






6.1实例识别 346
6.2图像分类 349
6.2.1基于特征的方法 350
6.2.2深度网络 358
6.2.3应用:视觉相似性搜索 360
6.2.4人脸识别 363
6.3目标检测 370
6.3.1人脸检测 371
6.3.2行人检测 376
6.3.3一般对象检测 379
6.4语义分割 387
6.4.1应用:医学图像分割 390
6.4.2实例分割 391
6.4.3全景分割 392
6.4.4应用:智能照片编辑 394
6.4.5姿态估计 395
6.5视频理解 396
6.6视觉和语言 400
6.7其他阅读材料 409
6.8练习 413

图6.1各类识别:(a)基于图像结构的人脸识别(Fischler和Elschlager 1973)©1973年IEEE;(b)实例(已知对象)识别(Lowe 1999)©1999年IEEE;(c)实时人脸检测(Viola和Jones 2004)©2004年Springer;(d)基于特征的识别(Fergus、Perona和Zisserman 2007)©2007年Springer;(e)使用Mask R-CNN进行实例分割(He、Gkioxari等人2017)©2017年IEEE;(f)姿态
估计(G ler、Neverova和Kokkinos2018)©2018 IEEE;(g)全景分割
(Kirillov,He等人,2019)©2019 IEEE;(h)视频动作识别(Feichtenhofer,Fan等人,2019);(i)图像描述(Lu,Yang等人,2018)©2018 IEEE。
在这本书涵盖的所有计算机视觉主题中,视觉识别在过去十年经历了最大的变化和最快的发展,部分原因是由于更大规模的标注数据集的可用性以及深度学习方面的突破(图5.40)。在本书的第一版(Szeliski2010)中,识别是最后一章,因为它被认为是一项“高级任务”,需要建立在特征检测和匹配等低级组件之上。事实上,许多入门级的视觉课程仍然在最后教授识别,通常先介绍“经典”(非学习型)视觉算法和应用,然后再转向深度学习和识别。
正如我在前言和引言中提到的,我已将机器学习和深度学习移到了书的开头部分,因为这些是计算机视觉其他领域广泛使用的基础技术。我还决定将识别章节放在深度学习之后,因为大多数现代识别技术都是深度神经网络的自然应用。旧的识别章节大部分已被更新的深度学习技术所取代,因此你有时会看到对经典识别技术的简要描述,以及指向第一版和相关综述或开创性论文的链接。
一个经典的例子是实例识别,我们试图找到特定制造对象的范例,如停车标志或运动鞋(图6.1b)。(更早的例子是使用相对特征位置进行面部识别,如图6.1a所示。)寻找独特特征的同时处理局部外观变化的一般方法(第7.1.2节),然后检查它们在图像中的共现和相对位置,至今仍广泛用于制造3D物体检测(图6.3)、3D结构和姿态恢复(第11章)以及位置识别(第11.2.3节)。高度准确且广泛应用的基于特征的实例识别方法是在2000年代开发的(图7.27),尽管最近出现了基于深度学习的替代方案,但这些方法通常仍然是首选(Sattler,Zhou等,2019)。我们在第6.1节回顾了实例识别,尽管一些必要的组件,如特征检测、描述和匹配(第7章),以及3D姿态估计和验证(第11章),将在后续章节中介绍。
更难的问题是类别或类别的识别(例如,识别高度变化的类别成员,如猫、狗或摩托车),最初也是通过基于特征的方法和相对位置(部分模型)来解决的,如图6.1d所示。我们在第6.2节中讨论图像分类(即全图类别识别)时,首先回顾这些“经典”(尽管现在很少使用)的技术。然后,我们展示前一章中描述的深度神经网络如何非常适合这类分类问题。接下来,我们讨论视觉相似性搜索,在这种情况下,不是将图像归类到预定义的数量中。
在分类中,我们检索出语义相似的其他图像。最后,我们专注于人脸识别,这是计算机视觉研究时间最长的主题之一。
在第6.3节中,我们转向物体检测这一主题,在这里我们不仅对整个图像进行分类,还通过边界框标出了各种物体的位置。这一主题包括更专业的变体,如面部检测和行人检测,以及通用类别的物体检测。在第6.4节中,我们研究了语义分割,任务是精确到像素地标出不同的物体和材料,即为每个像素标注一个物体的身份和类别。与此相关的变体包括实例分割,每个独立的物体获得一个独特的标签;全景分割,物体和背景(例如草地、天空)都得到标注;姿态估计,像素被标记为人体部位和方向。本章最后两节简要涉及视频理解(第6.5节)和视觉与语言(第6.6节)。
在开始描述个体识别算法及其变体之前,我应该简要提及大规模数据集和基准测试在识别系统快速进步中所起的关键作用。虽然像Xerox 10 (Csurka,Dance等人,2006年)和Caltech-101 (Fei-Fei,Fergus,和Perona,2006年)这样的小型数据集在评估物体识别系统方面发挥了早期作用,但PASCAL视觉对象类别(VOC)挑战赛(Everingham,Van Gool等人,2010年;Everingham,Eslami等人,2015年)是第一个足够大且具有挑战性的数据集,显著推动了该领域的发展。然而,PASCAL VOC仅包含20个类别。ImageNet数据集(Deng,Dong等人,2009年;Rusakovsky,Deng等人,2015年)的引入,拥有1,000个类别和超过一百万张标注图像,最终提供了足够的数据,使端到端学习系统得以突破。微软COCO(上下文中的常见对象)数据集进一步促进了发展(Lin,Maire等人,2014年),特别是在精确的对象分割方面,我们将在第6.4节中研究。关于构建此类数据集的人工众包方法的精彩综述见(Kovashka,Russakovsky等人,2016年)。本章将提到其他有时更为专业的数据集。最流行和活跃的数据集和基准测试列表见表6.1至6.4。
一般物体识别分为两类,即实例识别和类别识别。前者涉及重新识别一个已知的二维或三维刚性物体,可能从一个新的视角观察,在杂乱的背景中,并且部分

图6.2在杂乱场景中识别物体(Lowe2004)©2004斯普林格。数据库中的两张训练图像显示在左侧。它们通过SIFT特征与中间的杂乱场景匹配,这些特征以小方块的形式显示在右侧图像中。每个识别出的数据库图像在场景中的仿射变换显示为右侧图像中较大的平行四边形。
闭塞。1后者也被称为类别级或通用对象识别(Ponce,Hebert等人,2006),是识别特定一般类别的任何实例的更具挑战性的问题,如“猫”、“汽车”或“自行车”。
多年来,为实例识别开发了许多不同的算法。Mundy(2006)回顾了早期的方法,这些方法侧重于从图像中提取线条、轮廓或三维表面,并将其与已知的三维物体模型进行匹配。另一种流行的方法是从大量视角和光照条件下获取图像,并使用特征空间分解来表示它们(Murase和Nayar 1995)。更近一些的方法包括Lowe(2004)、Lepetit和Fua(2005)、Rothganger、Lazebnik等人(2006)以及Ferrari,
Tuytelaars和Van Gool2006b;Gordon和Lowe2006;Obdr lek和Matas2006;Sivic
并且Zisserman2009;Zheng,Yang和Tian2018)倾向于使用视角不变的二维特征,例如我们将在第7.1.2节中讨论的那些。从新图像和数据库中的图像中提取出具有信息量的稀疏二维特征后,使用第7.1.3节描述的一种稀疏特征匹配策略,将图像特征与对象数据库进行匹配。每当找到足够数量的匹配项时,通过寻找一个几何变换来对齐两组特征(图6.2)来进行验证。

图6.3使用仿射区域的三维物体识别(Rothganger、Lazebnik等人,2006年)©
2006斯普林格:(a)样本输入图像;(b)五个识别(重投影)的对象及其边界框;(c)几个局部仿射区域;(d)局部仿射区域(补丁)重投影到标准(正方形)框架中,连同其几何仿射变换。
为了识别一个或多个已知对象的实例,如图6.2左栏所示,识别系统首先在每个数据库图像中提取一组兴趣点,并将相关的描述符(及原始位置)存储在一个索引结构中,例如搜索树(第7.1.3节)。在识别时,从新图像中提取特征并与存储的对象特征进行比较。每当找到足够数量的匹配特征(比如三个或更多)时,系统就会调用匹配验证阶段,其任务是确定匹配特征的空间排列是否与数据库图像中的特征一致。
因为图像可能高度杂乱,相似特征可能属于多个对象,原始特征匹配集可能会包含大量异常值。因此,Lowe(2004)建议使用霍夫变换(Section7.4.2)来累积可能的几何变换的投票。在他的系统中,他使用了数据库对象与场景特征集合之间的仿射变换,这种方法对于主要是平面的物体或至少有几个对应特征具有准平面几何形状的物体效果很好。
另一种使用局部仿射框架的系统是由Rothganger、Lazebnik等人(2006)开发的。在他们的系统中,使用了Mikolajczyk和Schmid(2004)提出的仿射区域检测器来校正局部图像块(Figure6.3d),从中计算出SIFT描述子和10×10 UV颜色直方图,并用于匹配和识别。同一物体不同视角下的相应块及其局部仿射变形被用来计算该物体的三维仿射模型,通过扩展的方法实现。
第11.4.1节的分解算法,然后可以升级为欧几里得重建(Tomasi和Kanade1992)。在识别时,使用局部欧几里得邻域约束来过滤潜在匹配,类似于仿射几何
Lowe(2004)和Obdr lek和Matas(2006)使用的限制条件。图6.3显示了使用这种方法识别杂乱场景中的五个物体的结果。
虽然基于特征的方法通常用于检测和定位场景中的已知对象,但也可以根据这些匹配获得场景的像素级分割。法拉利、图特拉尔斯和范古尔(2006b)描述了一种同时识别对象和分割场景的系统,而卡纳拉、拉图等人(2008)则将这种方法扩展到非刚性变形。第6.4节重新审视了在通用类别(类别)识别背景下联合识别和分割的主题。
虽然在2000年代初期到中期,实例识别主要集中在图像中定位已知的三维物体,如图6.2-6.3所示,但注意力逐渐转向了更具挑战性的实例检索问题(也称为基于内容的图像检索),在这种情况下,需要搜索的图像数量可能非常庞大。第7.1.4节回顾了此类技术,其概览可参见图7.27以及郑、杨和田(2018)的综述。这一主题还与视觉相似性搜索(第6.2.3节)和三维姿态估计(第11.2节)相关。
虽然实例识别技术相对成熟,并被用于商业应用,如交通标志识别(Stallkamp,Schlipsing等,2012),但通用类别(类)识别仍然是一个快速发展的研究领域。例如,考虑图6.4a中的照片集,这些照片展示了来自10个不同视觉类别的对象。(我留给你们来命名每个类别。)你将如何编写一个程序,将这些图像分类到适当的类别中,特别是如果你还被提供了“以上都不是”的选项?
从这个例子可以看出,视觉类别识别是一个极其具有挑战性的问题。然而,如果以今天的算法比十年前的算法好多少来衡量,这个领域的进步是相当惊人的。
在本节中,我们回顾了用于全图像分类的主要算法类别。我们首先介绍基于经典特征的方法,这些方法依赖于手工设计的特征及其统计特性,有时还会使用机器学习来进行最终分类(图5.2b)。由于这类技术已不再广泛使用,我们仅简要描述最重要的几种方法。更多细节可参见本书的第一版。

图6.4图像识别的挑战:(a)来自Xerox 10类数据集的样本图像(Csurka,Dance等人,2006年)©2007年施普林格出版社;(b)来自ImageNet数据集的难度和变化轴(Russakovsky,Deng等人,2015年)©2015年施普林格出版社。
(Szeliski2010,第14章)以及引用的期刊论文和综述。接下来,我们描述基于前一章介绍的深度神经网络的现代图像分类系统。然后,我们讨论视觉相似性搜索,其任务是找到视觉上和语义上相似的图像,而不是归类到固定的类别中。最后,我们探讨人脸识别,因为这一主题有着悠久的历史。
6.2.1基于特征的方法
在本节中,我们回顾了基于特征的经典类别识别(图像分类)方法。历史上,基于部件的表示和识别算法(第6.2.1节)是首选方法(Fischler和Elschlager 1973;Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman 2007),我们首先描述了相似性-

图6.5来自两个广泛使用的图像分类数据集的样本图像:(a) Pascal视觉对象类别(VOC)(Everingham,Eslami等人,2015年)©2015 Springer;(b) ImageNet (Russakovsky,Deng等人,2015年)©2015 Springer。
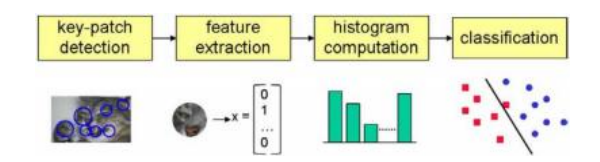
图6.6一个典型的词袋分类系统处理流程(Csurka,Dance等,2006)©2007斯普林格。首先在关键点处提取特征,然后量化以获得学习到的视觉词汇(特征聚类中心)上的分布(直方图)。利用特征分布直方图通过分类算法,如支持向量机,来学习决策面。
特征包方法将对象和图像表示为无序的特征描述子集合。接着,我们回顾了基于部件模型构建的更复杂系统,然后探讨上下文和场景理解以及机器学习如何提升整体识别效果。本节介绍的技术详情可参见早期的综述文章、论文集和课程(Pinz2005;Ponce,Hebert等2006;Dickinson,Leonardis等2007;Fei-Fei,Fergus和Torralba 2009),以及关于帕斯卡和ImageNet识别挑战的两篇综述文章(Everingham,Van Gool等2010;Everingham,Eslami等2015;Russakovsky,Deng等2015)和本书的第一版(Szeliski2010,第14章)。
词袋
类别识别中最简单的算法之一是词袋模型(也称为特征包或关键点包)方法(Csurka,Dance等2004;Lazebnik,Schmid和Ponce 2006;Csurka,Dance等2006;Zhang,Marszalek等2007)。如图6.6所示,该算法仅计算查询图像中视觉词汇的分布(直方图),并将此分布与训练图像中的分布进行比较。我们将在第7.1.4节中详细讨论这种方法。与实例识别最大的不同在于缺少几何验证阶段(第6.1节),因为通用视觉类别的单个实例,如图6.4a所示,其特征之间的空间一致性相对较低(但参见Lazebnik,Schmid和Ponce(2006)的研究)。
Csurka、Dance等人(2004)首次使用“关键点包”一词来描述此类方法,并且是最早证明基于频率的技术的效用的人之一
类别识别。他们最初的系统使用了仿射协变区域和SIFT描述子、k均值视觉词汇构建,以及朴素贝叶斯分类器和支持向量机进行分类。(后者表现
更佳。)他们的新系统(Csurka,Dance等人,2006年)采用了规则的(非仿射的)SIFT补丁和提升方法,而不是支持向量机,并结合了一小部分几何一致性信息。
张、马尔扎莱克等人(2007)对这种特征包系统进行了更详细的研究。他们比较了多种特征检测器(哈里斯-拉普拉斯(米科拉伊奇和施密特2004)和拉普拉斯(林德伯格1998b)、描述子(SIFT、RIFT和SPIN(拉泽比尼克、施密特和庞斯2005))以及SVM核函数。
格劳曼和达雷尔(2007b)没有将特征向量量化为视觉词汇,而是开发了一种直接计算两个大小可变的特征向量集合之间近似距离的技术。他们的方法是将特征向量归类到特征空间中定义的多分辨率金字塔中,并统计落在相应箱内的特征数量。两组特征向量之间的距离(可以视为高维空间中的点)通过对应箱之间的直方图交集计算得出,同时排除在更细层次上已找到的匹配项,并更重地加权更精细的匹配。在后续工作中,格劳曼和达雷尔(2007a)展示了如何使用哈希技术避免显式构建金字塔。
受到这项工作的启发,Lazebnik、Schmid和Ponce(2006)展示了如何利用类似的思想来增强关键点包,引入类似于SIFT(Lowe 2004)和“gist”(Torralba,Murphy等2003)所执行的池化操作的松散二维空间位置概念。在他们的工作中,他们提取了仿射区域描述符(Lazebnik,Schmid和Ponce 2005),并将其量化为视觉词汇。(基于Fei-Fei和Perona(2005)的先前研究,特征描述符在图像上以密集方式(在规则网格上)提取,这有助于描述如天空等无纹理区域。)然后,他们形成一个包含词汇计数(直方图)的空间金字塔,并使用类似的金字塔匹配核以层次方式结合直方图交集计数。
关于是否使用量化特征描述子或连续描述子,以及是否使用稀疏或密集特征的争论持续了多年。Boiman、Shechtman和Irani(2008)指出,如果将查询图像与表示某一类的所有特征进行比较,而不仅仅是每个类别图像单独比较,最近邻匹配
然后是一个na
。而不是我们
在研究通用特征检测器和描述符的同时,一些作者一直在探索学习特定类别特征的方法(Ferencz、Learned-Miller和Malik 2008),通常使用随机森林(Philbin、Chum等2007;Moosmann、Nowak和Jurie 2008;Shotton、Johnson和Cipolla 2008)或结合特征生成和图像分类阶段(Yang,

