










目录
2.5 scale和zero也不是数据预处理的--mean和--scale
2.8 权重的范围需不需要计算图片,权重和激活的scale zero point是不是一样的
2.8.1 权重的量化参数(scale 和 zero point)
2.8.2 激活的量化参数(scale 和 zero point)
1 引言
这几个概念有的平时就用,比如模型量化,有的只是听说过,这次有点时间,我整理下这个概念,然后写一篇博客笔记。
2 模型量化
2.1 什么是模型量化
模型量化(Model Quantization)是指将深度学习模型中使用的浮点数参数和计算,转换为较低位宽的表示(比如从32位浮点数转为8位整数),以减小模型大小、减少内存占用和加速推理计算的技术。
通俗点说,就是把模型里的参数和计算用“更小、更省资源”的数字形式表示,从而让模型运行更快,占用更少资源。
2.2 模型量化具体采用什么方法
- 动态量化(Dynamic Quantization):推理过程中动态把权重和激活转成低精度,通常只对权重量化为低精度,激活保持浮点。简单且快速,但量化效果有限。
- 静态量化(Static Quantization):静态量化在推理前先用一组“校准数据”(即量化校准图片)统计激活的分布范围,得到合适的缩放比例(scale)和零点(zero point),然后在推理时直接使用低精度整数运算。
- 量化感知训练:在训练阶段模拟量化误差,让模型适应低精度计算,效果更好。
- 混合精度量化:不同层或不同部分使用不同位宽量化,关键部分保留较高精度,非关键部分量化为更低位宽。
- 二值化/三值化:极端量化,将参数压缩为二值或三值,但训练难度较大,多用于特殊场景。
2.3 模型量化具体做了什么
量化过程核心就是把浮点数映射到整数,主要步骤如下:
1. 确定量化参数
对每层权重和激活,找到它们的范围(最小值和最大值),计算对应的缩放因子(scale)和零点(zero point),这两个参数用于把浮点数映射到整数区间。
2. 浮点数映射为整数
用下面公式: 其中,f是浮点数,q是量化后的整数。
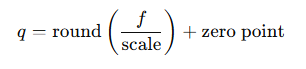
3. 存储量化参数和量化权重
权重和激活都用整数存储,同时保存scale和zero point,推理时恢复对应数值。
4. 修改推理计算流程
用整数计算替代浮点计算,减少硬件资源消耗,同时结合scale和zero point对结果进行反量化或保持整数运算。
5. 校准(Calibration)
用代表性的输入数据(校准图片)统计激活范围,确定scale和zero point的合理值。
总结来说,模型量化的目标就是用更低位宽的整数表示模型的参数和计算,以减少模型大小和推理延迟,适合部署在资源有限的设备上。量化过程就是找到映射关系,把浮点数“压缩”到整数区间。
2.4 scale和zero point不是方差和均值
2.4.1 scale(缩放因子)
-
作用:用来把浮点数的实际取值范围“压缩”到整数范围。
-
举个例子:如果你的浮点数据范围是 [−1.0,1.0][-1.0, 1.0][−1.0,1.0],但你用的是8位无符号整数 [0,255][0, 255][0,255],scale 就是一个把这两个区间联系起来的比例因子。
-
计算方式一般是:

2.4.2 zero point(零点)
• 作用:用于调整映射,使浮点的零值能准确映射到整数范围里的某个整数,保证“0”的位置对齐。
• 这是因为整数区间通常是从0开始(无符号8位整数是0-255),而浮点数区间可能是负数到正数。
• 计算方式一般是:
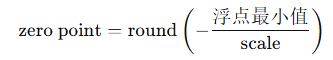
• zero point保证了浮点的“0”对应量化后整数的某个点,避免了偏移误差。
2.5 scale和zero也不是数据预处理的--mean和--scale
