






Kevin Lin , Jiwen Lu , Chu-Song Chen , Jie Zhou .IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016.
摘要:在本文中,我们提出一种称为DeepBit的新的无监督深度学习方法来学习紧凑二进制描述符,用于有效的视觉对象匹配。不同于大多数现有的二进制描述符设计与随机投影或线性哈希函数,我们开发一个深层神经网络以无监督的方式学习二进制描述符。我们对我们网络顶层学习的二进制代码执行三个标准:1)最小损耗量化,2)编码均匀分布和3)比特不相关。然后,我们用反向传播技术学习网络的参数。在三个不同的视觉分析任务包括图像匹配,图像检索和对象识别的实验结果清楚地证明了所提出的方法的有效性。
1.介绍
特征描述符在计算机视觉中起着重要作用[28],已被广泛应用于众多的计算机视觉任务,如对象识别[10,26,42],图像分类[15,52]和全景拼接[5]。理想的特征描述符应该满足两个基本属性:(1)高质量描述,和(2)低计算花费。特征描述符需要捕获图像中的重要和独特的信息[26,28],并且对于各种图像变换是鲁棒的[26,27]。另一方面,高效的描述符使机器能够实时运行,这对于检索大型语料库中的图像[37]或者利用移动设备检测对象也很重要[43,50]。
在过去十年中,已经广泛探索了高质量描述符,例如从卷积神经网络(CNN)[20,32]和代表性SIFT描述符[26]学习的丰富特征。这些描述符证明了卓越的辨别能力,弥合了低级像素和高级语义信息之间的差距[44]。然而,它们是高维实值描述符,并且通常需要高计算成本。
为了降低计算复杂度,最近提出了几个轻量级二进制描述符,如BRIEF [6],ORB [33],BRISK [22]和FREAK [1]。这些二进制描述符对排序和匹配非常有效。给定紧凑的二进制描述符,可以通过经由XOR按位操作计算二进制描述符之间的汉明距离来快速测量图像的相似性。由于这些早期的二进制描述符是通过简单的紧密度比较计算的,它们通常是不稳定的并且对尺度,旋转和噪声敏感。 一些先前的工作[9,40,48,53,54]通过在优化期间编码相似性关系来改进二进制描述符。然而,这些方法的成功主要归因于成对相似性标签。换句话说,他们的方法在训练数据不具有标签注释的情况下是不利的。
在这项工作中,我们提出一个问题 - 我们可以从没有标签的数据学习二进制描述符吗? 从深度学习的最新进展启发,我们提出了一个有效的深度学习方法,称为DeepBit,以学习紧凑的二进制描述符。我们对学习的二进制描述符执行三个重要标准,并使用反向传播优化网络的参数。我们采用我们的方法在三个不同的视觉分析任务,包括图像匹配,图像检索和对象识别。实验结果清楚地表明,我们提出的方法优于最先进的技术。
2. Related Work
