






现代微处理器具有矢量指令,可以同时对向量的所有元素进行操作。这也被称为单指令多数据(SIMD)操作。每个向量的总大小可以是64位(MMX)、128位(XMM)、256位(YMM)和512位(ZMM)。
当在大数据集上执行相同操作并且程序逻辑允许并行计算时,矢量运算非常有用。例如图像处理、声音处理以及对向量和矩阵进行数学运算。本质上是串行的算法(如大多数排序算法)不太适合进行矢量运算。大量依赖于表查询或需要大量数据排列的算法,如许多加密算法,可能不太适合进行矢量运算。
矢量运算使用一组特殊的矢量寄存器。如果SSE2指令集可用,则每个矢量寄存器的最大大小为128位(XMM),如果可用AVX指令集,则为256位(YMM),如果可用AVX512指令集,则为512位。每个向量中的元素数量取决于数据元素的大小和类型,如下所示:
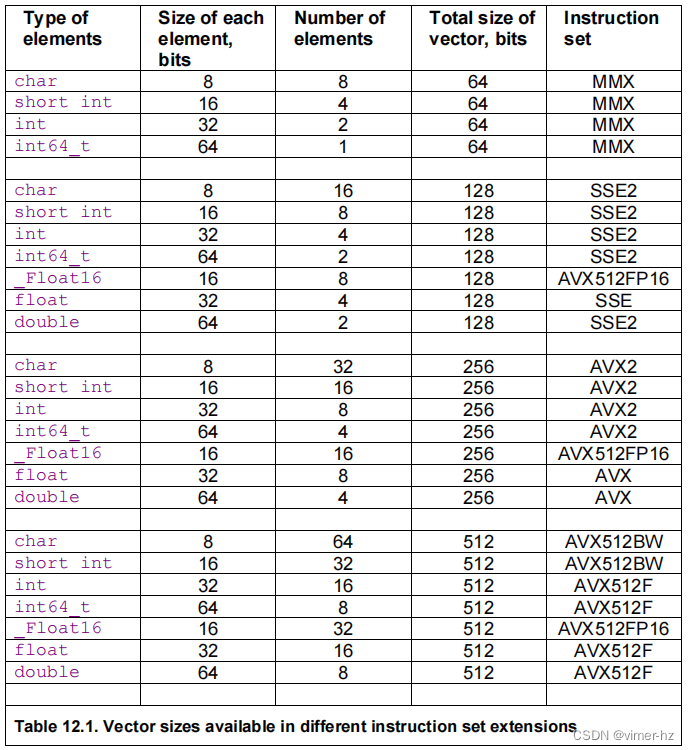
例如,当SSE2指令集可用时,128位的XMM寄存器可以组织成一个包含八个16位整数或四个浮点数的向量。应避免使用旧的64位宽度的MMX寄存器,因为它们不能与x87风格的浮点代码混合使用。
在低于AVX(见下文)的指令集编译时,128位的XMM向量必须以16的倍数对齐,即存储在内存地址上,该地址可被16整除。256位的YMM向量最好按32对齐,而512位的ZMM寄存器最好按64对齐,但是在为AVX和更新的指令集进行编译时,对齐要求不那么严格。
新型处理器在矢量运算方面特别快。许多处理器可以像处理标量(单一元素)一样快速地计算矢量。支持新的矢量大小的第一代处理器有时只具有最大矢量大小的一半的执行单元、内存端口等。这些单元会被用于两次处理一个完整大小的矢量。
使用矢量运算对较小的数据元素更有优势。例如,您可以在执行8个双精度浮点数加法的时间内完成16个单精度浮点数加法。如果数据恰好适合矢量寄存器,则在当今的CPU上使用矢量运算几乎总是更有优势的。
12.1 AVX instruction set and YMM registers
128位的XMM寄存器在AVX指令集中扩展为256位的寄存器,称为YMM寄存器。AVX指令集的主要优势是允许较大的浮点向量。还有其他一些优点可能会略微提高性能。AVX2指令集还允许256位的整数向量。
编译为AVX指令集的代码只有在CPU和操作系统都支持AVX时才能运行。老旧的不支持AVX的操作系统现今已很少使用,因此这不是一个问题。微软、英特尔、Gnu和Clang最新的编译器都支持AVX指令集。
在某些英特尔处理器上,混合编译了和未编译AVX支持的代码时会出现问题。由于YMM寄存器状态的改变,从AVX代码到非AVX代码的转换会产生性能惩罚。在任何从AVX代码到非AVX代码的转换之前调用内嵌函数_mm256_zeroupper(),可以避免这种惩罚。以下情况可能需要这样做:
• 如果程序的一部分编译有AVX支持,而程序的另一部分没有AVX支持,则在离开AVX部分之前调用_mm256_zeroupper()。
• 如果使用CPU分派在多个版本中编译带有AVX和不带AVX的函数,则在离开AVX部分之前调用_mm256_zeroupper()。
• 如果使用AVX支持编译的代码片段调用库中除编译器附带的库之外的另一个库函数,并且该库不支持AVX,则在调用库函数之前调用_mm256_zeroupper()。
编译器可能会或可能不会自动插入_mm256_zeroupper()。编译器输出的汇编代码会告知它的行为。
12.2 AVX512 instruction set and ZMM registers
256位的YMM寄存器在AVX512指令集中扩展为512位的寄存器,称为ZMM寄存器。在64位模式下,向量寄存器的数量从16个扩展到32个。在32位模式下,只有8个向量寄存器。因此,最好将AVX512代码编译为64位模式。
AVX512指令集还增加了一组掩码寄存器。这些寄存器用作布尔向量。几乎任何向量指令都可以使用掩码寄存器进行掩码,以便只有在掩码寄存器对应位为1时计算每个向量元素。这使得带有分支的代码的矢量化更高效。
AVX512还有许多其他扩展功能。所有支持AVX512的处理器都具有其中的一些扩展功能,但迄今为止没有一个处理器具有全部扩展功能。已知的和计划中的一些AVX512扩展功能包括:
• AVX512F. 基础功能。所有AVX512处理器都具有此功能。包括对32位和64位整数、浮点数和双精度浮点数在512位向量上进行操作,包括掩码操作。
• AVX512VL. 在128位和256位向量上执行相同的操作,包括掩码操作和32个向量寄存器。
• AVX512BW. 在512位向量上执行8位和16位整数操作。
• AVX512DQ. 使用64位整数的乘法和转换指令。对浮点数和双精度数执行各种其他指令。
• AVX512ER. 快速求倒数、求平方根和指数函数。对浮点数精确,对双精度数近似。仅适用于少数处理器。
• AVX512CD. 冲突检测。在向量中查找重复元素。
• AVX512PF. 具有gather/scatter逻辑的预取指令。
• AVX512VBMI. 具有8位粒度的置换和移位操作。
• AVX512VBMI2. 压缩和展开稀疏向量,包括8位和16位整数。在文本处理中很有用。
