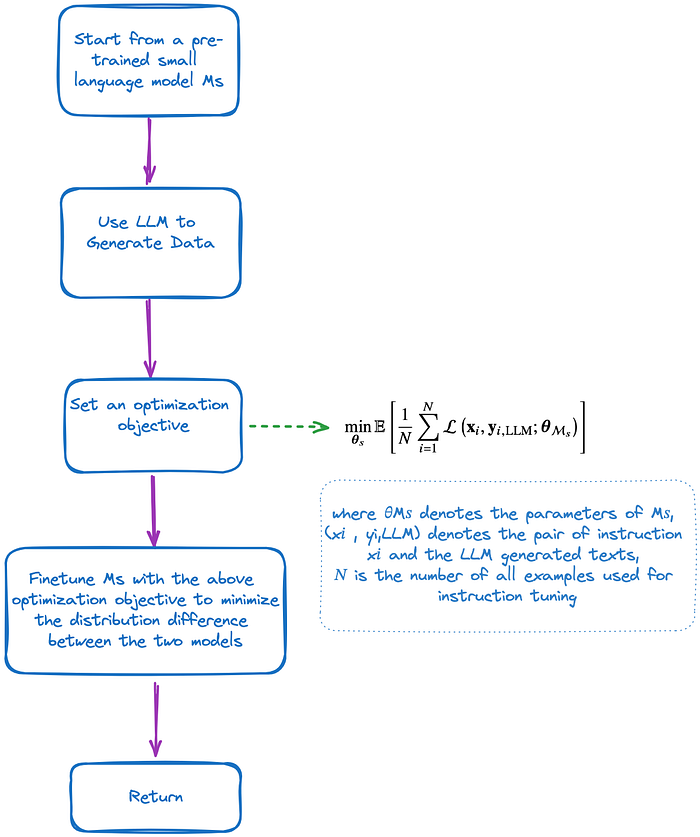
AutoCompressor
与前述方法不同,AutoCompressor采用了一种基于软提示(soft prompt)的方法。
它通过扩展词汇表并利用“摘要token”和“摘要向量”,智能地微调现有模型,高效地浓缩上下文信息,从而实现对文本内容的有效压缩而不损失核心意义。
上方的图表呈现了AutoCompressor的架构,其运行步骤如下:
扩充词汇:这个步骤涉及向模型现有的词汇中加入“摘要token”。这些token让模型有能力将大量的信息浓缩进较小的向量中。
分割文档:将待处理的文档划分为若干小段,每段末尾附加上摘要token。这些token同时携带了前面段落的摘要信息,形成了摘要累积的效果。
微调训练:采用无监督训练法,利用“下一个词预测”的任务来对模型进行微调。该任务的目标是基于当前词之前的词和当前段落之前各段落的摘要向量,预测下一个词。
反向传播:AutoCompressor使用时间反向传播(BPTT)和梯度检查点技术对每个段落进行操作,以减少计算图的规模。对整个文档进行反向传播,使得模型能够学习到完整上下文的关联性。
LLMLingua-2
LLMLingua-2指出,依据因果语言模型(如LLaMa-7B)通过删除token或词汇单位来压缩提示时存在以下两个问题:
用于确定信息熵的小型语言模型与提示压缩的目标并不一致。
它仅利用了单向上下文,可能无法涵盖提示压缩所需的所有信息。
这些问题的核心在于,信息熵可能并非压缩效果的最佳衡量标准。
下图展示了LLMLingua-2的整体架构:
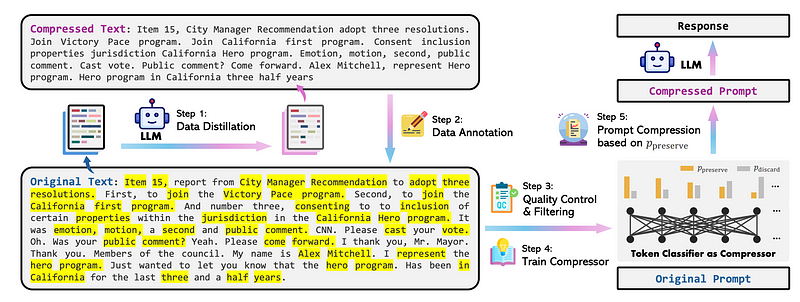
为了解决第一个问题,LLMLingua-2引入了数据蒸馏过程。这一过程从大型语言模型中提炼知识,压缩提示而不丢失关键信息。同时,它构建了一个提取式文本压缩数据集。在该数据集上的训练有助于使小型语言模型在提示压缩上有效对齐。
针对第二个问题,LLMLingua-2将提示压缩视为一个token分类问题。这种做法确保了压缩后的提示对原始提示的保真度。它使用变压器编码器作为基础架构,从完整的双向上下文中捕捉所有必要的信息,用于提示压缩。
RECOMP (检索、压缩、前置)
RECOMP引入了两类经过训练的压缩器:抽取式和抽象式。抽取式压缩器从检索到的文档中挑选有用句子,而抽象式压缩器则综合多文档信息生成摘要。
下方图表显示了压缩器在RECOMP中的位置。
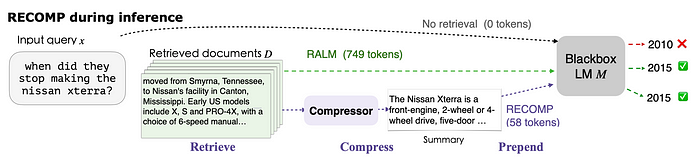
抽取式压缩器
对于输入文档集中的n个句子[s1, s2, …, sn],我们训练一个双编码器模型。此模型将句子si和输入序列x嵌入固定维度的表示中。这些表示的内积指示了将si添加到输入x中以生成目标输出序列对大型语言模型的好处。
压缩器产生的最终摘要s由内积排名前N的句子组成。
抽象式压缩器
抽象式压缩器是一个编码器-解码器模型。它接受输入序列x和检索到的文档集合的拼接,并输出一个摘要s。
该方法涉及使用大型语言模型(如GPT-3)生成训练数据集,过滤这些数据,然后使用过滤后的数据集训练编码器-解码器模型。
在讨论的方法中,LongLLMLingua可能是更优的选择。我们已经在研究项目中实现了它。此外,也可以尝试LLMLingua-2,它在速度和内存使用方面具有优势。