二进制描述符:与二进制描述符有关的早期作品可以追溯到BRIEF [6],ORB [33],BRISK [22]和FREAK [1]。这些二进制描述符建立在手工制作的采样模式和一组成对强度比较。虽然这些描述是有效的,但它们的性能是有限的,因为成对强度比较对尺度和几何变换敏感。 为了解决这些限制,已经提出了几种监督方法[3,9,38,39,41,50,53]来学习二进制描述符。 D-Brief [41]编码所需的相似关系,并学习项目矩阵来计算有区别的二进制特征。另一方面,局部差分二进制(LDB)[50,51]应用Adaboost来选择最佳采样对。 线性判别分析(LDA)也被应用于学习二进制描述符[14,38]。最近提出的BinBoost [39,40]使用增强算法学习一组投影矩阵,并在块匹配上实现最先进的性能。虽然这些方法已经取得了令人印象深刻的性能,他们的成功主要归因于配对相似的标签学习,并且不利于将二进制描述符转移到一个新的任务的情况。
无监督散列算法学习紧凑的二进制描述符,其距离与原始输入数据的相似性关系相关[2,14,34,46]。局部敏感哈希(LSH)[2]应用随机投影将原始数据映射到低维特征空间,然后执行二进制化。语义散列(SH)[34]构建了一个多层限制玻尔兹曼机(RBM)来学习用于文本和文档的紧凑二进制代码。频谱散列(SpeH)[46]通过频谱图分割生成高效的二进制代码。迭代量化(ITQ)[14]使用迭代优化策略找到具有最小二值化损失的投影。即使这些方法已经被证明是有效的,二进制码仍然不如真实值等价物那样准确。
深度学习:深度学习在视觉分析中引起越来越多的关注,因为Krizhevsky et al。 [20]证明了深层CNN在1000级图像分类中的突出性能。他们的成功归功于训练一个深度的CNN,在上百万的图像中学习丰富的中级图像表示。Oquab et al [31]表明,可以用少量的训练数据实现将中级图像表示传送到新域。Chatfield等人 [7]表明,微调领域特定深特征产生比非微调特性更好的性能。通过预训练的深度CNN和深层转移学习,如对象检测[12],图像分割[25]和图像搜索[23],几个视觉分析任务已经大大改善。在最近的深度学习和二进制代码学习研究中,Xia et al [47]和Lai et al [21]采用深度CNN学习一组散列函数,但是它们需要配对相似性标签或三元组训练数据。SSHD [49]在深层CNN中构造散列函数作为潜在层,实现了最先进的图像检索性能,但是它们的方法属于监督学习。深度散列(DH)[24]建立三层分层神经网络学习区分投影矩阵,但他们的方法没有利用深层转移学习,因此使二进制代码效率较低。
相比之下,所提出的DeepBit不仅将从ImageNet预训练的中级图像表示传送到目标域,而且还学习没有标签信息的紧凑但有区别的二进制描述符。我们将展示我们的方法在三个公共数据集上达到比最先进的描述符更好或可比的性能。
3.Approach
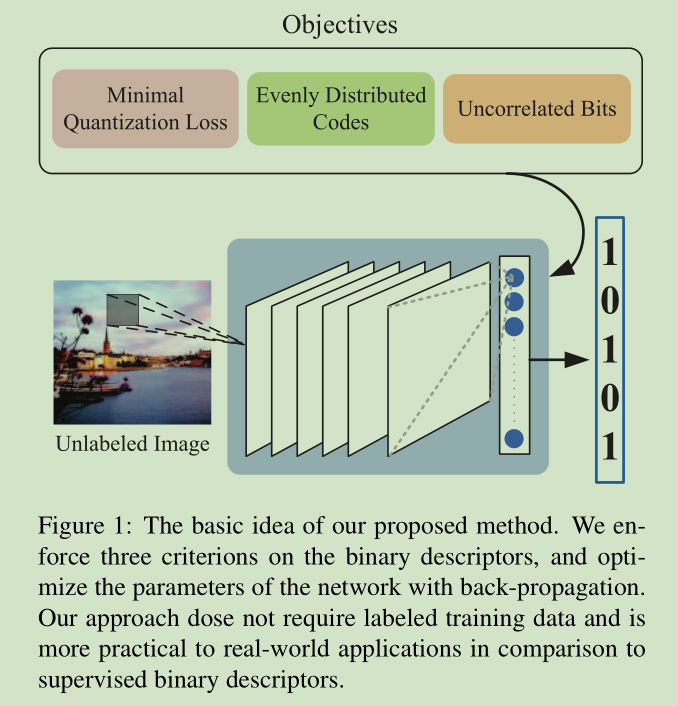
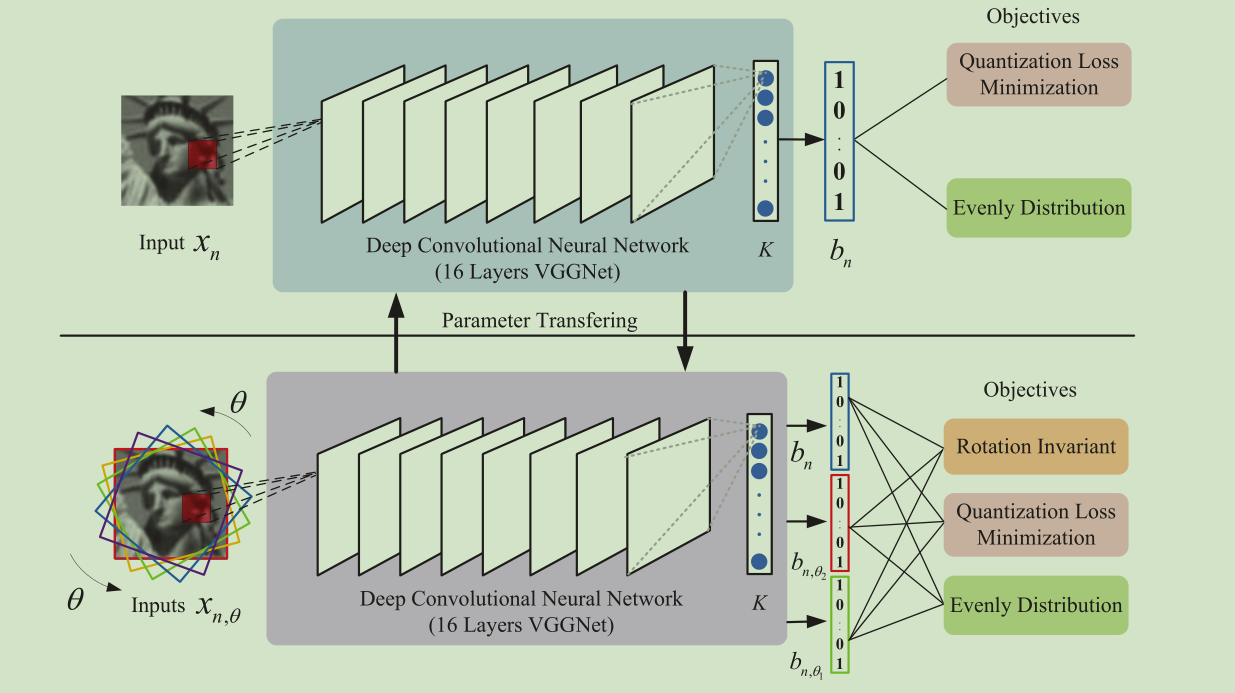
