







【编者按:近年来,深度学习应用日益广泛,其需求也在快速增长。那么,我们该如何选择合适的 GPU 来获得最优的训练和推理性能呢?
今天,我们为大家带来的这篇文章,作者的核心观点是:Tensor Core、内存带宽和内存层次结构是影响 GPU 深度学习性能的几个最关键因素。
作者详细解析了矩阵乘法运算在深度学习中的重要性,以及 Tensor Core 如何通过特有的矩阵乘法计算单元极大地提升计算性能。同时,作者还分析了内存带宽对性能的制约作用,比较了不同 GPU 架构在内存层次结构方面的差异。
通过这篇文章,我们可以清晰地了解 GPU 中与深度学习性能密切相关的硬件指标,这有助于我们在选择和使用 GPU 时做出更明智的决策。最后,期待 GPU 在这些关键性能指标的进一步优化和突破。】
作者 | Tim Dettmers
编译 | 岳扬
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/
这篇文章可以帮助我们了解 GPU 对深度学习性能的多个影响因素,从而帮助我们评估、选用 GPU。本文将按照 GPU 各组件的重要程度顺序来进行介绍。Tensor Core(张量计算核心)是最重要的因素,其次是 GPU 的内存带宽和缓存层次结构,最后是 GPU 的 FLOPS。
1. Tensor Core(张量计算核心)
Tensor Core(张量计算核心)是一种能执行高效矩阵乘法运算的微小核心。由于矩阵乘法是任何深度神经网络中最耗费计算资源的部分,因此Tensor Core(张量计算核心)非常有用。它的功能非常强大,强大到我不推荐使用任何没有Tensor Core(张量计算核心)的 GPU。
了解它们的工作原理,有助于理解这些特有的矩阵乘法计算单元(computational units)的重要性。下面以一个简单的 A*B=C 矩阵乘法为例(其中所有矩阵的大小都是 32×32),展示了有张量计算核心和没有张量计算核心的计算模式。这只是一个简化后的例子,并不是高性能矩阵乘法核心的精确编写方式,但它包含了所有基本要素。CUDA 程序员会将此作为第一份 "草稿",然后利用双缓冲(double buffering)、寄存器优化(register optimization)、占用优化(occupancy optimization)、指令级并行(instruction-level parallelism)等概念逐步优化,在此就不展开讨论了。
要完全理解这个例子,你必须理解周期(cycles)的概念。如果处理器的运行频率为 1GHz,那么它每秒可以执行 10^9 个周期。每个周期都代表一次计算机会。然而,大多数情况下,运算时间都超过一个周期。因此,实际上有一个队列,下一个操作需要等待上一个操作完成。这也被称为运算的延迟(the latency of the operation)。
以下是一些重要的运算延迟周期时间(latency cycle timings)。数值会随着 GPU 代次的不同而变化。下面这些数值来自 Ampere 架构的 GPU[1],其缓存速度相对较慢。
- 访问全局内存(高达80GB):约380个周期
- 二级缓存(L2 cache):约200个周期
- 一级缓存或访问共享内存(每个流式多处理器最多128KB):约34个周期
- 乘法和加法在指令集层面的结合(fused multiplication and addition,FFMA):4个周期
- Tensor Core(张量计算核心)矩阵乘法运算:1个周期
每次进行运算总是由一组线程(32个)执行,这组线程被称为线程束(warp)。线程束通常以同步模式(c pattern)运行,线程束内的线程必须等待彼此。GPU上的所有内存操作都针对线程束进行了优化。例如,从全局内存中加载的粒度是32*4字节,恰好是32个浮点数,每个线程束中的每个线程恰好一个浮点数。在一个流式多处理器(SM)中,可以有最多32个线程束(即1024个线程),这相当于CPU核心的GPU等效部分。流式多处理器(SM)的资源被分配给所有活跃的线程束。这意味着,有时我们希望运行较少的线程束,以便每个线程束拥有更多的寄存器/共享内存/张量计算核心资源。