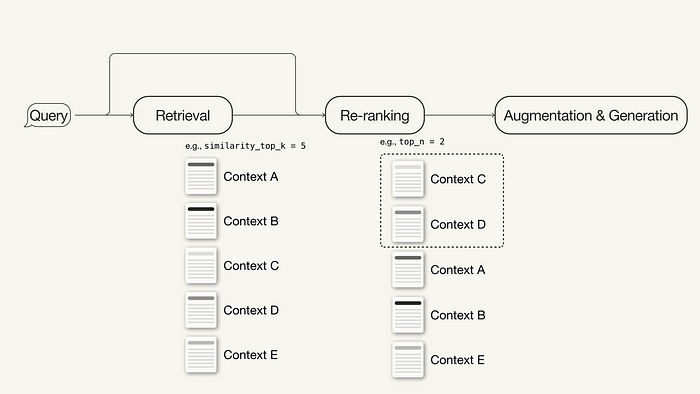
再排序
再排序在检索增强生成(RAG)过程中扮演着关键角色。在简单的RAG方法中,可能会检索出大量上下文,但并非所有上下文都一定与问题相关。再排序允许重新排序和筛选文档,将相关文档置于前列,从而提高RAG的有效性。
再排序介绍
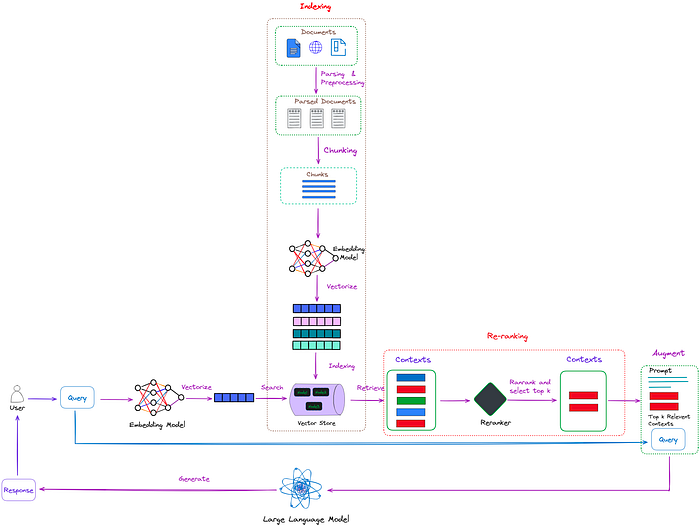
如上图所示,再排序的任务就像是一个智能过滤器。当检索器从索引集合中检索出多个上下文时,这些上下文对用户查询的相关性可能各不相同。有些上下文可能高度相关(红色框高亮),而其他一些可能只是略微相关甚至完全不相关(绿色和蓝色框高亮)。
再排序的任务就是评估这些上下文的相关性,并优先考虑那些最有可能提供准确且相关答案的上下文。这使得大型语言模型在生成答案时可以优先考虑这些排名靠前的上下文,从而提高响应的准确性和质量。
简单来说,再排序就像在开卷考试中帮助我们从一堆学习资料中选择最相关的参考材料,以便我们能够更高效、更准确地回答问题。
本文描述的再排序方法主要可以分为以下两类:
再排序模型:这类模型考虑文档和查询之间的交互特征,以更准确地评估它们的相关性。
大型语言模型(LLM):LLM的出现为再排序开辟了新的可能性。通过全面理解整个文档和查询,可以更全面地捕捉语义信息。
使用再排序模型作为再排序器
与嵌入模型不同,再排序模型将查询和上下文作为输入,直接输出相似度得分而非嵌入向量。值得注意的是,再排序模型是通过交叉熵损失进行优化的,这意味着相关性得分不限于某一特定范围,甚至可以是负数。
目前可用的再排序模型并不多。一种选择是Cohere提供的在线模型,可以通过API访问。还有开源模型,如bge-reranker-base和bge-reranker-large等。
下方图表展示了使用命中率(Hit Rate)和平均倒排秩(Mean Reciprocal Rank, MRR)指标的评估结果:

从这一评估结果我们可以看出:
无论使用哪种嵌入模型,再排序均展现出更高的命中率和MRR值,表明再排序环节的重要影响。
目前,表现最佳的再排序模型是Cohere,不过它是一项付费服务。开源的bge-reranker-large模型具备与Cohere相仿的能力。
嵌入模型与再排序模型的组合也可能产生影响,因此开发者可能需要在其实际流程中尝试不同的组合。
使用LLM作为再排序器
涉及LLM的现有再排序方法大致可归为三类:使用再排序任务对LLM进行微调、引导LLM进行再排序、以及在训练期间使用LLM进行数据增强。
引导LLM进行再排序的方法成本较低。以下是使用RankGPT的一个示例,它已被集成到LlamaIndex。
RankGPT的理念是使用LLM(如ChatGPT、GPT-4或其他LLM)进行零样本列表式段落再排序。它应用了排列生成策略和滑动窗口策略,以高效地对段落进行再排序。
如下方图表所示,论文提出了三种可行的方法。

利用LLM进行零样本段落再排序的三种指令类型。灰色和黄色块分别表示模型的输入和输出。(a)查询生成依赖于LLM的日志概率,根据段落生成查询。(b)相关性生成指导LLM输出相关性判断。(c)排列生成对一组段落生成排序列表。
前两种方法属于传统方式,其中,对每份文档给出一个分数,随后根据这一分数对所有段落进行排序。
