










文章目录
人工智能的浪潮席卷而来,多模态模型已成为 AI 领域的核心驱动力。它们如同拥有多重感官的智能体,能够理解和生成文本、图像、音频、视频等多元信息,在各个领域展现出前所未有的潜力。然而,与模型能力的飞速提升形成鲜明对比的是,多模态模型评测体系的相对滞后。 如何科学、全面、高效地评测多模态模型的性能,成为了制约领域发展的关键挑战。

正是在这样的背景下,EvolvingLMMs-Lab 倾力打造并开源了 lmms-eval ,一个专为大规模多模态模型评测而生的革命性框架。 lmms-eval 不仅仅是一个工具,更是一套标准化的评测方案,旨在推动多模态 AI 走向成熟和繁荣。
项目地址: https://github.com/EvolvingLMMs-Lab/lmms-eval/tree/b1fbf55f4f11cc2c30aa628252723f35c1dc1d90
1. 为什么选择 lmms-eval? 解决多模态评测的核心痛点
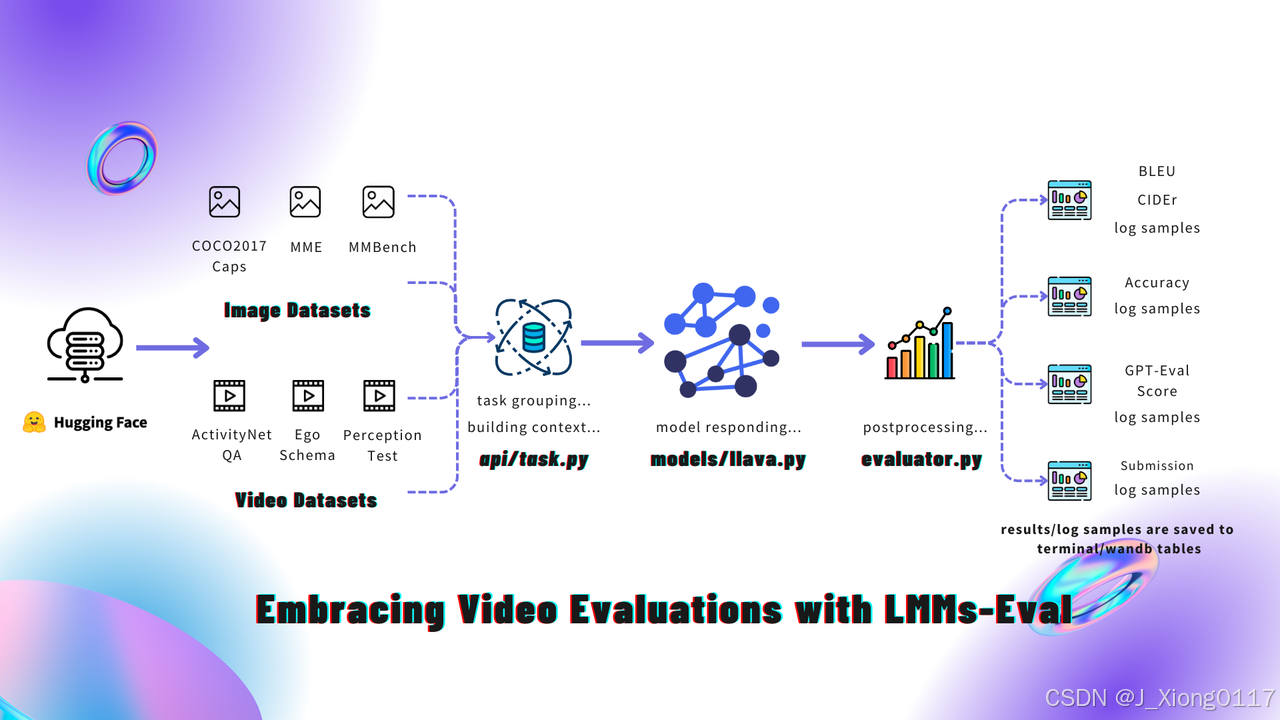
lmms-eval 的诞生并非偶然,它深刻洞察了当前多模态评测领域的痛点,并提供了针对性的解决方案:
-
碎片化的评测标准: 传统的多模态评测往往缺乏统一的标准和工具,不同研究团队使用不同的数据集、指标和方法,导致评测结果难以比较和复现。
lmms-eval致力于构建统一的评测平台,提供标准化的评测流程和指标,促进研究成果的交流和进步。 -
评测任务覆盖不足: 许多评测工具只关注单一模态或特定任务,无法全面评估多模态模型的综合能力。
lmms-eval的目标是覆盖尽可能广泛的多模态任务,从基础的图像描述、视觉问答,到复杂的视频理解、音频分析,甚至更前沿的多模态推理和生成任务,力求全方位刻画模型的性能轮廓。 -
模型集成和扩展困难: 现有的评测框架可能模型集成流程复杂,难以支持快速发展的新型多模态模型。
lmms-eval采用模块化和可扩展的设计,使得用户可以轻松集成自定义模型、数据集和评测指标,灵活应对快速变化的模型 landscape。 -
易用性与效率挑战: 复杂的评测工具学习成本高,运行效率低,阻碍了研究人员的快速迭代。
lmms-eval注重易用性和效率,提供简洁的命令行接口、清晰的配置文件和优化的代码实现,力求降低使用门槛,提升评测效率。
2. lmms-eval 的核心特性:强大功能,全面赋能评测
lmms-eval 之所以能够成为多模态评测的革新利器,源于其卓越的设计和强大的功能:
-
全面的多模态任务支持 :
lmms-eval当前版本已经支持极其丰富的多模态任务,涵盖图像、文本、视频、音频等多种模态,以及各种主流评测任务类型。 以下是lmms-eval支持的详细任务列表 (参考 current_tasks.md):[图像-文本任务]
-
图像分类 (Image Classification):
image_classificationimagenetcifar10cifar100mnistfashion_mnistsun397places365daimlerpedclassgtsrbvoc2007voc2012ade20kcityscapesnyu_depth_v2scannetsun_rgbdpascal_contextlvisobject365
-
图像描述生成 (Image Captioning):
image_captioningcoco_captionflickr30k_captionimage_net_caption
-
视觉问答 (Visual Question Answering, VQA):
vqavqav2okvqavizwiz_vqatextvqasciencevqaai2ddocvqachartqainfographicvqamultimodalqa
-
视觉蕴含 (Visual Entailment):
visual_entailmentsnli_ve
-
视觉常识推理 (Visual Commonsense Reasoning, VCR):
visual_commonsense_reasoningvcr
-
视觉定位 (Visual Grounding) / 指代表达理解 (Referring Expression Comprehension):