在下面的两个示例中,我们假设拥有相同的计算资源。在这个 32×32 矩阵乘法的小例子中,我们使用了8个流式多处理器(SM)(大约是RTX 3090的10%)和每个SM中的8个线程束。
为了理解周期延迟(cycle latencies)如何与每个SM的线程和共享内存等资源相互作用,现在来看一些矩阵乘法的示例。虽然下面这些示例大致遵循了有和没有张量计算核心的矩阵乘法的计算步骤顺序,但请注意,这些都是非常简化的示例。实际的矩阵乘法运算涉及更大的共享内存块,计算模式也略有不同。
1.1 在没有张量计算核心的情况下进行矩阵乘法运算
以一个简单的 A*B=C 矩阵乘法为例(其中每个矩阵的大小都是 32×32),我们会将反复访问的数据加载到共享内存(shared memory)中,这样做的主要原因是共享内存的延迟约为全局内存的六分之一(200 个周期 vs 34 个周期)。(译者注:为了加快访问速度,我们可以将这些经常访问的数据加载到共享内存中。共享内存是位于GPU的每个SM(流式多处理器)上的一块较小的高速缓存,其延迟较低。)共享内存中的内存块通常被直接称为 memory tile 或简称为 tile。通过使用2个线程束,每个线程束有32个线程,可以并行地将两个32×32的浮点数加载到共享内存 tile 中。如果有8个 SM,每个 SM 有8个线程束,通过并行化(parallelization)技术,我们只需要从全局内存一次顺序加载到共享内存中,整个过程只需200个周期。
为了进行矩阵乘法运算,我们现在需要从共享内存A和共享内存B中加载两个包含 32 个数字的向量,并执行乘法和加法在指令集层面的结合(fused multiplication and addition,FFMA),然后将输出存储在寄存器C中。我们将这项工作分割成多部分,使每个 SM 进行8次点积运算(32×32)来计算出 C 的8个输出。为什么是恰好8次而不是旧算法的4次,这是一个非常专业的问题。建议阅读Scott Gray关于矩阵乘法运算[2]的博文来了解更多细节。这意味着要访问 8 次共享内存,每次访问的需要 34 个周期,以及 8 次FFMA操作(并行进行32次),每次操作需要 4 个周期。因此,总共需要:
200个周期(访问全局内存)+ 8*34个周期(访问共享内存)+ 8*4个周期(FFMA操作)= 504个周期
现在让我们看一下使用张量计算核心进行该矩阵乘法运算需要多少个周期。
1.2 使用张量计算核心进行矩阵乘法运算
通过使用张量计算核心,我们可以在一个周期内执行 4×4 的矩阵乘法。为了实现这一目标,我们首先需要将内存数据传输到张量计算核心中。与前文类似,我们需要从全局内存中读取数据(需要200个周期),然后存储到共享内存中。对于 32×32 的矩阵乘法运算,我们需要进行 64 次张量计算核心运算(即8×8=64次)。每个 SM 具有 8 个张量计算核心,如果有 8 个 SM,就有 64 个张量计算核心,这正好符合我们的需求!我们可以通过一次内存传输(需要34个周期)将数据从共享内存传输到张量计算核心,然后进行64次并行的张量计算核心操作(仅需1个周期)。因此,在这种情况下,使用张量计算核心进行矩阵乘法运算总共需要:
200个周期(访问全局内存)+ 34个周期(访问共享内存)+ 1个周期(使用张量计算核心)= 235个周期。
因此,通过使用张量计算核心,我们将矩阵乘法运算的时间成本从 504 个周期大大降低到了 235 个周期。在这个简化的案例中,使用张量计算核心的方法减少了共享内存的访问和FFMA操作的时间成本。
这个例子是简化后的,通常情况下,当将数据从全局内存传输到共享内存时,每个线程需要计算要读取和写入的内存位置。有了新的Hooper(H100)架构,Tensor Memory Accelerator(TMA)可以在硬件中计算这些索引,从而帮助每个线程专注于更多的运算而不是索引计算。
1.3 使用张量计算核心和异步拷贝(RTX 30/RTX 40)以及TMA(H100)进行矩阵乘法运算
