










一、引言
在现代工业生产中,产品质量是企业生存与发展的命脉,尤其是在制造业领域,缺陷检测直接影响产品的可靠性和企业的市场声誉。传统的缺陷检测方法,如人工目视检查或基于固定规则的机器视觉技术,虽然在特定场景下起到了一定作用,但普遍存在效率低下、适应性不足、误检率高等问题。随着人工智能技术的迅猛发展,特别是 深度学习 在图像处理领域的突破性进展,自动化缺陷检测逐渐成为工业质检的主流趋势。深度学习通过 卷积神经网络(CNN) 等模型,能够自动提取图像特征,显著提升检测精度和鲁棒性。然而,工业质检场景中一个突出的挑战是 缺陷样本的稀缺性。在高质量的生产线上,缺陷发生率极低,获取足够的缺陷样本用于模型训练变得异常困难。此外,缺陷形态复杂多变,标注成本高昂,进一步加剧了数据稀缺的问题。这种“小样本”缺陷检测的困境,限制了传统深度学习模型在工业场景中的应用效果。
本文将深入探讨小样本缺陷检测的现状、挑战及解决方案,重点介绍基于深度学习的创新技术,包括 迁移学习、数据增强、生成对抗网络(GAN)、自监督学习 和 少样本学习 等。我们将结合具体的工业案例,详细分析这些方案的实施步骤、技术细节及其实际效果,并对未来的发展趋势进行展望。通过本文,读者将全面了解如何在数据受限的条件下实现高效、精准的缺陷检测,从而为智能制造提供强有力的技术支持。

二、小样本缺陷检测的挑战
小样本缺陷检测的复杂性源于工业场景的特殊性,以下是对其主要挑战的详细分析:
2.1 数据稀缺性
在高精度制造领域,产品质量通常受到严格控制,缺陷发生率极低。以汽车零部件生产为例,合格率可能高达 99.9%,这意味着每 1 0 4 10^4 104 个产品中仅可能出现 1 个缺陷。在这种情况下,收集足够数量的缺陷样本几乎是不可能的任务。此外,对于新产品或新工艺上线时,由于缺乏历史数据,数据稀缺问题更加突出。例如,在半导体芯片制造中,新型芯片的生产初期往往只有少量缺陷样本,这对依赖大数据的深度学习模型提出了严峻挑战。
2.2 标注难度
缺陷样本的标注 不仅需要专业知识和丰富经验,还常常依赖昂贵的检测设备。例如,光伏面板的隐裂缺陷可能仅在特定光线下可见,需要借助红外成像设备才能准确识别;印刷电路板(PCB)上的微小焊点缺陷则可能需要高倍显微镜和经验丰富的质检员共同确认。标注过程耗时长、成本高,且由于人为因素可能导致标注质量不一致。例如,一个初级质检员可能将正常磨损误标为缺陷,而专家则可能忽略微小但关键的异常。这种标注的不一致性使得高质量的有标签缺陷数据极为有限。
2.3 缺陷多样性
工业缺陷的特征千变万化,形态、尺寸、位置 等方面的差异给检测带来了巨大困难。例如:
- 金属表面缺陷:划痕可能呈现不同的长度、深度和方向,锈斑可能大小不一且颜色各异。
- 纺织品缺陷:污渍可能具有多种颜色和形状,断线缺陷则可能细微到难以察觉。
- 电子元件缺陷:焊点可能出现虚焊、漏焊或过焊,每种形态的特征差异显著。
这种多样性要求检测模型具备强大的特征提取能力和泛化能力。然而,在小样本条件下,模型难以充分学习缺陷的全部特征,导致在面对未知形态的缺陷时表现不佳。例如,一个在直线划痕上训练的模型,可能无法有效识别曲线状或点状缺陷。
2.4 模型泛化性
在小样本场景下训练的模型容易出现 过拟合 问题,即在训练集上表现优异,但在未见过的测试集上泛化能力不足。这是因为模型过度依赖有限样本的特定特征,而未能掌握缺陷的本质规律。例如,一个基于 10 张划痕样本训练的模型,可能只学会了特定划痕的纹理特征,而无法适应其他形态的划痕。此外,工业生产中的缺陷类型可能随工艺调整或时间变化而改变,例如设备老化可能导致新的缺陷模式,模型需要快速适应这些新缺陷,而小样本训练往往难以满足这一动态需求。

三、传统缺陷检测方法及其局限
3.1 基于规则的机器视觉
传统缺陷检测主要依赖机器视觉技术,通过 预设规则或模板 识别缺陷。常见方法包括:
- 模板匹配:将待检图像与标准模板进行像素级对比,找出差异区域。例如,在PCB检测中,用标准板图像与待检图像对比,识别焊点缺失。
- 阈值分割:根据像素灰度值将图像分为背景和缺陷区域。例如,在金属表面检测中,设定灰度阈值分离划痕和正常区域。
- 边缘检测:利用 Sobel、Canny 等算子提取缺陷边缘。例如,在纺织品检测中,检测断线的边缘特征。
这些方法在早期的工业质检中得到了广泛应用,尤其适用于规则性强、背景简单的场景,如流水线上的标准化零件检测。
3.2 局限性
尽管基于规则的机器视觉技术在特定场景下有效,但其局限性显著:
- 适应性差:对于复杂背景或非规则缺陷,预设规则难以覆盖所有情况。例如,在复杂纹理的木材表面检测中,模板匹配可能因背景干扰而失效。
- 鲁棒性不足:光照变化、噪声干扰等外部因素容易影响检测精度。例如,在室外环境下检测光伏面板时,光线变化可能导致误检。
- 灵活性低:每种缺陷类型需要单独设计规则,难以快速适应新缺陷或新产品。例如,当生产线更换零件时,需重新编写检测规则,增加了开发成本。
3.3 深度学习的兴起
近年来,深度学习技术 在图像识别领域的成功推动了其在缺陷检测中的应用。卷积神经网络(CNN)通过多层卷积和池化操作,能够自动提取图像的高级特征,显著提升了检测精度和鲁棒性。例如,ResNet 和 YOLO 模型在目标检测任务中的表现远超传统方法。然而,深度学习模型通常需要大量标注数据进行监督训练,这与工业质检中的小样本场景形成矛盾。因此,如何在数据稀缺条件下优化深度学习模型,成为研究的重点方向。
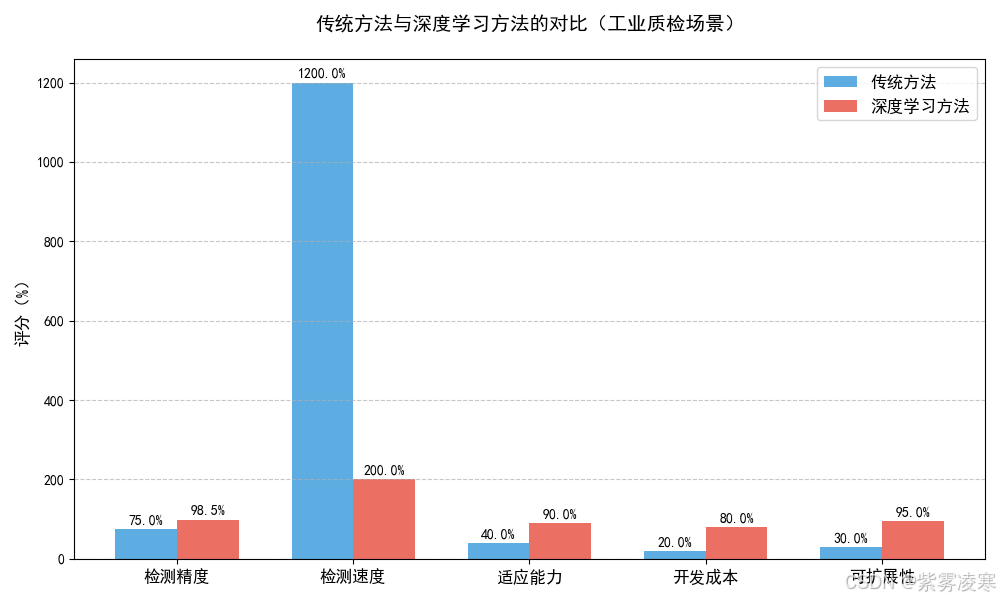
四、小样本缺陷检测的技术方案
针对小样本缺陷检测的挑战,研究人员提出了多种基于深度学习的解决方案,以下是主要技术及其应用的详细介绍:
4.1 迁移学习(Transfer Learning)
4.1.1 原理
迁移学习 利用在大规模通用数据集(如 ImageNet)上预训练的模型,将其知识迁移到目标任务中。在小样本缺陷检测中,通常选择 ResNet、VGG 等预训练模型作为特征提取器,然后在少量缺陷样本上进行微调。这种方法借助预训练模型的通用特征提取能力,减少对目标数据的需求。例如,ImageNet 数据集包含了数百万张图像,覆盖了丰富的纹理和形状特征,这些先验知识可以有效应用于工业缺陷检测。
4.1.2 应用步骤
在工业质检中,迁移学习的实施流程如下:
- 选择预训练模型:根据任务需求选择合适的模型架构,如 ResNet50(50 层残差网络)或 VGG16。
- 冻结部分层:冻结底层卷积层,保留通用特征提取能力,例如边缘、纹理等低级特征。
- 微调顶层:对顶层(如全连接层或分类层)进行训练,使其适应具体的缺陷检测任务。
- 调整学习率:采用较小的学习率(如 1 0 − 3 10^{-3} 10−3)进行微调,避免破坏预训练特征。
4.1.3 优势与局限
- 优势:
- 显著减少对标注数据的需求,利用预训练模型的先验知识。
- 加速训练过程,缩短开发周期。例如,一个从零开始训练的模型可能需要数周,而迁移学习只需数小时。
- 局限:
- 当目标缺陷与预训练数据分布差异较大时,迁移效果可能不佳。例如,ImageNet 以自然图像为主,而工业缺陷图像(如 PCB 焊点)与之差异显著。
- 存在负迁移风险,即不恰当的迁移可能降低性能。例如,若预训练特征与目标任务无关,可能引入噪声。
4.2 数据增强(Data Augmentation)
4.2.1 传统增强
数据增强 通过对现有样本进行变换,人工扩充训练集。传统方法包括:
- 几何变换:旋转、翻转、缩放、裁剪等。例如,将一张划痕图像旋转 90°,模拟不同角度的缺陷。
- 颜色调整:改变亮度、对比度、饱和度。例如,调整图像亮度以模拟不同光照条件下的缺陷。
- 噪声添加:引入高斯噪声、椒盐噪声等。例如,在金属表面图像中添加噪声,增强模型对干扰的鲁棒性。
