







 超级会员免费看
超级会员免费看

- 论文题目:Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
- 发布期刊:NeurIPS
- 通讯地址:香港大学 & 英特尔实验室 & 马克斯普朗克研究所
- 代码地址:https://github.com/Gofinge/PointTransformerV2
介绍
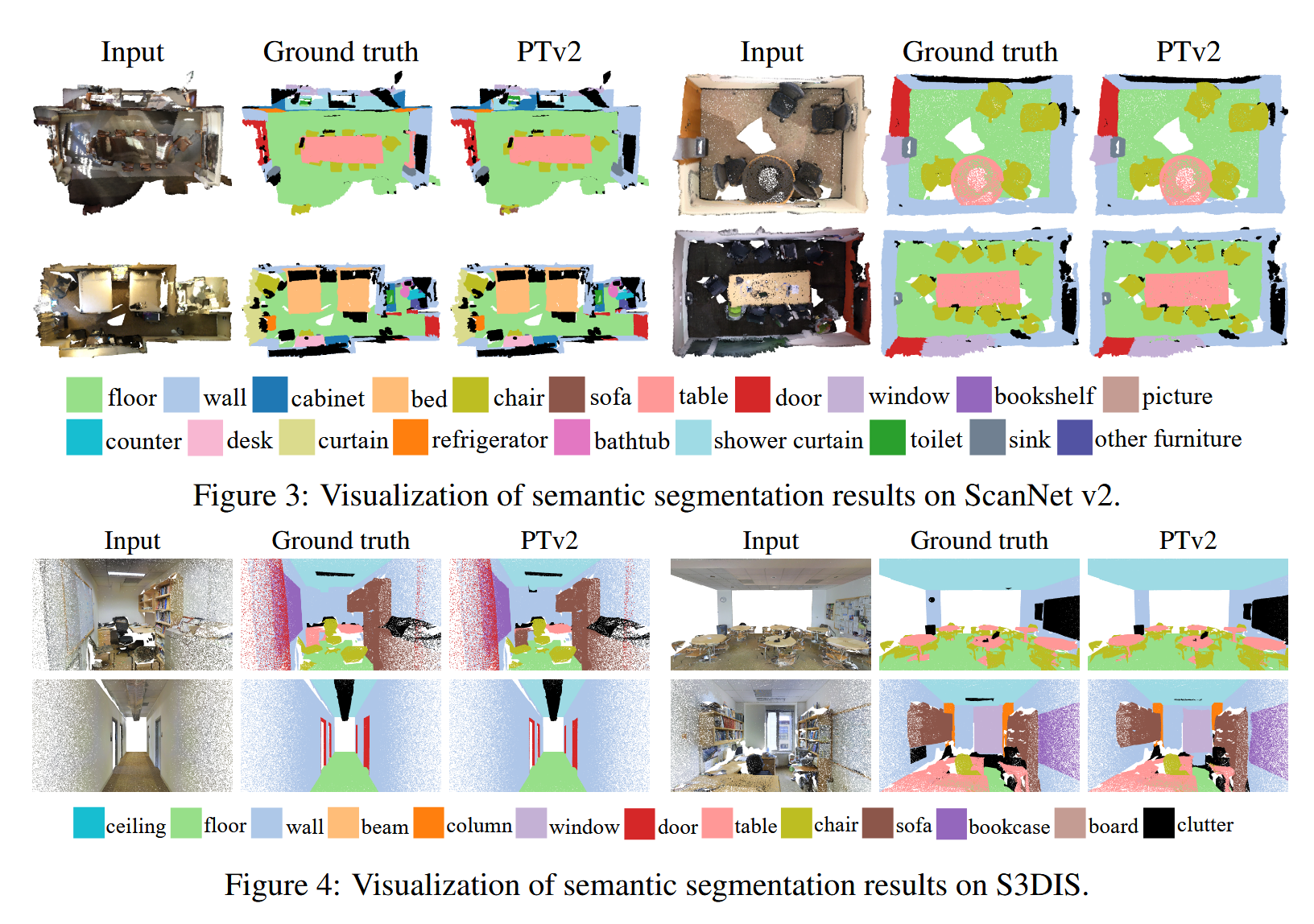
介绍了一个改进版的3D点云理解模型,称为Point Transformer V2(PTv2)。论文分析了原始PTv1的局限性,并展示了PTv2在多个基准测试中的精度和效率均优于PTv1。此外,论文还通过详细的消融实验评估了PTv2中各个模块的影响,并评估了模型的复杂度和延迟,展示了这些改进带来的显著优势。
- 分组向量注意力(Grouped Ve

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