RTX 30 Ampere和RTX 40 Ada系列的 GPU 还支持在全局内存和共享内存之间进行异步传输。H100 Hopper GPU通过引入 Tensor Memory Accelerator(TMA)单元进一步扩展了这一功能。TMA 单元同时结合了异步拷贝和索引计算,因此每个线程无需再计算下一个要读取的元素,而是可以专注于进行更多的矩阵乘法运算。具体如下所示。
TMA 单元从全局内存中获取数据并传输到共享内存,该过程需要耗费200个周期。数据到达后,TMA单元从全局内存异步获取下一个数据块。在此过程中,线程从共享内存中加载数据,并通过张量计算核心执行矩阵乘法运算。线程完成后,等待 TMA 单元完成下一次数据传输,然后再次进行这个过程。
因此,由于异步的特性,当线程处理当前共享内存 tile 时,TMA 单元已经开始进行第二次全局内存读取。这意味着,第二次读取只需要200 - 34 - 1 = 165个周期。
由于我们进行了多次读取,因此只有第一次内存访问的速度会比较慢,其他内存访问都会与TMA单元部分重叠。因此,平均减少了 35 个周期的时间。
165个周期(等待异步拷贝完成)+ 34个周期(访问共享内存)+ 1个周期(使用张量计算核心)= 200个周期。
这又将矩阵乘法运算的速度提高了 15% 左右。
从这些例子中,可以清楚地看出为什么下一个将要介绍的属性——内存带宽(Memory Bandwidth)对于配备有张量计算核心的GPU非常重要。由于访问全局内存(global memory),是目前使用张量计算核心进行矩阵乘法运算消耗时间成本最大的一种方法。如果能减少全局内存的延迟,开发者甚至可以拥有更快的GPU。可以通过增加内存的时钟频率(每秒更多周期,但也会产生更多的热量和拥有更高的能耗)增加同一时间可传输的元素数量(总线宽度)来实现这一目标。
2. 内存带宽
从前文我们可以看出,张量计算核心的运算速度非常快。它们太快了,以至于大部分时间都处于空闲状态,因为需要等待从全局内存中传输来的数据。例如,在训练规模为GPT-3级别的大型神经网络时使用了大矩阵(由于矩阵越大,对张量计算核心进行运算越有利),即便是这种情况下,张量计算核心的利用率约为45-65%,这说明即使是训练大型神经网络,张量计算核心也有约 50% 的时间处于闲置状态。
这一点说明,在比较两个都配备有张量计算核心的GPU时,需要关注的一个重要性能指标就是它们的内存带宽。例如,A100 GPU的内存带宽为1555 GB/s,而V100为900 GB/s。因此,A100 相对于 V100 的速度提升估计是1555/900 = 1.73倍。
3. 二级缓存/共享内存/一级缓存/寄存器
由于将数据传输到张量计算核心的速度不高,是GPU性能的重要限制因素,因此需要寻找一种能够通过其他 GPU 属性解决该限制的方法,以加快向张量计算核心传输数据的速度。二级缓存、共享内存、一级缓存和使用的寄存器数量都是与此相关的 GPU 属性。通过了解GPU上矩阵乘法运算的执行过程,我们可以更好地理解当前内存层次结构(memory hierarchy)如何提高内存传输速度。(译者注:内存层次结构(memory hierarchy)是指计算机系统中不同级别的存储器组件按照速度和容量进行层次化排列的结构。该架构划分为多个层次,从较大但较慢的存储器(如主存)到较小但更快的存储器(如高速缓存)以及寄存器。这种设计旨在通过将最常用的数据存储在更快的存储器级别中,从而提高数据访问速度和系统性能。微观GPU内存层次结构示例如下图所示)
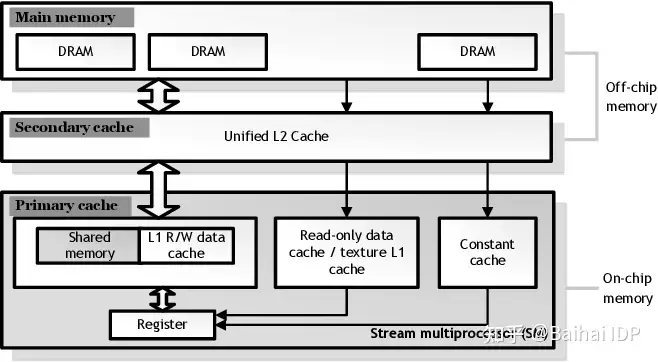
图片由译者附。GeForce GTX780 (Kepler)内存层次结构。Mei, X., & Chu, X. (2015). Dissecting GPU Memory Hierarchy Through Microbenchmarking. IEEE Transactions on Parallel and Distributed Systems, 28, 72-86.