图2显示了我们提出的方法的学习框架。我们引入一个无人监督的深度学习方法,称为DeepBit,以学习紧凑但有区别的二进制描述符。不同于以前的工作[9,39-41],优化具有手工特征和配对相似信息的投影矩阵,DeepBit学习一组非线性投影函数来计算紧凑二进制描述符。我们对二进制描述符执行三个重要目标,并使用随机梯度下降技术优化所提出的网络的参数。注意,我们的方法不需要标记的训练数据,并且比监督方法更实用。在本节中,我们首先概述我们的方法,然后在以下部分描述提出的学习目标。
3.1 总体学习目标
所提出的DeepBit通过将投影应用于输入图像来计算二进制描述符,然后对结果进行二值化:
b = 0.5 × (sign(F(x; W)) + 1), (1)
其中x表示输入图像,b是向量形式的结果二进制描述符。sign(k) = 1 if k > 0
and −1 otherwise.F(x; W)是多个非线性投影函数的组合,可以写为:
F(x; W) = f k (· · · f 2 (f 1 (x; w 1 ); w 2 ) · · · ; w k ), (2)
其中f i将数据x i和参数w i作为输入,并且产生投影结果x i + 1。
所提出的方法旨在学习一组非线性投影参数W =(w 1,w 2,...,w k),其将输入图像x量化为紧凑二进制向量b,同时保留来自输入的信息。为了学习紧凑而有区别的二进制描述符,我们执行三个重要的标准来学习W. 首先,所学习的紧凑二进制描述符应保留最后一层的致动的局部数据结构。 在投影之后,量化损耗应尽可能小。第二,我们促进二进制描述符均匀分布,使得二进制字符串将传达更多的歧视消息。第三个是使描述符不变的旋转和噪声,因此二进制描述符将倾向于从输入图像捕获更多不相关的信息。
其中N是每个小批量的训练数据的数量,M是二进制码的位长,R表示图像旋转角。是从具有旋转角度θ的图像x n投影的二进制描述符,C(θ)是根据其旋转度惩罚训练数据的成本函数。此外,α,β和γ是平衡不同目标的三个参数。
为了更好地理解所提出的目标,我们描述(3)的物理意义如下。 首先,L 1使二进制描述符和原始输入图像之间的量化损失最小化。然后,L 2鼓励二进制描述符被均匀分布以最大化二进制描述符的信息容量。 最后,L 3通过最小化描述参考图像的描述符和旋转的描述符之间的汉明距离来容忍旋转变换。我们详细阐述了每个提出的目标的细节如下。
3.2 学习辨别二进制描述符
所提出的DeepBit试图学习将输入图像映射成二进制串,同时保留原始输入的辨别信息的投影。保持二进制描述符信息的灵魂思想是通过重写(1)最小化量化损失如下:
(b − 0.5) = F(x; W), (4)
量化损失越小,二进制描述符将保留原始数据信息越好。不同于以前的工作[13],通过迭代更新W和b两个交替的步骤解决这个问题,我们制定这个优化问题作为神经网络训练目标。从那时起,所提出的网络的目标变成学习使二进制描述符和原始输入图像之间的量化损失最小化的W。为此,我们通过反向传播和随机梯度下降(SGD)使用以下损耗函数来优化所提出的网络的参数W:
3.3 学习高效的二进制描述符
为了增加二进制描述符的信息容量,我们最大化二进制字符串中每个bin的使用。考虑每个仓的方差,熵越高,二进制码表示的信息越多。 其中M表示二进制串的位长度。 对于每个bin,我们使用以下公式计算平均响应μm:
其中N是训练数据的数目,并且函数b(m)产生在第m个二进制位的二进制值。
3.4 学习旋转不变二进制描述符
由于旋转不变性对于局部描述符是必要的,因此我们希望在优化期间增强该属性。我们通过最小化描述参考图像和旋转后的二进制描述符之间的差异来解决这个问题。考虑到图像之间的估计误差,当增加旋转度时,估计误差可能变大。因此,我们通过根据旋转度惩罚网络的训练损失来减轻估计误差。我们将所提出的目标定义为成本敏感的优化问题如下:
其中θ∈(-R,R)是旋转角。表示从输入x n与旋转θ映射的描述符。 C(θ)提供成本信息以反映不同旋转变换之间的二进制描述符的关系。在本文中,我们通过设置以减少估计误差:
其中C(θ)是高斯分布,在我们的实验中nμ= 0,σ= 1。
我们使用开源Caffe实现我们的方法[18],算法1总结了所提出的DeepBit的详细过程。所提出的方法包括两个主要部分。第一个是网络初始化。 二是优化步骤。我们使用来自16层VGGNet [36]的预训练的权重来初始化网络,这是在ImageNet大规模数据集上训练的。然后,我们用新的完全连接的层替换VGGNet的分类层,并强制该层中的神经元学习二进制描述符。为此,我们使用随机梯度下降(SGD)方法和反向传播训练我们的网络,并使用提出的目标优化W(见(3))。其他设置如下所示。α = 1.0, β = 1.0, γ = 0.01.我们分别旋转图像10,5,0,-5,-10度。小批量大小为32,二进制描述符的位长度为256。图像归一化为256x256,然后中心裁剪为224×224作为网络输入。
4.实验结果
我们对三个具有挑战性的数据集,棕色灰色斑块[4],CIFAR-10彩色图像[19]和牛津17类花[29]进行实验。我们提供广泛的评估二进制描述符,并演示其在各种任务,包括图像匹配,图像检索和图像分类的性能。我们从介绍数据集开始,然后介绍我们的实验结果以及与其他最新型的方法比较评价。
4.1 数据集
Brown数据集[4]包括三个数据集,即Liberty,Notre Dame,Yosemite数据集。它们中的每一个包括超过400,000个灰度色块,导致总共1,200,000个色块。每个数据集被分成训练和测试集,分别具有20,000个训练对(10,000个匹配和10,000个非匹配对)和10,000个测试对(5,000个匹配和5,000个不匹配对)。
CIFAR-10数据集[19]包含10个对象类别,每个类由6,000个图像组成,导致总共60,000个图像。数据集被分成训练和测试集,分别有50,000和10,000图像。
牛津17类花数据集[29]包含17个类别,每个类由80个图像组成,导致总共 1 360个图像。
4.3 图像检索实验结果
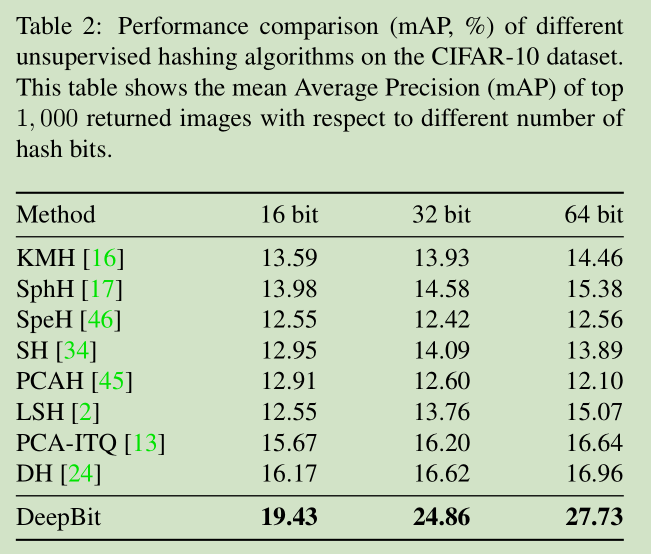