第三种方法,即排列生成,是在本论文中提出的。具体而言,这种方法不依赖于外部评分,而是直接对段落进行端到端的排序。换言之,它直接利用LLM的语义理解能力对所有候选段落进行相关性排序。
然而,通常候选文档的数量非常庞大,而LLM的输入是有限的。因此,往往无法一次性输入所有文本。为解决这一问题,论文中提出了一种滑动窗口策略。通过将候选段落分组,每次只处理一小批段落,从而降低单次处理的文本量。这种方法不仅解决了输入限制问题,还提高了处理效率,使得大规模文档集的再排序成为可能。
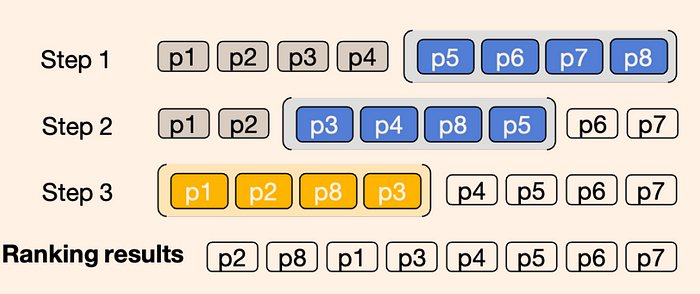
利用滑动窗口进行段落再排序的示意图,窗口大小为4,步长为2,对8个段落进行再排序。蓝色代表前两个窗口,黄色代表最后一个窗口。滑动窗口按从后向前的顺序应用,意味着前一个窗口的前2个段落将参与下一个窗口的再排序。
因此,如上图所示,引入了一种滑动窗口方法,其理念类似于冒泡排序。每次仅对前4个文本进行排序,然后移动窗口,对接下来的4个文本进行排序。遍历完整个文本后,我们可以得到表现最优的顶部文本。
过滤
知识链(COK)介绍了渐进式理由修正技术,旨在通过检索到的知识迭代优化理由。这种方法构成了一种持续优化过程,显著提升了用于内容生成的信息的相关性和质量。
Self-RAG引入了一种自我反思机制,以高效地过滤掉不相关的内容。通过运用批判性token,这种方法评估了检索到的段落的相关性、支持性和实用性,确保只有高质量信息被整合到内容生成的过程中。
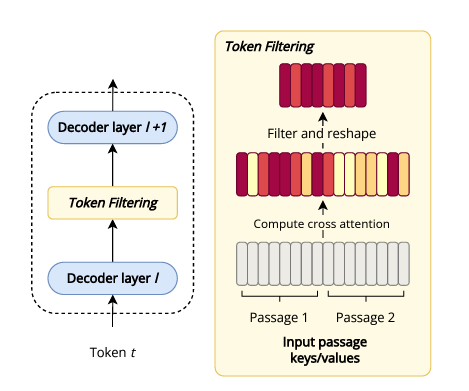
我们的Token过滤方法概览。在此,将两个段落视作解码器模块的输入。在生成token t时,在解码层l和l+1之间执行Token过滤操作。利用第l层的token t表示,计算所有输入token的交叉注意力。接着,从输入中筛选掉排名最低的token(标记为黄色),仅使用排名最高的输入token来生成后续的每一个token。
此外,结合Token过滤的解码器融合(FiD-TF)(上图)和RECOMP致力于从检索到的文档中剔除不相关或冗余的token和信息。FiD-TF采用动态机制识别并剔除不必要的token,从而提高信息处理的效率。相比之下,RECOMP将文档压缩成精简的摘要,专注于选择最相关的内容用于生成过程。这些方法通过确保仅使用相关和支持性的信息,简化了内容生成的工作流程,从而提升生成内容的整体质量和相关性。
Self-RAG
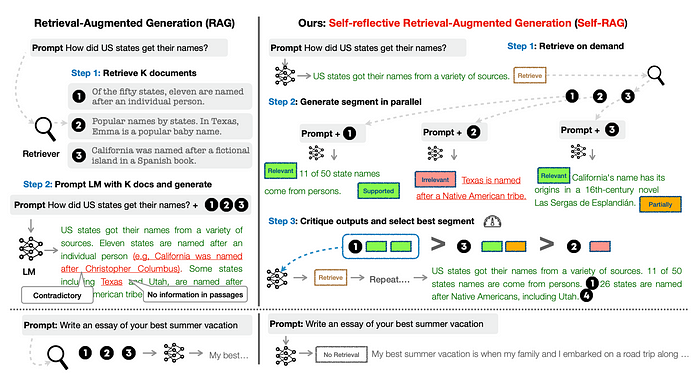
让我们考虑一个常见的场景:参加开卷考试。我们通常有两种策略:
方法1:对于熟悉的话题,迅速作答;对于不熟悉的话题,打开参考书查找,快速定位相关内容,在心中整理归纳,然后在试卷上作答。
方法2:对于每一个话题,都查阅书籍。找到相关章节,在心里整理归纳,然后在试卷上写下我们的答案。
显然,方法1是更优选的。方法2可能耗时,且容易引入不相关或错误的信息,这可能导致混淆和错误,甚至在原本理解的领域也会出错。
然而,方法2正是经典RAG流程的体现,而方法1代表了self-RAG流程,这也是本文将进一步探讨的内容。
下方图表对比了RAG和self-RAG主要流程:
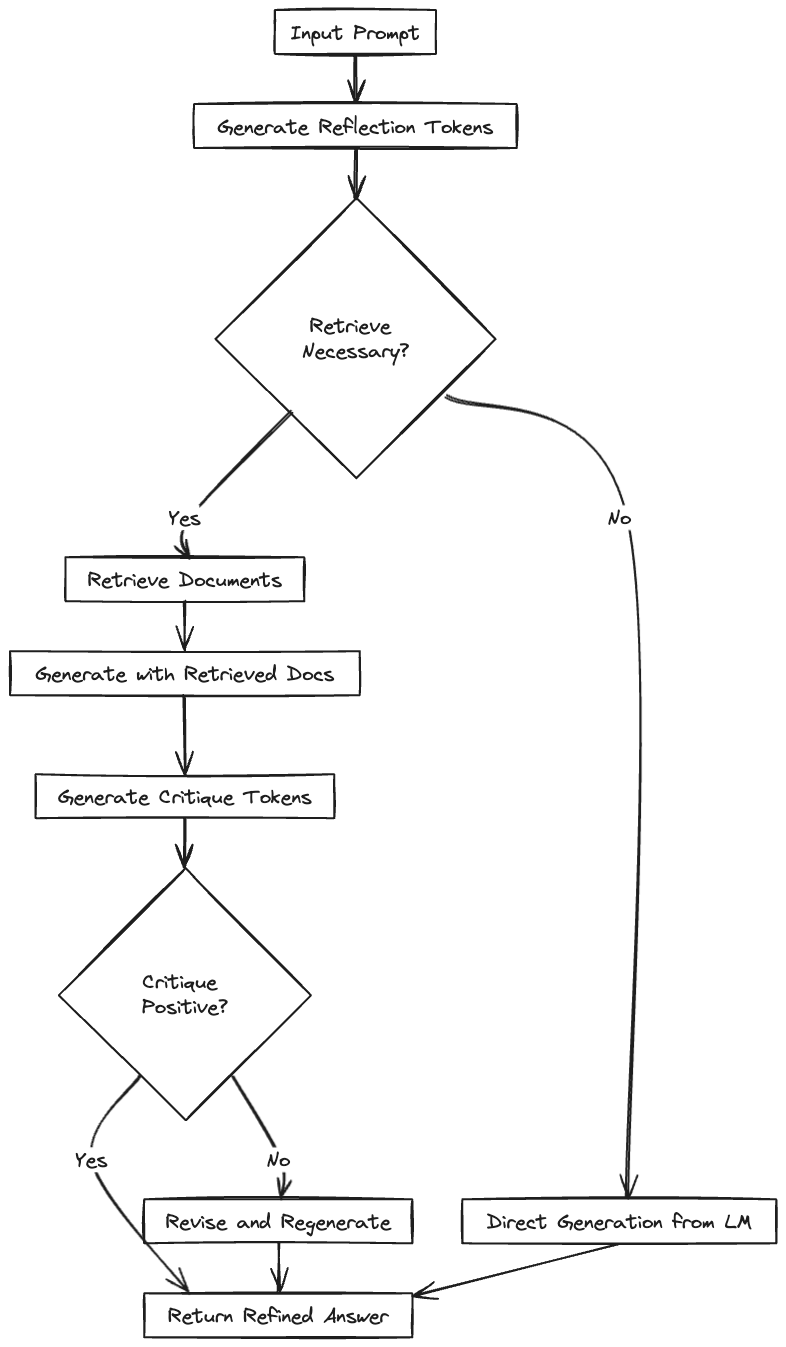