要执行矩阵乘法运算,我们需要合理利用 GPU 的内存层次结构,从速度较慢的全局内存到较快的二级缓存,再到快速的本地共享内存,最后到速度快如闪电的寄存器。然而,内存越快,其内存大小就越小。
虽然从逻辑上讲,二级缓存和一级缓存是相似的,但二级缓存更大,因此检索缓存行所需的平均物理距离也更长。我们可以将一级缓存和二级缓存比喻为仓库,我们从中检索所需的物品。即使我们知道物品在哪里,对于较大的仓库,平均而言到达目标位置需要更长的时间。这是一级缓存和二级缓存之间的基本区别。Large = slow, small = fast.
对于矩阵乘法运算,我们可以利用这种内存分层的方法,将其分解为越来越小、速度更快的内存块,使其能够执行非常快速的矩阵乘法运算。为此,我们需要将大的矩阵乘法运算划分为较小的子矩阵乘法运算。这些内存块被称为memory tiles,通常简称为 tiles。
我们在本地共享内存中用这些较小的 tiles 执行矩阵乘法,本地共享内存速度快且位于流式多处理器(SM)附近——类似于 CPU 核心。使用张量计算核心,我们可以更进一步:将每个 tiles 的一部分加载到由寄存器直接寻址的张量计算核心中。二级缓存中的矩阵内存 tiles 比 GPU 全局内存(GPU RAM)快 3 到 5 倍,共享内存比 GPU 全局内存快约 7 到 10 倍,而张量计算核心的寄存器比 GPU 全局内存快约 200 倍。
较大的 tiles 意味着我们可以重复使用更多的内存空间,在我撰写的关于 TPU vs GPU的博客文章[3]中详细介绍了这一点。实际上,你可以看到 TPU 的每个张量计算核心都有非常非常大的 tiles 。因此,TPU 每次从全局内存传输数据时可以重复使用更多的内存,这使得它们在矩阵乘法运算方面比 GPU 更加高效 。
每个 tiles 的大小由每个流式多处理器(SM)的内存和所有 SM 上的二级缓存大小决定。以下是不同架构 GPU 上的共享内存大小:
- Volta(Titan V):128KB 共享内存/6MB 二级缓存
- Turing(RTX 20系列):96KB 共享内存/5.5MB 二级缓存
- Ampere(RTX 30系列):128KB 共享内存/6MB 二级缓存
- Ada(RTX 40系列):128KB 共享内存/72MB 二级缓存
我们可以看到,Ada 架构的 GPU 具有更大的二级缓存,可以容纳更大的 tiles 尺寸,从而减少了对全局内存的访问。例如,在 BERT large 的训练过程中,任何矩阵乘法运算的输入和权重矩阵都可以完全适应 Ada 架构的二级缓存(但其他架构不行)。因此,数据只需要从全局内存中加载一次,然后就可以通过二级缓存获取数据,这使得对于 Ada 架构,矩阵乘法运算速度提高了约 1.5 到 2.0 倍。对于较大的模型,在训练过程中速度的提升可能较低,但存在某些 sweetspots (译者注:意味着存在某些特定的模型大小、batch size或其他参数设置,使得在该点或区域上的模型训练速度更快或性能更好),可能使某些模型训练速度更快。对于batch size 大于 8 的大模型推理任务,具有更大的二级缓存能够提高推理效率。