图6.7使用图像结构定位和跟踪人物(Felzenszwalb和Huttenlocher 2005)©2005斯普林格。该结构由可活动的矩形身体部分(躯干、头部和四肢)组成,这些部分以树状拓扑连接,编码相对部位的位置和方向。为了拟合图像结构模型,首先使用背景减除计算出二值轮廓图像。
Jin等人(2008))。其他研究者,如Serre、Wolf和Poggio(2005)以及Mutch和Lowe(2008)则使用了受生物(视觉皮层)处理启发的密集特征变换层次结构,并结合SVM进行最终分类。
基于部件的模型
通过识别物体的组成部分并测量它们之间的几何关系,是物体识别中最古老的方法之一(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991)。基于部件的方法常用于人脸识别(Moghaddam和Pentland 1997;Heisele、Ho等2003;Heisele、Serre和Poggio 2007),并且继续被用于行人检测(图6.24)(Felzenszwalb、McAllester,
以及Ramanan2008)和姿态估计(G ler、Neverova和Kokkinos2018)。
在这篇综述中,我们讨论了基于部件识别的一些核心问题,即几何关系的表示、单个部件的表示以及学习这些描述并在运行时识别它们的算法。关于基于部件的识别模型的更多细节,可参见Fergus(2009)的课程笔记。
Fischler和Elschlager(1973)将最早用于表示几何关系的方法称为图像结构,它由不同特征位置之间的弹簧式连接组成(图6.1a)。为了将图像结构拟合到图像中,能量函数的形式为
E = Σi Vi(li)+ i Vij(li;lj
) (6.1)
在所有可能的部件位置或姿态{li }和存在边(几何关系)的部件对(i,j)上最小化。请注意,这种能量与用于马尔可夫随机场(4.35–4.38)的能量密切相关,后者可以将图像结构嵌入到一个概率框架中,使参数学习更加容易(Felzenszwalb和Huttenlocher 2005)。
基于部件的模型可以有不同的几何连接拓扑结构(Carneiro和Lowe 2006)。例如,Felzenszwalb和Huttenlocher(2005)将连接限制为树状结构,这使得学习和推理更加可行。树状拓扑结构允许使用递归维特比(动态规划)算法(Pearl 1988;Bishop 2006),其中叶节点首先根据其父节点进行优化,然后将得到的值代入并从能量函数中消除。为了进一步提高推理算法的效率,Felzenszwalb和Huttenlocher(2005)将成对能量函数Vij(li,lj)限制为位置变量函数的马氏距离,并使用快速距离变换算法在接近线性的N时间内最小化每个成对交互。
图6.7展示了使用他们的图像结构算法将关节模型拟合到通过背景分割获得的二值图像的结果。在这个图像结构的应用中,部件由其近似矩形的位置、大小和方向参数化。一元匹配势能Vi(li)是通过计算每个部件所代表的倾斜矩形内外的前景和背景像素百分比来确定的。
许多不同的图形模型已被提出用于基于部件的识别。卡内罗和洛(2006)讨论了其中一些模型,并提出了他们自己的一个模型,称为稀疏灵活模型;该模型涉及对部件进行排序,并且每个部件的位置最多依赖于其k个祖先位置。
最简单的模型是词袋模型,在这种模型中,不同部分或特征之间没有几何关系。虽然这类模型可以非常高效,但它们在表达部件的空间排列方面的能力非常有限。树和星(一种特殊的树,其中所有叶节点都直接连接到一个共同的根)在推理方面最为高效,因此在学习方面也是如此(Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman2005;Felzenszwalb,McAllester以及Ramanan 2008)。有向无环图在复杂度上紧随其后,仍然能够支持高效的推理,尽管这会强加一个因果结构到部件模型上(Bouchard和Triggs 2005;Carneiro和Lowe 2006)。k-扇形模型中,大小为k的团构成了星形模型的根,其推理复杂度为O(N^k+1),但通过距离变换和高斯先验,这一复杂度可以降低到O(N^k)(Crandall、Felzenszwalb和Huttenlocher

图6.8上下文的重要性(图片由安东尼奥·托拉尔巴提供)。你能说出图像(a-b)中所有物体的名字吗,特别是那些被圈出的(c-d)。仔细观察这些圈出的物体。你是否注意到它们都有相同的形状(旋转后),如列(e)所示?
2005年;Crandall和Huttenlocher2006年)。最后,完全连接的星座模型是最通用的,但是对于中等数量的部件P,特征分配到部件变得难以处理,因为这种分配的复杂度是O(NP)(Fergus、Perona和Zisserman2007年)。
原始星座模型由伯尔、韦伯和佩罗纳(1998)开发,包含多个部分,这些部分的相对位置通过它们的平均位置和一个完整的协方差矩阵来编码,该矩阵不仅表示位置不确定性,还表示不同部分之间的潜在关联。韦伯、韦林和佩罗纳(2000)将这一技术扩展到弱监督设置,在这种设置下,每个部分的外观及其位置都可以根据整个图像标签自动学习。费格斯、佩罗纳和齐瑟曼(2007)进一步将这种方法扩展到从尺度不变的关键点检测中同时学习外观和形状模型。
基于部件的识别方法也被扩展到从少量示例中学习新类别,这建立在为其他类别开发的识别组件之上(Fei-Fei,Fergus和Perona 2006)。可以利用语法的概念开发更复杂的层次化部件模型(Bouchard和Triggs 2005;Zhu和Mumford 2006)。一种更简单的方法是使用关键点,这些关键点被识别为属于估计部件位置的类别投票(Leibe,Leonardis和Schiele 2008)。如图6.9所示,部件也可以成为细粒度类别识别系统中的有用组件。
情境和场景理解
到目前为止,我们主要考虑的是识别和定位物体的任务,而不是理解物体出现的场景(上下文)。这是一个很大的问题。
限制,因为上下文在人类物体识别中扮演着非常重要的角色(Oliva和Tor- ralba2007)。上下文可以极大地提高物体识别算法的性能(Divvala,Hoiem等人2009),同时为一般场景理解提供有用的语义线索(Torralba2008)。
考虑图6.8a-b中的两张照片。你能说出所有物体的名字吗,特别是那些在图像(c-d)中圈出的物体?现在仔细看看这些圈出的物体。你是否发现它们的形状有相似之处?事实上,如果你将它们旋转90°,它们都与图6.8e中所示的“团块”相同。这就是我们通过形状来识别物体的能力!
尽管我们在本章前面没有明确讨论上下文,但我们已经看到了这一普遍概念的几个实例。一种简单的方法是将空间信息融入识别算法中,即在不同区域计算特征统计,如拉泽布尼克、施密德和庞斯(2006)提出的空间金字塔系统。基于部件的模型(图6.7)使用了一种局部上下文,其中各个部件需要以正确的几何关系排列,才能构成一个物体。
基于部件和基于上下文模型之间的最大区别在于,后者将对象组合成场景,而每个类别的组成对象数量事先并不知道。实际上,可以将基于部件和基于上下文的模型结合在同一识别架构中(Murphy,Torralba和Freeman 2003;Sudderth,Torralba等2008;Crandall和Huttenlocher 2007)。
考虑一个包含街道和办公室场景的图像数据库。如果我们有足够的训练图像,并且这些图像中带有标记区域,如建筑物、汽车和道路,或者显示器、键盘和鼠标,我们就可以开发出一种几何模型来描述它们之间的相对位置。苏德斯、托拉尔巴等人(2008)开发了这样一个模型,可以将其视为一个两层星座模型。在顶层,物体之间的相对分布(例如,建筑物相对于汽车)被建模为高斯分布。在底层,物体中心相对于各部分(仿射协变特征)的分布则使用高斯混合模型进行建模。然而,由于场景中的物体数量以及每个物体中的部分数量未知,因此使用潜在狄利克雷过程(LDP)在生成框架中建模物体和部分的创建。所有物体和部分的分布都是从一个大型标注数据库中学习得到的,然后在推理(识别)过程中用于标记场景中的元素。
另一个上下文的例子是在同时分割和识别中(第6.4节和图6.33),场景中各种物体的排列被用作标注过程的一部分。托拉尔巴、墨菲和弗里曼(2004)描述了一种条件随机场,其中建筑物和道路的估计位置影响汽车的检测,并使用增强学习来学习CRF的结构。拉比诺维奇、韦达利等人(2007)
利用上下文改进CRF分割的结果,注意某些相邻关系(关系)比其他关系更可能成立,例如,一个人骑马的可能性比骑狗的大。Galleguillos和Belongie(2010)回顾了为对象分类添加上下文的各种方法,而Yao和Fei-Fei(2012)研究了人与物体的互动。(关于这一问题的最新观点,参见Gkioxari、Girshick等人(2018)。)
上下文在单张图像的三维推断中也起着重要作用(图6.41),利用计算机视觉技术将像素标记为属于地面、垂直表面或天空(Hoiem,Efros,和Hebert 2005a)。这一研究方向已扩展到一种更为全面的方法,同时推理物体的身份、位置、表面方向、遮挡和相机视角参数(Hoiem,Efros,和Hebert 2008)。
许多方法利用场景的大致轮廓(Torralba2003;Torralba,Murphy等2003)来确定特定物体实例可能出现的位置。例如,Murphy、Torralba和Freeman(2003)训练了一个回归器,根据图像的大致轮廓预测行人、汽车和建筑物(或室内办公场景中的屏幕和键盘)的垂直位置。这些位置分布随后与经典对象检测器结合使用,以提高检测器的性能。大体轮廓还可以直接匹配完整图像,正如我们在Hays和Efros(2007)的场景补全工作中所见。
最后,场景理解的一些工作利用了大量标注(甚至未标注)图像的存在,直接对整个图像进行匹配,其中图像本身隐含地编码了物体之间的预期关系(Russell,Torralba等2007;Malisiewicz和Efros 2008;Galleguillos和Belongie 2010)。当然,这是使用深度神经网络的一个核心优势,我们将在下一节中讨论。
正如我们在第5.4.3节中所见,随着Krizhevsky、Sutskever和Hinton(2012)提出的“AlexNet”超级视觉系统在ImageNet大规模视觉识别挑战赛(ILSVRC)上的引入,深度网络开始超越基于学习的“浅层”方法。自那时起,识别准确率继续显著提高(图5.40),很大程度上得益于更深的网络和更优的训练算法。最近,更高效的网络成为研究的重点(图5.45),同时更大的(未标注的)训练数据集也受到关注(第5.4.7节)。现在有诸如Classy Vision3这样的开源框架,可用于训练和微调自己的图像和视频分类模型。
图6.9使用部件进行细粒度类别识别(张、多纳休等,2014)©2014斯普林格。深度神经网络物体和部件检测器经过训练,其输出通过几何约束结合。最终分类使用从提取的部件特征训练的分类器完成。
看看许多流行的计算机视觉模型在自己的图像上表现如何。
除了识别图像网络和COCO数据集中常见的类别外,研究人员还研究了细粒度类别识别问题(段、帕里克等,2012;张、多纳休等,2014;克劳斯、金等,2015),其中子类之间的差异可能非常微妙,且示例数量极少(图6.9)。细粒度子类的例子包括花卉(尼尔斯巴克和齐瑟曼,2006)、猫和狗(帕尔希、韦达利等,2012)、鸟类(瓦赫、布兰森等,2011;范霍恩、布兰森等,2015)以及汽车(杨、罗等,2015)。最近的一个细粒度分类例子是iNaturalist系统(范霍恩、麦克奥达等,2018),该系统允许专家和公民科学家拍摄并标注生物物种,使用细粒度类别识别系统来标注新图像(图6.10a)。 细粒度分类通常通过图像和类别的属性进行攻击(Lampert、Nickisch和Harmeling 2009;Parikh和Grauman 2011;Lampert、Nickisch和Harmeling 2014),如图Figure6.10b所示。提取属性可以实现零样本学习(Xian、Lampert等2019),即使用这些属性的组合来描述以前未见过的类别。然而,为了不

图6.10细粒度类别识别。(a)iNaturalist网站和应用程序允许公民科学家通过手机收集和分类图像(Van Horn,Mac Aodha等,2018)©2018 IEEE。(b)属性可用于细粒度分类和零样本学习(Lampert,Nickisch,和Harmeling,2014)©2014斯普林格。这些图像是“具有属性的动物”数据集的一部分。
学习不同属性之间的虚假关联(Jayaraman、Sha和Grauman 2014)或对象与其共同上下文之间的关联(Singh、Mahajan等2020)。细粒度识别也可以通过度量学习(Wu、Manmatha等2017)或最近邻视觉相似性搜索(Touvron、Sablayrolles等2020)来解决,我们将在下文讨论这些方法。
使用计算机视觉算法自动将图像分类并用属性标记,使得在目录和网络中查找它们变得更加容易。这在图像搜索或图像检索引擎中很常见,这些引擎根据关键词找到可能的图像,就像常规的网络搜索引擎找到相关的文档和页面一样。
然而,有时从图像中找到所需信息更为容易,即使用视觉搜索。例如,我们刚刚看到的细粒度分类,以及实例检索,即找到完全相同的对象(第6.1节)或位置(第11.2.3节)。另一种变体是寻找视觉相似的图像(通常称为视觉相似性搜索或反向图像搜索),当搜索意图无法用简洁的语言表达时,这种方法非常有用。6

图6.11 GrokNet产品识别服务用于产品标记、视觉搜索和推荐©Bell,Liu等人(2020):(a)识别照片中的所有产品;(b)使用弱监督数据增强自动获取数据进行度量学习。
视觉相似性搜索这一主题历史悠久,有多种名称,包括图像内容查询(QBIC)(Flickner,Sawhney等,1995)和基于内容的图像检索(CBIR)(Smeulders,Worring等,2000;Lew,Sebe等,2006;Vasconcelos,2007;Datta,Joshi等,2008)。这些领域的早期研究主要基于简单的全图相似度指标,如颜色和纹理(Swain和Ballard,1991;Jacobs,Finkelstein和Salesin,1995;Manjunathi和Ma,1996)。
后来的架构,如Fergus、Perona和Zisserman(2004)提出的,使用基于特征的学习和识别算法来重新排序传统关键词图像搜索引擎的输出结果。在后续工作中,Fergus、Fei-Fei等人(2005)利用概率最新语义分析(PLSA)(Hofmann 1999)的扩展方法对图像搜索返回的结果进行聚类,然后选择与最高排名结果相关的聚类作为该类别的代表性图像。其他方法则依赖于精心标注的图像数据库,例如LabelMe (Russell、Torralba等人2008)。例如,Malisiewicz和Efros(2008)描述了一个系统,该系统可以根据查询图像找到类似的LabelMe图像;而Liu、Yuen和Torralba(2009)则将基于特征的对应算法与标记数据库结合,以实现同时识别和分割。
新的视觉相似性搜索方法使用了诸如费舍尔核和局部聚合描述子向量(VLAD)(J gou,Perronnin等,2012)或池化卷积神经网络激活(Babenko和Lempitsky,2015a;Tolias
,Sicre和J gou,2016;Cao,Araujo和Sim,2020;Ng,Balntas等,2020;Tolias,Jenicek
和Chum,2020)等整体图像描述符,结合度量学习(Bell和Bala,2015;Song,Xiang等,2016;Gordo,Al- maz n等,2017;Wu,Manmatha等,2017;Berman,J gou等,2019)
,以紧凑的描述符表示每张图像,可用于在大型数据库
中测量相似性(Johnson,Douze和J gou,2021)。还可以将多种技术结合起来,例如深度网络与VLAD的结合(Arandjelovic,Gronat
等,2016),广义均值(GeM)
Radenovi、Tolias和Chum2019
)。
图6.12 GrokNet训练架构使用了7个数据集、一个通用DNN主干、两个分支和83个损失函数(80个分类损失+3个嵌入损失)©Bell,Liu et al.(2020)。
池化(Radenovi、Tolias和Chum2019),
或动态均值池化(DAME)池化(Yang、Kien Nguyen等人2019)被整合到端到端可调的完整系统中。Gordo、Al- maz n等人(2017)对这些技术进行
了全面的综述和实验比较,我们也在第7.1.4节的大规模匹配和检索部分进行了讨论。一些最新的图像检索技术使用局部和全局描述符的组合,在地标识别任务中取得了最先进的性能(Cao、Araujo和Sim2020;Ng、Balntas等人2020;Tolias、Jenicek和Chum2020)。ECCV 2020实例级识别研讨会7提供了该领域的一些最新工作的参考,而即将举行的NeurIPS‘21图像相似性挑战赛8则提供了检测内容篡改的新数据集。
最近的一个商业系统例子是贝尔、刘等人(2020)描述的GrokNet产品识别服务,该系统除了类别识别外还使用了视觉相似性搜索。GrokNet接收用户图像和购物查询作为输入,并返回与查询图像中相似的索引项目(图6.11a)。需要相似性搜索组件的原因在于,世界上的“长尾”商品种类繁多,如“毛绒水槽、电动狗刷或汽油驱动高领毛衣”,使得全面分类变得不切实际。
在训练时,GrokNet同时使用带有类别和/或属性标签的弱标记图像和未标记图像,在这些图像中检测物体中的特征,然后用于度量学习,使用ArcFace损失(Deng,Guo等人,2019)的修改版本和一种新方法。