• AVX512IFMA. 对52位整数进行融合乘加操作。
• AVX512_4VNNIW. 对16位整数进行迭代点积运算。
• AVX512_4FMAPS. 迭代融合乘加运算,单精度。
• AVX512_FP16. 半精度浮点数向量。
这使得CPU分派更加复杂。您可以选择对特定任务有用的扩展功能,并为具有该扩展功能的处理器创建代码分支。
在AVX512代码中使用_mm256_zeroupper()函数的重要性较小,但仍然推荐使用。详细信息请参阅手册2:“汇编语言优化子程序”第13.2章和手册5:“调用约定”第6.3章。
12.3 Automatic vectorization
优秀的编译器可以在并行性明显的情况下自动使用向量操作。请查阅编译器文档以获取详细的指导说明。以下是一个例子:
// Example 12.1a. Automatic vectorization
const int size = 1024;
int a[size], b[size];
// ...
for (int i = 0; i < size; i++) {
a[i] = b[i] + 2;
}当指定了SSE2或更高版本的指令集时,优秀的编译器将通过使用向量操作来优化此循环。代码将根据指令集从数组b中读取四个、八个或十六个元素,并与包含(2,2,2,...)的另一个向量寄存器进行相加,然后将四个结果存储在a中。这个操作将根据数组大小除以每个向量的元素数量重复执行。速度会相应提高。当循环计数可以被每个向量的元素数量整除时效果最好。您可以在数组末尾添加虚拟元素,使得数组大小成为向量大小的倍数。
当通过指针访问数组时存在一个劣势,例如:
// Example 12.1b. Vectorization with alignment problem
void AddTwo(int * __restrict aa, int * __restrict bb) {
for (int i = 0; i < size; i++) {
aa[i] = bb[i] + 2;
}
}性能最佳的情况是,如果数组按照向量大小对齐,即对于XMM、YMM和ZMM寄存器分别为16、32或64。在AVX之前的指令集中,高效的向量操作要求数组的地址可被16整除。在示例12.1a中,编译器可以按照要求对数组进行对齐,但在示例12.1b中,编译器无法确定数组是否正确对齐。循环仍然可以向量化,但代码效率会降低,因为编译器必须采取额外的预防措施来处理未对齐的数组。当通过指针或引用访问数组时,有几种方法可以使代码更有效率:
- 如果使用Intel编译器,可以使用#pragma vector aligned或__assume_aligned指令来告诉编译器数组已经对齐,并确保它们确实对齐。
- 将函数声明为内联函数。这可能使编译器将示例12.1b简化为12.1a。
- 如果可能,启用具有最大向量大小的指令集。AVX及更高版本的指令集在对齐方面几乎没有限制,无论数组是否对齐,生成的代码都会高效执行。
自动向量化在满足以下条件时效果最佳:
1. 使用支持自动向量化的优秀编译器,如Gnu、Clang或Intel。
2. 使用最新版本的编译器。编译器在向量化方面越来越好。
3. 如果通过指针或引用访问数组或结构体,则根据需要使用__restrict或__restrict__关键字明确告诉编译器指针不会别名。
4. 使用适当的编译器选项启用所需的指令集(对于Windows,使用/arch:SSE2、/arch:AVX等;对于Linux,使用-msse2、-mavx512f等)。
5. 使用较宽松的浮点选项。对于Gnu和Clang编译器,使用选项-O2 -fno-trapping-math -fno-math-errno -fno-signed-zeros(-ffast-math也可以,但在-ffast-math下函数isnan(x)等将无效)。
6. 对于SSE2,将数组和大结构体按16对齐,最好对于AVX按32对齐,对于AVX512按64对齐。
7. 循环计数最好是一个常数,可被向量中的元素数量整除。
8. 如果通过指针访问数组,以至于在想要向量化的函数作用域中对齐不可见,请遵循上述建议。
9. 减少在向量元素级别上的分支使用。
10. 避免在向量元素级别上进行表查找。
您可以查看汇编输出列表,以查看代码是否按照预期进行向量化(见第88页)。
编译器可能由于多种原因无法将代码向量化,或者使代码变得过于复杂。自动向量化的最重要障碍包括:
- 编译器无法确定数据指针是否指向重叠或别名地址。
- 编译器无法排除未执行分支将生成异常或其他副作用。
- 编译器不知道数组的大小是否为向量大小的倍数。
- 编译器不知道数据结构是否正确对齐。
- 需要重新排列数据以适应向量。
- 代码过于复杂。
- 代码调用了不可在向量版本中使用的外部函数。
- 代码使用了查找表。
编译器还可以在没有循环的情况下使用向量操作,如果同一操作在一系列连续的变量上执行。例如:
// Example 12.2
struct alignas(16) S1 { // Structure of 4 floats, aligned
float a, b, c, d;
};
void Func() {
S1 x, y;
...