Self-RAG包含三个步骤:
按需检索:当模型需要检索时,例如面对“美国各州名称是如何得来的?”这样的查询(上图右上角),模型的输出将包含一个
[Retrieve]token。这表明需要检索与查询相关的内容。相反,当要求写一篇“关于我最好的暑假的文章”(上图右下角)时,模型选择直接生成答案,无需检索。并行生成:模型利用提示和检索到的内容生成输出。在整个过程中,三种类型的反思令牌指示检索内容的相关性。
评估与选择:对第二步中生成的内容进行评估,并选择最佳段落作为输出。
修正RAG
考虑一个常见的情景:参加开卷考试。通常,我们有三种策略:
方法1:对熟悉的话题,迅速作答。对于不熟悉的话题,查阅参考书。快速定位相关章节,心中整理归纳,然后在试卷上写出答案。
方法2:对每一个话题,都翻阅书籍。找到相关章节,在心中总结,然后在试卷上写下我们的回答。
方法3:对每一个话题,查阅书籍并找到相关章节。在形成观点前,将收集到的信息分为三类:
正确、错误和模糊。分别处理每种类型的信息。然后,基于处理过的信息,在心中整理汇总。在试卷上写出我们的回答。
方法1涉及self-RAG,而方法2则是经典RAG流程。
最后,方法3,即Corrective Retrieval Augmented Generation (CRAG),是本文将要介绍的内容。
CRAG的动机
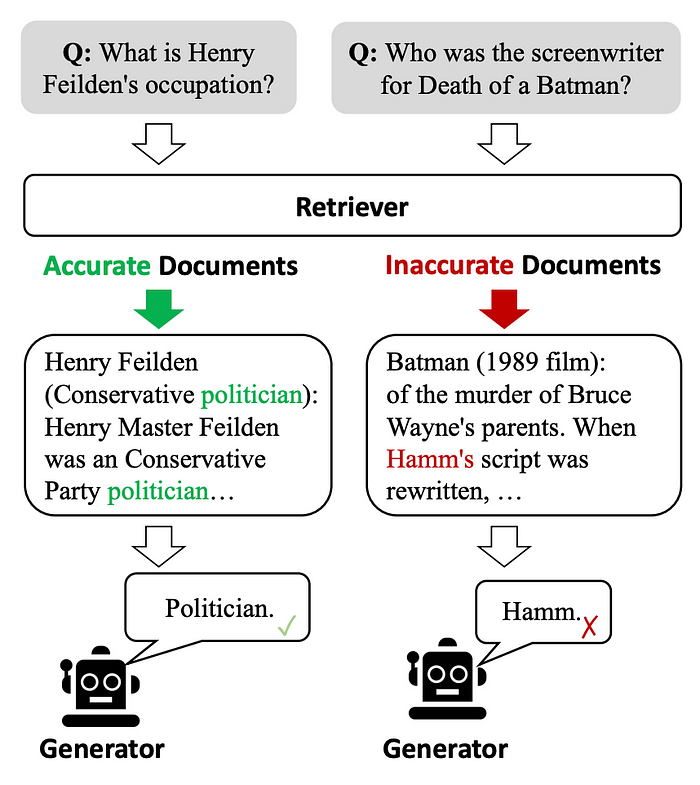
示例说明,低质量的检索器倾向于引入大量不相关信息,阻碍生成器获取准确知识,甚至可能误导生成器。
上方图表说明,大多数传统的RAG方法并未考虑文档与问题的相关性,仅仅是合并检索到的文档。这可能引入不相关信息,阻碍模型获得准确知识,甚至误导模型,导致幻觉问题的出现。
此外,大多数传统的RAG方法将检索到的整篇文档作为输入。然而,这些检索到的文档中的大量文本对于生成而言往往是不必要的,不应同等程度地参与到RAG中。
CRAG的核心理念
CRAG设计了一个轻量级的检索评估器,用于评估针对特定查询检索到的文档的整体质量。它还利用网络搜索作为辅助工具,以改善检索结果。
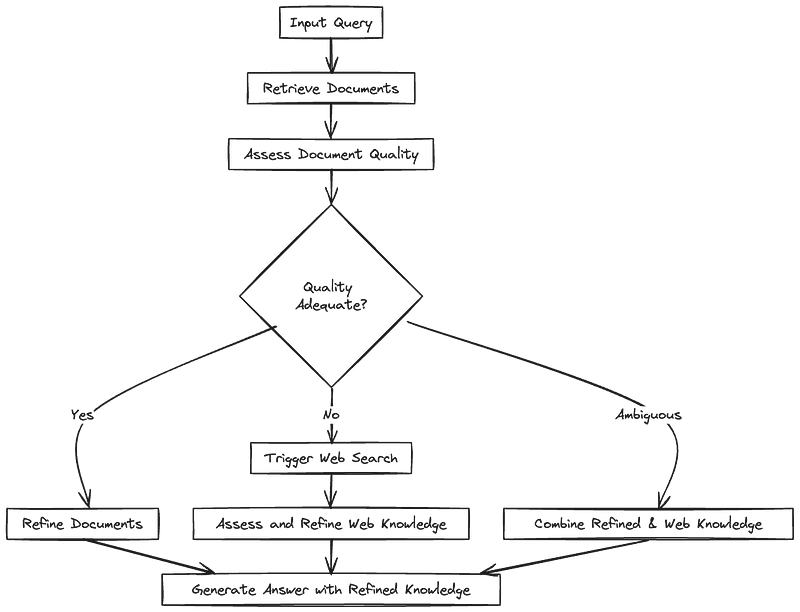
CRAG具有即插即用的特点,能够无缝集成到基于RAG的各种方法中。整体架构如下方图表所示。
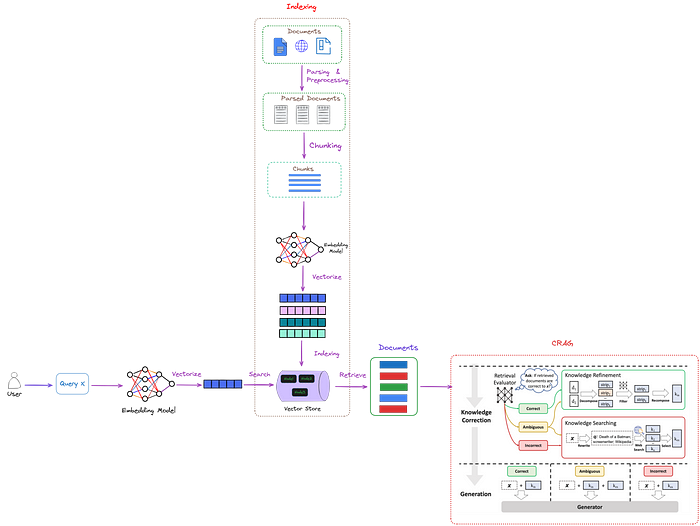
CRAG在RAG中的位置(红色虚线框)。设计了一个检索评估器来评估检索到的文档与输入的相关性。它还估计了一个置信度水平,这可以触发不同的知识检索行为,即{Correct, Incorrect, Ambiguous}。此处,“x”代表查询。
如上图所示,CRAG通过引入检索评估器来评估检索到的文档与查询之间的关系,从而增强了传统的RAG。
有3种可能的判断结果。
如果判断为
correct,这意味着检索到的文档包含了查询所要求的必要内容,那么采用知识精炼算法对检索到的文档进行改写。如果检索到的文档被判定为
incorrect,这意味着查询与检索到的文档不相关。因此,我们不能将文档发送给LLM。在CRAG中,使用网络搜索引擎来检索外部知识。对于
ambiguous的情况,这意味着检索到的文档可能接近但不足以提供答案。在这种情况下,需要通过网络搜索获取额外信息。因此,知识精炼算法和搜索引擎都会被使用。