成对边缘损失(图6.11b)。整个系统接收大量未标记和弱标记的图像,并使用类别和属性软最大值损失以及三种不同的嵌入度量损失训练ResNeXt101主干网络(图6.12)。GrokNet只是最近开发的众多商业视觉产品搜索系统中的一个例子。其他系统包括亚马逊(Wu,Manmatha等,2017年)、Pinterest (Zhai,Wu等,2019年)和Facebook (Tang,Borisyuk等,2019年)的系统。除了帮助人们找到他们可能想要购买的商品外,大规模相似性搜索还可以加快网络上有害内容的搜索速度,例如Facebook的SimSearchNet。10
在计算机被要求执行的各种识别任务中,人脸识别可以说是它们最成功的一项。尽管人们甚至无法轻易区分不熟悉的人(O‘Toole,Jiang等,2006;O’Toole,Phillips等,2009),但计算机在区分少数家庭成员和朋友方面的能力已经进入了消费级照片应用。人脸识别还可以用于多种其他应用,包括人机交互(HCI)、身份验证(Kirovski,Jojic,Jancke等,2004)、桌面登录、家长控制和患者监测(Zhao,Chellappa等,2003),但也存在滥用的可能(Chokshi,2019;Ovide,2020)。
| 名称/网址 | 内容/参考 |
| CMU多PIE数据库 http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie 野外的面孔 http://vis-www.cs.umass.edu/lfw YouTube脸部(YTF) https://www.cs.tau.ac.il/~ wolf/ytfaces 超级脸 https://megaface.cs.washington.edu IARPA Janus基准(IJB) https://www.nist.gov/programs-projects/face-challenges 宽脸型 http://shuoyang1213.me/WIDERFACE | 337张不同姿势的面部照片 Gross、Matthews等人(2010)5,749名网络名人 Huang,Ramesh等人(2007) 3,425个YouTube视频中的1,595人 Wolf、Hassner和Maoz(2011)1M互联网面临的问题 Nech和Kemelmacher-Shlizerman(2017)31,334张3,531人的视频面孔 Maze、Adams等人(2018) 用于人脸检测的32,203张图像,Yang,Luo等人(2016) |
表6.1人脸识别和检测数据集,改编自Maze、Adams等人。
(2018).
姿势、光照和表情(PIE)条件(Phillips,Moon等,2000;Sim,Baker和Bsat,2003;Gross,Shi和Cohn,2005;Huang,Ramesh等,2007;Phillips,Scruggs等,2010)。近年来广泛使用的数据集包括野外标注人脸(LFW)(Huang,Ramesh等,2007;Learned-Miller,Huang等,2016),YouTube面部(YTF)(Wolf,Hassner,和Maoz,2011),MegaFace (Kemelmacher-Shlizerman,Seitz等,2016;Nech和Kemelmacher-Shlizerman,2017),以及IARPA Janus基准(IJB)(Klare,Klein等,2015;Maze,Adams等,2018),详见表6.1。(有关用于训练的其他数据集,请参见Masi,Wu等(2018)。)
一些最早的人脸识别方法涉及找到图像中独特特征的位置,如眼睛、鼻子和嘴巴,并测量这些特征位置之间的距离(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991)。其他方法则依赖于将灰度图像投影到称为特征脸(Section5.2.3)的低维子空间上,并使用主动外观模型联合建模形状和外观变化(同时忽略姿态变化)(第6.2.4节)。关于“经典”(DNN之前)人脸识别系统的描述可以在许多调查报告和书籍中找到(Chellappa、Wilson和Sirohey 1995;Zhao、Chellappa等2003;Li和Jain 2005),以及人脸识别网站。Sinha、Balas等人(2006)关于人类人脸识别的综述也非常值得一读;它包括许多
令人惊讶的结果,比如人类识别熟悉事物的低分辨率图像的能力

图6.14通过形状和颜色操纵面部外观(Rowland和Per- rett1995)©1995 IEEE。通过向输入图像(b)添加或减去性别特异性形状和颜色特征,可以诱导出不同量的性别变化。
添加的数值(从平均值)为:(a)+50%(性别增强)、(b)0%(原始图像)、(c)-50%(接近“两性同体”)、(d)-100%(性别转换),以及(e)-150%(增强相反性别特征)。
(图6.13)以及眉毛在识别中的重要性。研究人员还研究了面部表情的自动识别。参见Chang、Hu等人(2006)、Shan、Gong和McOwan(2009)以及Li和Deng(2020)的一些代表性论文。
活动外观和三维形状模型
使用模块化或基于视图的特征空间进行人脸识别的需求,我们在第5.2.3节中讨论过,这反映了更普遍的一个观察,即面部外观和可识别性不仅依赖于颜色或纹理(这些正是特征脸所捕捉的内容),还同样依赖于形状。此外,在处理三维头部旋转时,进行识别时应忽略人的头部姿态。
事实上,最早的面部识别系统,如菲舍勒和埃尔施拉格(1973)、卡纳德(1977)以及尤尔(1991)所开发的系统,都在面部图像上找到了独特的特征点,并基于这些特征点的相对位置或距离进行识别。后来的技术,如局部特征分析(佩内夫和阿蒂克1996)和弹性聚类图匹配(威斯科特、费洛斯等人1997),将局部滤波器响应(喷流)与形状模型结合,在独特特征位置处进行识别。
一个视觉上引人注目的例子说明了形状和纹理为什么都很重要
罗兰和佩雷特(1995)手动勾勒面部特征的轮廓,然后利用这些轮廓将每张图像标准化(扭曲)为标准形状。通过分析形状和颜色图像与平均值的偏差,他们能够将某些形状和颜色的变形与个人特征如年龄和性别联系起来(图6.14)。他们的研究证明,形状和颜色对这些特征的感知具有重要影响。
大约在同一时期,计算机视觉领域的研究人员开始使用同时的形状变形和纹理插值来建模由身份或表情引起的面部外观变化(Beymer1996;Vetter和Poggio1997),开发了诸如主动形状模型(Lanitis、Taylor和Cootes1997)、3D可变形模型(Blanz和Vetter1999;Egger、Smith等人2020)以及弹性束图匹配(Wiskott、Fellous等人1997)等技术。
库特斯、爱德华兹和泰勒(2001)提出的活动外观模型(AAMs)不仅模拟了图像形状的变化,这种变化通常由图像上关键特征点的位置编码,还模拟了纹理的变化,这些变化在分析前被归一化到一个标准形状。形状和纹理都表示为相对于平均形状和纹理的偏差,
(6.2)
t = + Uta; (6.3)
在Us和Ut中,特征向量已经预先缩放(白化),使得a中的单位向量代表训练数据中观察到的一个标准差的变化。除了这些主要变形外,形状参数还通过全局相似性变换来匹配给定人脸的位置、大小和方向。同样,纹理图像包含尺度和偏移,以最好地适应新的光照条件。
正如你所见,相同的外观参数a(6.2-6.3)同时控制着从平均值出发的形状和纹理变形,这在我们认为它们之间存在关联时是合理的。图6.15展示了沿前四个主方向移动三个标准差如何最终改变一个人外貌中的多个相关因素,包括表情、性别、年龄和身份。
虽然活动外观模型主要是为了准确捕捉面部特征的外观和变形的变化,但它们可以通过计算一个身份子空间来适应面部识别,该子空间将身份变化与其他变化来源如光照、姿势和表情区分开来(Costen,Cootes等。

图6.15主要变化模式在活动外观模型中的表现(Cootes、Edwards和Taylor 2001)©2001 IEEE。四张图片展示了同时改变形状和纹理前四个变化模式的±σ与平均值的影响。你可以清楚地看到面部形状和阴影是如何同时受到影响的。
1999年)。这一基本思想借鉴了特征脸(Belhumeur、Hes- panha和Kriegman 1997;Moghaddam、Jebara和Pentland 2000)等类似研究,旨在计算个体内部和外部变异的独立统计量,然后在这些子空间中找到区分方向。尽管AAMs有时被直接用于识别(Blanz和Vetter 2003),但在识别领域的主要用途是将人脸对齐到标准姿态(Liang、Xiao等2008;Ren、Cao等2014),以便可以使用更传统的人脸识别方法(Penev和Atick 1996;Wiskott、Fellous等1997;Ahonen、Hadid和Pietikinen 2006;Zhao和Pietikinen 2007;Cao、Yin等2010)。
主动外观模型已扩展以处理光照和视角变化(Gross,Baker等,2005)以及遮挡问题(Gross,Matthews和Baker,2006)。其中一个最重要的扩展是构建形状的三维模型(Matthews,Xiao和Baker,2007),这些模型在捕捉和解释面部外观在大幅度姿态变化中的全部变异性方面表现得更好。这样的模型既可以从单目视频序列中构建(Matthews,Xiao和Baker,2007),如图6.16a所示,也可以从多视图视频序列中构建(Ramnath,Koterba等,2008),后者在重建和跟踪中提供了更高的可靠性和准确性(Murphy-Chutorian和Trivedi,2009)。
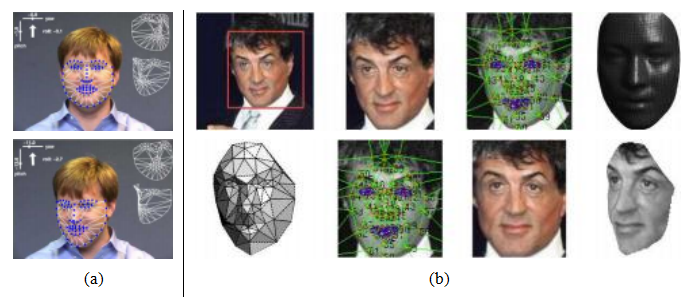
图6.16头部追踪与正面化:(a)使用3D主动外观模型(AAMs)(Matthews,Xiao和Baker 2007)©2007斯普林格出版社,显示视频帧以及估计的偏航、俯仰和滚动参数及拟合的3D可变形网格;(b)使用DeepFace系统中的六个点,随后是67个点(Taigman,Yang等2014)©2014 IEEE,用于正面化面部图像(底部行)。

图6.17 DeepFace架构(Taigman,Yang等人,2014)©2014 IEEE,从正面化阶段开始,随后是几个局部连接(非卷积)层,然后是两个具有K类软性函数的全连接层。
使用深度学习的面部识别
受到深度网络在全图像分类中取得巨大成功的启发,人脸识别研究人员开始在其系统中使用深度神经网络骨干。图6.16b–6.17展示了Taigman、Yang等人(2014)提出的DeepFace系统的两个阶段,这是最早利用深度网络实现显著提升的系统之一。在他们的系统中,采用基于特征点的预处理正面化步骤,将原始彩色图像转换为裁剪良好的正面人脸。然后,深度局部连接网络(其中卷积核可以随空间变化)被输入到两个最终的全连接层,再进行分类。
一些较新的深度人脸识别方法省略了正面化阶段,转而使用数据增强(第5.3.3节)来生成具有更多姿态变化的合成输入(Schroff,Kalenichenko和Philbin 2015;Parkhi,Vedaldi和Zisserman 2015)。Masi、Wu等人(2018)提供了一篇关于深度人脸识别的优秀教程和综述,包括广泛使用的训练和测试数据集列表、正面化和数据增强的讨论,以及一个关于训练损失(Figure6.18)的部分。最后一个主题对于扩展到越来越多的人数至关重要。Schroff、Kalenichenko和Philbin(2015)以及Parkhi、Vedaldi和Zisserman(2015)使用三元组损失构建了一个与受试者数量无关的低维嵌入空间。更近期的系统则采用了受softmax函数启发的对比损失,我们在第5.3.4节中讨论过这一点。例如,Deng、Guo等人(2019)的ArcFace论文在嵌入空间的单位超球上测量角度距离,并增加额外的边缘以使身份聚在一起。这一想法进一步扩展用于视觉相似性搜索(Bell、Liu等人2020)和人脸识别(Huang、Shen等人2020;Deng、Guo等人2020a)。
个人照片集
除了数码相机自动寻找人脸以辅助自动对焦,以及视频会议中摄像机寻找人脸以聚焦演讲者(无论是机械方式还是数字方式),人脸识别技术已经渗透到大多数消费级照片整理软件和照片分享网站中。找到人脸并允许用户标记它们,使得日后更容易找到选定人物的照片,或者自动与朋友分享。事实上,在照片中标记朋友是脸书上最受欢迎的功能之一。
然而,有时人脸很难找到和识别,特别是当他们身材矮小、背对着摄像头或被遮挡时。在这种情况下,将人脸识别与人物检测和衣物识别结合使用可以非常有效,如图6.19所示(Sivic,Zitnick,和Szeliski 2006)。将人物识别与其他技术结合使用可以进一步提高效果。
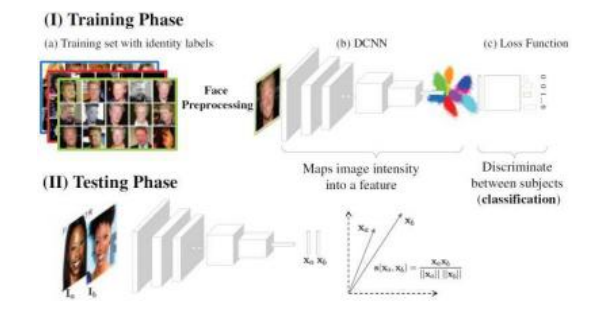
图6.18一个典型的现代深度人脸识别架构,出自Masi、Wu等人(2018)的调查©2018 IEEE。在训练时,使用大量标注的人脸数据集(a)来约束深度卷积神经网络(b)的权重,优化分类任务的损失函数(c)。测试时,通常丢弃分类层,使用DCNN作为特征提取器来比较人脸描述符。
各种上下文,如位置识别(第11.2.3节)或活动或事件识别,也能帮助提高性能(Lin,Kapoor等人,2010)。
如果我们被给予一张图像进行分析,比如图6.20中的集体肖像,我们可以尝试将识别算法应用于该图像中的每一个可能的子窗口。这样的算法可能会既慢又容易出错。相反,构建专门的
目标探测器,它的工作是快速找到特定物体可能出现的可能区域。
我们首先介绍面部检测器,这是最早成功的识别示例之一。这类算法被集成到当今大多数数码相机中,以增强自动对焦功能,并被应用于视频会议系统中,用于控制平移和缩放。接着,我们探讨行人检测器,作为更广泛对象检测方法的一个例子。最后,我们将讨论多类对象检测问题,这一问题如今已通过以下方式解决:

图6.19使用组合面部、头发和躯干模型进行人物检测和识别(Sivic,Zitnick和Szeliski2006)©2006 Springer。(a)仅使用面部检测,有多个头部被遗漏。(b)组合面部和服装模型成功重新找到了所有人。
6.3.1人脸检测
在将人脸识别应用于普通图像之前,必须首先找到任何人脸的位置和大小(图6.1c和6.20)。原则上,我们可以在每个像素和尺度上应用人脸识别算法(Moghaddam和Pentland 1997),但这种过程在实际中会过于缓慢。
在过去四十年中,开发了多种快速人脸检测算法。杨、克里格曼和阿胡贾(2002)以及赵、切拉帕等人(2003)对此领域早期工作的综述进行了全面介绍。根据他们的分类法,人脸检测技术可以分为基于特征、基于模板或基于外观的类型。基于特征的技术试图找到眼睛、鼻子和嘴巴等显著图像特征的位置,然后验证这些特征是否处于合理的几何排列。这些技术包括一些早期的人脸识别方法(菲舍勒和埃尔施拉格1973;卡纳德1977;尤尔1991),以及后来基于模块化特征空间的方法(莫加达姆和彭特兰1997)、局部滤波器喷射(梁、伯尔和