x.a = y.a + 1.;
x.b = y.b + 2.;
x.c = y.c + 3.;
x.d = y.d + 4.;
};一个由四个浮点数构成的结构适配到一个128位XMM寄存器中。在示例12.2中,优化后的代码将把结构体y加载到一个向量寄存器中,将常量向量(1,2,3,4)相加,并将结果存储在x中。
编译器并不总是能够准确预测是否向量化会带来优势。编译器可能具有#pragma或其他指令,可用于告诉编译器哪些循环应该进行向量化。这些#pragma指令必须紧接在您想要应用的循环或一系列语句之前。
如果代码包含分支语句(如下面的示例12.4a),则会出现复杂情况。处理分支的方法是计算分支的两个方向,然后合并两个结果向量,使得一些向量元素来自于一个分支,而其他元素来自于另一个分支。如果有理论上的可能性表明未采用的分支会产生陷阱(如浮点溢出)或其他副作用,编译器将不会对此类代码进行向量化。您可以通过为Gnu和Clang编译器指定编译选项-fno-trapping-math和-fno-math-errno,或者为其他编译器指定类似的选项,以帮助编译器对代码进行向量化。不建议使用选项-ffast-math,因为它会禁用对无穷大和NAN的检测(请参阅第66页)。
在应用程序中使用适合的最小数据大小是有优势的。例如,在示例12.3a中,通过使用short int而不是int,您可以将速度提高一倍。short int的宽度为16位,而int的宽度为32位,因此,一个向量可以容纳8个short int类型的数字,而只能容纳4个int类型的数字。因此,使用足够大以容纳所需数字且不产生溢出的最小整数大小是有优势的。同样,如果代码可以进行向量化,使用float而不是double也是有优势的,因为float使用32位,而double使用64位。如果需要大量额外的代码来在不同的精度之间进行转换,那么使用较低精度的优势可能会消失。
SSE2向量指令集无法对除short int(16位)以外的其他大小的整数进行乘法。向量中没有整数除法指令,但是向量类库(参见第125页)提供了整数向量除法的函数。
12.4 Using intrinsic functions
很难预测编译器是否会对循环进行向量化。下面的示例展示了一段可能或可能不会被编译器自动向量化的代码。这段代码有一个分支,用于在数组中的每个元素之间选择两个表达式之一:
// Example 12.4a. Loop with branch
// Loop with branch
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
for (int i = 0; i < 256; i++) {
aa[i] = (bb[i] > 0) ? (cc[i] + 2) : (bb[i] * cc[i]);
}
}可以通过使用所谓的内置函数来显式地对代码进行向量化。这在像示例12.4a这样的情况下非常有用,其中当前的编译器并不总是自动向量化代码。它还适用于自动向量化导致次优代码的情况。
内置函数在某种程度上类似于汇编语言编程,因为大多数内置函数调用都会转换为特定的机器指令。与汇编程序相比,使用内置函数更容易、更安全,因为编译器会处理寄存器分配、函数调用约定等。另一个优点是编译器可以通过重新排序指令、公共子表达式消除等进一步优化代码。内置函数得到了Gnu、Clang、Intel和Microsoft编译器的支持。使用Gnu和Clang编译器可以获得最佳性能。
我们想要对示例12.4a中的循环进行向量化,以便我们可以一次处理八个16位整数的向量,每个向量中包含八个元素。根据可用的指令集,循环内部的分支可以以不同的方式实现。传统的方法是当bb[i]>0时生成一个全1的位掩码,并在为假时全部为0。将cc[i]+2的值与此掩码进行按位与操作,并将bb[i]*cc[i]与反转的掩码进行按位与操作。与全1进行按位与操作的表达式保持不变,而与全0进行按位与操作的表达式将返回零。这两个表达式的或组合给出所选的表达式。示例12.4b展示了如何使用SSE2指令集的内置函数来实现这一点:
// Example 12.4b. Vectorized with SSE2
#include <emmintrin.h> // Define SSE2 intrinsic functions
// Function to load unaligned integer vector from array
static inline __m128i LoadVector(void const * p) {
return _mm_loadu_si128((__m128i const*)p);
}
// Function to store unaligned integer vector into array
static inline void StoreVector(void * d, __m128i const & x) {
_mm_storeu_si128((__m128i *)d, x);
}
// Branch/loop function vectorized:
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
// Make a vector of (0,0,0,0,0,0,0,0)
__m128i zero = _mm_setzero_si128();
// Make a vector of (2,2,2,2,2,2,2,2)
__m128i two = _mm_set1_epi16(2);
// Roll out loop by eight to fit the eight-element vectors:
for (int i = 0; i < 256; i += 8) {
// Load eight consecutive elements from bb into vector b:
__m128i b = LoadVector(bb + i);
// Load eight consecutive elements from cc into vector c:
__m128i c = LoadVector(cc + i);
// Add 2 to each element in vector c
__m128i c2 = _mm_add_epi16(c, two);
// Multiply b and c
__m128i bc = _mm_mullo_epi16 (b, c);
// Compare each element in b to 0 and generate a bit-mask:
__m128i mask = _mm_cmpgt_epi16(b, zero);
// AND each element in vector c2 with the bit-mask:
c2 = _mm_and_si128(c2, mask);
// AND each element in vector bc with the inverted bit-mask:
bc = _mm_andnot_si128(mask, bc);
// OR the results of the two AND operations:
__m128i a = _mm_or_si128(c2, bc);
// Store the result vector in eight consecutive elements in aa:
StoreVector(aa + i, a);
}
}由于一次处理八个元素,并且避免了循环内的分支,所以生成的代码将更高效。示例12.4b的执行速度比示例12.4a快三到七倍,具体取决于循环内部分支的可预测性。