visual_groundingrefcocorefcoco_grefcoco_plus
-
图像文本检索 (Image-Text Retrieval):
image_retrievalcoco_retrievalflickr30k_retrievalunsplashpexelsiapr_tc12esicrsicdreclip
-
文本到图像检索 (Text-to-Image Retrieval):
text_retrievalcoco_retrievalflickr30k_retrievalunsplashpexelsiapr_tc12esicrsicdreclip
-
零样本图像分类 (Zero-shot Image Classification):
zero_shot_image_classificationimagenet_zeroshot
-
视觉属性和关系预测 (Visual Attribute and Relation Prediction):
visual_attribute_predictionvisual_genome_attributesvisual_genome_relationsvisual_genome_objects
-
视觉推理 (Visual Reasoning):
visual_reasoningnlvr2clevrshapesreasoning_shapessqoopgqaclevr_hans
-
多模态基准评测 (Multimodal Benchmarks):
multimodal_benchmarkm3examscienceqa_imgmmbenchmmbench_cnccbenchhallusion_benchseed_benchllava_benchmmepopemvbench
-
鲁棒性评测 (Robustness Evaluation):
robustnessvqav2_cpvqa_hatvqav2_cfvqav2_adgqa_oodgqa_cpgqa_adgqa_cfgqa_gnlgqa_nlgqa_vggqa_vdgqa_vsgqa_vrgqa_vcgqa_vagqa_vfgqa_vhgqa_vlgqa_vngqa_vvgqa_vp
-
对抗性评测 (Adversarial Evaluation):
adversarialpope
-
幻觉评测 (Hallucination Evaluation):
hallucinationhallusion_bench
-
安全性和偏见评测 (Safety and Bias Evaluation):
safety_biashateful_memesmugreddit_disinformationtwitter_disinformationfake_news_netpolitifactbuzzfeedcovid_factmedifact
[视频-文本任务]
-
视频描述生成 (Video Captioning):
video_captioningmsr_vtt_captionmsvd_captionactivity_net_caption
-
视频问答 (Video Question Answering, VQA):
video_vqamsr_vtt_qamsvd_qa
-
视频文本检索 (Video-Text Retrieval):
video_retrievalmsr_vtt_retrievalmsvd_retrieval
-
动作识别 (Action Recognition):
action_recognitionkinetics400something_something_v2
-
时间动作定位 (Temporal Action Localization):
temporal_action_localizationthumos14activitynet_entities
[音频-文本任务]
-
音频分类 (Audio Classification):
audio_classificationaudiosetesc50
-
语音识别 (Automatic Speech Recognition, ASR):
asrlibrispeech_asrcommon_voice_asr
-
音频事件检测 (Audio Event Detection):