图6.20 Rowley、Baluja和Kanade(1998)产生的面部检测结果©1998 IEEE。您能在57个真阳性结果中找到一个假阳性结果(非人脸的框)吗?
Perona1995;Penev和Atick1996;Wiskott,Fellous等人1997),支持向量机(Heisele,Ho等人2003;Heisele,Serre和Poggio2007)以及提升法(Schneiderman和Kanade2004)。
基于模板的方法,如主动外观模型(AAM)(第6.2.4节),可以处理广泛的姿势和表情变化。通常,它们需要在真实人脸附近进行良好的初始化,因此不适合用作快速人脸检测器。
基于外观的方法会扫描图像中小而重叠的矩形区域,寻找可能的人脸候选对象,然后使用一系列更昂贵但选择性更强的检测算法进行细化(Sung和Poggio 1998;Rowley、Baluja和Kanade 1998;Romdhani、Torr等2001;Fleuret和Geman 2001;Viola和Jones 2004)。为了处理尺度变化,通常将图像转换为次八度金字塔,并在每一层进行单独扫描。大多数基于外观的方法都严重依赖于使用标记的人脸和非人脸区域集来训练分类器。
宋和波吉奥(1998)以及罗利、巴卢贾和卡纳德(1998)提出了两种最早的基于外观的人脸检测器,并引入了许多后来被广泛采用的创新方法。首先,这两个系统收集了一组标记的人脸图像(图6.20),以及一组来自已知不含人脸的图像的图像,例如航拍图像或植被。收集到的人脸图像通过人工镜像、旋转、缩放和轻微平移来增强,以减少这些效果对面部检测器的影响。
接下来的几段将对一些早期出现的基于外观的系统进行快速回顾
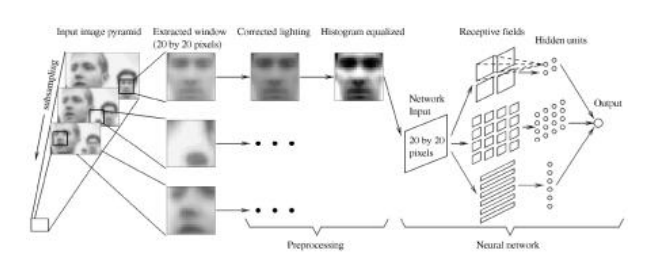
图6.21面部检测神经网络(Rowley、Baluja和Kanade1998)©1998 IEEE。从金字塔的不同层次中提取重叠的补丁,然后进行预处理。然后使用三层神经网络来检测可能的脸部位置。
基于机器算法的面部检测器。这些系统为计算机视觉中机器学习的逐渐采用和进化提供了一个有趣的视角。更详细的描述可以在原始论文以及本书的第一版(Szeliski2010)中找到。
聚类与主成分分析。一旦人脸和非人脸模式经过预处理,Sung和Poggio(1998)使用k-means将每个数据集聚类为六个独立的簇,然后对生成的12个簇分别拟合主成分分析子空间。在检测时,首先使用Moghaddam和Pentland(1997)开发的DIFS和DFFS指标生成24个马氏距离测量值(每个簇两个)。这24个测量值被输入到多层感知器(MLP),即全连接神经网络。
神经网络。Rowley、Baluja和Kanade(1998)没有先对数据进行聚类并计算到聚类中心的马氏距离,而是直接将神经网络(MLP)应用于20×20像素的灰度强度块,使用不同大小的手工设计“感受野”来捕捉大尺度和小尺度结构(图6.21)。由此产生的神经网络直接输出每个重叠块中心出现人脸的可能性,形成一个多分辨率金字塔。由于多个重叠块(在空间和分辨率上)可能在人脸附近触发,因此使用了一个额外的合并网络来合并重叠检测结果。作者还尝试训练多个网络并合并它们的输出。图6.20显示了他们面部检测器的一个样本结果。
支持向量机。与使用神经网络分类图像块不同,Osuna、Freund和Girosi(1997)采用支持向量机(SVM),我们在第5.1.4节中讨论过,来对与Sung和Poggio(1998)相同的预处理图像块进行分类。SVM在特征空间中寻找不同类别(在这种情况下是人脸和非人脸图像块)之间的最大间隔分离平面。当线性分类边界不足时,可以使用核函数将特征空间提升到更高维度的特征(5.29)。SVM已被其他研究人员用于人脸检测和人脸识别(Heisele、Ho等2003;Heisele、Serre和Poggio 2007),以及一般对象识别(Lampert 2008)。
提升。在2000年代开发的所有面部检测器中,由维奥拉和琼斯(2004)引入的可能是最著名的。他们的技术首次将提升的概念引入计算机视觉领域,这一概念涉及训练一系列越来越具区分性的简单分类器,然后融合它们的输出(Bishop 2006,第14.3节;Hastie、Tibshirani和Friedman 2009,第10章;Murphy 2012,第16.4节;Glassner 2018,第14.7节)。
更详细地说,提升涉及构建一个分类器h(x),作为简单弱学习者的总和,
=签名αj hj
(6.4)
其中每个弱学习器hj (x)都是输入的一个极其简单的函数,因此在分类性能中(单独地)预期不会产生太多贡献。
在大多数提升变体中,弱学习器是阈值函数,
这些也被称作决策桩(基本上是决策树最简单的版本)。在大多数情况下,传统上(也是更简单的方法)将aj和bj设为±1,即aj = -sj,bj = +sj,这样只需要选择特征fj、阈值θj以及阈值的极性sj∈±1。14

图6.22基于提升法的人脸检测器中使用的简单特征(Viola和Jones 2004)©2004斯普林格:(a)由2-4个不同矩形组成的矩形特征差异(白色矩形内的像素从灰色矩形中减去);(b)AdaBoost选择的第一和第二特征。第一个特征测量眼睛与脸颊之间的强度差异,第二个特征测量眼睛与鼻梁之间的强度差异。
比单个像素更精细,一旦预计算了累加面积表,它们的计算速度极快,如第3.2.3节(3.31–3.32)所述。实际上,在O(N)预计算阶段的成本下(其中N是图像中的像素数量),后续矩形差值可以通过4r次加法或减法来计算,其中r∈{2;3;4}是特征中矩形的数量。
提升成功的关键在于逐步选择弱学习器的方法以及每个阶段后重新加权训练样本。AdaBoost(自适应提升)算法(Bishop2006;Hastie,Tibshirani和Friedman2009;Murphy2012)通过根据每个阶段是否正确分类来重新加权每个样本,并使用阶段平均分类错误来确定最终的弱分类器权重αj。
为了进一步提高检测器的速度,可以创建一个分类器级联,其中每个分类器使用少量测试(例如,二项式AdaBoost分类器)来拒绝大部分非人脸,同时尝试通过所有潜在的人脸候选(Fleuret和Geman2001;Viola和Jones2004;Brubaker、Wu等人2008)。
深度网络。自20世纪初面部检测研究的初期爆发以来,面部检测算法一直在不断进化和改进(Zafeiriou,Zhang,和Zhang 2015)。研究人员提出了使用特征级联(Li和Zhang 2013)、可变形部件模型(Mathias,Benenson等2014)、聚合通道特征(Yang,Yan等2014)以及神经网络(Li,Lin等2015;Yang,Luo等2015)。更广泛的face基准-

图6.23使用定向梯度直方图检测行人(Dalal和Triggs
2005)©2005 IEEE: (a)训练样本上的平均梯度图像;(b)每个“像素”显示以该像素为中心的块中的最大正SVM权重;(c)同样,负SVM权重也是如此;(d)测试图像;(e)计算出的R-HOG(矩形梯度直方图)描述符;(f)由正SVM权重加权的R-HOG描述符;(g)由负SVM权重加权的R-HOG描述符。
mark15,16(杨、罗等人,2016)包含了来自更近期论文的结果和指向,包括RetinaFace(邓、郭等人,2020b),该方法结合了其他最近的神经网络和目标检测器的思想,如特征金字塔网络(林、多尔等人,2017)和RetinaNet(林、戈亚尔等人,2017),还有一篇关于
其他近期人脸检测器的精彩综述。
虽然早期关于物体检测的研究主要集中在人脸检测上,但行人和汽车等其他物体的检测也受到了广泛关注(Gavrila和Philomin 1999;Gavrila 1999;Papageorgiou和Poggio 2000;Mohan、Papageorgiou和Poggio 2001;Schneiderman和Kanade 2004)。其中一些技术在速度和效率方面保持了与人脸检测相同的关注点。然而,另一些则专注于准确性,将检测视为更具有挑战性的通用类别识别变体(第6.3.3节),旨在尽可能准确地确定物体的位置和范围(Everingham、Van Gool等2010;Everingham、Eslami等2015;Lin、Maire等2014)。一个著名的行人检测器的例子是达拉尔开发的算法。
以及Triggs(2005),他们使用了一组重叠的方向梯度直方图(HOG)
输入支持向量机的描述符(图6.23)。每个HOG都有单元格来累积特定方向梯度的幅度加权投票,就像Lowe(2004)开发的尺度不变特征变换(SIFT)一样,我们将在第7.1.2节和图7.16中描述。然而,与仅在兴趣点位置评估的SIFT不同,HOG是在一个规则重叠网格上评估的,其描述符幅度使用更粗糙的网格进行归一化;它们仅在一个尺度和固定方向上计算。为了捕捉人物轮廓周围细微的方向变化,使用了大量的方向区间,并且在中心差异梯度计算中不进行平滑处理——更多实现细节参见Dalal和Triggs(2005)。图6.23d显示了一个样本输入图像,而图6.23e则显示了相关的HOG描述符。
一旦计算出描述符,支持向量机(SVM)就会在生成的高维连续描述符向量上进行训练。图6.23b-c展示了每个块中(最)正和负的SVM权重图,而图6.23f-g则显示了中心输入图像对应的加权HOG响应。可以看出,在人的头部、躯干和脚周围有相当数量的正响应,而在毛衣的中部和颈部则相对较少的负响应。
与人脸检测类似,行人和一般物体检测领域在2000年代继续迅速发展(Belongie,Malik和Puzicha2002;Mikolajczyk,Schmid和Zisserman2004;Dalal和Triggs2005;Leibe,Seemann和Schiele2005;Opelt,Pinz和Zisserman2006;Torralba2007;Andriluka,Roth和Schiele2009;Maji和Berg2009;Andriluka,Roth和Schiele2010;Doll r,Belongie和Perona2010)。
在人物检测领域的一项重要进展是费尔岑斯瓦尔布、麦克阿莱斯特和拉马南(2008)的工作,他们扩展了方向梯度直方图人物检测器,以纳入灵活的部件模型(第6.2.1节)。每个部件都在整体对象模型下方两个金字塔层级的HOG上进行训练和检测,同时学习并使用部件相对于父节点(即整体边界框)的位置(图6.24b)。为了补偿训练示例边界框中的不准确或不一致(图6.24c中的虚线),“真实”位置的父(蓝色)边界框被视为一个潜在(隐藏)变量,并在训练和识别过程中推断。由于部件的位置也是潜在的,系统可以采用半监督方式训练,无需在训练数据中包含部件标签。该系统的扩展版本(费尔岑斯瓦尔布、吉什克等人,2010年)包括了一个简单的上下文模型改进,在2008年视觉对象类别检测挑战赛中,该系统是表现最好的两个对象检测系统之一(埃弗林厄姆、范古尔等人,2010年)。
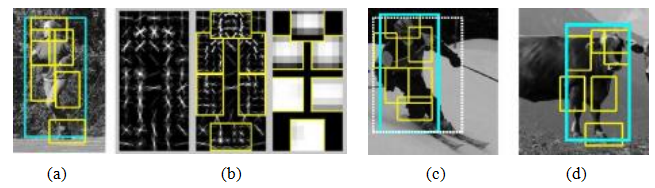
图6.24部件对象检测(Felzenszwalb,McAllester和Ramanan 2008)©2008 IEEE:(a)输入照片及其关联的人物(蓝色)和部件(黄色)检测结果。(b)检测模型由粗略模板、多个高分辨率部件模板以及每个部件位置的空间模型定义。(c)正确检测到一名滑雪者,而(d)错误地检测到一头牛(被标记为人物)。