这些方法能够模拟缺陷在实际生产中的多样性,提升模型的泛化能力。
4.2.2 高级增强
近年来,基于生成模型的高级增强技术逐渐兴起,尤其是 生成对抗网络(GAN)。GAN 能够生成逼真的缺陷样本。例如,CycleGAN 可以通过无监督学习将正常样本转化为缺陷样本。例如,将正常 PCB 图像转化为带有焊点缺陷的图像,显著扩充训练集。此外,变分自编码器(VAE)也可以用于生成多样化的缺陷样本,尽管其生成质量通常不如 GAN。
4.2.3 实践效果
在某 PCB 板检测项目中,工程师将原始 100 张样本通过传统增强(旋转、翻转)和 GAN 增强扩展至 1000 张。训练后的模型 F1 分数从 0.75 提升至 0.90,显著提高了对微小焊点缺陷的识别能力。具体来说,传统增强增加了样本的几何多样性,而 GAN 生成的样本则丰富了缺陷的纹理特征,二者结合显著提升了模型性能。
图片建议:插入一张数据增强效果图,展示原始图像、传统增强图像和 GAN 生成图像的对比。
4.3 生成对抗网络(GAN)
4.3.1 基础原理
生成对抗网络(GAN) 由生成器(Generator)和判别器(Discriminator)组成,通过对抗训练生成高质量的合成数据。生成器负责生成逼真图像,判别器区分真实图像与生成图像,两者博弈直至生成器生成的图像难以分辨。其损失函数可表示为:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
其中, G G G 为生成器, D D D 为判别器, x x x 为真实样本, z z z 为随机噪声。
4.3.2 应用流程
在小样本缺陷检测中,GAN 常用于生成稀缺的缺陷样本:
- 训练 GAN:利用少量真实缺陷样本和正常样本训练 GAN。例如,使用 10 张划痕图像和 100 张正常图像训练生成器。
- 生成样本:使用训练好的生成器生成大量缺陷图像。例如,生成 500 张带有不同划痕特征的图像。
- 混合训练:将生成样本与真实样本混合,用于训练缺陷检测模型。例如,将生成的 500 张图像与原始 10 张图像结合,训练 YOLOv5 模型。
4.3.3 案例分析
在光伏面板隐裂检测中,某企业利用 条件 GAN(Conditional GAN) 生成带有隐裂特征的合成图像。条件 GAN 通过引入条件变量(如缺陷类型标签),控制生成图像的特征。合成样本与真实样本共同训练 YOLOv5 模型后,召回率从 85% 提升至 95%,误报率降低至 3%。具体来说,GAN 生成的隐裂图像在纹理和分布上与真实缺陷高度相似,有效弥补了样本不足的短板。
4.4 自监督学习(Self-Supervised Learning)
延伸阅读:
4.4.1 原理
自监督学习 通过设计预设任务(pretext tasks)从无标签数据中提取特征。常见的任务包括:
- 图像修复:随机遮挡图像部分,预测被遮挡内容。例如,遮挡金属表面的一部分,预测其纹理。
- 旋转预测:预测图像旋转角度。例如,将图像旋转 90°,训练模型识别旋转角度。
- 对比学习:学习图像间的相似性和差异性。例如,通过 SimCLR 框架,使同一图像的不同增强版本在特征空间中靠近。
这些任务帮助模型学习图像的语义和结构特征,而无需依赖标注数据。
4.4.2 应用流程
在工业质检中,自监督学习常用于预训练:
- 预训练:利用大量无标签正常样本进行自监督学习。例如,使用 1000 张正常金属表面图像进行图像修复任务。
- 微调:在少量有标签缺陷样本上微调模型。例如,用 10 张划痕样本微调预训练模型。
这种方法充分利用工业场景中丰富的正常样本,减少对标注缺陷样本的依赖。
4.4.3 优势与案例
- 优势:
- 充分利用无标签数据,降低标注成本。
- 学习到的特征更具泛化性,提升模型在小样本场景下的性能。
