







# 导入相关模块
import lightgbm as lgb
from lightgbm import early_stopping
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 导入iris数据集
iris = load_iris()
data = iris.data
target = iris.target
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=43)
# 创建lightgbm分类模型
gbm = lgb.LGBMClassifier(objective='multiclass',
num_class=3,
num_leaves=31,
learning_rate=0.05,
n_estimators=20)
# 模型训练
callbacks = [early_stopping(stopping_rounds=5)]
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)],callbacks=callbacks)
# 预测测试集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
# 模型评估
print('Accuracy of lightgbm:', accuracy_score(y_test, y_pred))
lgb.plot_importance(gbm)
plt.show()
使用 LightGBM 对鸢尾花数据集进行分类的代码解析
1. 导入相关模块
import lightgbm as lgb
from lightgbm import early_stopping
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
- lightgbm:导入 LightGBM 的 Python 接口,用于构建和训练模型。
- early_stopping:从 LightGBM 中导入早停函数,防止过拟合。
- accuracy_score:用于计算模型的准确率。
- load_iris:加载鸢尾花数据集的函数。
- train_test_split:用于将数据集拆分为训练集和测试集。
- matplotlib.pyplot:用于数据可视化,绘制特征重要性图等。
2. 导入鸢尾花数据集
iris = load_iris()
data = iris.data
target = iris.target
- load_iris():加载鸢尾花数据集,该数据集包含 150 个样本,每个样本有 4 个特征,目标变量有 3 个类别(0,1,2)。
- data:特征矩阵,大小为 (150, 4)。
- target:目标向量,大小为 (150,)。
3. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(
data, target, test_size=0.2, random_state=43
)
- train_test_split():将数据集划分为训练集和测试集。
- test_size=0.2:测试集占 20%。
- random_state=43:设置随机数种子,保证结果可重复。
4. 创建 LightGBM 分类模型
gbm = lgb.LGBMClassifier(
objective='multiclass',
num_class=3,
num_leaves=31,
learning_rate=0.05,
n_estimators=20
)
- LGBMClassifier:初始化一个 LightGBM 分类器。
- objective=‘multiclass’:设置目标函数为多分类。
- num_class=3:类别数量为 3。
- num_leaves=31:树的最大叶子节点数,控制模型复杂度。
- learning_rate=0.05:学习率,控制每次迭代的步长。
- n_estimators=20:弱学习器(决策树)的数量。
5. 模型训练
callbacks = [early_stopping(stopping_rounds=5)]
gbm.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
callbacks=callbacks
)
- callbacks:设置回调函数列表,这里使用早停法。
- early_stopping(stopping_rounds=5):如果在 5 次迭代中,验证集的指标没有提升,则停止训练。
- eval_set:指定验证集,用于监控模型在训练过程中的性能。
6. 预测测试集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
- predict():对测试集进行预测。
- num_iteration=gbm.best_iteration_:使用在验证集上表现最好的迭代次数。
7. 模型评估
print('Accuracy of lightgbm:', accuracy_score(y_test, y_pred))
lgb.plot_importance(gbm)
plt.show()
- accuracy_score(y_test, y_pred):计算模型的准确率。
- lgb.plot_importance(gbm):绘制特征重要性图,显示各特征对模型的贡献度。
- plt.show():显示绘制的图形。
深入理解
早停法(Early Stopping)
- 作用:防止模型过拟合,提高泛化能力。
- 原理:监控验证集的性能指标,如果在若干次迭代内没有提升,则提前停止训练。
特征重要性
- 意义:衡量每个特征在模型决策中的作用大小。
- 计算方法:根据特征在树结构中的分裂次数、信息增益等指标计算。
参数说明
- objective:定义了损失函数类型。
- ‘multiclass’:多分类损失函数。
- num_class:类别数,必须与数据集实际类别数一致。
- num_leaves:树的最大叶子数,值越大,模型越复杂。
- learning_rate:学习率,值越小,模型训练越慢,但可能获得更好的效果。
- n_estimators:弱学习器的数量,过大可能导致过拟合。
- stopping_rounds:早停法中没有提升的迭代次数阈值。
可能的改进方向
-
参数调优
- Grid Search 或 Random Search:使用网格搜索或随机搜索来寻找最优参数组合。
- 调整
num_leaves:根据数据集规模和复杂度,调整叶子节点数。 - 增加
n_estimators:在控制过拟合的前提下,增加弱学习器数量。
-
交叉验证
- 使用 K 折交叉验证,提高模型评估的可靠性。
-
特征工程
- 特征选择:去除不相关或冗余的特征。
- 特征构造:创建新的特征以捕获更多信息。
-
处理类别不平衡
- 如果类别分布不均衡,可以调整 class_weight 参数。
注意事项
-
LightGBM 的优势:
- 高效性:训练速度快,内存占用低。
- 准确性:在很多任务上都能取得较高的准确率。
- 易用性:接口友好,参数丰富。
-
数据预处理:
- LightGBM 能够自动处理缺失值和类别特征,但良好的数据预处理仍然重要。
运行结果示例
Accuracy of lightgbm: 0.9666666666666667
-
解释:模型在测试集上的准确率为 96.67%,表现良好。
-
特征重要性图:
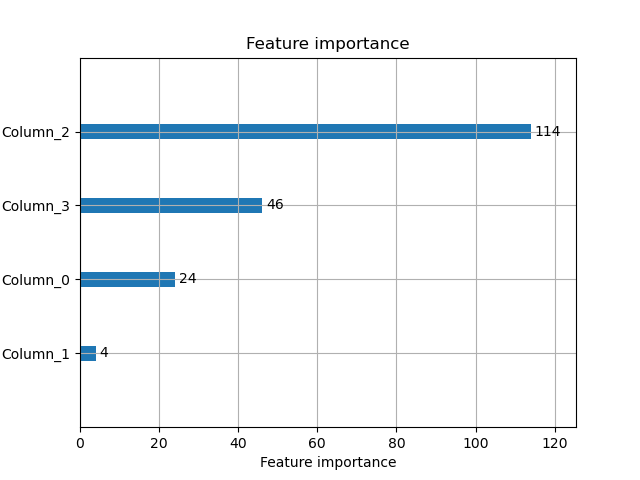
- 图中显示了各个特征的重要性,有助于理解模型决策过程。
结论
通过以上代码,您成功地使用 LightGBM 对鸢尾花数据集进行了多分类任务的建模和评估。该示例展示了 LightGBM 的基本用法,包括模型创建、训练、预测和评估。


















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