为了评估所提出的二进制描述符的可辨别性,我们进一步测试我们的方法对图像检索的任务。我们在CIFAR-10数据集上比较DeepBit和几种无监督的哈希方法,包括LSH [2],ITQ [14],PCAH [45],语义哈希[SH] [34],光谱哈希[SpeH] [46] 17],KMH [16]和深度散列(DH)[24]。在这八个无监督方法中,深度散列(DH),像我们的方法,利用深层神经网络学习紧凑二进制代码。
根据[24]中的设置,表2示出了基于前1000个返回图像相对于不同位长度的平均平均精度(mAP)的CIFAR-10检索结果。DeepBit分别相对于16,32和64个散列位将以前的最佳检索性能提高了3.26%,8.24%和10.77%mAP。根据结果,我们发现,哈希位越长,DeepBit实现的性能越好。此外,图6分别示出了具有16,32,64个散列位的不同无监督散列方法的精度/回忆曲线。可以看出,DeepBit 始终优于以前的无监督方法。 这表明所提出的方法有效地学习二进制描述符。值得注意的是,DH [24]采用三层分层神经网络来学习二进制散列码; 然而,DH不利用训练期间的深层转移学习。相比之下,提出的DeepBit不仅将从ImageNet预训练的中级图像表示传输到目标域,而且还学习具有期望标准的二进制描述符。实验表明,深层转移学习与提出的目标可以提高无人监管的哈希性能。
5. 总结
在本文中,我们提出了一个无监督的深度学习框架来学习紧凑二进制描述符。我们采用三个标准来学习二进制代码和估计深度神经网络的参数以获得二进制描述符。我们的方法在学习期间不需要标记数据,并且与监督的二进制描述符相比对于现实世界的应用更加实用。在三个基准数据库上的实验包括灰度局部斑块,彩色图像和野生花卉表明我们的方法在大多数情况下比最先进的特征描述符更好的性能。
本文通过深度学习网络来学习 Compact Binary Descriptors ,
亮点是 Unsupervised,在优化函数里面加入了三个约束:
1) minimal loss quantization
2) evenly distributed codes
3) uncorrelated bits

优化函数:
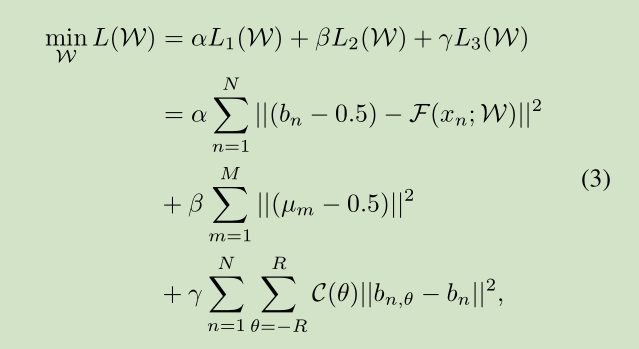
L1, L2,L3 分别对应:
1)Discriminative Binary Descriptors
2) Efficient Binary Descriptors
3) Rotation Invariant Binary Descriptors
算法流程如下:

4 Experimental Results
4.2. Results on Image Matching
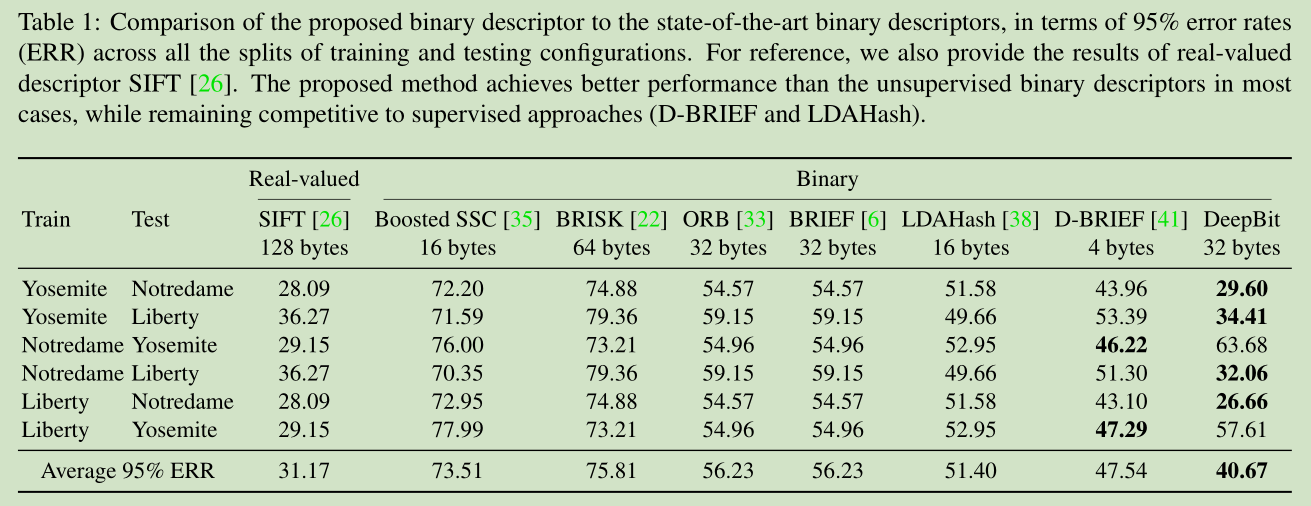
4.3. Results on Image Retrieval
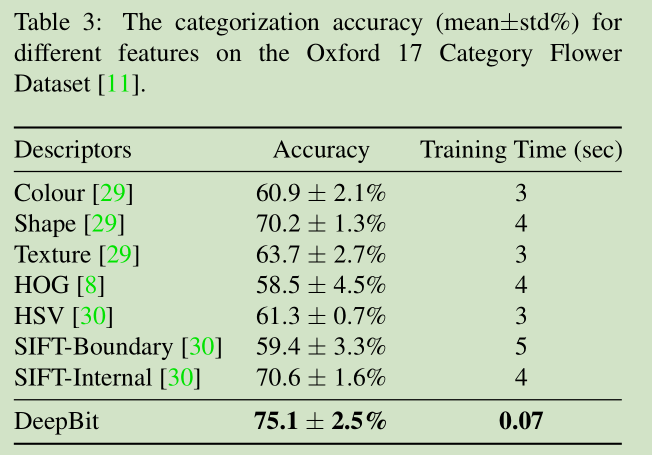
4.4. Results on Object Recognition
Kevin Lin , Jiwen Lu , Chu-Song Chen , Jie Zhou .IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016.