audio_event_detectiondcase2017_task4
-
音频标注 (Audio Tagging):
audio_taggingmagnatagatunefreesound_dataset
-
-
强大的模型支持 (持续扩展):
lmms-eval框架设计灵活,支持集成各种多模态模型。 当前版本已经原生支持或易于集成以下模型 (参考lmms_eval/models目录):-
Vision-Language Models:
- CLIP (Contrastive Language-Image Pre-training): 广泛使用的图像-文本预训练模型,
lmms-eval支持多种 CLIP 变体。 - BLIP (Bootstrapping Language-Image Pre-training): 包括 BLIP 和 BLIP-2,在视觉问答和图像描述等任务上表现出色。
- FLAN (Finetuned Language Net): 例如 FLAN-T5, FLAN-UL2 等,通过指令微调提升了模型的泛化能力。
- LLaMA (Large Language Model Meta AI): 支持 LLaMA 和 LLaMA-Adapter 等,可以与视觉模块结合进行多模态任务。
- MiniGPT-4: 基于视觉编码器和大型语言模型的组合,用于视觉理解和生成任务。
- InstructBLIP: 在 BLIP-2 的基础上进行指令微调,更擅长处理指令相关的多模态任务。
- Otter: 一种基于 Transformer 的多模态模型架构。
- X-LLM: 跨模态大型语言模型。
- Vision Transformer (ViT): 作为视觉编码器,可以与其他模块结合构建多模态模型。
- ResNet: 经典的卷积神经网络,常用于图像特征提取。
- CLIP (Contrastive Language-Image Pre-training): 广泛使用的图像-文本预训练模型,
-
Audio-Language Models (初步支持,未来可期):
- 框架设计上支持音频模态,未来有望扩展对更多音频-语言模型的支持。
-
General Language Models (用于文本处理部分):
- GPT 系列: 例如 GPT-3, GPT-2 等,用于文本生成和理解。
- T5 (Text-to-Text Transfer Transformer): 用于各种文本到文本的任务。
- BERT (Bidirectional Encoder Representations from Transformers): 用于文本特征提取和理解。
- RoBERTa (A Robustly Optimized BERT Approach): BERT 的改进版本,性能更优。
[模型集成方式]:
lmms-eval采用模型适配器 (Adapter)机制,用户只需编写简单的适配器代码,即可将自定义模型无缝集成到评测框架中。 框架已经预置了常用模型的适配器,用户可以参考示例进行快速扩展。 -
-
灵活的配置系统:YAML 配置文件驱动
lmms-eval采用YAML 配置文件来管理评测任务的各个方面,包括模型选择、数据集指定、评测指标设定、运行参数调整等。 用户只需修改配置文件,即可灵活定制评测流程,无需修改代码。 配置文件结构清晰,易于理解和维护。 -
丰富的评测指标:满足多样化评估需求
lmms-eval支持各种常用的多模态评测指标,例如:- 图像描述生成: BLEU, METEOR, ROUGE_L, CIDEr, SPICE 等。
- 视觉问答: Accuracy, VQA Accuracy, Answer Type Accuracy 等。
- 图像文本检索: Recall@K, mAP, NDCG 等。
- 视频描述生成: 与图像描述生成类似的指标。
- 音频分类: Accuracy, F1-score, AUC 等。
- 语音识别: Word Error Rate (WER), Character Error Rate (CER) 等。
同时,
lmms-eval支持自定义评测指标,用户可以根据特定任务的需求,添加和使用自定义的评估指标。 -
简洁易用的命令行接口 (CLI):