model_transform.py \
--model_name structure \
--model_def ../vehicle_structure_yolov8s-cls.onnx \
--input_shapes [[1,3,224,224]] \
--mean 0.0,0.0,0.0 \
--scale 1,1,1 \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names output0 \
--test_input ../calib/00c4cb4ded2d4ca8ad7a9b642e84e970000830-vehicle.jpg \
--test_result structure_top_outputs.npz \
--mlir structure.mlir上面是算能的模型转换命令,这里面有个mean和scale,这里的参数是数据预处理的参数,不是量化参数。
- --mean:表示对输入图像每个通道减去的均值,用来做数据归一化(mean subtraction)。例如 0.0,0.0,0.0 就是没减什么。
- --scale:表示对输入图像每个通道做的缩放因子(乘法因子),一般用来把像素值归一化到某个范围,比如把 [0,255] 缩放到 [0,1]。
- 这两个参数是深度学习模型训练时,输入数据归一化的一部分,目的是保证输入图像的像素值分布和训练时一致。
 2.6 前面提到的激活是什么意思
2.6 前面提到的激活是什么意思
量化不仅包括参数权重,也可能包括激活(中间计算结果)的量化。
激活值(Activation)指的是神经网络中各层经过计算后输出的中间数据,比如卷积层或全连接层的输出结果。它是输入层和输出层之间的“中间状态”,会被传递到下一层继续计算,比如,卷积层卷积完后的feature map,就是激活。
2.7 scale和zero point 是怎么得到的
前面的步骤一种说,这个scale和zerp point是计算出来,然后步骤五又说用校准图片进行统计,那么到底是怎么做的,是先直接计算出来一个值,然后用校准图片再去修正,还是说就是先用校准图片统计出来激活的范围然后从而能够计算出来scale和zero point的值,
答案是:先用校准图片统计激活(或权重)的最小值和最大值范围,再根据这个范围计算 scale 和 zero point。
具体流程:
收集校准数据(比如几百张代表性的校准图片),用这些数据做一次“前向推理”(或模拟推理),采集每一层激活的实际数值分布范围(最小值和最大值)。
用这些统计的最小值和最大值计算 scale 和 zero point,公式如下:
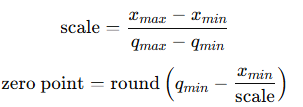
这里的 xmin,xmaxx_{min}, x_{max}xmin,xmax 是激活/权重的浮点最小最大值,qmin,qmaxq_{min}, q_{max}qmin,qmax 是整数量化区间(例如0到255)。
权重参数的范围是固定的,可以直接用权重本身统计;激活值因为会随输入变化,所以必须用校准图片统计。
所以, 不存在“先直接计算一个值,再用校准数据修正”的过程,而是用校准数据统计范围,直接计算出scale和zero point。
2.8 权重的范围需不需要计算图片,权重和激活的scale zero point是不是一样的
2.8.1 权重的量化参数(scale 和 zero point)
• 权重是固定参数,它们是模型训练后确定的值,不依赖输入数据。
• 所以权重的范围(最小值和最大值)可以直接从权重本身统计得出,不需要校准图片。
• 也就是说,权重量化的 scale 和 zero point 是固定不变的,由权重分布决定。
2.8.2 激活的量化参数(scale 和 zero point)
- 激活是每次推理时产生的中间数据,它的分布会随着输入数据变化。
- •因此激活的范围不固定,需要用代表性的校准图片来统计激活的最大最小值。