摘要:在本文中,我们提出一种称为DeepBit的新的无监督深度学习方法来学习紧凑二进制描述符,用于有效的视觉对象匹配。不同于大多数现有的二进制描述符设计与随机投影或线性哈希函数,我们开发一个深层神经网络以无监督的方式学习二进制描述符。我们对我们网络顶层学习的二进制代码执行三个标准:1)最小损耗量化,2)编码均匀分布和3)比特不相关。然后,我们用反向传播技术学习网络的参数。在三个不同的视觉分析任务包括图像匹配,图像检索和对象识别的实验结果清楚地证明了所提出的方法的有效性。
1.介绍
特征描述符在计算机视觉中起着重要作用[28],已被广泛应用于众多的计算机视觉任务,如对象识别[10,26,42],图像分类[15,52]和全景拼接[5]。理想的特征描述符应该满足两个基本属性:(1)高质量描述,和(2)低计算花费。特征描述符需要捕获图像中的重要和独特的信息[26,28],并且对于各种图像变换是鲁棒的[26,27]。另一方面,高效的描述符使机器能够实时运行,这对于检索大型语料库中的图像[37]或者利用移动设备检测对象也很重要[43,50]。
在过去十年中,已经广泛探索了高质量描述符,例如从卷积神经网络(CNN)[20,32]和代表性SIFT描述符[26]学习的丰富特征。这些描述符证明了卓越的辨别能力,弥合了低级像素和高级语义信息之间的差距[44]。然而,它们是高维实值描述符,并且通常需要高计算成本。
为了降低计算复杂度,最近提出了几个轻量级二进制描述符,如BRIEF [6],ORB [33],BRISK [22]和FREAK [1]。这些二进制描述符对排序和匹配非常有效。给定紧凑的二进制描述符,可以通过经由XOR按位操作计算二进制描述符之间的汉明距离来快速测量图像的相似性。由于这些早期的二进制描述符是通过简单的紧密度比较计算的,它们通常是不稳定的并且对尺度,旋转和噪声敏感。 一些先前的工作[9,40,48,53,54]通过在优化期间编码相似性关系来改进二进制描述符。然而,这些方法的成功主要归因于成对相似性标签。换句话说,他们的方法在训练数据不具有标签注释的情况下是不利的。
在这项工作中,我们提出一个问题 - 我们可以从没有标签的数据学习二进制描述符吗? 从深度学习的最新进展启发,我们提出了一个有效的深度学习方法,称为DeepBit,以学习紧凑的二进制描述符。我们对学习的二进制描述符执行三个重要标准,并使用反向传播优化网络的参数。我们采用我们的方法在三个不同的视觉分析任务,包括图像匹配,图像检索和对象识别。实验结果清楚地表明,我们提出的方法优于最先进的技术。
2. Related Work
二进制描述符:与二进制描述符有关的早期作品可以追溯到BRIEF [6],ORB [33],BRISK [22]和FREAK [1]。这些二进制描述符建立在手工制作的采样模式和一组成对强度比较。虽然这些描述是有效的,但它们的性能是有限的,因为成对强度比较对尺度和几何变换敏感。 为了解决这些限制,已经提出了几种监督方法[3,9,38,39,41,50,53]来学习二进制描述符。 D-Brief [41]编码所需的相似关系,并学习项目矩阵来计算有区别的二进制特征。另一方面,局部差分二进制(LDB)[50,51]应用Adaboost来选择最佳采样对。 线性判别分析(LDA)也被应用于学习二进制描述符[14,38]。最近提出的BinBoost [39,40]使用增强算法学习一组投影矩阵,并在块匹配上实现最先进的性能。虽然这些方法已经取得了令人印象深刻的性能,他们的成功主要归因于配对相似的标签学习,并且不利于将二进制描述符转移到一个新的任务的情况。
无监督散列算法学习紧凑的二进制描述符,其距离与原始输入数据的相似性关系相关[2,14,34,46]。局部敏感哈希(LSH)[2]应用随机投影将原始数据映射到低维特征空间,然后执行二进制化。语义散列(SH)[34]构建了一个多层限制玻尔兹曼机(RBM)来学习用于文本和文档的紧凑二进制代码。频谱散列(SpeH)[46]通过频谱图分割生成高效的二进制代码。迭代量化(ITQ)[14]使用迭代优化策略找到具有最小二值化损失的投影。即使这些方法已经被证明是有效的,二进制码仍然不如真实值等价物那样准确。
深度学习:深度学习在视觉分析中引起越来越多的关注,因为Krizhevsky et al。 [20]证明了深层CNN在1000级图像分类中的突出性能。他们的成功归功于训练一个深度的CNN,在上百万的图像中学习丰富的中级图像表示。Oquab et al [31]表明,可以用少量的训练数据实现将中级图像表示传送到新域。Chatfield等人 [7]表明,微调领域特定深特征产生比非微调特性更好的性能。通过预训练的深度CNN和深层转移学习,如对象检测[12],图像分割[25]和图像搜索[23],几个视觉分析任务已经大大改善。在最近的深度学习和二进制代码学习研究中,Xia et al [47]和Lai et al [21]采用深度CNN学习一组散列函数,但是它们需要配对相似性标签或三元组训练数据。SSHD [49]在深层CNN中构造散列函数作为潜在层,实现了最先进的图像检索性能,但是它们的方法属于监督学习。深度散列(DH)[24]建立三层分层神经网络学习区分投影矩阵,但他们的方法没有利用深层转移学习,因此使二进制代码效率较低。