类型__m128i定义了一个包含整数的128位向量。它可以包含16个8位整数、8个16位整数、4个32位整数或2个64位整数。类型__m128定义了一个包含四个浮点数的128位向量。类型__m128d定义了一个包含两个双精度数的128位向量。相应的256位向量寄存器称为__m256i、__m256和__m256d。512位寄存器称为__m512i、__m512和__m512d。
内置的向量函数的名称以_mm开头。这些函数在Intel的编程手册《Intel 64和IA-32体系结构软件开发人员手册》中列出。也可以在便捷的搜索页面Intel Intrinsics Guide上找到它们。有数千个不同的内置函数,找到特定目的的正确函数可能会有困难。
如果可用的是SSE4.1指令集,则可以使用混合指令来替代示例12.4b中的AND-OR结构:
// Example 12.4c. Same example, vectorized with SSE4.1
// Function to load unaligned integer vector from array
static inline __m128i LoadVector(void const * p) {
return _mm_loadu_si128((__m128i const*)p);
}
// Function to store unaligned integer vector into array
static inline void StoreVector(void * d, __m128i const & x) {
_mm_storeu_si128((__m128i *)d, x);
}
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
// Make a vector of (0,0,0,0,0,0,0,0)
__m128i zero = _mm_setzero_si128();
// Make a vector of (2,2,2,2,2,2,2,2)
__m128i two = _mm_set1_epi16(2);
// Roll out loop by eight to fit the eight-element vectors:
for (int i = 0; i < 256; i += 8) {
// Load eight consecutive elements from bb into vector b:
__m128i b = LoadVector(bb + i);
// Load eight consecutive elements from cc into vector c:
__m128i c = LoadVector(cc + i);
// Add 2 to each element in vector c
__m128i c2 = _mm_add_epi16(c, two);
// Multiply b and c
__m128i bc = _mm_mullo_epi16 (b, c);
// Compare each element in b to 0 and generate a bit-mask:
__m128i mask = _mm_cmpgt_epi16(b, zero);
// Use mask to choose between c2 and bc for each element
__m128i a = _mm_blendv_epi8(bc, c2, mask);
// Store the result vector in eight consecutive elements in aa:
StoreVector(aa + i, a);
}
}AVX512指令集提供了一种更高效的分支方式,使用掩码寄存器和条件指令。可以在一条指令中完成计算和分支:
// Example 12.4d. Same example, vectorized with AVX512F
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
// Make a vector of all 0
__m512i zero = _mm512_setzero_si512();
// Make a vector of all 2
__m512i two = _mm512_set1_epi16(2);
// Roll out loop by 32 to fit the 32-element vectors:
for (int i = 0; i < 256; i += 32) {
// Load 32 consecutive elements from bb into vector b:
__m512i b = _mm512_loadu_si512(bb + i);
// Load 32 consecutive elements from cc into vector c:
__m512i c = _mm512_loadu_si512(cc + i);
// Multiply b and c
__m512i bc = _mm512_mullo_epi16(b, c);
// Compare each element in b to 0 and generate a 32 bit mask
// Each bit in mask is 1 for b[i] > 0
__mmask32 mask = _mm512_cmp_epi16_mask(b, zero, 6);
// Conditionally add 2 to each element in vector c.
// Select c+2 when mask bit = 1, bc when mask bit = 0
__m512i r = _mm512_mask_add_epi16(bc, mask, c, two);
// Store the result vector in 32 elements in aa:
_mm512_storeu_epi16(aa + i, r);
}
}在编译时,您必须包含适当的头文件以支持所用的指令集。immintrin.h或x86intrin.h头文件涵盖了所有的指令集。
您必须确保CPU支持相应的指令集。如果程序包含CPU不支持的指令,将会导致程序崩溃。除了Microsoft编译器外,其他编译器都允许您在命令行上指定要编译的指令集。
请参考第135页以了解如何检查CPU支持的指令集。
Aligning data
如果数据对齐到向量大小(16、32或64字节)的地址,向量的数据加载速度会更快。这对于旧处理器和Intel Atom处理器有显著影响,但在大多数新处理器上不那么重要。下面的示例展示了如何对数组进行对齐:
// Example 12.5. Aligned arrays
const int size = 256; // Array size
alignas(16) int16_t aa[size]; // Make aligned arrayVectorized table lookup
如第144页所解释的那样,查找表可以用于优化代码。不幸的是,查找表通常是矢量化的障碍。AVX2和之后的指令集具有针对查找表很有用的gather指令。32位或64位整数的向量提供了内存中表的索引。结果是一个32位或64位整数、浮点数或双精度值的向量。gather指令需要多个时钟周期,因为元素被逐个读取。
如果查找表非常小,可以放入一个或几个向量寄存器中,那么使用置换指令进行查找更高效。AVX指令集允许在256位向量中置换32位浮点数。使用16位整数进行置换需要AVX512BW指令集。在具有超过16个元素的表中使用8位整数进行置换需要AVX512VBMI指令集。
使用内置函数可能会相当繁琐。代码变得臃肿且难以阅读。通常,使用向量类更容易,接下来的部分将对此进行解释。