最后,处理过的信息被传递给LLM以生成响应。下方图表正式描绘了这一过程。

需要注意的是,网络搜索并不直接使用用户的输入查询进行搜索。相反,它构建一个提示,以少量示例的方式呈现给GPT-3.5 Turbo,以获取用于搜索的查询。
CRAG与self-RAG的区别:
从流程角度来看,self-RAG可以使用LLM直接响应,无需检索,而CRAG必须先进行检索,然后再添加一层评估。
从结构上看,self-RAG比CRAG更为复杂,它要求更复杂的训练过程和在生成阶段的多重标签生成与评估,不可避免地增加了推理成本。因此,CRAG相比self-RAG更加轻量化。
性能方面,如下方图表所示,CRAG在大多数情况下普遍优于self-RAG。这表明CRAG在处理检索信息的质量控制和准确性上具有优势,尤其是在处理模糊或错误信息时,CRAG能够更有效地进行纠正和优化。
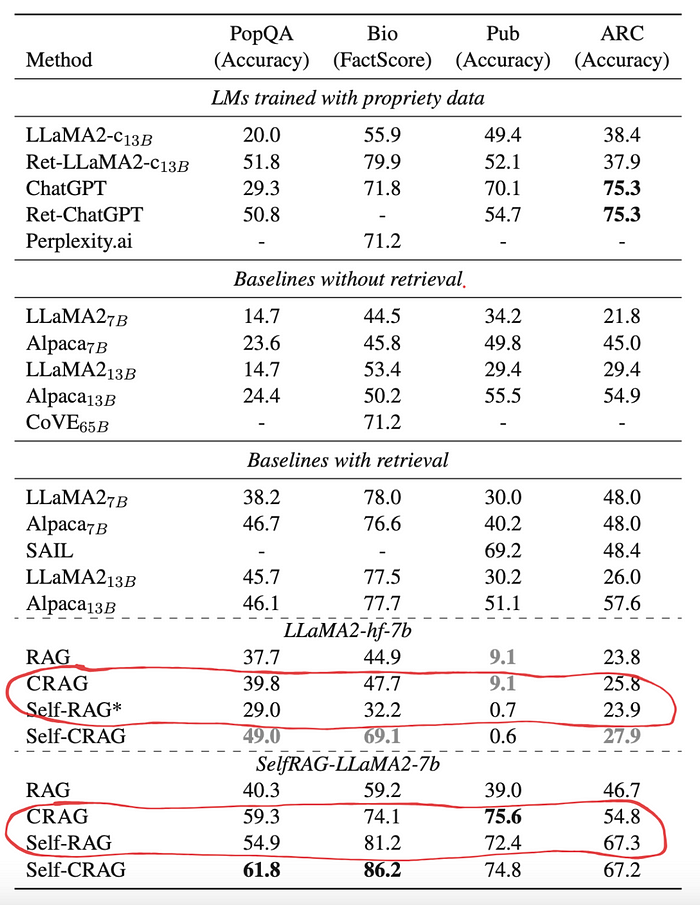
四个数据集测试集上的总体评估结果。结果依据生成的LLMs进行分类。粗体数字表示在所有方法和LLMs中最佳的表现。灰色粗体分数表示使用特定LLM时的最佳表现。* 表示由CRAG复现的结果,否则除了我们的结果外,其余结果引用自原始论文。
检索评估器的改进
检索评估器可以被视为一个评分分类模型。这个模型用于确定查询和文档的相关性,类似于RAG中的再排序模型。
此类相关性判断模型可以通过整合更多符合现实场景的特征来改进。例如,科学论文问答的RAG包含许多专业术语,而旅游领域的RAG则倾向于有更多的口语化用户查询。
通过在检索评估器的训练数据中加入场景特征,它可以更好地评估检索到的文档的相关性。其他特征,如用户意图和编辑距离,也可以被纳入,如下方图表所示:
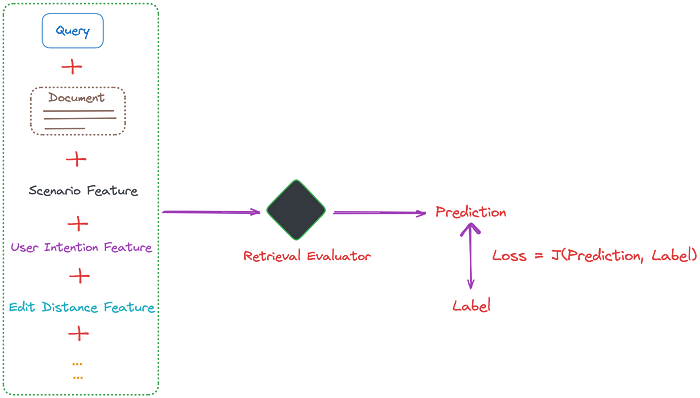
此外,考虑到T5-Large取得的结果,轻量级模型似乎也能达到不错的效果。这为小规模团队或公司在应用CRAG上带来了希望。
检索评估器的得分和阈值
正如前面所述,阈值因不同种类的数据而异。而且,我们可以发现ambiguous和incorrect的阈值基本上在-0.9左右,这表明检索到的知识大多与查询相关。完全抛弃这些检索到的知识,仅仅依赖网络搜索可能并非明智之举。
RAG融合
RAG-Fusion首先使用大型语言模型生成多个衍生查询。这一步骤扩展了对初始用户输入的理解,确保了从多角度全面探索查询主题。接下来,向量搜索为原始查询及其衍生查询找到相关文档,汇编了一系列相关的信息。
在文档检索之后,Reciprocal Rank Fusion(RRF)算法根据相关性重新排序这些文档。这些文档随后被整合成一个全面且相关的信息源。
在最后阶段,这个综合数据集及所有查询都被大型语言模型处理。模型将这些输入综合,创造出条理清晰、与上下文相关性强的回应。通过这一系统性的方法,RAG-Fusion提升了回应的准确性和全面性,显著提高了对用户查询回答的质量。
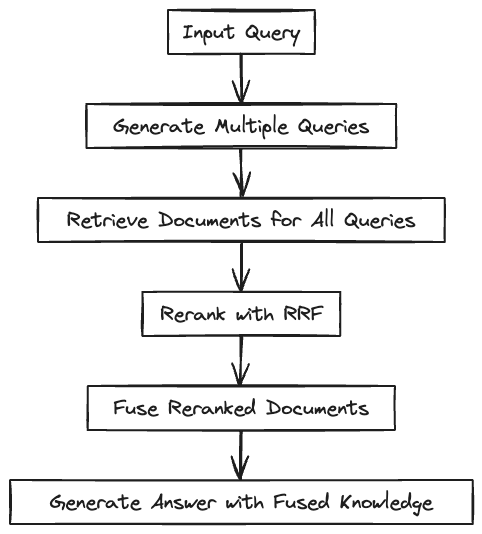
让我们总结并并列比较这三种方法:
生成技术
增强
展示-搜索-预测(DSP)引入了一个框架,旨在生成多个检索查询以汇总和回答问题,从多个段落中聚合信息。该框架利用多种搜索组合(CombSUM)计算不同检索列表中段落的累积概率得分,从而从多个来源汇编全面的响应。