- •这样才能得到合理的激活量化参数 scale 和 zero point。
2.8.3 权重和激活用不同的量化参数
• 权重和激活必须分别计算和使用自己的 scale 和 zero point,不能共用。
• 因为它们的数据分布和动态范围不同,强行用同一套参数会导致量化误差大、模型性能下降。
• 典型流程是:
• 权重参数预先固定量化参数(只算一次)。
• 激活参数通过校准数据动态统计,得到适合输入数据分布的量化参数。
3 校准
校准图片最主要的作用就是,模型会利用校准图片做一次实际推理,然后统计网络中各层激活值的实际范围(最大值、最小值)。
4 模型蒸馏
4.1 什么是模型蒸馏
模型蒸馏是一种训练方法,通过让一个体积更小、速度更快的“学生模型(Student)”学习一个大型、准确率更高的“教师模型(Teacher)”的输出行为,从而达到“以小博大”的效果。
简而言之:
📘 大模型先学会任务 → 📘 大模型教小模型 → 📗 小模型学会“像大模型那样聪明地思考”。
4.2 模型蒸馏的核心思路
普通训练时,小模型学的是标签(如猫、狗):
图像 → 小模型 → 输出 → 与真实标签对比(交叉熵损失)
蒸馏训练时,小模型除了学标签,还要模仿大模型输出的“知识”(即soft label):
图像 → 教师模型 → soft输出(概率分布,比如猫0.7狗0.2兔0.1) ← 蒸馏目标
↘
小模型 → 尽量输出与大模型相似的soft分布(而不只是0或1)
为什么要这么做呢
因为:
• 真实标签是“硬”的:只有一个正确类别,信息量少(one-hot)。
• 教师模型输出的是“软标签”:比如说某张图片猫0.7、狗0.2、兔0.1,反映出模型对类别的理解和不确定性,信息量丰富。
• 学生模型通过学习这些分布,可以获得更强的泛化能力和精度。
✅ 蒸馏的主要训练损失:
训练时会综合三种损失:
1. 交叉熵损失(CE):小模型输出 vs 真实标签
2. 蒸馏损失(KL散度):小模型输出 vs 教师模型输出
3. 温度调节(Temperature T):让softmax输出更“软”,信息更丰富
总损失通常是:
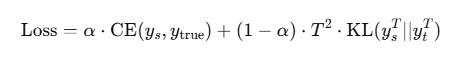
4.3 模型蒸馏和模型迁移学习的区别


模型蒸馏
-
比如你有个训练好的 ResNet152 教师模型,准确率高但模型大。
-
你训练一个轻量化的 MobileNet 学生模型,它同时学:
-
真实标签(如“猫”)
-
教师模型输出的概率分布(如“猫:0.7,狗:0.2”)
-
-
最终学生模型变小、推理快、精度尽量接近老师。
迁移学习
-
你有个在 ImageNet 上训练好的 ResNet50。
-
你把它迁移到一个新的数据集,比如 X光片肺炎检测,微调最后几层。
-
不需要重新从零训练,提高训练效率、适应新领域。
✅ 总结一句话:
模型蒸馏是“大带小”,为了压缩和提速;
迁移学习是“旧带新”,为了适应新任务或新数据。

普通训练: 蒸馏训练:
输入图像 → 小模型 输入图像 → 教师模型 → soft输出
↓ ↘
hard label 小模型输出 → 模仿(soft loss + hard loss)
4.4 模型蒸馏具体怎么落地实施
4.4.1 场景设定
你有一个训练好的大模型(Teacher),可能是 YOLOv5x、YOLOv7、甚至是别的模型(如 Detectron2/FasterRCNN 等),准确率高但太大。
你想用一个小模型(Student),比如 YOLOv5s,来模仿它的输出,提高小模型的准确率,同时保持推理速度快。
4.4.2 总体操作流程
🔧 步骤 1:准备开源 YOLOv5 工程
克隆官方 YOLOv5 仓库:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
📦 步骤 2:准备教师模型(Teacher)
• 教师模型可以是:
• 你自己训练好的 yolov5x/yolov7.pt 等模型
• 也可以是 ONNX / TorchScript 格式,但建议先用 PyTorch 格式,方便操作
• 要能通过 PyTorch 前向推理拿到它的输出
✍️ 步骤 3:修改 YOLOv5 工程,支持蒸馏训练
这部分是关键,要加蒸馏逻辑,下面是做法:
方法 A:简单版(只蒸馏最终输出)
在 train.py 或 models/yolo.py 中修改训练逻辑:
1. 加载教师模型
teacher_model = attempt_load('teacher.pt', map_location=device)
teacher_model.eval()2. 在每个 batch 中前向教师模型:
with torch.no_grad():
teacher_out = teacher_model(images)[0] # [0] 是预测结果3. 在 loss 计算中添加一项 distillation loss,例如:
# 学生模型输出
student_out = student_model(images)[0]
# 普通损失(分类+回归+obj)
loss, _ = compute_loss(student_out, targets)
# 蒸馏损失(可以是 L2 或 KL 散度)
distill_loss = F.mse_loss(student_out, teacher_out)
# 总损失
total_loss = loss + λ * distill_loss
其中 λ 是蒸馏权重,比如 0.5、1.0。
✅ 方法 B:更强版本(中间层蒸馏)
如果你想要更深入的蒸馏,比如蒸馏中间 feature map:
• 在 models/yolo.py 中手动暴露中间层
• 用 hook 或显式地返回中间层输出
• 对比教师和学生的 feature map,用 L2 或注意力蒸馏等方式计算损失
🧪 步骤 4:训练小模型(Student)
直接运行训练脚本即可(像平常一样):
python train.py --img 640 --batch 16 --epochs 100 --data your.yaml --weights yolov5s.pt --name yolov5s-distill✅ 工具推荐(可选)
• YOLOv5-Knowledge-Distillation:开源项目,已在 YOLOv5 上集成蒸馏代码,支持输出层和中间层蒸馏。
• RepDistiller:通用的分类蒸馏框架,但原理可以参考。
4.5 yolov5蒸馏的本质操作
那我看自己修改工程的方法里面,其实就是增加了个对教室模型的输出进行推理,然后计算loss的时候把教室模型的输出给计算上,简单来说就是这个吧,
在训练学生模型时,额外引入教师模型的输出,和学生模型的输出一起计算一个“模仿损失”(distillation loss),让学生不仅学标签,还学老师的“判断方式”。
🔁 所以你的理解可以拆成这三步:
1. 推理阶段:
• 教师模型和学生模型都对同一张图做一次前向传播。
2. Loss计算阶段:
• 除了用学生模型的输出和真实标签算常规损失(比如 obj、cls、bbox loss),
• 还用教师模型的输出和学生模型的输出,算一个“蒸馏损失”,比如 MSE、KL 散度。
3. 合并损失训练学生模型:
• total_loss = normal_loss + λ * distill_loss
• 这个损失反向传播只更新学生模型参数。
核心就是一句话:
训练时加一项蒸馏损失,目标是让小模型模仿大模型的输出行为。
5 算子
算子(Operator)是指在深度学习中,完成某种特定数学计算的最小功能单元。
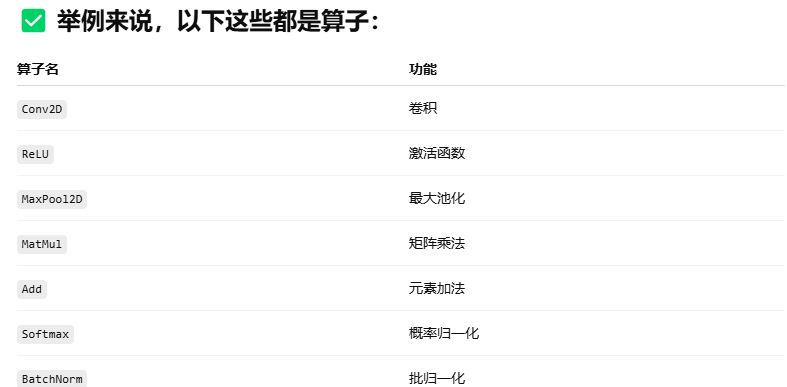
5.1 算子和神经网络的层是一个概念吗
网络中的一个卷积层、激活层,都可以成为算子吗?
网络中的一个卷积层、激活层,都可以成为算子吗?
✔ 答案是:是的!