图6.25使用随机森林进行姿态检测(Rogez,Rihan等人,2008)©2008 IEEE。估计的姿态(运动学模型的状态)绘制在每个输入帧上。
基于部件的人体检测和姿态估计的改进包括Andriluka、Roth和Schiele(2009)以及Kumar、Zisserman和Torr(2009)的工作。
罗热兹、里汉等人(2008)提出了一个更精确的人体姿态和位置估计方法,他们使用基于HOG构建的随机森林计算了人在行走周期中的相位以及各个关节的位置(图6.25)。由于他们的系统能够生成完整的三维姿态信息,因此其应用领域更接近于三维人体跟踪器(西登布拉德、布莱克和弗利特2000;安德里卢卡、罗斯和席勒2010),我们将在第13.6.4节中讨论。当有视频序列可用时,光流和运动不连续性中的额外信息可以大大帮助检测任务,这一点由埃夫罗斯、伯格等人(2003)、维奥拉、琼斯和斯诺(2003)以及达拉尔、特里格斯和施密德(2006)讨论过。
自2000年代以来,行人和一般人物检测一直在积极开发中,通常是在更广泛的多类物体检测的背景下进行(Everingham,Van Gool等人,2010;Everingham,Eslami等人,2015;Lin,Maire等人,2014)。Cal-
技术行人检测基准17和多尔、贝尔戈和佩罗纳(2010)的调查介绍了一个新的数据集
,并提供了截至2012年的算法综述,包括积分通道特征(多尔、图等人2009)、西方最快的行人检测器(多尔、贝尔戈和佩罗纳2010
),以及3D姿态估计算法如姿态小部件(布尔德夫和马利克2009)。自其最初
构建以来,该基准继续发布并评估更近期的检测器,包括多尔、阿佩尔和基恩兹勒(2012)、多尔、阿佩尔等人(2014)以及基于深度神经网络的更近期算法(塞曼内特、卡武库奥卢等人2013;欧阳和王2013;田、
罗等人2015;张
、林等人2016)。城市行人数据集(张、本森和席勒2017)和更广泛的面部与人物挑战18也报告了最近算法的结果。
虽然人脸和行人检测算法是最早被广泛研究的,但计算机视觉一直致力于解决一般的物体检测和标注问题,而不仅仅是全图像分类。帕斯卡视觉对象类别(VOC)挑战赛(Everingham,Van Gool等人2010)包含20个类别,既包括分类也包括检测挑战。早期在检测挑战中表现良好的参赛作品包括Chum和Zisserman(2007)基于特征的检测器和空间金字塔匹配SVM分类器、Felzenszwalb、McAllester和Ramanan(2008)的星型拓扑可变形部件模型以及Lampert、Blaschko和Hofmann(2008)的滑动窗口SVM分类器。该竞赛每年重新举行,2012年检测挑战赛的前两名参赛者(Everingham,Eslami等人2015)使用了滑动窗口空间金字塔匹配(SPM)SVM (de Sande,Uijlings等人2011)和牛津大学重新实现的可变形部件模型(Felzenszwalb,Girshick等人2010)。
图像净大规模视觉识别挑战赛(ILSVRC)于2010年发布,将数据集从帕斯卡VOC 2010的大约2万张图像扩展到ILSVRC 2010的超过140万张图像,并从20个物体类别增加到1000个物体类别(Russakovsky等人,2015)。与帕斯卡类似,它也有一个物体检测任务,但包含更广泛的具有挑战性的图像(图6.4)。微软COCO(上下文中的常见对象)数据集(Lin等人,2014)每张图像中包含更多的物体,以及多个物体的像素级分割,这使得不仅能够研究语义分割(第6.4节),还能研究单个物体实例分割(第6.4.2节)。表6.2列出了用于训练和测试通用物体检测算法的一些数据集。
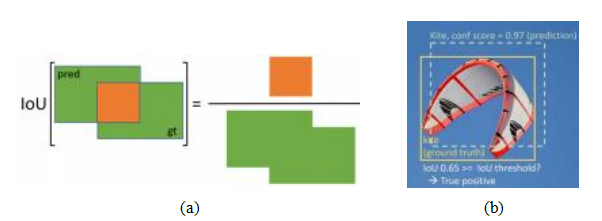
图6.26交并比(IoU):(a)示意图,(b)实际例子©2020 Ross Girshick。
COCO的发布恰逢图像分类、目标检测和分割领域向深度网络的全面转型(Jiao,Zhang et al.2019;Zhao,Zheng et al. 2019)。图6.29显示了COCO目标检测任务中平均精度(AP)的快速提升,这与深度神经网络架构的进步密切相关(图5.40)。
精确度与召回率
在描述现代物体检测器的要素之前,我们首先需要讨论它们试图优化的指标。如图6.5a和6.26b所示,物体检测的主要任务是为所有感兴趣的物体放置精确的边界框,并正确地标记这些物体。为了衡量每个边界框的准确性(既不太小也不太大),常用的指标是交并比(IoU),也称为杰卡德指数或杰卡德相似系数(Rezatofighi,Tsoi等,2019)。IoU通过计算预测边界框Bpr和真实边界框Bgt的交面积与并面积之比来得出,
IoU =
(6.6)
如图6.26a所示。
正如我们即将看到的,目标检测器首先提出多个合理的矩形区域(检测结果),然后对每个检测进行分类,并生成置信度评分(图6.26b)。这些区域随后会经过某种非极大值抑制(NMS)阶段,该阶段使用贪婪的最自信优先算法移除与较强检测重叠过多的较弱检测。
为了评估一个对象检测器的性能,我们遍历所有的检测结果,
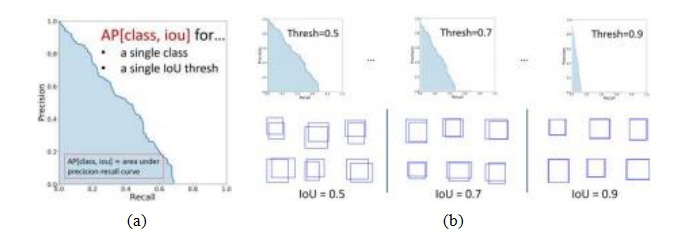
图6.27目标检测器平均精度©2020 Ross Girshick:单个类别和IoU阈值下的(a) a精度-召回率曲线,其中AP是P-R曲线下面积;(b)平均精度是在多个IoU阈值(从宽松到严格)上取平均值。
从最自信到最不自信,将它们分类为真阳性TP(正确标签且IoU足够高)或假阳性FP(错误标签或真实对象已匹配)。对于每个新的递减置信度阈值,我们可以计算精确率和召回率
精确度=
(6.7)
记住=
(6.8)
其中P是正例的数量,即测试图像中标注的真值检测的数量。19(关于特征匹配的其他术语,可参见第7.1.3节,这些术语常用于测量和描述错误率。)
计算每个置信阈值下的精确率和召回率,可以生成一个精确率-召回率曲线,如图6.27a所示。该曲线下面积称为平均精确率(AP)。对于检测到的每个类别,可以分别计算AP分数,并取这些分数的平均值以得到平均精确率(mAP)。另一种广泛使用的度量是平均精确率。早期的基准测试,如PASCAL VOC使用单一IoU阈值0.5来确定mAP(Everingham,Eslami等,2015),而COCO基准测试(Lin,Maire等,2014)则在一系列IoU阈值下平均mAP,即IoU∈{0.50;0.55;...;0.95},如图6.27a所示。尽管这一AP分数仍被广泛使用,但最近提出了一种基于概率的检测质量(PDQ)分数(Hall,Dayoub等,2020)。还提出了一种更平滑的平均精确率版本,称为Smooth-AP,并证明其在大规模图像检索任务中具有优势(Brown,Xie等,2020)。
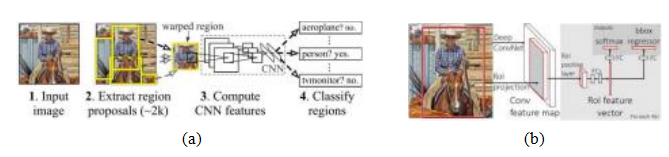
图6.28 R-CNN和Fast R-CNN目标检测器。(a) R-CNN重新缩放每个提议区域内的像素,并执行CNN + SVM分类(Girshick,Donahue等,2015)©2015 IEEE。(b) Fast R-CNN重采样卷积特征,并使用全连接层进行分类和边界框回归(Girshick2015)©2015 IEEE。
现代物体探测器
检测图像中物体的第一阶段是提出一组合理的矩形区域,以便运行分类器。这类区域提议算法的发展在20世纪初是一个活跃的研究领域(Alexe,Deselaers和Ferrari 2012;Uijlings,Van De Sande等2013;Cheng,Zhang等2014;Zitnick和Doll 2014)。
基于神经网络的最早物体检测器之一是R-CNN,即由Girshick、Donahue等人(2014)开发的区域卷积网络。如图6.28a所示,该检测器首先使用Uijlings、Van De Sande等人(2013)的选择性搜索算法提取大约2,000个区域提议。每个提议的区域随后被重新缩放(扭曲)到一个224平方的图像,并通过AlexNet或VGG神经网络,最终由支持向量机(SVM)分类器进行分类。
吉什克(2015)的后续论文《快速R-CNN》中,交换了卷积神经网络和区域提取阶段,并用一些全连接(FC)层替换了SVM,这些层同时计算对象类别和边界框精炼(图6.28b)。这重新利用了CNN的计算,使得训练和测试时间大大加快,与之前的网络相比,精度显著提高(图6.29)。从图6.28b可以看出,快速R-CNN是一个具有共享主干和两个独立头部的深度网络示例,因此也有两种不同的损失函数,尽管这些术语直到何、吉奥查里等人(2017)的《掩码R-CNN》论文中才被引入。
几个月后,Ren、He等人(2015)引入了更快的R-CNN系统,用卷积区域提议网络(RPN)替换了相对较慢的选择性搜索阶段,从而实现了更快的推理速度。计算出卷积特征后,RPN在每个粗略位置建议多个潜在的锚框,这些锚框在形状和大小上各不相同。
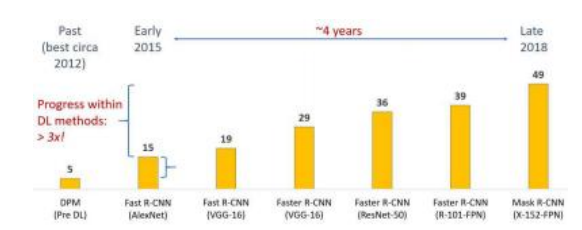
图6.29按年份划分的COCO目标检测任务的最佳平均精度(AP)结果(Lin,Maire等人,2014)©2020 Ross Girshick。
以适应不同的潜在对象。然后,通过Fast R-CNN头部的实例对每个提案进行分类和细化,并使用非最大抑制对最终检测结果进行排序和合并。
R-CNN、Fast R-CNN和Faster R-CNN都在单一分辨率的卷积特征图(Figure6.30b)上操作。为了获得更好的尺度不变性,最好是在一系列分辨率上操作,例如,在每个图像金字塔层级计算特征图,如图6.30a所示,但这计算成本高昂。我们也可以从卷积网络内部的不同层级开始(图6.30c),但这些层级具有不同程度的语义抽象,即较高/较低的层级更倾向于抽象结构。最佳解决方案是构建特征金字塔网络(FPN),如图6.30d所示,通过自上而下的连接赋予高分辨率(低)金字塔层级以在更高层级推断出的语义(Lin,Doll r等2017)。这种额外信息显著提升了目标检测器(及其他下游任务)的性能,并使其行为对物体大小的敏感度大大降低。
DETR (Carion,Massa等,2020)采用了一种更简单的架构,消除了非极大值抑制和锚点生成的使用。他们的模型由一个ResNet主干网络组成,该主干网络连接到一个变压器编码器-解码器。大致来说,它生成N个边界框预测,其中一些可能包括“无对象类别”。真实边界框也用“无对象类别”边界框填充,以获得总共N个边界框。在训练过程中,二分匹配用于建立每个预测边界框与真实边界框之间的一对一映射,所选映射导致
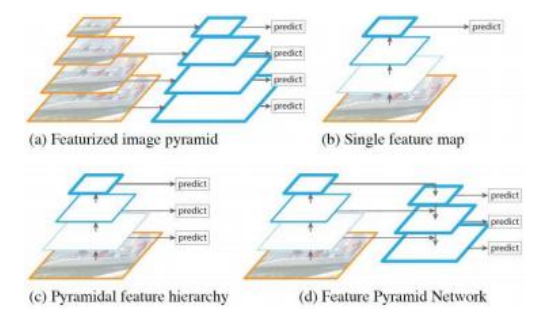
2017 IEEE:(a)在图像金字塔的每个层次提取的深度特征;(b)单个低分辨率特征图;(c)深度特征金字塔,其中较高层次具有更高的抽象性;(d)特征金字塔网络,具有自上而下的上下文信息。
以最低的成本进行训练。整体的训练损失是匹配的边界框之间的损失之和。他们发现他们的方法在COCO上的性能与最先进的目标检测方法具有竞争力。
单级网络
在我们迄今为止研究的架构中,区域提议算法或网络会选择要考虑的检测位置和形状,然后使用第二个网络对每个区域内的像素或特征进行分类和回归。另一种方法是使用单阶段网络,该网络通过单一神经网络输出多个位置的检测结果。例如,Liu、Anguelov等人(2016)提出的SSD(单次多盒检测器)和Redmon、Divvala等人(2016)、Redmon和Farhadi(2017)以及Redmon和Farhadi(2018)描述的YOLO(你只需看一次)系列检测器。RetinaNet (Lin、Goyal等人,2017)也是一种基于特征金字塔网络构建的单阶段检测器。它利用焦点损失来集中训练,通过降低正确分类样本的损失权重,防止大量容易的负样本压倒训练过程。这些以及更近期的卷积物体检测器在Jiao、Zhang等人(2019)的最新综述中有所描述。图6.31展示了截至2017年初发布的检测器的速度和准确性。
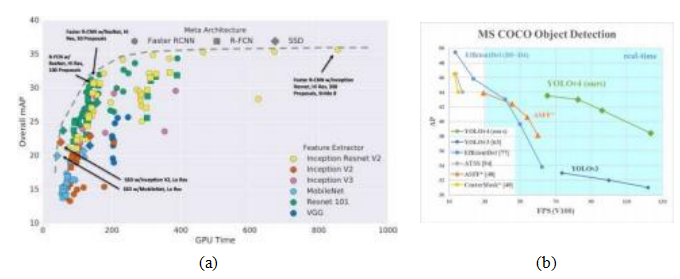
图6.31卷积物体检测器的速度/精度权衡:(a) (Huang,Rathod等人,2017)©2017 IEEE;(b) YOLOv4©Bochkovskiy,Wang和Liao(2020)。
最新的YOLO检测器家族成员是Bochkovskiy、Wang和Liao(2020)提出的YOLOv4。除了在性能上超越其他近期的快速检测器如EfficientDet(Tan、Pang和Le,2020),如图Figure6.31b所示,该论文还将处理流程分为几个阶段,包括一个颈部模块,该模块执行特征金字塔网络中的自上而下的特征增强。此外,论文还评估了许多不同的组件,这些组件被归类为“免费工具包”,可以在训练时使用,以及“特殊工具包”,可以在检测时以最小的额外成本使用。
虽然大多数边界框目标检测器继续在COCO数据集(Lin,Maire等人,2014)上评估其结果,但较新的数据集如Open Images (Kuznetsova,Rom等人,2020)和LVIS:大规模词汇实例分割(Gupta,Doll r,和Girshick,2019)现在也被使用(见表6.2)。最近的两个研讨会重点介绍了使用这些数据集的最新成果,分别是Zendel等人(2020)和Kirillov,Lin等人(2020),并且还涉及了与实例分割、全景分割、关键点估计和密集姿态估计相关的挑战,这些主题我们将在本章后面讨论。用于训练和微调目标检测器的开源框架包括TensorFlow object Detection。
| 名称/网址 | 范围 | 内容/参考 | ||
| 对象识别 | ||||
| 牛津建筑数据集 建筑物图片 https://www.robots.ox.ac.uk/~ vgg/data/oxbuildings INRIA假期 假日场景 https://lear.inrialpes.fr/people/jegou/data.php 帕斯卡 分割,框 http://host.robots.ox.ac.uk/pascal/VOC 图像网 完成图片 https://www.image-net.org 时尚MNIST 完成图片 https://github.com/zalandoresearch/fashion-mnist | 5062张图像 Philbin、Chum等人(2007)1,491张图像 J gou、Douze和Schmid (2008)11k张图像(2.9k张带分割的图像) Everingham、Eslami等人(2015)21k(WordNet)类别,14M张图像 邓、董等(2009)70k时尚产品 Xiao、Rasul和Vollgraf(2017) | |||
| 物体检测和分割 | ||||
| 加州理工学院行人数据集边界框 http://www.vision.caltech.edu/Image-Datasets/CaltechPedestrians MSR剑桥 每像素分割 https://www.microsoft.com/en-我们/研究/项目/图像理解 LabelMe数据集 多边形边界 http://labelme.csail.mit.edu 微软COCO 分割,框 https://cocodataset.org 城市景观 多边形边界 https://www.cityscapes-dataset.com 布罗登 分割掩模 http://netdissect.csail.mit.edu 布罗登+ 分割掩模 https://github.com/CSAILVision/unifiedparsing 利兹 实例分割 https://www.lvisdataset.org 打开图片 段落,关系 https://g.co/dataset/openimages | 行人 Doll r,Wojek等人( 2009)23类 Shotton、Winn等人(2009)>500个类别 Russell、Torralba等人(2008)330k张图像 Lin,Maire等人(2014)30个类别,25,000张图像 Cordts、Omran等人(2016)多种视觉概念 Bau、Zhou等人(2017)多种视觉概念 Xiao,Liu等人(2018) 1000类,220万张图片 Gupta、Doll r和Girshick(2019
)478k张图像,3M个关系 库兹涅佐娃、Rom等人(2020) | |||


图6.32图像分割示例(Kirillov,He等人,2019)©2019 IEEE:(a)原始图像;(b)语义分割(逐像素分类);(c)实例分割(划分每个对象);(d)全景分割(标注所有物体和物品)。
一个具有挑战性的通用物体识别和场景理解版本是同时执行识别和精确边界分割(Fergus2007)。在本节中,我们探讨了一些相关问题,即语义分割(逐像素类别标注)、实例分割(准确划分每个独立对象)、全景分割(标注对象和背景)以及密集姿态估计(标注属于人体及其身体部位的像素)。图6.32和6.43展示了这些类型的分割示例。
同时识别和分割的基本方法是将问题表述为给图像中的每个像素标注其类别归属。早期的方法通常使用能量最小化或贝叶斯推断技术来实现这一点,即条件随机场(第4.3.1节)。Shotton、Winn等人(2009年)的TextonBoost系统基于特定图像的颜色分布(第4.3.2节)、位置信息(例如,前景物体更可能位于图像中央,天空更可能较高,道路更可能较低)以及使用共享提升训练的新颖纹理布局分类器,采用一元(像素级)势能。它还使用传统的成对势能,考虑图像颜色梯度。纹理布局特征首先通过一系列17个方向滤波器组过滤图像,然后聚类响应以将每个像素分类为30种不同的纹理类别(Malik、Belongie等人,2001年)。随后,响应使用经过联合提升训练的偏移矩形区域进行过滤(Viola和Jones,2004年),生成用作一元势能的纹理布局特征。图6.33展示了一些成功使用TextonBoost标记和分割的图像示例。
TextonBoost条件随机场框架已被扩展到LayoutCRFs

图6.33使用TextonBoost (Shotton,Winn等人,2009)同时识别和分割©2009 Springer。
温恩和肖顿(2006)引入了额外的约束条件,以识别多个对象实例并处理遮挡问题;霍伊姆、罗瑟和温恩(2007)则引入了完整的三维模型。条件随机场继续被广泛使用,并扩展到同时进行识别和分割的应用中,如本书第一版所述(Szeliski2010,第14.4.3节),以及那些首先执行低级或层次化分割的方法(第7.5节)。
全卷积网络(Long、Shelhamer和Darrell 2015)的发展,我们在第5.4.1节中有所介绍,使得使用单一神经网络实现逐像素语义标注成为可能。尽管早期的网络分辨率较低(边界非常模糊),但在最终阶段加入条件随机场(Chen、Papandreou等2018;Zheng、Jayasumana等2015)、反卷积上采样(Noh、Hong和Han 2015)以及U-Net中的精细连接(Ronneberger、Fischer和Brox 2015),这些改进都有助于提高准确性和分辨率。
现代语义分割系统通常基于诸如特征金字塔网络(Lin,Doll等人,2017)等架构构建,这些架构具有自上而下的连接,有助于将语义
信息传递到更高分辨率的地图中。例如,赵、石等人(2017)提出的金字塔场景解析网络(PSPNet)使用空间金字塔池化(He,Zhang等人,2015)来聚合不同分辨率级别的特征。肖、刘等人(2018)提出的统一感知解析网络(UPerNet)则同时使用特征金字塔网络和金字塔池化模块,不仅标注图像像素的对象类别,还
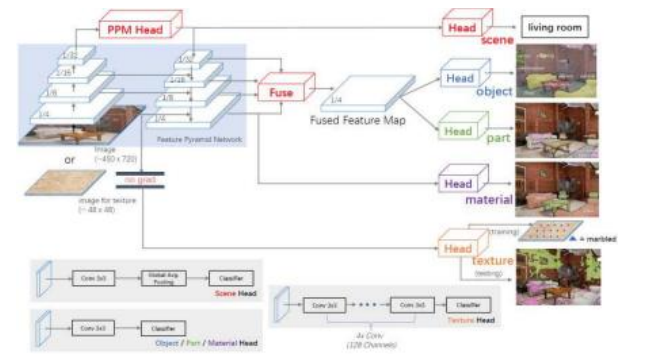
图6.34统一感知解析(Xiao,Liu等,2018)的UPerNet框架©2018斯普林格。特征金字塔网络(FPN)主干在输入到FPN的自上而下的分支之前,附加了一个金字塔池化模块(PPM)。FPN和/或PPM的各个层被输入到不同的头部,包括用于图像分类的场景头、来自融合FPN特征的对象和部分头、在FPN最细粒度级别操作的材料头,以及不参与FPN微调的纹理头。底部灰色方块提供了某些头部的更多细节。
材料、部件和纹理,如图6.34所示。HRNet(王、孙等人,2020)在整个管道中保留了特征图的高分辨率版本,并在不同分辨率层之间偶尔交换信息。此类网络还可以用于估计图像中的表面法线和深度(黄、周等人,2019;王、格拉吉蒂等人,2020)。
语义分割算法最初是在MSRC (Shotton,Winn等,2009)和PASCAL VOC (Everingham,Eslami等,2015)等数据集上进行训练和测试的。近年来的数据集包括用于城市场景理解的城市景观数据集(Cordts,Omran等,2016)和ADE20K (Zhou,Zhao等,2019),后者标注了150个不同类别和部分标签的更广泛的室内和室外场景像素。Bau,Zhou等(2017)创建的广泛且密集标注数据集(Broden)整合了多个此类密集标注数据集,包括ADE20K、Pascal-Context、Pascal-Part、OpenSur- faces和可描述纹理,以获得材料和纹理等广泛标签。
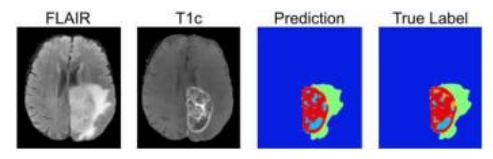
图6.35使用深度网络的三维体积医学图像分割(Kamnitsas,Ferrante等人,2016)©2016 Springer。
除了基本的对象语义之外,该数据集最初是为了帮助解释深度网络而开发的,但也已被证明(经过扩展后)对于训练统一多任务标注系统如UPerNet (Xiao,Liu等,2018)非常有用。表6.2列出了用于训练和测试语义分割算法的一些数据集。
最后一点。虽然语义图像分割和标注在图像理解中有着广泛的应用,但将场景的语义草图或绘画转化为逼真图像的问题也受到了广泛关注(Johnson,Gupta和Fei-Fei 2018;Park,Liu等2019;Bau,Strobelt等2019;Ntavelis,Romero等2020b)。我们将在第10.5.3节中详细讨论这一主题,涉及语义图像合成。
图像分割最有前景的应用之一是在医学影像领域,可以用于分割解剖组织以供后续定量分析。图4.21展示了一个带有方向边的二值图割,用于分割肝脏组织(浅灰色)与其周围的骨骼(白色)和肌肉(深灰色)组织。图6.35展示了脑部扫描中用于检测脑肿瘤的分割过程。在现代图像分割算法中使用的成熟优化和深度学习技术发展之前,这种处理需要对单个X光切片进行更为繁琐的手动追踪。
最初,医学图像分割使用了诸如马尔可夫随机场(第4.3.2节)和区分性分类器如随机森林(第5.1.5节)等优化技术(Criminisi、Robertson等人,2013)。最近,该领域转向了深度学习方法(Kamnitsas、Ferrante等人,2016;Kamnitsas、Ledig等人,2017;Havaei、Davy等人,2017)。
医学图像分割(McInerney和Terzopoulos1996)和医学图像配准(Kybic和Unser2003)(第9.2.3节)是研究领域丰富