可插拔奖励驱动上下文适配器(PRCA)描述了一个奖励驱动阶段,其中,基于生成器的反馈细化蒸馏上下文。通过强化学习,此阶段根据提供相关上下文所获得的奖励调整PRCA的参数。目标是微调提取的上下文,以满足生成器的具体需求,从而优化生成过程。
检索并插入(REPLUG)提出了一种方法,在黑盒LM进行最终预测之前,将检索到的文档附加到输入上下文中。它引入了一种集成策略,以并行编码检索到的文档,克服了LM上下文长度的限制,并通过分配更多计算资源提高了准确性。这种方法通过确保LM能够访问更广泛的相关信息,改进了生成过程。
RECITE实施了一种自一致性技术,涉及独立生成多个复述,并采用多数投票系统确定最合适的答案。这种方法旨在提高答案的可靠性和准确性,从而提高输出的质量和可信度。
定制
参数化知识引导(PKG)框架代表了一种定制LM输出的方法。通过使用预训练模型内部生成背景知识,PKG消除了对传统外部检索过程的需求。这种方法直接在生成步骤中整合领域或任务特定知识,显著增强了LM产生针对特定上下文或需求量身定制的响应的能力。
Self-RAG提供了一种策略,即在可定制的解码算法中融入反思令牌。这种技术允许根据特定任务动态调整模型的检索和生成行为,促进更灵活的响应生成。根据需求,这种方法可以在准确性或创造性之间进行调整,提供生成满足多样化需求的输出的灵活性。
子图检索增强生成(SURGE)通过应用图-文本对比学习实现了定制。该方法确保生成的对话响应与检索到的子图中包含的知识紧密对齐,产生具体、相关且深深植根于对话上下文的响应。通过保持检索到的知识和生成文本之间的一致性,SURGE能够产生精确反映子图详细知识的输出,增强了响应的相关性和特定性。
聊天引擎
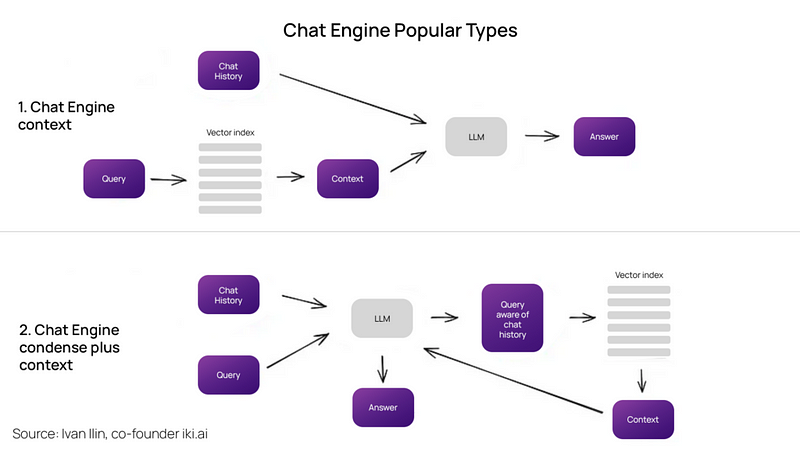
构建一个能够对单一查询进行多次工作的出色RAG系统,下一个重要步骤是聊天逻辑,考虑到对话上下文,就像在LLM时代之前的经典聊天机器人中一样。这是为了支持后续问题、指代或与先前对话上下文相关的任意用户命令。通过查询压缩技术,将聊天上下文与用户查询一起考虑来解决这个问题。
如同以往,有几种方法可用于上述上下文压缩——一个流行且相对简单的ContextChatEngine,首先检索与用户查询相关的上下文,然后将其与来自内存缓冲区的聊天历史一起发送给LLM,以便在生成下一个答案时LLM能够了解先前的上下文。
稍微复杂一点的情况是CondensePlusContextMode——在每次交互中,聊天历史和最近的消息被压缩成一个新的查询,然后这个查询进入索引,检索到的上下文与原始用户消息一起传递给LLM以生成答案。
值得注意的是,LlamaIndex也支持基于OpenAI代理的聊天引擎,提供更灵活的聊天模式,Langchain也支持功能API,为创建更智能、更适应用户需求的聊天体验提供了可能。
RAG 中的代理
自首个LLM(大型语言模型)API发布以来,代理(由Langchain和LlamaIndex支持)几乎就已存在——其理念是为具有推理能力的LLM提供一系列工具及待完成的任务。这些工具可能包括确定性的函数,如任何代码函数、外部API,甚至是其他代理——这种LLM链式调用的想法正是LangChain命名的由来。