Tensor core算力与带宽分析
截止到H100 hopper架构,NV 的 tensor core 已经更新到第四代,历代的算力和计算类型如下图所示。
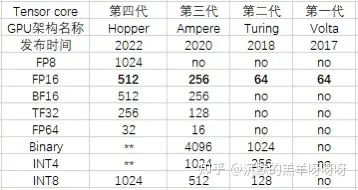
(单位:每个时钟周期能计算乘累加的个数)
以一个FP16的tensor core计算:算力从Volta/Turing架构的4x4x4、Amere架构的4x8x8、到Hopper架构的4x8x16。
Tensor core每个时钟周期能完成FP16的矩阵运算D=A*B+C如下图所示。
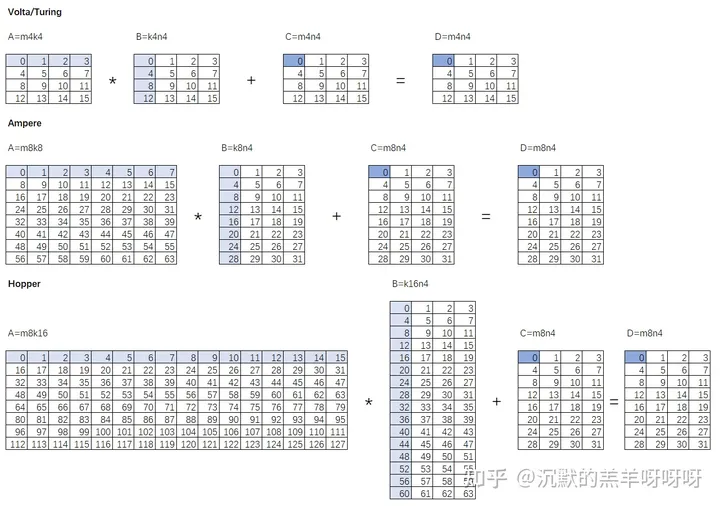
一个FP16的tensor core计算:每个时钟周期需要的矩阵A、B、C的带宽数据量为:
Volta/Turing架构:矩阵A : 4*4*2B=32B;矩阵B : 4*4*2B=32B;矩阵C/矩阵D : 4*4*2B=32B;(以FP16累加和, 若是FP32累加和则需要64B)
Ampere架构: 矩阵A: 8*8*2B=128B;矩阵B : 8*4*2B=64B;矩阵C/矩阵D: 8*4*2B=64B;(以FP16累加和, 若是FP32累加和则需要128B)
Hopper架构: 矩阵A: 8*16*2B=256B;矩阵B : 16*4*2B=128B;矩阵C/矩阵D:16*4*2B=128B;(以FP16累加和, 若是FP32累加和则需要256B)。
寄存器文件:
对于Volta/Turing/Ampere架构,其寄存器文件register files(RF)是有两组sram Banks,每组Bank的位宽是64bit。以一个FMMA指令为例,“FFMA R6, R97, R99, RX”,只要三个源寄存器不会同时访问同一个Bank就不会出现寄存器访问冲突。对于Tensor core 计算是以一个Warp32线程为单位执行的,其源数据也是从register files(RF)获取,每个时钟周期32个线程并行访问32*32bit=128B 矩阵A数据。从寄存器文件的角度看,可以满足Tensor core计算的带宽需求。
对于Hopper架构而言,因为矩阵A需要256B的数据,按照一个warp还是32线程执行,每个线程就需要能够访问64bit的数据才能满足算力的需求。这里还需实际测试才能确认。
Share memory/L2/Global memory:
各级缓存的大小和理论带宽如下表所示:

(*:是估计值,不一定准确)
每一级缓存的带宽和容量相对上一代都有明显的提升。
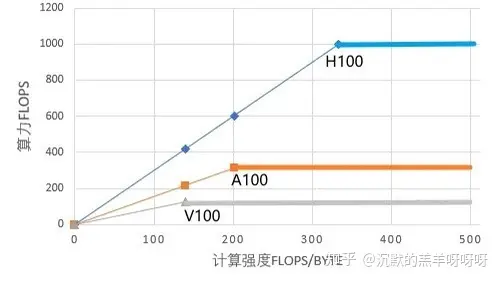
从全局存储带宽和峰值FP16 Tensor core算力上看,其Roofline Model如下图所示,计算强度: H100 > A100 > V100。对于一个任务通常受限于访存或者算力,在不同的硬件算力平台上表现不同。
以Ampere架构,A100的计算平台,其内存结构简化如下图所示。
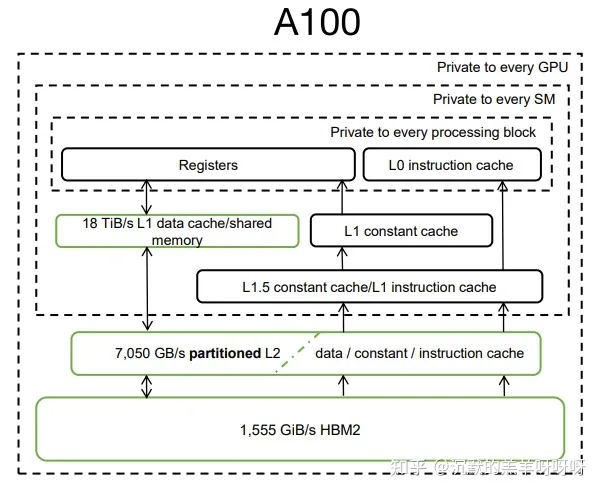
