







 超级会员免费看
超级会员免费看
- 论文题目:Point Transformer
- 发布期刊:ICCV
- 通讯地址:牛津大学 & 香港大学 & 香港中文大学
- 代码地址:https://github.com/POSTECH-CVLab/point-transformer

介绍
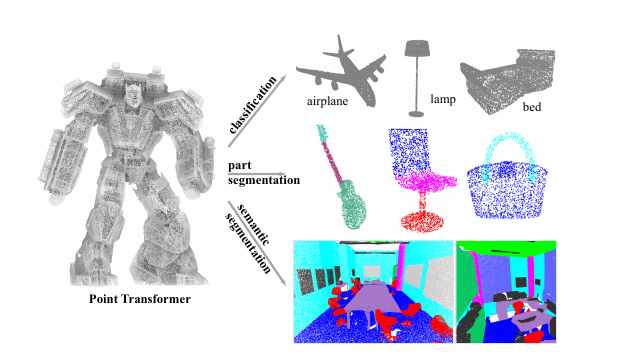
- 提出了Point Transformer层:基于自注意力机制,设计了适用于3D点云处理的自注意力层。由于点云本质上是嵌入到3D空间中的点集,自注意力机制在这种情况下很自然地适用。该层对点的排列顺序不敏感,适用于3D点云数据。
- 用于多种3D理解任务:作者通过Point Transformer网络,处理语义场景分割、物体部分分割和物体分类等任务,展示了模型在不同领域的广泛适用性。实验表明,Point Transfor

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