代理本身就是一个庞大的主题,在RAG概览中深入探讨这一主题是不可能的,因此我将继续讨论基于代理的多文档检索案例,在OpenAI助手这一站稍作停留,因为它是一个相对较新的事物,最近在OpenAI开发者大会上以GPT的身份亮相,并在下面描述的RAG系统背后运作。
OpenAI助手基本上实现了围绕LLM所需的许多工具,这些工具我们之前在开源领域已有——聊天历史记录、知识存储、文档上传界面以及也许最重要的,函数调用API。后者提供了将自然语言转化为对外部工具或数据库查询的API调用的能力。
在LlamaIndex中,有一个OpenAIAgent类,将这种高级逻辑与ChatEngine和QueryEngine类结合,提供基于知识和情境感知的聊天功能,以及在一次对话回合中多次调用OpenAI函数的能力,这确实带来了智能代理行为。
让我们看一下多文档代理架构——一个相当复杂的设置,涉及对每份文档初始化一个代理(OpenAIAgent),它能够进行文档摘要和经典的问答机制,以及一个顶层代理,负责向文档代理路由查询并合成最终答案。
每个文档代理有两个工具——向量存储索引和摘要索引,根据路由的查询决定使用哪一个。而对于顶层代理,所有文档代理都是可敬重的工具。
此架构展示了先进的RAG结构,其中每个参与的代理都会做出大量的路由决策。这种方法的优势在于能够比较不同文档及其摘要中描述的不同解决方案或实体,同时涵盖了经典单文档摘要和问答机制——这基本上覆盖了最常见的与文档集合聊天的使用场景。
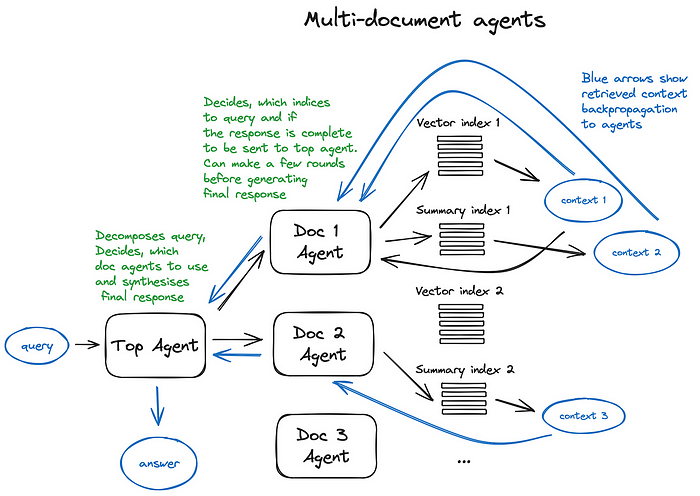
这种复杂方案的缺点可以从图中猜测到——由于代理内部与LLM的多次来回迭代,它的速度有点慢。需要注意的是,LLM调用始终是RAG管道中最耗时的操作——搜索设计上是为了优化速度。
编码器与LLM微调
这种方法涉及对我们RAG管道中的两个深度学习模型之一进行微调——即负责嵌入质量从而影响上下文检索质量的Transformer编码器,或者负责最佳利用所提供的上下文回答用户查询的LLM——幸运的是,后者是一个很好的少量样本学习者。
如今的一大优势是,可以使用像GPT-4这样的高端LLM生成高质量的合成数据集。但我们应该始终意识到,采用由专业研究团队在精心收集、清理和验证的大数据集上训练的开源模型,并使用小规模的合成数据集快速微调,可能会在总体上限制模型的能力。
编码器微调
我也对编码器微调的方法持有些许怀疑态度,因为最新的为搜索优化的Transformer编码器效率相当高。因此,我在LlamaIndex笔记本设置中测试了bge-large-en-v1.5(撰写本文时MTEB排行榜排名前四)微调后性能提升的情况,结果表明检索质量提高了2%。虽然没有戏剧性的变化,但了解这个选项是好的,尤其是在我们有针对狭窄领域数据集构建RAG的情况下。
排序器微调
另一种久经考验的选择是使用交叉编码器对检索到的结果进行重新排序,如果我们对基础编码器完全不信任的话。其工作方式如下——我们将查询和检索出的前k个文本片段传递给交叉编码器,通过SEP标记分隔,并对其进行微调,使其对相关片段输出1,对非相关片段输出0。在此教程中可以找到此类微调过程的一个好例子,结果显示通过交叉编码器微调,配对得分提高了4%。
LLM微调
