







传统的医疗保健系统有大量的病人数据,包括生理信号、医疗记录、提供者注释和评论。开发数字健康应用程序所面临的最大挑战是分析大量可用数据,得出可操作的见解,以及开发可在嵌入式设备上运行的解决方案。
在开发这样的端到端解决方案时,从事生物医学数据集工作的工程师和数据科学家经常遇到挑战,因为他们必须手动集成应用程序代码,与必要的工具链集成以进行部署,在许多情况下,还必须重写代码以在目标硬件上运行应用程序。如果算法不能产生预期的结果,他们必须调试底层案例,这可能会很耗时。
这篇文章讨论了数据科学家和工程师如何使用 NVIDIA gpu 为生物医学应用开发基于人工智能的数字健康算法原型,并在嵌入式物联网和边缘人工智能平台(如 NVIDIA Jetson 开关 )上部署这些算法。您还可以使用 MathWorks GPU 编码器在 Jetson 上部署预测管道。
解决的目标是训练一个分类器来区分心律失常( ARR )、充血性心力衰竭( CHF )和正常窦性心律( NSR )。本教程使用从以下三个组或类获得的 ECG 数据:
- 心律失常患者
- 充血性心力衰竭患者
- 窦性心律正常的人
该示例使用 来自三个 PhysioNet 数据库的 162 个心电图记录 ,每个记录有 65536 个样本:
- MIT-BIH 心律失常数据库: 96 次记录
- BIDMC 充血性心力衰竭数据库: 30 个记录
- 正常窦性心律数据库: 36 次录音
要运行此示例,您需要以下资源:
- MATLAB
- 小波工具箱
- 讯号处理工具箱
- 并行计算工具箱
- GPU 编码器
- MATLAB 编码器
- NVIDIA GPU 的 GPU 编码器支持包
请求产品试用 或发送电子邮件至 medical@mathworks.com 。
开发基于人工智能的数字健康应用程序的总体工作流程
建立心电信号预测模型的方法很多。这篇文章的重点是探索一个简化的工作流程,它结合了信号处理方面的进展,并利用了在开发卷积神经网络( CNNs )和 ECG 信号分类的深度学习体系结构方面已经完成的大量工作。图 1 显示了整个工作流。
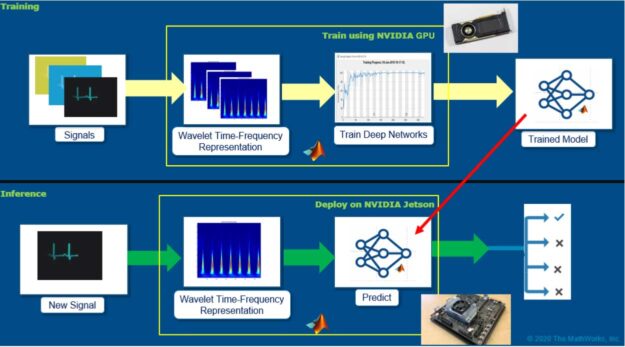
图 1 。基于人工智能的数字健康应用的总体工作流程。
这里的主要思想是从 ECG 信号生成时频表示,并将这些表示保存为图像。 ECG 的时频表示捕获了 spe CTR al 成分随时间的变化。这些图像可以用来训练卷积神经网络( CNNs )。 CNNs 可以从图像中的模式( ECG 信号的时频表示)中提取特征,并且可以建立一个模型来区分属于不同类别的 ECG 信号。
开发模型之后,就可以在嵌入式硬件(如 Jetson )上部署 pipeline : time-frequency 表示和经过训练的模型,以便使用 GPU 编码器对新信号执行推断。 GPU 编码器根据 MATLAB 算法自动生成优化的 CUDA 代码。
使用 NVIDIA Quadro RTX 6000 加速时频表示
下面是如何从 ECG 记录中生成时频表示。虽然 MATLAB 中有几种方法可以从信号中生成时频表示,但我们强烈建议使用连续小波变换( CWT ),因为它简单且能够从信号中生成清晰的时频表示。由此产生的时频表示也被称为 scalogram 。
CWT 是通过对信号进行加窗处理而得到的,小波经过时间缩放和移位。小波是振荡的,可以是复值的。对原型小波进行了尺度变换和移位运算。 CWT 中使用的缩放可收缩和拉伸原型小波:
- 缩小原型子波可以产生短时间、高频子波,这些子波能够很好地检测瞬态事件。
- 拉伸原型子波会产生长持续时间的低频子波,这些子波擅长于隔离长持续时间的低频事件。
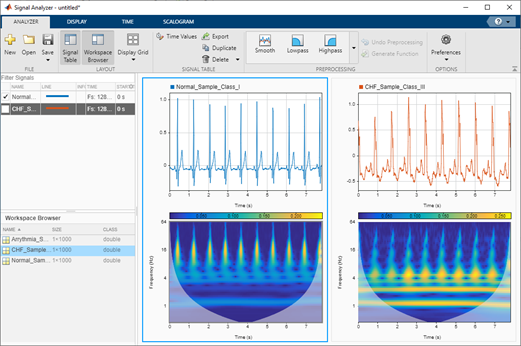
图 2 。正常窦性心律( NSR )和充血性心力衰竭( CHF )的标度图。
拥有这样清晰的时频表示可能很有用,因为深度网络或 cnn 擅长从这种表示中提取特征并建立预测模型。使用清晰的时频表示法的另一个好处是,它使您能够构建模型来捕捉细微的变化,这些变化反过来有助于区分许多信号类别,即使这些信号看起来相似。
为了加快比例图的生成过程,如果将输入变量转换为 gpuArray 类型,则可以在 gpu 上运行 MATLAB 函数。然后可以使用 gather 函数从 GPU 检索输出数据。为了加快尺度图的生成过程,使用函数 cwtfilterbank 创建一次小波滤波器组,然后使用 cwtfilterbank 的小波变换方法生成时频表示。
我们使用 NVIDIA Quadro RTX 6000 来计算标度图,并且能够实现约 6 . 5 倍的加速。使用的 CPU 是 Intel Xeon CPU E5-1650 v4 @ 3 . 60 GHz ,带有 64 GB RAM 。
有关更多信息,请参阅 cwt 和 cwtfilterbank 函数参考。
load('ECGData.mat'); % Data file downloaded from git
useGPU = true;
tic;
X = he
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