12.5 Using vector classes
确实,按照示例12.4b、c和d的方式使用内置函数进行编程相当繁琐。通过将向量封装到C++类中,并使用重载的运算符来执行诸如向量相加之类的操作,可以以更清晰易懂的方式编写相同的代码。这些运算符是内联的,因此生成的机器码与使用内置函数时相同。相比于编写_mm512_add_epi16(a, b),写a + b更容易。
向量类的优势包括:
• 您可以明确指定哪部分代码要进行矢量化,以及如何进行矢量化
• 您可以克服第119页上列出的自动矢量化的障碍
• 与自动矢量化相比,代码通常更简单,因为编译器必须处理可能在您的情况下不相关的特殊情况
• 代码比汇编代码或内置函数更简单,更易读,同时效率相当
目前有许多预定义的向量类库可供使用,包括Intel和我自己的。我的向量类库(VCL)具有许多功能,详情请参阅https://github.com/vectorclass。Intel的向量类库功能较少,且更新较少。
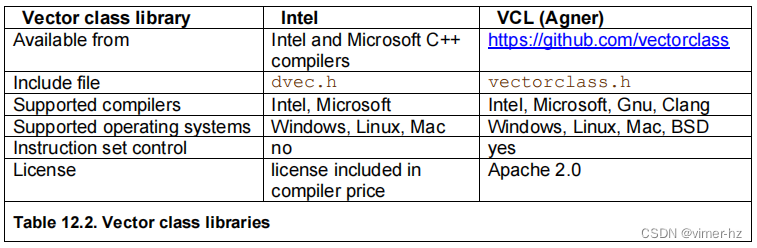
下表列出了可用的向量类。包含相应的头文件将使您可以访问所有这些类。
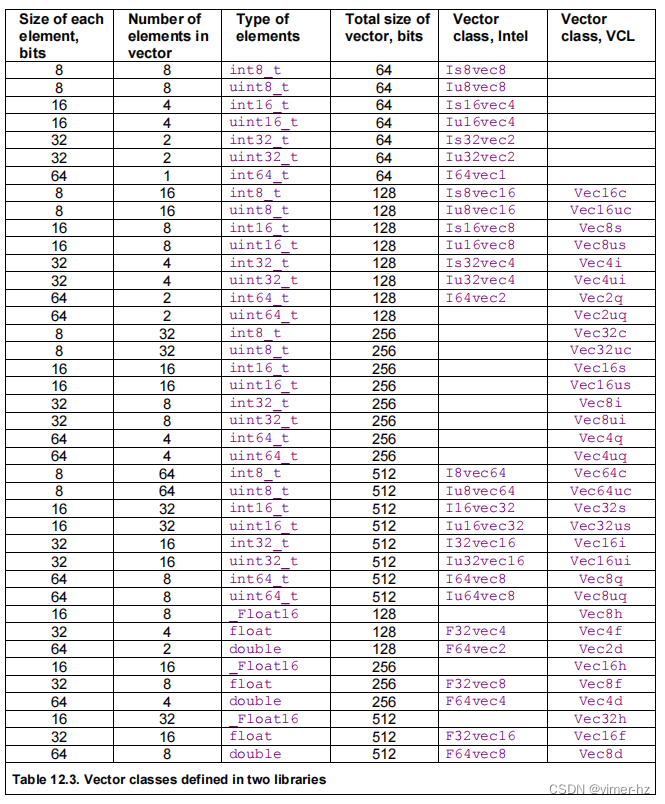
不推荐使用总大小为64位的向量,因为它们与浮点代码不兼容。如果您确实使用64位向量,则必须在64位向量操作之后、任何浮点代码之前执行_mm_empty()。而128位及更大的向量则没有这个问题。 只有在CPU和操作系统支持的情况下(参见第117页),才能使用256位和512位大小的向量。VCL向量类库可以模拟256位向量,将其表示为两个128位向量;也可以模拟512位向量,将其表示为两个256位向量或四个128位向量,具体取决于指令集。如果启用了AVX512-FP16指令集,半精度浮点数(_Float16)向量才是高效的。 以下示例展示了与示例12.4b相同的代码,但使用了Intel向量类进行重写:
// Example 12.4d. Same example, using Intel vector classes
#include <dvec.h> // Define vector classes
// Function to load unaligned integer vector from array
static inline __m128i LoadVector(void const * p) {
return _mm_loadu_si128((__m128i const*)p);}
// Function to store unaligned integer vector into array
static inline void StoreVector(void * d, __m128i const & x) {
_mm_storeu_si128((__m128i *)d, x);}
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
// Make a vector of (0,0,0,0,0,0,0,0)
Is16vec8 zero(0,0,0,0,0,0,0,0);
// Make a vector of (2,2,2,2,2,2,2,2)
Is16vec8 two(2,2,2,2,2,2,2,2);
// Roll out loop by eight to fit the eight-element vectors:
for (int i = 0; i < 256; i += 8) {
// Load eight consecutive elements from bb into vector b:
Is16vec8 b = LoadVector(bb + i);
// Load eight consecutive elements from cc into vector c:
Is16vec8 c = LoadVector(cc + i);
// result = b > 0 ? c + 2 : b * c;
Is16vec8 a = select_gt(b, zero, c + two, b * c);
// Store the result vector in eight consecutive elements in aa:
StoreVector(aa + i, a);
}
}The same example using VCL vector classes looks like this:
// Example 12.4e. Same example, using VCL
#include "vectorclass.h" // Define vector classes
void SelectAddMul(short int aa[], short int bb[], short int cc[]) {
// Define vector objects
Vec16s a, b, c;
// Roll out loop by eight to fit the eight-element vectors:
for (int i = 0; i < 256; i += 16) {
// Load eight consecutive elements from bb into vector b:
b.load(bb+i);
// Load eight consecutive elements from cc into vector c:
c.load(cc+i);
// result = b > 0 ? c + 2 : b * c;
a = select(b > 0, c + 2, b * c);
// Store the result vector in eight consecutive elements in aa:
a.store(aa+i);
}
}向量类库(VCL)包括许多功能,例如向量排列和数学函数。它还包括用于各种目的的附加包。请参阅GitHub网站获取详细信息。
CPU dispatching with vector classes
VCL向量类库可以从同一源代码编译出适用于不同指令集的版本。该库具有预处理指令,可为给定指令集选择最佳实现。
以下示例展示了如何使用自动CPU派发来创建SelectAddMul示例(12.4e)。此示例中的代码应编译四次,分别针对SSE2指令集、SSE4.1、AVX2和AVX512BW。这四个版本将链接到同一个可执行文件中。SSE2是向量类库支持的最低指令集,SSE4.1在select函数中具有优势,AVX2指令集具有更大的向量寄存器优势,而AVX512则具有更大的向量和更高效的分支操作。
根据指令集的不同,向量类库将使用一个512位向量寄存器、两个256位向量寄存器或四个128位向量寄存器。
预处理宏INSTRSET用于为每个指令集为函数命名。CPU调度程序在首次调用函数时将函数指针设置为最佳版本。有关详细信息,请参阅vectorclass手册。
// Example 12.6. Vector class code with automatic CPU dispatching
#include "vectorclass.h" // vector class library
#include <stdio.h> // define fprintf
// define function type
typedef void FuncType(short int aa[], short int bb[], short int cc[]);
// function prototypes for each version
FuncType SelectAddMul, SelectAddMul_SSE2, SelectAddMul_SSE41,