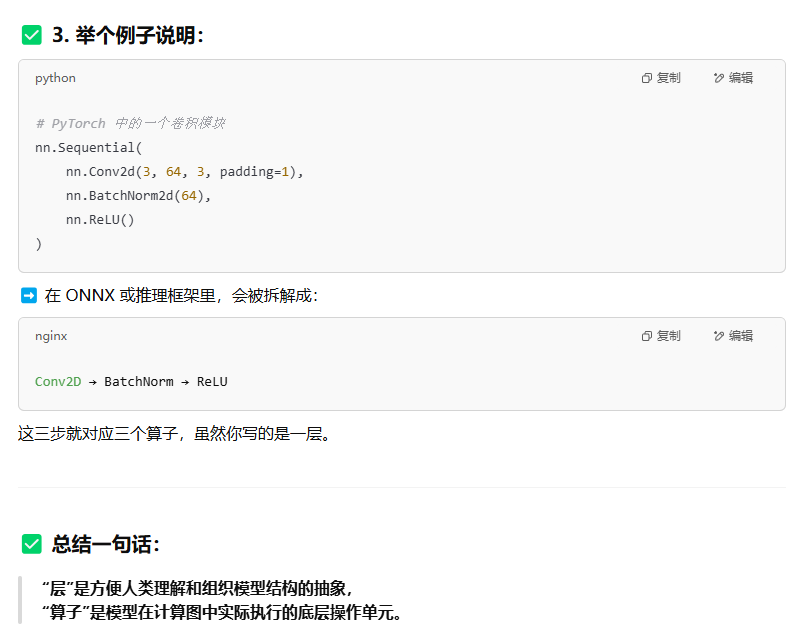
• 一个卷积层对应一个 Conv2D 算子
• 一个激活层对应一个 ReLU 或 LeakyReLU 算子
• 一个全连接层其实对应一个 MatMul + Add 算子组合
• 有时候,一个“层”可能包含多个算子(例如卷积层 + BN + ReLU)
所以说:
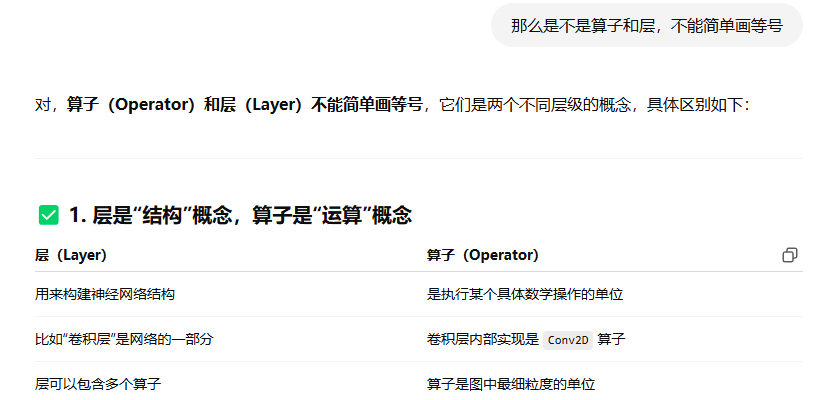
“算子”更像是深度学习模型运行时的“指令级”单位,而“层”更像是构建网络时的“模块级”单位。
✅ 再深入一点:
框架层面:
-
在 TensorFlow / PyTorch / ONNX 里,模型的计算图就是由一系列 算子节点组成的 DAG 图(有向无环图)。
-
每个节点是一个算子,每个边是张量的输入输出。
编译部署时:
-
在 TVM、TensorRT、BM1684X、Ascend、RKNN 这些框架中:
-
模型优化、融合、量化、调度等操作,都是围绕“算子”进行的
-
所以要部署模型,你得知道它用了什么算子,平台支不支持这些算子
-

5.2 层和算子不能划等号

6 算子融合
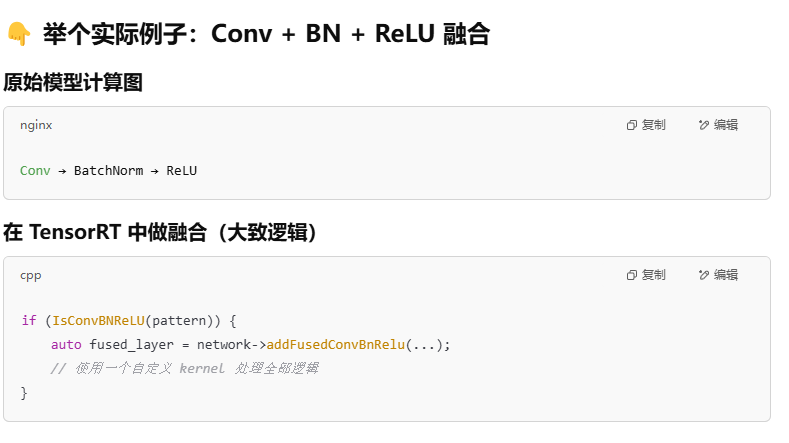
算子融合是将多个相邻的算子在编译或部署阶段合并为一个算子,从而减少内存访问、提高推理性能的一种优化手段。
6.1 为什么要做算子融合?