图6.36使用Mask R-CNN进行实例分割(He、Gkioxari等人,2017年)©2017
IEEE:(a)系统架构,附加分割分支;(b)样本结果。
他们自己专门举办的会议,如医学影像计算和计算机辅助介入(MICCAI),以及期刊,如医学影像分析和IEEE医学影像学杂志。这些可以成为该领域研究的参考和灵感来源。
实例分割是寻找图像中所有相关对象并为其可见区域生成像素级掩模的任务(图6.36b)。一种潜在的方法是执行已知对象实例识别(第6.1节),然后将对象模型反投影到场景中(Lowe2004),如图6.1d所示,或者将新场景的部分与预学习的(分割的)对象模型匹配(Ferrari,Tuytelaars,和Van Gool2006b;Kannala,Rahtu等2008)。然而,这种方法仅适用于已知的刚性3D模型。
对于更复杂的(灵活的)对象模型,如人类模型,一种不同的方法是将图像预分割成更大或更小的部分(第7.5节),然后将这些部分与模型的部分进行匹配(Mori,Ren等,2004;Mori2005;He,Zemel,和Ray2006;Gu,Lim等,2009)。对于一般高度可变的类别,一种相关的方法是根据特征对应关系投票确定潜在的对象位置和尺度,然后推断对象的范围(Leibe,Leonardis,和Schiele2008)。
随着深度学习的出现,研究人员开始将区域建议或图像预分割与卷积第二阶段结合,以推断最终实例分割(Hariharan,Arbel ez等人2014;Hariharan,Arbel ez等人2015;Dai,He和Sun2015
;Pinheiro,Lin等人2016
;Dai,He和Sun2016;Li,Qi等人2017)。
实例分割的突破是Mask R-CNN的引入

图6.37使用Mask R-CNN进行人物关键点检测和分割(He,Gkioxari et al.2017)©2017 IEEE
(He,Gkioxari等,2017)。如图6.36a所示,Mask R-CNN使用了与Faster R-CNN (Ren,He等,2015)相同的区域提议网络,但在此基础上增加了一个额外的分支用于预测对象掩码,除了现有的边界框精炼和分类分支外。与其他具有多个分支(或头)和输出的网络一样,每个监督输出对应的训练损失需要仔细平衡。还可以添加其他分支,例如,用于检测人体关键点位置的分支(通过关键点掩码图像实现),如图6.37所示。
自引入以来,Mask R-CNN及其扩展的性能随着骨干架构的进步而持续提升(Liu,Qi等2018;Chen,Pang等2019)。最近两个突出展示该领域最新成果的工作坊是COCO + LVIS联合识别挑战赛(Kirillov,Lin等2020)和鲁棒视觉挑战赛(Zendel等2020)。此外,还可以用时间演化的闭合轮廓,即“蛇”(第7.3.1节),来替代大多数实例分割技术生成的像素掩码,如Peng,Jiang等(2020)所述。为了鼓励更高质量的分割边界,Cheng,Girshick等(2021)提出了一种新的边界交并比(Boundary IoU)指标,以替代常用的掩码交并比(Mask IoU)指标。
如我们所见,语义分割将图像中的每个像素分类为其语义类别,即每个像素对应什么。实例分割关联
具有单独对象的像素,即有多少个对象以及它们的范围

图6.38使用Panoptic特征金字塔网络(Kirillov,Girshick等人,2019)生成的全景分割结果©2019 IEEE。

图6.39 Detectron2对一些我个人照片的全景分割结果。(点击https://github.com/facebookresearch/detectron2and上的“Colab Notebook”链接,然后编辑输入图像URL来尝试自己的。)
(图6.32)。将这两个系统结合起来一直是语义场景理解的目标(Yao,Fidler和Urtasun 2012;Tighe和Lazebnik 2013;Tu,Chen等2005)。在像素级别上实现这一点,可以得到一个全景分割的场景,其中所有物体都被正确分割,剩余的部分也被正确标注(Kir- illov,He等2019)。设计一个合理的全景质量(PQ)指标,同时平衡两个任务的准确性,需要精心设计。在他们的论文中,Kirillov,He等(2019)描述了他们提出的指标,并分析了人类(以一致性为标准)和最近算法在三个不同数据集上的表现。
COCO数据集现已扩展,包括一个全景分割任务,最近的一些成果可以在ECCV 2020工作坊上找到(Kirillov,Lin等2020)。图6.38显示了由Kirillov,Girshick等(2019)描述的全景特征金字塔网络生成的一些分割结果,该网络在特征金字塔网络中增加了两个分支,分别用于实例分割和语义分割。

图6.40使用数百万张照片完成场景(Hays和Efros2007)©
2007年ACM:(a)原始图像;(b)去除不需要的前景后;(c)合理的场景匹配,用户选择的场景以红色突出显示;(d)替换和混合后的输出图像。
物体识别和场景理解的进步极大地增强了智能(半自动)照片编辑应用的能力。一个例子是Lalonde、Hoiem等人(2007年)的“照片剪辑艺术”系统,该系统能够识别并分割互联网照片集合中的感兴趣对象,如行人,然后允许用户将它们粘贴到自己的照片中。另一个例子是Hays和Efros(2007年)的场景补全系统,它解决了我们在第10.5节将要研究的同一修复问题。给定一张图像,我们希望擦除并填充一大块区域(图6.40a-b),那么你从哪里获取填补编辑后图像空白的像素呢?传统方法要么使用平滑连续法(Bertalmio、Sapiro等人,2000年),要么从图像的其他部分借用像素(Efros和Leung,1999;Criminisi、P rez和Toyama,2004;Efros和Freeman,2001)。随着网络上大量图像的可用性,通常更有意义的是找到另一张图像作为缺失像素的来源。
在他们的系统中,海斯和埃夫罗斯(2007)计算每张图像的要点(奥利瓦和托拉尔巴2001;托拉尔巴、墨菲等人2003),以找到颜色和构图相似的图像。然后他们运行一个图割算法,该算法最小化图像梯度差异,并使用泊松图像融合(第8.4.4节)(普雷兹、甘格内特和布莱克2003)将新的替换部分合成到原始图像中。图6.40d显示了结果图像,其中
被擦除的前景屋顶区域被帆船所替代。由阿维丹、贝克和山编辑的特别期刊专刊(2010)中,还可以找到更多由所谓的“互联网计算机视觉”支持的照片编辑和计算摄影应用示例。
图像识别和分割的另一种应用是通过识别特定场景结构从单张照片中推断出三维结构。例如,Criminis,Reid,

图6.41自动照片弹出窗口(Hoiem、Efros和Hebert2005a)©2005 ACM:
(a)输入图像;(b)超像素被分为(c)多个区域;(d)标签表示地面(绿色)、垂直方向(红色)和天空(蓝色);(e)结果分段平面3D模型的新视角。
齐瑟曼(2000)检测消失点,并让用户绘制基本结构,如墙壁,以推断三维几何(第11.1.2节)。霍伊姆、埃夫罗斯和赫伯特(2005a)则处理更“有机”的场景,例如图6.41所示。他们的系统使用多种分类器和从标记图像中学习到的统计方法,将每个像素分类为地面、垂直或天空(图6.41d)。为此,他们首先计算超像素(图6.41b),然后将其分组为可能具有相似几何标签的合理区域(图6.41c)。所有像素被标记后,可以利用垂直像素与地面像素之间的边界来推断图像沿哪些三维线折叠成“弹出”效果(移除天空像素后),如图6.41e所示。在相关工作中,萨克森、孙和吴(2009)开发了一种系统,直接推断每个像素的深度和方向,而不仅仅是使用三个几何类别标签。我们将在第12.8节中详细探讨从单张图像推断深度的技术。
6.4.5姿态估计
从单张图像推断人体姿态(头部、身体和四肢的位置和姿态)可以看作是另一种分割任务。我们已经讨论过
第6.3.2节中给出了行人检测部分的一些姿态估计技术,如图所示
图6.25.自Felzenszwalb和Huttenlocher(2005)的开创性工作开始,二维和三维姿态检测与估计迅速发展成为活跃的研究领域,并取得了重要的进展和数据集(Sigal和Black2006a;Rogez、Rihan等人2008;Andriluka、Roth和Schiele2009;Bourdev和Malik2009;Johnson和Everingham2011;Yang和Ramanan2011;Pishchulin、Andriluka等人2013;Sapp和Taskar2013;Andriluka、Pishchulin等人2014)。
最近,深度网络已成为识别人体关键点的首选技术,以便将其转换为姿态估计(Tompson,Jain等人,2014;

图6.42 OpenPose实时多个人2D姿态估计(Cao,Simon et al.2017)©2017 IEEE。
Toshev和Szegedy 2014;Pishchulin、Insafutdinov等人2016;Wei、Ramakrishna等人2016;Cao、Simon等人2017;He、Gkioxari等人2017;Hidalgo、Raaj等人2019;Huang、Zhu等人2020)。图6.42显示了OpenPose系统(Cao、Hidalgo等人2019)生成的一些令人印象深刻的实时多人2D姿态估计结果。
在人体姿态估计中,最新的、最具挑战性的任务是DensePose任务
由G ler、Neverova和Kokkinos(2018)提出,其中任务是将每个像素与之关联
图6.43展示了基于表面模型的人体3D点RGB图像。作者为COCO图像中出现的50,000个人提供了密集注释,并评估了多种对应网络,包括他们自己的DensePose-RCNN及其几种扩展。关于3D人体建模和跟踪的更深入讨论,请参见第13.6.4节。
正如我们在本章前面几节中所看到的,图像理解主要关注于命名和描述图像中的物体和物品,尽管物体与人之间的关系有时也会被推断出来(Yao和Fei-Fei2012;Gupta

图6.43密集姿态估计旨在映射RGB图像中所有的人体像素
至人体3D表面(G ler、Neverova和Kokkinos2018)©2018 IEEE。
本文描述了DensePose-COCO,一个大规模的真实数据集,包含50K个人的手动注释的图像到表面对应关系,以及DensePose-RCNN,训练以每秒多个帧密集回归UV坐标。
以及Malik2015;Yatskar、Zettlemoyer和Farhadi2016;Gkioxari、Girshick等人2018)。(我们将在关于视觉与语言的下一节中讨论描述完整图像的主题。)
那么,什么是视频理解呢?对于许多研究者来说,它始于对人类动作的检测和描述,这些动作被视为视频的基本原子单位。当然,就像图像一样,这些基本的原语可以被链接成更完整的对较长视频序列的描述。
人类活动识别研究始于20世纪90年代,同时期还涉及了人体运动跟踪等相关课题,相关内容将在第9.4.4节和第13.6.4节中讨论。阿加瓦尔和蔡(1999)对这两个领域进行了全面综述,他们称之为人体运动分析。他们调查的一些技术包括点跟踪、网格跟踪以及时空特征。
在2000年代,研究重点转向了时空特征,例如巧妙利用小区域中的光流来识别体育活动(Efros,Berg等人,2003年),或用于电影中动作分类的时空特征检测器(Laptev,Marszalek等人,2008年),后来结合图像上下文(Marszalek,Laptev,和Schmid,2009年)和跟踪特征轨迹(Wang和Schmid,2013年)。Poppe(2010年)、Aggarwal和Ryoo(2011年)以及Weinland、Ronfard和Boyer(2011年)提供了本十年算法的综述。一些
本研究使用的数据集包括KTH人体运动数据集(Sch ldt,Laptev,
以及Caputo2004)、UCF体育动作数据集(Rodriguez、Ahmed和Shah2008)、好莱坞人体动作数据集(Marszalek、Laptev和Schmid2009)、UCF-101(Soomro、Zamir和Shah2012)和HMDB人体运动数据库(Kuehne、Jhuang等人2011)。近十年来,视频理解技术已转向使用深度网络。
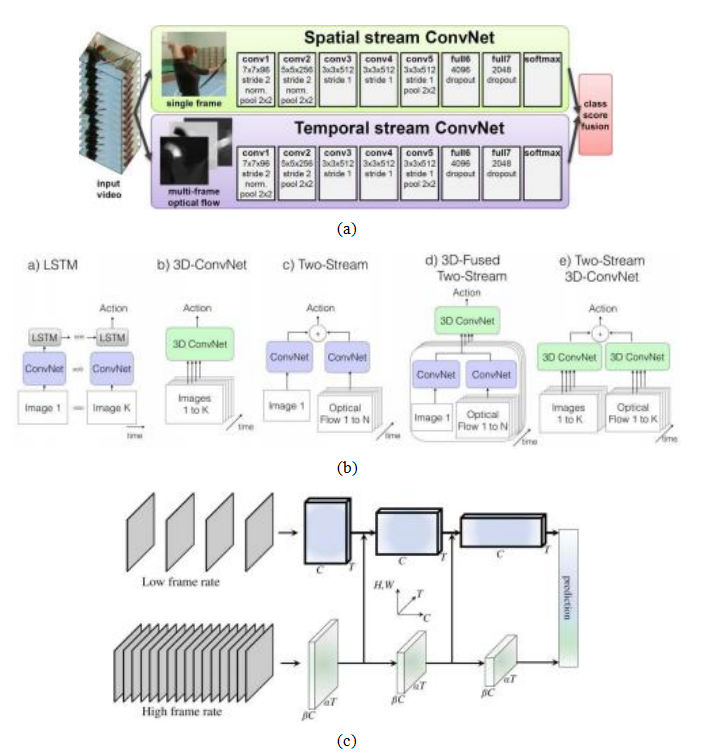
视频分类©Simonyan和Zisserman(2014a);(b)一些替代的视频处理架构(Carreira和Zisserman 2017)©2017 IEEE;(c)一种低帧率、低时间分辨率的慢路径和高帧率、高时间分辨率的快路径的SlowFast网络(Feichtenhofer,Fan等2019)©2019 IEEE。
(Ji,Xu等人,2013;Karpathy,Toderici等人,2014;Simonyan和Zisserman,2014a;Tran,Bourdev等人,2015;Feichtenhofer,Pinz和Zisserman,2016;Carreira和Zisserman,2017;Varol,Laptev和Schmid,2017;Wang,Xiong等人,2019;Zhu,Li等人,2020),有时与时间模型如LSTM结合(Baccouche,Mamalet等人,2011;Donahue,Hendricks等人,2015;Ng,Hausknecht等人,2015;Srivastava,Mansimov和Salakhudinov,2015)。
虽然可以直接将这些网络应用于视频流中的像素,例如使用三维卷积(第5.5.1节),研究人员还探讨了使用光流(第9.3章)作为额外输入。由此产生的双流架构由西蒙尼安和齐瑟曼(2014a)提出,并如图6.44a所示。卡雷拉和齐瑟曼(2017)后来的一篇论文将这种架构与像素流上的三维卷积以及两流和三维卷积的混合体进行了比较(图6.44b)。
最新的视频理解架构已回归到在原始像素流上使用3D卷积(Tran,Wang等2018,2019;Kumawat,Verma等2021)。Wu,Feichtenhofer等(2019)将3D卷积特征存储到他们称为长期特征库中,以提供更广泛的时间上下文用于动作识别。Feichtenhofer,Fan等(2019)提出了一种双流SlowFast架构,其中慢路径以较低帧率运行,并与快速路径结合,后者具有更高的时间采样但通道数较少(图6.44c)。表6.3总结了一些广泛用于评估这些算法的数据集。它们包括Charades(Sigurdsson,Varol等2016)、YouTube8M(Abu-El-Haija,Kothari等2016)、Kinetics(Carreira和Zisserman 2017)、“Something-something”(Goyal,Kahou等2017)、AVA (Gu,Sun等2018)、EPIC-厨房(Damen,Doughty等2018)和AVA-Kinetics (Li,Thotakuri等2020)。关于这些及其他视频理解算法的精彩介绍可以在Johnson (2020,第18讲)中找到。
与图像识别一样,研究人员也开始使用自监督算法来训练视频理解系统。与图像不同,视频片段通常是多模态的,即除了像素外还包含音频轨道,这可以成为未标记监督信号的极佳来源(Alwassel,Mahajan等2020;Patrick,Asano等2020)。当在推理时可用时,音频信号可以提高此类系统的准确性(Xiao,Lee等2020)。
最后,虽然动作识别是最近视频理解工作的主要焦点,但也可以将视频分类为不同的场景类别,如“海滩”、“烟花”或“下雪”。这个问题被称为动态场景识别,可以
| 名称/网址 元数据 | 内容/参考 |
| 猜字谜 动作、对象、描述 https://prior.allenai.org/projects/charades YouTube 800万 实体 https://research.google.com/youtube8m 动力学 行动类别 https://deepmind.com/research/open-source/kinetics “某物-某物”与对象的交互 https://20bn.com/datasets/something-something 阿瓦 行动 https://research.google.com/ava 史诗厨房 操作和对象 https://epic-kitchens.github.io | 9.8k视频 Sigurdsson,Varol等人(2016)4.8k视觉实体,8M视频 Abu-El-Haija、Kothari等人(2016) 700个动作类别,65万视频Carreira和Zisserman(2017) 174个动作,220k个视频 Goyal、Kahou等人(2017) 80个动作,430个15分钟视频,Gu,Sun等人(2018) 100小时以自我为中心的视频Damen,Doughty等人(2018) |
表6.3视频理解与动作识别数据集。
计算机视觉研究的最终目标不仅仅是解决诸如构建世界三维模型或寻找相关图像等简单任务,而是成为人工智能(AGI)的重要组成部分。这要求视觉与其他人工智能组件如语音和语言理解与合成、逻辑推理以及常识和专业知识表示与推理相融合。
语音和语言处理技术的进步使得基于语音的智能虚拟助手如Siri、Google Assistant和Alexa得以广泛应用。在本章前面,我们已经了解了计算机视觉系统如何命名图像中的单个对象,并通过外观或关键词找到相似的图像。接下来自然而然地与其它人工智能组件集成的一步是将视觉和语言结合起来,即自然语言处理(NLP)。
尽管这一领域已经研究了很长时间(Duygulu,Barnard等,2002;Farhadi,Hejrati等,2010),但过去十年中,其性能和能力有了迅速提升(Mogadala,Kalimuthu和Klakow,2021;Gan,Yu等,2020)。一个例子是库尔卡尼、普雷姆拉杰等人(2013)开发的BabyTalk系统,该系统首先检测物体、它们的属性及其位置关系,然后推断出这些物体可能的兼容标签,最后生成图像描述,如图6.45a所示。