SelectAddMul_AVX2, SelectAddMul_AVX512BW, SelectAddMul_dispatch;
// Define function name depending on instruction set
#if INSTRSET == 2 // SSE2
#define FUNCNAME SelectAddMul_SSE2
#elif INSTRSET == 5 // SSE4.1
#define FUNCNAME SelectAddMul_SSE41
#elif INSTRSET == 8 // AVX2
#define FUNCNAME SelectAddMul_AVX2
#elif INSTRSET == 10 // AVX512BW
#define FUNCNAME SelectAddMul_AVX512BW
#endif
// specific version of the function. Compile once for each version
void FUNCNAME(short int aa[], short int bb[], short int cc[]) {
Vec32s a, b, c; // Define biggest possible vector objects
// Roll out loop by 32 to fit the biggest vectors:
for (int i = 0; i < 256; i += 32) {
b.load(bb+i);
c.load(cc+i);
a = select(b > 0, c + 2, b * c);
a.store(aa+i);
}
}
#if INSTRSET == 2
// make dispatcher in only the lowest of the compiled versions
#include "instrset_detect.cpp" // instrset_detect function
// Function pointer initially points to the dispatcher.
// After first call it points to the selected version
FuncType * SelectAddMul_pointer = &SelectAddMul_dispatch;
// Dispatcher
void SelectAddMul_dispatch(
short int aa[], short int bb[],short int cc[]) {
// Detect supported instruction set
int iset = instrset_detect();
// Set function pointer
if (iset >=10) SelectAddMul_pointer = &SelectAddMul_AVX512BW;
else if (iset >= 8) SelectAddMul_pointer = &SelectAddMul_AVX2;
else if (iset >= 5) SelectAddMul_pointer = &SelectAddMul_SSE41;
else if (iset >= 2) SelectAddMul_pointer = &SelectAddMul_SSE2;
else {
// Error: lowest instruction set not supported
fprintf(stderr, "\nError: Instruction set lower than SSE2 not
supported");
return;
}
// continue in dispatched version
return (*SelectAddMul_pointer)(aa, bb, cc);
}
// Entry to dispatched function call
inline void SelectAddMul(
short int aa[], short int bb[], short int cc[]) {
// go to dispatched version
return (*SelectAddMul_pointer)(aa, bb, cc);
}
#endif // INSTRSET == 212.6 Transforming serial code for vectorization
并非所有的代码都具有可以轻松组织成向量的并行结构。很多代码是串行的,每个计算都依赖于前一个计算。然而,如果代码是重复的,仍然可以以一种可以向量化的方式组织代码。最简单的情况是对一长列表中的数字求和:
// Example 12.7a. Sum of a list
float a[100];
float sum = 0;
for (int i = 0; i < 100; i++) sum += a[i];上面的代码是串行的,因为每个sum的值都依赖于前一个sum的值。技巧在于通过n来展开循环,并重新组织代码,使得每个值都依赖于n个位置前的值,其中n是向量中元素的数量。如果n = 4,则有:
// Example 12.7b. Sum of a list, rolled out by 4
float a[100];
float s0 = 0, s1 = 0, s2 = 0, s3 = 0, sum;
for (int i = 0; i < 100; i += 4) {
s0 += a[i];
s1 += a[i+1];
s2 += a[i+2];
s3 += a[i+3];
}
sum = (s0+s1)+(s2+s3)现在,s0、s1、s2和s3可以组合成一个128位向量,以便我们可以使用一次操作进行四个加法。如果我们指定快速数学选项和SSE或更高的指令集,一个好的编译器将自动将示例12.7a转换为12.7b并向量化代码。
更复杂的情况无法自动向量化。例如,让我们看看泰勒级数的示例。指数函数可以通过以下级数计算:
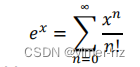
一个C++实现可能是这样的:
// Example 12.8a. Taylor series
float Exp(float x) { // Approximate exp(x) for small x
float xn = x; // x^n
float sum = 1.f; // sum, initialize to x^0/0!
float nfac = 1.f; // n factorial
for (int n = 1; n <= 16; n++) {
sum += xn / nfac;
xn *= x;
nfac *= n+1;
}
return sum;
}在这里,每个值xn都从前一个值计算而来,如xn = x∙xn-1,每个n!的值都从前一个值计算而来,如n! = n∙(n-1)!。如果我们想通过4来展开循环,我们将不得不从四个位置后的值计算每个值。因此,我们将计算xn为x4∙xn-4。没有简单的方法可以展开阶乘的计算,但这并不是必要的,因为阶乘不依赖于x,所以我们可以将这些值存储在预先计算的表中。更好的方法是:存储倒数的阶乘,这样我们就不必进行除法(除法很慢,你知道的)。代码现在可以向量化如下(使用向量类库):
// Example 12.8b. Taylor series, vectorized
#include "vectorclass.h" // Vector class library
// Approximate exp(x) for small x
float Exp(float x) {
// table of 1/n!