对于任意m*n*k的FP16矩阵运算:一个tensor core的访存计算比(Byte/s)可以简化表示为:512*(m+n)/n/m,因为A100有108SM、每个SM 有4个tensor core,峰值主频是1410Mhz,故一共需要:297*(m+n)/n/m TB/s。
从当前的每一级缓存带宽看上显然不能满足此计算带宽需求,所以首先需要利用SM内部shared memory缓存数据,保证SM内部的4个tensor core计算时可以共享数据;其次在L2 缓存上也能缓存数据,保证多个SM之间计算时可以共享数据,这样才能达到实际的访存计算比,使得算力能够充分发挥。
总结
从算力与带宽上看,单个Tensor core的算力不断增加,总算力和带宽不断增加。
Tensor core编程模型分析
Ampere架构
对于一个16x16x16的FP16矩阵运算,采用FFMA 指令、Volta架构Tensor core(TC)、Ampere架构Tensor core(TC)的指令数、寄存器读写访问次数、执行cycle数如下图所示:
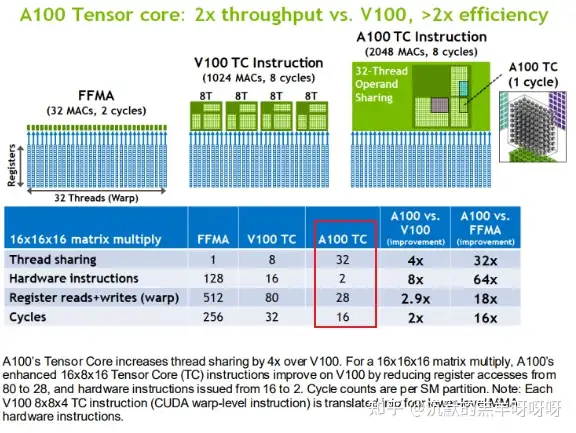
以Ampere架构为例,Tensor core相关的指令,是以一个Warp为单位的指令,32线程间的数据是共享的,不同于FFMA指令。
一条Tensor core PTX指令wmma(m16n16k16 ):
wmma.mma.sync.aligned.row.col.m16n16k16.f16.f16 {%r53, %r52, %r51, %r50}, {%r29, %r30, %r31, %r32, %r33, %r34, %r35, %r36}, {%r37, %r38, %r39, %r40, %r41, %r42, %r43, %r44}, {%r53, %r52, %r51, %r50};会对应两条SASS指令HMMA:
HMMA.16816.F16 R8, R4, R24, R8
HMMA.16816.F16 R2, R4, R26, R2tensor core单元一个cycle只能计算m8n4k8(256Macs),每一条HMMA.16816(2048Macs)指令执行会理论上需要8cycle, 故完成一个 m16n16k16 的矩阵运算需要16cycle。
一条PTX指令 MMA .m16n8k16计算时,对于FP16类型:
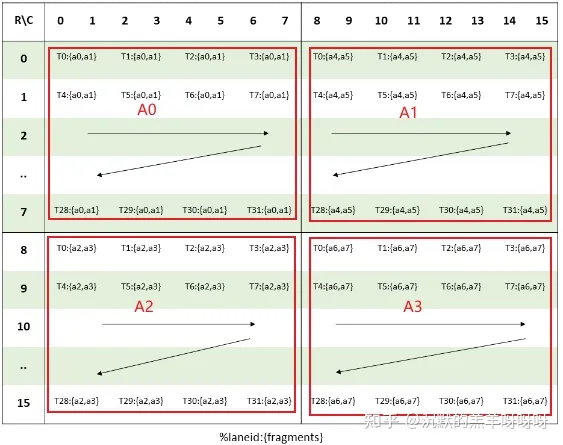
矩阵A:会按照下图拆分为:4个8x8的小块,每个线程需要4个32bit寄存器,分为A0、A1、A2、A3。
(MMA .m16n8k16 fragment layout for matrix A with .f16 / .bf16 type)
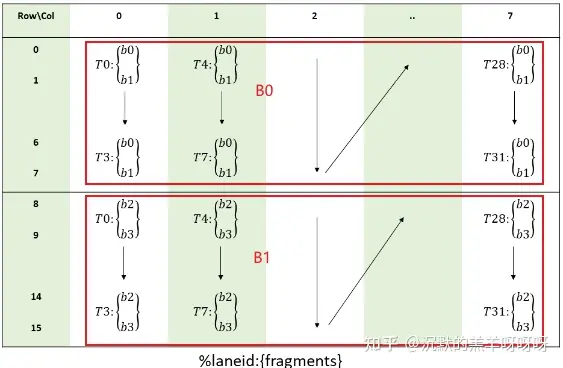
矩阵B:会按照下图拆分为:2个8x8的小块,每个线程需要2个32bit寄存器,分为B0、B1。
(MMA .m16n8k16 fragment layout for matrix B with .f16 / .bf16 type.)