图6.45图像描述系统:(a) BabyTalk检测物体、属性和位置关系,并将这些信息组合成图像描述(Kulkarni,Premraj等2013)©2013 IEEE;(b-c)DenseCap将词语短语与区域关联,然后使用RNN构建合理的句子(Johnson,Karpathy和Fei-Fei 2016)©2016 IEEE。

图6.46注意力图像描述:(a)“展示、关注和讲述”系统,利用硬注意力将生成的词语与图像区域对齐©胸,Ba等人(2015);(b)使用不同检测器生成的神经婴儿对话描述,展示了词语与基础区域之间的关联(Lu,Yang等人,2018)©2018 IEEE。
视频字幕
接下来的几年里,关于图像描述和标注的论文如雨后春笋般涌现,包括(陈和劳伦斯·齐特尼克2015;多纳休、亨德里克斯等人2015;方、古普塔等人2015;卡帕西和费-菲2015;维尼亚尔、托舍夫等人2015;徐、巴等人2015;约翰逊、卡帕西和费-菲2016;杨、何等人2016;尤、金等人2016)。许多系统将基于CNN的图像理解组件(主要是物体和人物动作检测器)与RNN或LSTM结合,以生成描述,通常与其他技术如多实例学习、最大熵语言模型和视觉注意力相结合。一个令人惊讶的早期结果是,最近邻技术,即找到具有相似标题的图像集并创建共识标题,表现得非常出色(德夫林、古普塔等人2015)。
近年来,基于注意力机制的系统一直是图像描述系统的重要组成部分(Lu,Xiong等,2017;Anderson,He等,2018;Lu,Yang等,2018)。图6.46展示了两篇相关论文的例子,其中生成的每个字都与相应的图像区域相对应。CVPR 2020教程(Zhou 2020)总结了过去五年中二十多篇相关的论文,包括使用变压器(第5.5.3节)进行描述的论文。该教程还涵盖了视频描述的

图6.47©Goh、Camarata等人(2021)发现的针对CLIP的对抗性打字攻击(Radford、Kim等人,2021)。与预测场景中存在的对象不同,CLIP根据对抗性的手写标签来预测输出。
以及密集视频字幕(Aafaq,Mian等,2019;Zhou,Kalantidis等,2019)和视觉-语言预训练(Sun,Myers等,2019;Zhou,Palangi等,2020;Li,Yin等,2020)。教程还包含关于视觉问答和推理(Gan2020)、文本到图像合成(Cheng2020)以及视觉-语言预训练(Yu,Chen,和Li 2020)的讲座。
对于图像分类任务(第6.2节),一个主要限制是模型只能预测其训练时使用的离散预定义标签集中的一个标签。CLIP (Radford,Kim等,2021)提出了一种替代方法,该方法依赖于图像描述,以实现零样本迁移至任何可能的标签集。给定一张带有标签集的图像(例如,{狗;猫;……;房子}),CLIP预测能够最大化图像被描述为“一张{标签}的照片”的概率的标签。第5.4.7节讨论了CLIP的训练方面,该方法收集了4亿个文本-图像对,并使用对比学习来确定图像与描述配对的可能性。
令人惊讶的是,CLIP在没有见过或微调过许多流行图像分类基准(如ImageNet、Caltech 101)的情况下,能够超越独立微调的ResNet-50模型在每个特定数据集上的表现。此外,与最先进的分类模型相比,CLIP的零样本泛化能力对数据分布的变化更为稳健,在ImageNet Sketch(Wang,Ge等2019)、ImageNetV2(Recht,Roelofs等2019)和ImageNet-R(Hendrycks,Basart等2020)等数据集上均表现出色,而无需针对这些数据集进行专门训练。事实上,Goh,Cammarata等人(2021)发现,CLIP单元对不同模态呈现的概念(例如,蜘蛛侠的图片、“蜘蛛”一词的文字以及蜘蛛侠的画作)的反应相似。图6.47显示了他们发现的一种对抗性打字攻击,可以欺骗CLIP。通过简单地将手写类别标签(例如,iPod)放在现实物体(例如,苹果)上,CLIP经常预测出标签上所写的类别。
与其他视觉识别和基于学习的系统领域一样,数据集在视觉和语言系统的开发中发挥了重要作用。一些广泛使用的带有标题的图像数据集包括概念性标题(Sharma,Ding等人,2018),