最近,OpenAI开始提供LLM微调API,而LlamaIndex有一篇关于在RAG设置下微调GPT-3.5-turbo的教程,目的是“提炼”部分GPT-4的知识。这里的思路是,从一份文档出发,使用GPT-3.5-turbo生成一系列问题,然后利用GPT-4基于文档内容生成这些问题的答案(构建一个GPT4驱动的RAG管道),最后在问题-答案对的数据集上对GPT-3.5-turbo进行微调。用于评估RAG管道的Ragas框架显示,**在忠实度指标上提高了5%**,这意味着微调后的GPT 3.5-turbo模型比原始模型更好地利用了所提供的上下文生成答案。
一种更为复杂的方法在最近的论文中提出,即RA-DIT:Retrieval Augmented Dual Instruction Tuning ,由Meta AI Research提出,提出了一种技术,可以在查询、上下文和答案的三元组上同时微调LLM和检索器(在原论文中是双重编码器)。这项技术既被用来通过微调API微调OpenAI的LLM,也被用来微调Llama2开源模型(在原论文中),结果是在知识密集型任务的指标上提高了约5%(与带有RAG的Llama2 65B相比),在常识推理任务上也提高了几个百分点。
评估
有多个框架用于评估RAG系统的性能,它们共同的理念是拥有几个独立的指标,比如整体答案相关性、答案基于事实的程度、忠实度以及检索到的上下文相关性。
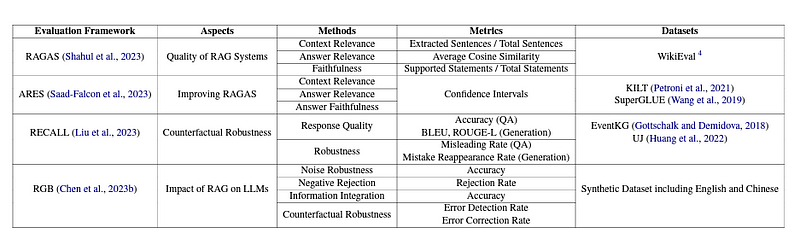
前面提到的Ragas使用了忠实度和答案相关性作为生成答案的质量指标,并使用经典的上下文精确度和召回率来评估RAG方案中的检索部分。
一个非常简单的检索器评估流程的好例子可以在这里找到,并且它在编码器微调部分被应用。一个更先进的方法,不仅考虑了命中率,还考虑了平均倒数排名(Mean Reciprocal Rank),这是搜索引擎常用的一项指标,同时也考虑了生成答案的指标,如忠实度和相关性,这个方法在OpenAI的cookbook中有所展示。
LangChain拥有一套相当先进的评估框架LangSmith,其中可以实现自定义评估器,此外,它监控运行在我们RAG管道内的痕迹,以便让我们的系统更加透明。
如果我们在使用LlamaIndex构建,有一个rag_evaluator llama pack,提供了一个快速工具,让我们能够使用公共数据集评估我们的管道。
结论
我们尝试概述了RAG的核心算法方法,并通过图解一些方法,希望能激发在我们的RAG管道中尝试新想法的灵感,或者向大家介绍今年发明的众多技术中的一些。
还有很多其他值得考虑的事情,例如基于网络搜索的RAG(LlamaIndex的RAGs、webLangChain等),深入探索代理架构(以及一些关于LLM长期记忆的想法。
除了答案相关性和忠实度之外,RAG系统的主要生产挑战是速度,特别是在我们采用更灵活的基于代理的方案时,但这将是另一篇文章的主题。这种流式特征,ChatGPT和其他大多数助手使用的,不仅仅是随机的赛博朋克风格,而是一种缩短感知答案生成时间的方式。

—END—
英文原文:https://medium.com/@vipra_singh/building-llm-applications-advanced-rag-part-10-ec0fe735aeb1

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