对于矩阵C/D:会按照下图拆分为:2个8x8的小块,若累加为fp16, 每个线程需要2个32bit寄存器;若累加为fp32, 每个线程需要4个32bit寄存器,分为C0、C1/D0、D1。
(MMA .m16n8k16 fragment layout for accumulator matrix matrix C/D)
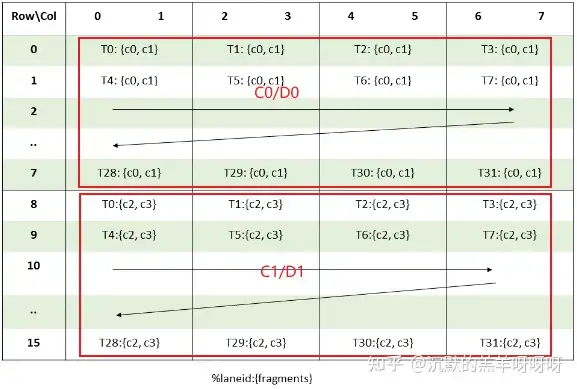
推测部分:
对于MMA.m16n8k16指令,tensor core 执行时会分为4步操作,每一步:执行两次m8n4k8的矩阵运算操作,需要两个cycle。
第一步:A0 * B0 + 0 = C0;
第二步:A1 * B1 + C0 = D0;
第三步:A2 * B0 + 0 = C1;
第四步:A3 * B1 + C1 = D1;
一共需要8个cycle。
寄存器的访存次数:
第一步:2 read + 1 write
第二步:2 read + 1 read + 1 write
第三步:2 read + 1 write
第四步:2 read + 1 read + 1 write
一共是14次访问。
所以对于Ampere架构,一个m16n16k16运算操作,Tensor core计算时,需要16cycle, 28次寄存器访问次数。
Hopper架构
PTX ISA version 8.0加入了wgmma指令,该指令支持N个Warp操作组合到一起,以Warp Group的方式执行,而在SASS层级上也增加了HGMMA等指令。
在PTX 维度wgmma.mma_async指令支持的矩阵维度如下图所示, 矩阵A:m*k,矩阵B:k*n,这里m=64,k=16,n=8~256。

矩阵A的输入来自寄存器或者shared memory,而矩阵B的输入只能来自shared memory。所以这里推测:一条wgmma执行时,在一个SM内部,矩阵A是被切分为4组,每一组是16*16,分别执行在对应4个tensor core上;而矩阵B是需要被4个tensor core共享的,所以它只能放在shared memory上。
一条Tensor core PTX指令wgmma(64n8k16):
wgmma.mma_async.sync.aligned.m64n8k16.f16.f16.f16会对应三条SASS指令:
WARPGROUP.ARRIVE
HGMMA.64x8x16.F16
WARPGROUP.DEPBAR.LE当以一个Warp Group的方式执行,会减小指令数,如果采用mma的指令,这里则需要4条MMA.m16n8k16指令。
一条PTX指令WGMMA .m64n8k16 计算时,对于FP16类型:
矩阵A:会按照下图拆分为:16个8x8的小块,分为A0、A1、....、A15。每个线程需要4个32bit寄存器,一共有128个线程。
(WGMMA .m64nNk16 register fragment layout for matrix A.)