lmms-eval提供简洁直观的命令行接口,用户只需一条命令即可启动评测任务。 例如:lmms-eval --config configs/your_config.yamlCLI 提供了丰富的参数选项,方便用户进行各种配置和控制。
-
高度可扩展性:模块化设计,无限可能
lmms-eval采用模块化设计,各个组件 (模型、数据集、任务、指标等) 相互独立,易于扩展和替换。 用户可以轻松添加新的模型、数据集、任务和指标,构建定制化的评测平台。 框架的扩展性为未来支持更多模态、更复杂任务和更先进模型奠定了坚实基础。 -
促进评测标准化和可复现性:
lmms-eval的出现,有助于推动多模态模型评测走向标准化和可复现。 通过使用统一的框架、基准数据集和评测指标,研究人员可以更方便地比较不同模型的性能,并确保研究结果的可信度和可复现性。
3. 快速上手 lmms-eval:几步开启多模态评测之旅
- 安装环境: 参考项目
README.md中的 “Installation” 部分,安装lmms-eval及其依赖项。 通常需要 Python 环境 (建议使用 conda 或 virtualenv 管理环境),以及 PyTorch, Transformers 等必要的库。
git clone https://github.com/EvolvingLMMs-Lab/lmms-eval
cd lmms-eval
pip install -e .
-
准备配置文件: 在
configs/目录下选择或创建配置文件。 根据你的评测需求,修改配置文件中的模型、数据集、任务、指标等参数。 可以参考configs/目录下的示例配置文件。 -
运行评测命令: 在命令行中执行
lmms-eval命令,并指定配置文件路径:
Qwen2-VL-7B-Instruct模型评测
CUDA_VISIBLE_DEVICES=0 python3 -m lmms_eval \
--model=qwen2_vl \
--model_args=/home2/jianxiong/models/vlm/Qwen2-VL-7B-Instruct,device_map=auto \
--tasks=mmmu,mathvista_testmini,mmstar,mme,chartqa,ocrbench,textvqa,mmbench \
--batch_size=1 \
--log_samples \
--log_samples_suffix=qwen2_vl \
--output_path="./logs/" \
--verbosity=DEBUG
QVQ-72B-Preview模型评测
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python3 -m lmms_eval \
--model=qwen2_vl \
--model_args=pretrained=/mnt/data/jinchenyu/llms/QVQ-72B-Preview,device_map=auto \
--tasks=mmmu,mathvista_testmini,mmstar,mme,chartqa,ocrbench,textvqa,mmbench \
--batch_size=1 \
--log_samples \
--log_samples_suffix=QVQ \
--output_path="./logs/" \
--verbosity=DEBUG
- 查看评测结果: 评测完成后,结果将输出到终端和日志文件。 分析评测结果,评估模型性能。
4. lmms-eval 的应用场景:广泛覆盖,价值无限
lmms-eval 适用于各种需要进行多模态模型评测的场景:
- 学术研究: 研究人员可以使用
lmms-eval评估新提出的多模态模型,进行消融实验和性能对比,推动多模态 AI 理论和算法的进步。 - 工业应用: 企业开发者可以使用
lmms-eval选择和优化多模态模型,应用于智能客服、图像搜索、视频分析、语音助手等各种实际应用场景。 - 教育学习: 学生和爱好者可以通过
lmms-eval学习多模态模型评测的原理和方法,提升实践能力。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