在模型推理阶段,有三个主要的性能瓶颈:
1. 内存带宽:加载数据、写回结果浪费时间
2. 中间张量频繁写入/读出内存
3. 指令调度、缓存使用低效
而算子融合的目标就是解决这些问题,做到:
• ✅ 减少内存读写(多个中间输出不落地)
• ✅ 降低调度/启动开销
• ✅ 加速推理,尤其是在边缘设备、芯片(如 BM1684X)上提升明显
6.2 常见的可融合算子组合有哪些

6.3 算子融合一般是什么时候做
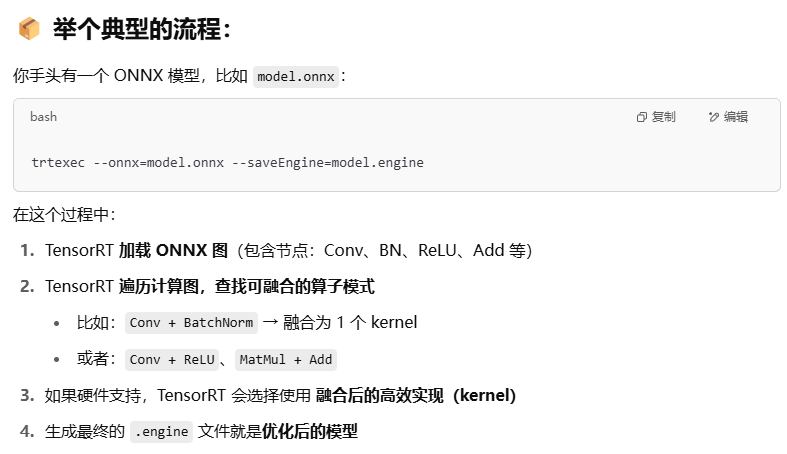
6.4 怎么实现算子融合
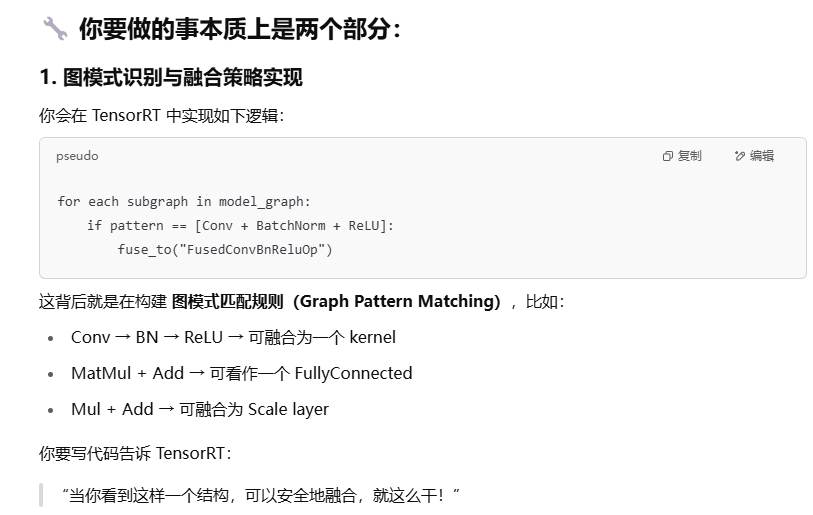




















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