- 案例:在某金属表面检测任务中,使用 SimCLR 框架进行自监督预训练,仅用 10 张缺陷样本微调后,模型检测精度达 85%,远超直接监督训练的 60%。具体来说,自监督学习使模型学会了金属表面的通用纹理特征,从而在微调时更容易捕捉缺陷的异常特征。
4.5 少样本学习(Few-Shot Learning)
4.5.1 概念
少样本学习 通过“学习如何学习”(元学习,Meta-Learning),使模型在少量样本下快速适应新任务。其核心是训练模型在多个任务上学习,获得快速适应的能力。例如,通过在不同缺陷类型(如划痕、污渍)上训练,模型学会如何从少量样本中提取关键特征。
4.5.2 方法
常见方法包括:
- 原型网络(Prototypical Networks):为每个类别学习一个原型表示,新样本通过与原型的距离分类。例如,为划痕类学习一个特征向量,新图像根据欧氏距离判断是否为划痕。
- 关系网络(Relation Networks):学习样本间的关系,判断是否属于同一类别。例如,比较两张图像的特征相似度,判断是否同属缺陷类。
4.5.3 应用场景
在工业质检中,少样本学习适用于缺陷类型多变且样本稀少的场景。例如,在电子元件检测中,模型通过 5-10 张样本快速学习新缺陷类型(如虚焊),准确率达 88%。具体来说,原型网络在训练阶段学习了多种缺陷的原型表示,使其在测试时能快速适应新缺陷。
五、工业应用案例分析
5.1 案例一:汽车零部件表面缺陷检测
5.1.1 背景
某汽车零部件企业推出新款零件,需检测表面划痕等缺陷。由于新产品上线,缺陷样本仅有 30 张,传统方法(如模板匹配)检测精度仅为 70%,无法满足生产需求。
5.1.2 方案
采用 迁移学习结合数据增强:
- 迁移学习:选择 ResNet50 预训练模型,冻结前几层卷积层,微调后几层和全连接层。
- 数据增强:对 30 张样本进行旋转、翻转、亮度调整,生成 300 张训练样本。
- 训练:使用 Adam 优化器,学习率设为 1 0 − 3 10^{-3} 10−3,训练 10 个 epoch。
5.1.3 结果
模型检测精度达 92%,漏检率低于 5%,远超传统方法的 70%。具体来说,迁移学习利用了 ResNet50 在 ImageNet 上学习的边缘和纹理特征,而数据增强则丰富了划痕的多样性,使模型更具鲁棒性。

5.2 案例二:光伏面板隐裂检测
5.2.1 背景
光伏面板隐裂难以识别,标注样本不足 100 张,企业要求高精度检测以确保产品质量。
5.2.2 方案
结合 GAN 和自监督学习:
- GAN 生成:训练条件 GAN 生成隐裂图像,扩充样本至 500 张。
- 自监督预训练:利用 1000 张正常样本进行图像修复任务,预训练特征提取器。
- 微调:在合成和真实样本上微调 YOLOv5 模型。
5.2.3 结果
召回率提升至 96%,误报率降至 3%,显著提高质检效率。GAN 生成的隐裂图像在细节上逼真,而自监督学习则增强了模型对正常背景的理解,使其更专注于异常检测。

六、未来发展趋势与展望
6.1 多模态融合
未来缺陷检测将结合视觉、红外、超声等多源数据,提升准确性和鲁棒性。例如,在复合材料检测中,融合视觉和超声数据可更全面评估缺陷。
6.2 自动化标注
通过弱监督或半监督学习,减少人工标注依赖,如利用正常样本训练异常检测模型。
6.3 边缘计算
将模型部署到边缘设备,实现实时质检,提升响应速度和安全性。
七、结论
小样本缺陷检测 是工业质检的关键难题,也是人工智能在制造业落地的典型场景。通过迁移学习、数据增强、GAN、自监督学习、少样本学习等技术,我们能够在数据稀缺条件下实现高效、精准的缺陷检测。这些方案提升了质检自动化水平,降低了企业成本。
延伸阅读



















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