相比之下,所提出的DeepBit不仅将从ImageNet预训练的中级图像表示传送到目标域,而且还学习没有标签信息的紧凑但有区别的二进制描述符。我们将展示我们的方法在三个公共数据集上达到比最先进的描述符更好或可比的性能。
3.Approach
图2显示了我们提出的方法的学习框架。我们引入一个无人监督的深度学习方法,称为DeepBit,以学习紧凑但有区别的二进制描述符。不同于以前的工作[9,39-41],优化具有手工特征和配对相似信息的投影矩阵,DeepBit学习一组非线性投影函数来计算紧凑二进制描述符。我们对二进制描述符执行三个重要目标,并使用随机梯度下降技术优化所提出的网络的参数。注意,我们的方法不需要标记的训练数据,并且比监督方法更实用。在本节中,我们首先概述我们的方法,然后在以下部分描述提出的学习目标。
3.1 总体学习目标
所提出的DeepBit通过将投影应用于输入图像来计算二进制描述符,然后对结果进行二值化:
b = 0.5 × (sign(F(x; W)) + 1), (1)
其中x表示输入图像,b是向量形式的结果二进制描述符。sign(k) = 1 if k > 0
and −1 otherwise.F(x; W)是多个非线性投影函数的组合,可以写为:
F(x; W) = f k (· · · f 2 (f 1 (x; w 1 ); w 2 ) · · · ; w k ), (2)
其中f i将数据x i和参数w i作为输入,并且产生投影结果x i + 1。
所提出的方法旨在学习一组非线性投影参数W =(w 1,w 2,...,w k),其将输入图像x量化为紧凑二进制向量b,同时保留来自输入的信息。为了学习紧凑而有区别的二进制描述符,我们执行三个重要的标准来学习W. 首先,所学习的紧凑二进制描述符应保留最后一层的致动的局部数据结构。 在投影之后,量化损耗应尽可能小。第二,我们促进二进制描述符均匀分布,使得二进制字符串将传达更多的歧视消息。第三个是使描述符不变的旋转和噪声,因此二进制描述符将倾向于从输入图像捕获更多不相关的信息。
其中N是每个小批量的训练数据的数量,M是二进制码的位长,R表示图像旋转角。是从具有旋转角度θ的图像x n投影的二进制描述符,C(θ)是根据其旋转度惩罚训练数据的成本函数。此外,α,β和γ是平衡不同目标的三个参数。
为了更好地理解所提出的目标,我们描述(3)的物理意义如下。 首先,L 1使二进制描述符和原始输入图像之间的量化损失最小化。然后,L 2鼓励二进制描述符被均匀分布以最大化二进制描述符的信息容量。 最后,L 3通过最小化描述参考图像的描述符和旋转的描述符之间的汉明距离来容忍旋转变换。我们详细阐述了每个提出的目标的细节如下。
3.2 学习辨别二进制描述符
所提出的DeepBit试图学习将输入图像映射成二进制串,同时保留原始输入的辨别信息的投影。保持二进制描述符信息的灵魂思想是通过重写(1)最小化量化损失如下:
(b − 0.5) = F(x; W), (4)
量化损失越小,二进制描述符将保留原始数据信息越好。不同于以前的工作[13],通过迭代更新W和b两个交替的步骤解决这个问题,我们制定这个优化问题作为神经网络训练目标。从那时起,所提出的网络的目标变成学习使二进制描述符和原始输入图像之间的量化损失最小化的W。为此,我们通过反向传播和随机梯度下降(SGD)使用以下损耗函数来优化所提出的网络的参数W:
3.3 学习高效的二进制描述符
为了增加二进制描述符的信息容量,我们最大化二进制字符串中每个bin的使用。考虑每个仓的方差,熵越高,二进制码表示的信息越多。 其中M表示二进制串的位长度。 对于每个bin,我们使用以下公式计算平均响应μm:
其中N是训练数据的数目,并且函数b(m)产生在第m个二进制位的二进制值。
3.4 学习旋转不变二进制描述符
由于旋转不变性对于局部描述符是必要的,因此我们希望在优化期间增强该属性。我们通过最小化描述参考图像和旋转后的二进制描述符之间的差异来解决这个问题。考虑到图像之间的估计误差,当增加旋转度时,估计误差可能变大。因此,我们通过根据旋转度惩罚网络的训练损失来减轻估计误差。我们将所提出的目标定义为成本敏感的优化问题如下:
其中θ∈(-R,R)是旋转角。表示从输入x n与旋转θ映射的描述符。 C(θ)提供成本信息以反映不同旋转变换之间的二进制描述符的关系。在本文中,我们通过设置以减少估计误差:
其中C(θ)是高斯分布,在我们的实验中nμ= 0,σ= 1。