alignas(16) const float coef[16] = {
1., 1./2., 1./6., 1./24., 1./120., 1./720., 1./5040.,
1./40320., 1./362880., 1./3628800., 1./39916800.,
1./4.790016E8, 1./6.22702E9, 1./8.71782E10,
1./1.30767E12, 1./2.09227E13};
float x2 = x * x; // x^2
float x4 = x2 * x2; // x^4
// Define vectors of four floats
Vec4f xxn(x4, x2*x, x2, x); // x^1, x^2, x^3, x^4
Vec4f xx4(x4); // x^4
Vec4f s(0.f, 0.f, 0.f, 1.f); // initialize sum
for (int i = 0; i < 16; i += 4) { // Loop by 4
s += xxn * Vec4f().load(coef+i); // s += x^n/n!
xxn *= xx4; // next four x^n
}
return horizontal_add(s); // add the four sums
}这个循环在一个向量中计算四个连续的项。如果循环很长,速度可能受到xxn乘法的延迟而不是吞吐量的限制,因此进一步展开循环可能是值得的(参见第113页)。这里计算系数表是在编译时进行的。如果你能确保它只在函数被调用时计算一次而不是每次都计算,那么在运行时计算表可能更方便。
12.7 Mathematical functions for vectors
有各种函数库可以计算向量中的数学函数,例如对数、指数函数、三角函数等等。这些函数库对于矢量化数学代码很有用。
有两种不同类型的矢量数学库:长矢量库和短矢量库。为了解释它们的区别,假设你想在一千个数字上计算相同的函数。使用长向量库,你将一个包含一千个数字的数组作为参数传递给库函数,函数将一千个结果存储在另一个数组中。使用长向量库的缺点是,如果你正在执行一个序列的计算,那么你必须在调用下一个步骤的函数之前将每个步骤的中间结果存储在一个临时数组中。使用短向量库,你将数据集分成适合CPU中矢量寄存器大小的子向量。如果矢量寄存器可以容纳8个数字,那么你需要8个数字打包成一个矢量寄存器,然后125次调用库函数,每次调用8个数字。库函数将在矢量寄存器中返回结果,可以直接传递给计算序列中的下一个步骤,无需在RAM内存中存储中间结果。尽管调用了额外的函数,这可能会更快,因为CPU可以在同时预取下一个函数的代码时进行计算。然而,如果计算序列形成长的依赖链,短向量方法可能处于劣势。我们希望CPU在完成对第一个子向量的计算之前开始对第二个子向量进行计算。长的依赖链可能会填满CPU中待处理指令队列,防止它充分利用其乱序计算能力。
这里列出了一些长矢量数学库:
• Intel向量数学库(VML、MKL)。适用于所有x86平台。在非Intel CPU上的性能尚不确定。请参见第Error!Bookmark not defined.页。
• Intel性能原语(IPP)。适用于所有x86平台。与非Intel CPU配合良好。包括许多用于统计、信号处理和图像处理的函数。
• Yeppp。开源库。支持x86和ARM平台以及各种编程语言。www.yeppp.info
这里是一些短向量数学库的列表:
• Sleef库。支持许多不同的平台。开源库。www.sleef.org
• Intel短向量数学库(SVML)。这是与Intel编译器一起提供的,并且通过自动矢量化调用。如果您不使用Intel编译器,该库通常也适用于非Intel CPU。参见第Error!Bookmark not defined.页。
• 大多数编译器都包含一个用于自动矢量化循环中的数学函数的矢量数学库。请参见下面的讨论。
• VCL矢量类库。开源库。支持所有x86平台,包括Microsoft、Intel、Gnu和Clang编译器。代码已内联,无需链接外部库。https://github.com/vectorclass
所有这些库都具有非常好的性能和精度。其速度比任何非矢量化库快得多。
矢量数学库中的函数名称并不总是很好地文档化。如果您想直接调用库函数,此表中的示例可能会有所帮助:
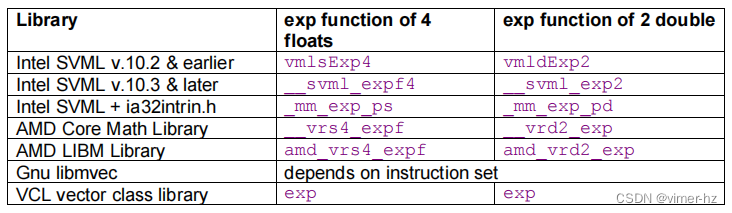
Using short vector math libraries with different compilers
只有存在包含这些函数的向量版本,且具有向量输入和向量输出的函数库,才能对包含数学函数的循环进行矢量化处理(sqrt函数不需要外部库)。
早期的Gnu编译器有一个使用Intel提供的名为SVML(Short Vector Math Library)的外部库的选项。现在,Gnu编译器有自己的矢量数学库,名为libmvec,如果需要的话会自动链接。
Clang编译器目前没有矢量数学库。Clang 12及更高版本有一个选项fveclib=libmvec,可以使其使用Gnu的矢量数学库。
Microsoft编译器(2022年版17版本)有自己的矢量数学库,在需要时会自动链接。
所有版本的Intel编译器都包含高度优化的SVML库,会自动链接。SVML库针对Intel处理器进行了优化,但在非Intel处理器上也能提供令人满意的性能,除非与Intel编译器的旧版本(称为“classic”)一起使用。
对于矢量化数学函数的另一种解决方案是使用Vector Class Library(链接)(第125页有描述)。该矢量类库提供了以矢量形式的内联数学函数。它还包括与Intel的SVML库的可选接口。这适用于上述提到的所有编译器。