图6.48来自Visual Genome数据集的图像和数据(Krishna,Zhu等人,2017)©
2017斯普林格。(a)一个示例图像及其区域描述符。(b)每个区域都有一个对象、属性和两两关系的图表示,这些图被组合成场景图,在这个图中所有对象都与图像关联,并且还关联了问题和答案。(c)一些样本问题和答案对,涵盖了从识别到高级推理的各种视觉任务。
| 名称/网址 元数据 | 内容/参考 |
| Flickr30k(实体)图片说明(基于地面) https://shannon.cs.illinois.edu/DenotationGraph http://bryanplummer.com/Flickr30kEntities COCO字幕 全部图片说明 https://cocodataset.org/#captions-2015 概念性字幕完整图像字幕 https://ai.google.com/research/ConceptualCaptions 100米远场 Flickr元数据 http://projects.dfki.uni-kl.de/yfcc100m 视觉基因组 密集注释 https://visualgenome.org VQA v2.0 问题/回答对 https://visualqa.org 视频通话 多项选择题 https://visualcommonsense.com 广岛县 Compositional QA https://visualreasoning.net 视控 聊天机器人的对话框 https://visualdialog.org | 30k张图像(+边界框)Young,Lai等人(2014) Plummer、Wang等人(2017)150万字幕,33万张图像 Chen、Fang等人(2015)3.3M图像说明对 Sharma、Ding等人(2018)100M张带元数据的图像 Thomee、Shamma等人(2016)108k张图像,带区域图 Krishna、Zhu等人(2017)265k张图像 Goyal、Khot等人(2017)110k电影片段,290k问答 Zellers、Bisk等人(2019) 关于视觉基因组的220万问题 Hudson和Manning(2019)120k COCO图像+对话 Das,Kottur等人(2017) |
UIUC帕斯卡句子数据集(法哈迪、赫尔拉蒂等人,2010年)、SBU带注释图片数据集(奥多涅兹、库尔卡尼和伯格,2011年)、Flickr30k(杨、莱等人,2014年)、COCO标题(陈、方等人,2015年),以及每张图像包含50个句子的扩展版本(韦丹塔姆、劳伦斯·齐特尼克和帕里克,2015年)(见表6.4)。更密集标注的数据集如视觉基因组(克里希纳、朱等人,2017年)描述了图像的不同子区域及其各自的短语,即提供密集的标题,如Figure6.48所示。YFCC100M(托米、沙玛等人,2016年)包含来自Flickr的大约1亿张图片,但仅包括每个图片的原始用户上传元数据,如标题、上传时间、描述、标签和(可选地)图片位置。
衡量句子相似性的指标在图像描述和其他视觉与语言系统的发展中也发挥着重要作用。一些广泛使用的指标包括:BLEU:双语评估(Papineni等,2002年),ROUGE:基于召回的摘要评价(Lin,2004年),METEOR:显式排序翻译评估指标(Banerjee和Lavie,2005年),CIDEr:共识基础的
图6.49 DALL·E的定性文本生成图像结果,展示了广泛的泛化能力©Ramesh,Pavlov等(2021)。右下角的例子提供了一个部分完成的猫的图像提示,以及文字,模型会填充其余部分。其他三个例子仅以文字提示作为输入,模型生成整个图像。
图像描述评价(Vedantam、Lawrence Zitnick和Parikh2015)和香料:语义命题图像描述评价(Anderson、Fernando等人2016)。27
文本生成图像
文本生成图像的任务是视觉字幕的逆过程,即给定一个文本提示,生成相应的图像。由于图像具有如此高的维度,使其看起来连贯历来都十分困难。从文本提示生成图像可以视为从少量类别标签生成图像的一种泛化(第5.5.4节)。由于可能的文本提示几乎是无限的,成功的模型必须能够从训练中看到的相对较少的部分进行泛化。
早期关于这一任务的研究,如Mansimov、Parisotto等人(2016)的工作,使用RNN从头开始迭代地生成图像。他们的结果与文本提示有些相似,但生成的图像相当模糊。次年,Reed、Akata等人(2016)将GAN应用于该问题,未见过的文本提示开始显示出有希望的结果。他们生成的图像相对较小(64×64),后来的研究在这方面有所改进,通常首先生成小规模图像,然后基于该图像和文本输入生成更高分辨率的图像(Zhang、Xu等人,2017,2018;Xu、Zhang等人,2018;Li、Qi等人,2019)。
DALL·E(Ramesh,Pavlov等人,2021)使用了数量级更多的数据(2.5亿
互联网上的图像-文本对)并计算以实现惊人的定性结果(图6.49)。他们的方法在超越训练数据泛化方面产生了有希望的结果,甚至能够组合不常相关的对象(例如,扶手椅和牛油果),生成多种风格(例如,绘画、卡通、炭笔画),并且在处理困难对象时表现得相当不错(例如,镜子或文字)。
DALL·E的模型由两个组件构成:VQ-VAE-2(第5.5.4节)和解码器变压器(第5.5.3节)。文本被分词为256个标记,每个标记是16,384个可能向量之一,使用BPE编码(Sennrich,Haddow和Birch 2015)。VQ-VAE-2使用大小为8,192的代码本(显著大于原始VQ-VAE-2论文中使用的512代码本),将图像压缩为32×32的向量标记网格。在推理时,DALL·E使用变压器解码器,从256个文本标记开始,自回归预测32×32的图像标记网格。给定这样的网格,VQ-VAE-2能够利用其解码器生成最终的256×256大小的RGB图像。为了获得更好的实验结果,DALL·E生成512张图像候选,并使用CLIP (Radford,Kim等2021)重新排序这些图像,CLIP决定给定标题与给定图像关联的可能性。
一个引人入胜的DALL·E扩展是使用VQ-VAE-2编码器来预测压缩图像令牌的一部分。例如,假设我们有一个文本输入和一张图片。文本输入可以被分解为其256个令牌,然后可以使用VQ-VAE-2编码器获得32×32的图像令牌。如果我们丢弃图像令牌的下半部分,变压器解码器就可以自回归地预测哪些令牌可能存在于那里。这些令牌,连同未被丢弃的原始图像中的令牌,可以传递给VQ-VAE-2解码器以生成完整的图像。图6.49(右下角)展示了如何使用这样的文本和部分图像提示应用于图像到图像转换(第5.5.4节)。
视觉问题回答和推理
图像和视频字幕是有助于我们构建人工智能系统的有用任务,因为它们展示了将视觉线索如物体身份、属性和动作组合起来的能力。然而,系统是否真正理解了场景的深层含义,以及能否对构成部分及其组合方式进行推理,目前仍不清楚。
图像,如图6.48c所示。许多这项工作始于视觉问答(VQA)数据集的创建(Antol,Agrawal等,2015),这激发了大量后续研究。次年,VQA v2.0通过创建平衡的图像对集改进了这一数据集,每个问题在两个图像中有不同的答案(Goyal,Khot等,2017)。该数据集进一步扩展,以减少先前假设和数据分布的影响,并鼓励答案基于图像(Agrawal,Batra等,2018)。
自那时起,许多额外的VQA数据集被创建。这些包括用于视觉常识推理的VCR数据集(Zellers,Bisk等人,2019年)以及用于评估视觉推理和组合问题回答的GQA数据集和指标(Hudson和Manning,2019年),后者基于通过视觉基因组场景图提供的关于对象、属性和关系的信息(Krishna,Zhu等人,2017年)。关于这些及其他VQA数据集的讨论可以在Gan(2020年)在CVPR 2020教程中找到,其中包括测试视觉定位和指称表达理解、视觉蕴含、使用外部知识、阅读文本、回答子问题和使用逻辑的数据集。部分数据集总结见表6.4。
与图像和视频字幕处理一样,VQA系统使用各种形式的注意力机制来关联像素区域与语义概念(杨、何等,2016)。然而,不同于使用RNN、LSTM或变压器等序列模型生成文本,自然语言问题首先被解析以产生编码,然后与图像嵌入融合,生成所需答案。
图像语义特征可以基于粗网格计算,或者结合“自下而上”的对象检测器和“自上而下”的注意力机制来提供特征权重(Anderson,He等,2018)。近年来,使用自下而上区域和网格化特征描述符的技术之间来回摇摆,最近表现最佳的两种算法又回到了更简单(且速度快得多)的网格化方法(Jiang,Misra等,2020;Huang,Zeng等,2020)。Gan(2020)在CVPR 2020教程中讨论了这些以及其他数十种VQA系统及其子组件,如多模态融合变体(双线性池化、对齐、关系推理)、神经模块网络、鲁棒VQA和多模态预训练。Mogadala、Kalimuthu和Klakow(2021)的综述以及年度VQA挑战研讨会(Shri-vasava,Hudson等,2020)也是获取更多信息的极佳来源。如果您想测试当前VQA系统的状态,可以将您自己的图像上传到https://vqa.cloudcv.org,并向系统提出您的问题。
视觉对话。VQA的一个更具挑战性的版本是视觉对话,在这种对话中,聊天机器人会收到一张图片,并被要求回答关于该图片的开放式问题,同时还要参考之前的对话元素。VisDial数据集是最早广泛用于此任务的数据集(Das,Kottur等,2017)。你可以在视觉对话研讨会和挑战赛中找到为此任务开发的系统指南(Shrivastava,Hudson等,2020)。此外,在https://visualchatbot.cloudcv.org上还有一个聊天机器人,你可以上传自己的图片并开始对话,有时这会导致幽默(或奇怪)的结果(Shane2019)。
视觉-语言预训练。与许多其他识别任务一样,预训练在过去几年中取得了显著的成功,例如ViLBERT (Lu,Batra等,2019年)、Oscar (Li,Yin等,2020年),以及CVPR 2020关于视觉-语言自监督学习教程中描述的许多其他系统(Yu,Chen,和Li,2020年)。
与机器学习或深度学习不同,近期没有专门针对图像识别和场景理解的一般主题的教科书或综述。一些早期的综述(Pinz2005;Andreopoulos和Tsotsos2013)和论文集(Ponce,Hebert等2006;Dickinson,Leonardis等2007)回顾了“经典”(深度学习前)的方法,但鉴于过去十年的巨大变化,许多这些技术已不再使用。目前,除了本章和大学计算机视觉课程外,主要视觉会议如ICCV (Xie,Girshick等2019)、CVPR (Girshick,Kirillov等2020)和ECCV (Xie,Girshick等2020)上的教程也是获取最新材料的最佳来源之一。表6.1–6.4that中列出的图像识别数据集的活跃排行榜也可以成为获取最新论文的良好来源。
例如,实例识别算法,即检测外观变化微小但可能在三维姿态上有所差异的静态制造对象,仍然经常基于检测二维兴趣点并使用视点不变描述符来描述它们,如第7章和(Lowe2004)、Rothganger、Lazebnik等人(2006)以及Gordon和Lowe(2006)所讨论的那样。近年来,注意力转向了更具挑战性的实例检索问题(也称为基于内容的图像检索),其中需要搜索的图像数量可以非常大(Sivic和Zisserman2009)。下一章第7.1.4节回顾了此类技术,Zheng、Yang和Tian(2018)的综述也是如此。这一主题还与视觉相似性搜索有关(Bell和Bala2015;Arandjelovic、Gronat等人。
Al.2016;Song,Xiang et al.2016;Gordo,Almaz n et al.2017
;Rawat and Wang2017;Bell,Liu et al.2020),这些研究均在Section6.2.3中进行了报道。
关于基于特征的全图(单对象)类别识别,已有大量调查、论文集和课程笔记被撰写(Pinz2005;Ponce,Hebert等2006;Dickinson,Leonardis等2007;Fei-Fei,Fergus和Torralba 2009)。其中一些论文使用了词袋或关键点(Csurka,Dance等2004;Lazebnik,Schmid和Ponce 2006;Csurka,Dance等2006;Grauman和Darrell 2007b;Zhang,Marszalek等2007;Boiman,Shechtman和Irani 2008;Ferencz,Learned-Miller和Malik 2008)。其他论文则基于对象轮廓进行识别,例如使用形状上下文(Belongie,Malik和Puzicha 2002)或其他技术(Shotton,Blake和Cipolla 2005;Opelt,Pinz和Zisserman 2006;Ferrari,Tuytelaars和Van Gool 2006a)。
许多物体识别算法使用基于部件的分解方法,以提高对关节和姿态的不变性。早期算法主要关注部件之间的相对位置(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991),而后期算法则采用了更复杂的外观模型(Felzenszwalb和Huttenlocher 2005;Fergus、Perona和Zisserman2007;Felzenszwalb,McAllester以及Ramanan 2008)。关于基于部件模型的识别,Fergus(2009)的课程笔记提供了很好的概述。Carneiro和Lowe(2006)讨论了用于基于部件识别的多种图形模型,包括树形图、星型图、k-扇形图和星座图。
经典识别算法通常将场景上下文作为其识别策略的一部分。该领域的代表性论文包括托拉尔巴(2003年)、托拉尔巴、墨菲等人(2003年)、拉比诺维奇、韦达利等人(2007年)、拉塞尔、托拉尔巴等人(2007年)、苏德斯、托拉尔巴等人(2008年)和迪瓦拉、霍伊姆等人(2009年)。机器学习也成为经典物体检测和识别算法的关键组成部分(费尔岑斯瓦尔布、麦克阿莱斯特和拉马南2008年;西维奇、拉塞尔等人2008年),利用大型人工标注数据库也是如此(拉塞尔、托拉尔巴等人2007年;托拉尔巴、弗里曼和弗格斯2008年)。
克里维斯基、苏特塞弗和欣顿(2012)的“AlexNet”超级视觉系统取得了突破性成功,这使得类别识别研究的重点从基于特征的方法转向了深度神经网络。如图5.40所示,识别准确率的快速提升在很大程度上得益于更深的网络和更优的训练算法,部分还归功于更大(未标注)的训练数据集(第5.4.7节)。
更专业的识别系统,如人脸识别系统,经历了类似的演变。虽然最早的一些人脸识别方法涉及找到独特的图像特征并测量它们之间的距离(Fischler和Elschlager 1973;Kanade 1977;Yuille 1991),但后来的方法则依赖于比较灰度-
图像通常投影到低维子空间(Turk和Pentland 1991;Belhumeur、Hespanha和Kriegman 1997;Heisele、Ho等2003),或局部二值模式(Ahonen、Hadid和Pietikinen 2006)。还开发了多种
形状和姿态变形模型(Beymer 1996;Vetter和Poggio 1997),包括活动形状模型(Cootes、Cooper等1995)、3D可变形模型(Blanz和Vetter 1999;Egger、Smith等2020)以及活动外观模型(Cootes、Edwards和Taylor 2001;Matthews和Baker 2004;Ramnath、Koterba等2008)。关于经典人脸识别算法的更多信息,可以在许多调查报告和书籍中找到(Chellappa、Wilson和Sirohey 1995;Zhao、Chellappa等2003;Li和Jain 2005)。
形状模型的概念在社区转向深度神经网络方法时继续被使用(Taigman,Yang等,2014)。然而,一些较新的深度人脸识别系统省略了正面化阶段,转而使用数据增强来生成具有更多姿态变化的合成输入(Schroff,Kalenichenko和Philbin,2015;Parkhi,Vedaldi和Zisserman,2015)。Masi,Wu等(2018)提供了一篇关于深度人脸识别的优秀教程和综述,包括广泛使用的训练和测试数据集列表、正面化和数据增强的讨论,以及训练损失的部分。
随着全图(单个对象)类别识别问题逐渐“解决”,研究重点转向了多对象轮廓划分和标注,即物体检测。物体检测最初是在特定类别如人脸、行人、汽车等的背景下进行研究的。人脸识别领域的开创性论文包括奥苏纳、弗伦德和吉罗西(1997年);宋和波吉奥(1998年);罗利、巴卢贾和卡纳德(1998年);维奥拉和琼斯(2004年);海塞勒、霍等人(2003年),杨、克里格曼和阿胡贾(2002年)则提供了该领域早期工作的全面综述。行人和汽车检测的早期工作由加夫里拉和菲洛明(1999年);加夫里拉(1999年);帕帕乔治奥和波吉奥(2000年);施耐德曼和卡纳德(2004年)完成。后续论文包括(米科拉伊奇克、施密德和齐瑟曼2004年;达拉尔和特里格斯2005年;莱贝、塞曼和席勒2005年;安德里卢卡、罗思和席勒2009年;多尔、贝隆吉和佩罗纳2010年;费尔岑斯瓦尔布、吉什克等人2010年)。
现代通用物体检测器通常采用区域提议算法(Uijlings,Van De Sande等,2013;Zitnick和Doll,2014)构建,该算法将图像中选定的区域(无论是
像素还是预计算的神经特征)输入多路分类器,从而形成如R-CNN (Girshick,Donahue等,2014)、Fast R-CNN (Girshick,2015)、Faster R-CCNN (Ren,He等,2015)和FPN (Lin,Doll等,2017)等架构。这种两阶段方法的另一种替代方案是单阶段网络,它使用单一网络在
多个位置输出检测结果。此类架构的例子包括
SSD (Liu,Anguelov等人,2016)、RetinaNet (Lin,Goyal等人,2017)和YOLO (Redmon,Divvala等人,2016;Redmon和Farhadi2017,2018;Bochkovskiy,Wang,以及Liao,2020)。这些以及更近期的卷积物体检测器在Jiao,Zhang等人(2019)的最新综述中进行了描述。
虽然在许多计算机视觉应用中,如计数汽车或行人甚至描述图像,对象检测已经足够,但详细的像素级标注可能更有用,例如用于照片编辑。这种标注有多种类型,包括语义分割(这是什么?)、实例分割(这是哪个可数对象?)、全景分割(这是什么或什么对象?)。早期解决这一问题的方法之一是将图像预分割成块,然后将这些块与模型的部分匹配(Mori,Ren等2004;Russell,Efros等2006;Borenstein和Ullman 2008;Gu,Lim等2009)。另一种流行的方法是使用
条件随机场(Kumar和Hebert2006;He,Zemel和Carreira-Perpi n2004;
温恩和肖顿2006;拉比诺维奇、韦达利等人2007;肖顿、温恩等人2009)。这些方法在当时在帕斯卡VOC分割挑战中取得了最佳结果之一。现代语义分割算法使用金字塔形全卷积架构,将输入像素映射到类别标签(龙、谢尔哈默和达雷尔2015;赵、石等人2017;肖、刘等人2018;王、孙等人2020)。
实例分割这一更具挑战性的任务,每个不同的对象都需要一个独特的标签,通常通过结合物体检测器和逐对象分割来解决,这在He、Gkioxari等人(2017)的开创性论文《Mask R-CNN》中得到了体现。后续研究使用了更复杂的主干架构(Liu、Qi等人,2018;Chen、Pang等人,2019)。最近两个突出展示该领域最新成果的工作坊是COCO + LVIS联合识别挑战赛(Kirillov、Lin等人,2020)和鲁棒视觉挑战赛(Zendel等人,2020)。
将语义分割和实例分割结合在一起一直是语义场景理解的目标(Yao,Fidler,和Urtasun 2012;Tighe和Lazebnik 2013;Tu,Chen等2005)。在像素级别上实现这一点可以得到一个全景分割,其中所有物体都被正确分割,剩余的部分也被正确标注(Kirillov,He等2019;Kirillov,Girshick等2019)。COCO数据集现已扩展以包含全景分割任务,在ECCV 2020工作坊中可以找到一些最近的结果(Kirillov,Lin等2020)。
视频理解的研究,或更具体地说,人类活动识别,可以追溯到20世纪90年代;一些优秀的综述包括(Aggarwal和Cai 1999;Poppe 2010;Aggarwal和Ryoo 2011;Weinland、Ronfard和Boyer 2011)。在过去十年中,视频理解技术转向使用深度网络(Ji、Xu等2013;Karpathy、Toderici等
Al.2014;Simonyan和Zisserman2014a;Donahue、Hendricks等人2015;Tran、Bourdev等人2015;Feichtenhofer、Pinz和Zisserman2016;Carreira和Zisserman2017;Tran、Wang等人2019;Wu、Feichtenhofer等人2019;Feichtenhofer、Fan等人2019)。表6.3总结了一些广泛用于评估这些算法的数据集。
虽然将文字与图像关联的研究已经进行了很长时间(Duygulu,Barnard等,2002),但对用标题和完整句子描述图像的持续研究始于2010年代初(Farhadi,Hejrati等,2010;Kulkarni,Premraj等,2013)。过去十年间,这类系统的性能和能力迅速提升(Mogadala,Kalimuthu和Klakow,2021;Gan,Yu等,2020)。最早被广泛研究的子问题之一是图像描述(Donahue,Hendricks等,2015;Fang,Gupta等,2015;Karpathy和Fei-Fei,2015;Vinyals,Toshev等,2015;Xu,Ba等,2015;Devlin,Gupta等,2015),随后的系统开始使用注意力机制(Anderson,He等,2018;Lu,Yang等,2018)。最近,研究人员开发了用于视觉问答(Antol,Agrawal等,2015)和视觉常识推理(Zellers,Bisk等,2019)的系统。
CVPR 2020关于视觉字幕最新进展的教程(Zhou2020)总结了过去五年中二十多篇相关论文,包括使用Transformer进行字幕生成的论文。该教程还涵盖了视频描述和密集视频字幕(Aafaq,Mian等2019;Zhou,Kalantidis等2019)以及视觉-语言预训练(Sun,Myers等2019;Zhou,Palangi等2020;Li,Yin等2020)。此外,该教程还包括关于视觉问答和推理(Gan2020)、文本到图像合成(Cheng2020)以及视觉-语言预训练(Yu,Chen,和Li2020)的讲座。
例6.1:预训练识别网络。为图像分类、分割或其他任务如人脸识别或行人检测寻找一个预训练网络。
运行网络后,你能描述出网络最常见的错误类型吗?创建一个“混淆矩阵”,显示哪些类别被归类为其他类别。现在用网络处理你自己的数据,无论是来自网络搜索还是个人照片集。有令人惊讶的结果吗?
我自己最喜欢尝试的代码是Detectron2,31,我用它生成了图6.39所示的全视图分割结果。
31点击“Colab Notebook”链接athttps://github.com/facebookresearch/detectron2,然后编辑输入图像URL,尝试自己的。
例6.2:重新训练识别网络。在分析了预训练网络的性能之后,尝试在原始数据集上对其进行重新训练,但参数(层数、通道数、训练参数)进行了修改,或者使用了额外的例子。你能让网络表现得更符合你的期望吗?
许多在线教程,如上述提到的Detectron2协作笔记本,都附有如何从头开始在不同数据集上重新训练网络的说明。你能创建自己的数据集吗?例如,通过网络搜索并弄清楚如何标注示例?一种低投入(但不太准确)的方法是信任网络搜索的结果。Russakovsky、Deng等人(2015年)、Kovashka、Russakovsky等人(2016年)以及其他关于图像数据集的论文讨论了获取准确标签的挑战。
训练你的网络,尝试优化它的架构,并报告你所面临的挑战和你所发现的。
注:以下练习由Matt Deitke提出。
例6.3:图像扰动。下载ImageNet或Imagenette。32现在,通过在图像的左上角添加一个小方块来扰动每个图像,该方块的颜色对于每个标签都是唯一的,如下图所示:

使用任意图像分类模型,例如ResNet、EfficientNet或ViT,在扰动后的图像上从头开始训练模型。模型是否会过度拟合到正方形的颜色而忽略图像的其他部分?在训练和验证数据上评估模型时,尝试在不同标签之间对抗性地交换颜色。
例6.4:图像归一化。使用之前练习中下载的相同数据集,取一个ViT模型并移除所有中间层的归一化操作。你能否训练网络?利用Li、Xu等人(2018)的技术,有无中间层归一化操作时,损失景观图会呈现什么变化?
例6.5:语义分割。解释实例分割、语义分割和全景分割之间的区别。对于每种分割类型,是否可以进行后处理以获得其他类型的分割?
例6.6:类别编码。神经网络中的分类输入,如单词或对象,可以使用独热编码向量进行编码。然而,通常会将独热编码向量通过嵌入矩阵,然后输出结果传递给神经网络的损失函数。与使用独热编码相比,向量嵌入有哪些优势?
例6.7:目标检测。对于目标检测,DETR、Faster-RCNN和YOLOv4的参数数量如何比较?尝试在MS COCO上训练每个模型。哪一个训练速度最慢?每个模型在推理时评估单个图像需要多长时间?
例6.8:图像分类与描述。对于图像分类,列出使用分类标签和自然语言描述之间的至少两个显著差异。
例6.9:ImageNet Sketch。尝试使用几个预训练模型在ImageNet上进行评估,不进行任何微调,在ImageNet Sketch上进行评估(Wang,Ge et al.2019)。对于这些模型中的每一个,由于分布的变化,性能下降的程度有多大?
例6.10:自监督学习。为以下每种数据类型提供自监督学习预设任务的例子:静态图像、视频和视觉-语言。
例6.11:视频理解。对于许多视频理解任务,我们可能对跟踪一个物体在时间上的变化感兴趣。为什么这比为每一帧独立做出预测更受欢迎呢?假设推理速度不是问题。
例6.12:微调新头部。使用为对象分类训练的网络的主干,并用YOLO的一个变体对其进行对象检测微调。为什么可能希望冻结网络的早期层?
例6.13:电影理解。目前,大多数视频理解网络,如本章讨论的那些,往往只处理作为输入的短视频片段。为了在更长的序列上运行,例如整个电影,可能需要进行哪些修改?


















 4710
4710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