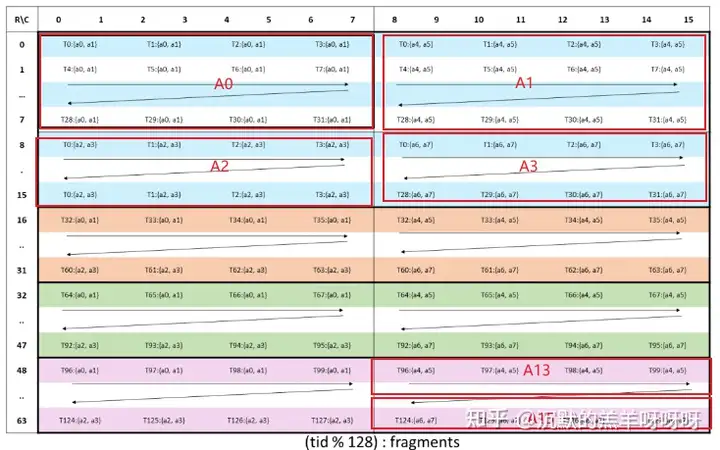
矩阵B会存储在 shared memory 上,类似下图。
矩阵D:会按照下图拆分为:8个8x8的小块,分为A0、A1、....、A7。
(WGMMA .m64nNk16 register fragment layout for accumulator matrix D)
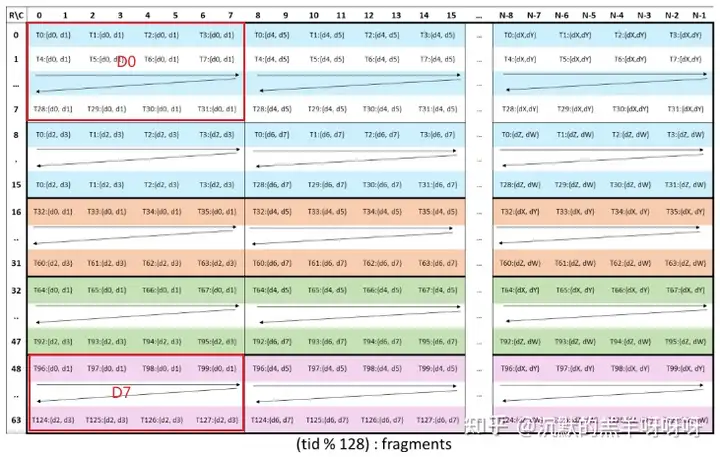
推测部分:
在一个SM上执行时,对于wgmma.m64n8k16指令,会分布在4个tensor core 上执行,每一个tensor core 执行 m16n8k16。每一个tensor core上执行时,会分为2步操作,每一步:执行两次m8n4k16的矩阵运算操作,需要两个cycle。
tensor core0:
第一步:A0 * B0 + A1 * B1 = D0;
第二步:A2 * B0 + A3 * B1 = D1;
tensor core1:
第一步:A4 * B0 + A5 * B1 = D2;
第二步:A6 * B0 + A7 * B1 = D3;
tensor core2:
第一步:A8 * B0 + A9 * B1 = D4;
第二步:A10 * B0 + A11 * B1 = D5;
tensor core3:
第一步:A12 * B0 + A13 * B1 = D7;
第二步:A14 * B0 + A15 * B1 = D8;
一共需要4个cycle。
总结
从编程接口上看,编程演进方向向着:更少的指令个数,更少的寄存器访问次数,以及更大粒度的执行单元。
参考资料
Hopper Superchip Architecture Whitepaper
Ampere-architecture-whitepaper
Turing-Architecture-Whitepaper
volta-architecture-whitepaper
Dissecting the Ampere GPU Architecture through Microbenchmarking
Dissecting the NVidia Volta GPU architecture via mircobenchmark
Dissecting the NVidia Turing T4 GPU via Microbenchmarking
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#
本文章转载自公众号:芯设计

















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