我们使用开源Caffe实现我们的方法[18],算法1总结了所提出的DeepBit的详细过程。所提出的方法包括两个主要部分。第一个是网络初始化。 二是优化步骤。我们使用来自16层VGGNet [36]的预训练的权重来初始化网络,这是在ImageNet大规模数据集上训练的。然后,我们用新的完全连接的层替换VGGNet的分类层,并强制该层中的神经元学习二进制描述符。为此,我们使用随机梯度下降(SGD)方法和反向传播训练我们的网络,并使用提出的目标优化W(见(3))。其他设置如下所示。α = 1.0, β = 1.0, γ = 0.01.我们分别旋转图像10,5,0,-5,-10度。小批量大小为32,二进制描述符的位长度为256。图像归一化为256x256,然后中心裁剪为224×224作为网络输入。
4.实验结果
我们对三个具有挑战性的数据集,棕色灰色斑块[4],CIFAR-10彩色图像[19]和牛津17类花[29]进行实验。我们提供广泛的评估二进制描述符,并演示其在各种任务,包括图像匹配,图像检索和图像分类的性能。我们从介绍数据集开始,然后介绍我们的实验结果以及与其他最新型的方法比较评价。
4.1 数据集
Brown数据集[4]包括三个数据集,即Liberty,Notre Dame,Yosemite数据集。它们中的每一个包括超过400,000个灰度色块,导致总共1,200,000个色块。每个数据集被分成训练和测试集,分别具有20,000个训练对(10,000个匹配和10,000个非匹配对)和10,000个测试对(5,000个匹配和5,000个不匹配对)。
CIFAR-10数据集[19]包含10个对象类别,每个类由6,000个图像组成,导致总共60,000个图像。数据集被分成训练和测试集,分别有50,000和10,000图像。
牛津17类花数据集[29]包含17个类别,每个类由80个图像组成,导致总共 1 360个图像。
4.3 图像检索实验结果
为了评估所提出的二进制描述符的可辨别性,我们进一步测试我们的方法对图像检索的任务。我们在CIFAR-10数据集上比较DeepBit和几种无监督的哈希方法,包括LSH [2],ITQ [14],PCAH [45],语义哈希[SH] [34],光谱哈希[SpeH] [46] 17],KMH [16]和深度散列(DH)[24]。在这八个无监督方法中,深度散列(DH),像我们的方法,利用深层神经网络学习紧凑二进制代码。
根据[24]中的设置,表2示出了基于前1000个返回图像相对于不同位长度的平均平均精度(mAP)的CIFAR-10检索结果。DeepBit分别相对于16,32和64个散列位将以前的最佳检索性能提高了3.26%,8.24%和10.77%mAP。根据结果,我们发现,哈希位越长,DeepBit实现的性能越好。此外,图6分别示出了具有16,32,64个散列位的不同无监督散列方法的精度/回忆曲线。可以看出,DeepBit 始终优于以前的无监督方法。 这表明所提出的方法有效地学习二进制描述符。值得注意的是,DH [24]采用三层分层神经网络来学习二进制散列码; 然而,DH不利用训练期间的深层转移学习。相比之下,提出的DeepBit不仅将从ImageNet预训练的中级图像表示传输到目标域,而且还学习具有期望标准的二进制描述符。实验表明,深层转移学习与提出的目标可以提高无人监管的哈希性能。
5. 总结
在本文中,我们提出了一个无监督的深度学习框架来学习紧凑二进制描述符。我们采用三个标准来学习二进制代码和估计深度神经网络的参数以获得二进制描述符。我们的方法在学习期间不需要标记数据,并且与监督的二进制描述符相比对于现实世界的应用更加实用。在三个基准数据库上的实验包括灰度局部斑块,彩色图像和野生花卉表明我们的方法在大多数情况下比最先进的特征描述符更好的性能。
本文通过深度学习网络来学习 Compact Binary Descriptors ,
亮点是 Unsupervised,在优化函数里面加入了三个约束:
1) minimal loss quantization
2) evenly distributed codes
3) uncorrelated bits
优化函数:
L1, L2,L3 分别对应:
1)Discriminative Binary Descriptors
2) Efficient Binary Descriptors
3) Rotation Invariant Binary Descriptors
算法流程如下:
4 Experimental Results
4.2. Results on Image Matching
4.3. Results on Image Retrieval
4.4. Results on Object Recognition















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