Gnu的libmvec库目前只包含最基本的函数,如sin、cos、pow、log、exp。其他库还包含反三角函数、双曲函数等。SVML库包含最多的数学函数。SVML库可以与除Intel以外的其他编译器一起使用,但其调用接口文档较差。SVML还包含未记录的函数,例如sinpi。
这些不同的库使用不同的计算方法,但它们都能提供相当精确的准确度。
很难比较不同的矢量数学库的性能。在数据处于合理范围内的一般情况下,所有的矢量数学库都能提供良好的性能,但它们在处理极端数据值和特殊情况时的效率差异很大。libmvec库在特殊情况下会退回到标量函数,以确保即使是最罕见的情况也能正确处理。Microsoft和Intel的SVML库也使用大分支来处理特殊情况。只有Vector Class Library在主程序流中处理特殊情况而无需分支。这在所有特殊情况下都能提供优越的性能,但对于极端输入值,代码可能会过早溢出或下溢。
要确定哪个矢量数学库在特定情况下最有效,需要考虑的不仅是简单数据值的性能,还包括它在应用中是否常见的INF、NAN、亚正规数和极端值等数据值的处理情况。
12.8 Aligning dynamically allocated memory
使用new或malloc分配的内存在不同平台上会按8或16字节对齐。当需要16字节或更高对齐时,这会对矢量操作造成问题。C++ 17标准在使用operator new时会自动提供所需的对齐方式:
// Example 12.9
// Aligned memory allocation in C++17
int arraysize = 100;
__m512 * pp = new __m512[arraysize];
// pp will be aligned by alignof(__m512) if using C++1712.9 Aligning RGB video or 3-dimensional vectors
RGB图像数据每个点有三个值。这无法适应例如四个浮点数的向量。对于三维几何和其他奇数大小的向量数据也是如此。出于效率考虑,数据必须按照向量大小进行对齐。使用非对齐的读写操作可能会降低执行速度,甚至不如使用向量操作优势明显。根据具体算法,您可以选择以下解决方案之一:
- 增加一个未使用的第四个值,使数据适应向量。这是一种简单的解决方案,但会增加所使用内存的数量。如果内存访问是瓶颈,您可以避免使用此方法。
- 将数据组织成每组四个(或八个)点,其中第一个向量包含四个R值,下一个向量包含四个G值,最后一个向量包含四个B值。
- 将数据按照所有R值、所有G值,最后所有B值的顺序组织。
选择使用哪种方法取决于适合特定算法的情况。您可以选择最简单的代码方法。
如果点的数量无法被向量大小整除,则在末尾添加一些未使用的点,以获得整数个向量。
12.10 Conclusion
如果算法允许并行计算,使用向量化代码可以大幅提高速度。收益取决于每个向量的元素数量。最简单和最简洁的解决方案是依靠编译器的自动向量化。在并行性明显并且代码只包含简单标准操作的简单情况下,编译器将自动进行向量化。您只需要启用适当的指令集和相关的编译器选项。
然而,有许多情况下编译器无法自动向量化代码,或者以次优的方式进行向量化。在这种情况下,您需要显式地对代码进行向量化。有多种方法可以做到这一点:
- 使用汇编语言
- 使用内部函数
- 使用预定义的向量类
显式向量化代码的最简单方法是使用向量类库。如果需要向量类库中未定义的功能,可以与内部函数结合使用。选择使用内部函数还是向量类通常只是一种方便的问题 - 在性能上通常没有区别。内部函数具有看起来笨拙而繁琐的长名称。当您使用向量类和重载运算符时,代码更易读。
在您手动向量化代码后,优秀的编译器通常能进一步优化代码。编译器可以使用优化技术,如函数内联、公共子表达式消除、常量传播、循环优化等。手动汇编编码中很少使用这些技术,因为这会使代码难以处理、容易出错,并且几乎不可能维护。手动向量化与编译器进一步优化的结合通常可以在复杂情况下获得最佳结果。
可能需要一些实验才能找到最佳解决方案。您可以查看汇编输出或调试器中的反汇编显示,以检查编译器的操作。
向量化的代码通常包含大量额外的指令,用于将数据转换为正确的格式并将其放置在向量中的正确位置。有时,这种数据转换和排列可能比实际计算所花费的时间还要多。在决定是否要使用向量化代码时,应考虑到这一点。VCL(Vector Class Library)中有一些非常有用的排列函数,可以自动找到特定排列模式的最优实现。
总结决定向量化优势的因素如下。
Factors that make vectorization favorable:
• 小数据类型:char,int16_t,float。
• 对大型数组中的所有数据执行类似操作。
• 数组大小可被向量大小整除。
• 在两个简单表达式之间选择的不可预测分支。
• 仅能与向量操作数一起使用的操作:最小值、最大值、饱和加法、快速逼近倒数、快速逼近倒数平方根、RGB颜色差异。
• 可用的向量指令集,例如AVX2、AVX-512。
• 数学向量函数库。
• 使用GNU或Clang编译器。
Factors that make vectorization less favorable:
• 较大的数据类型:int64_t,double。
• 不对齐的数据。
• 需要额外的数据转换,排列,打包,解包。
• 可预测的分支,在未被选择时可以跳过较大的表达式。
• 编译器对指针对齐和别名的信息不足。
• 缺少适当类型向量指令集中的操作,例如SSE4.1之前的32位整数乘法和整数除法。
• 执行单元小于向量寄存器大小的旧CPU。
向量化代码对程序员来说更难以编写,因此更容易出错。因此,最好将向量化代码放在可重用且经过良好测试的库模块和头文件中。


















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









