






原文:http://blog.sina.com.cn/s/blog_9409e4a3010137gm.html
环境建模
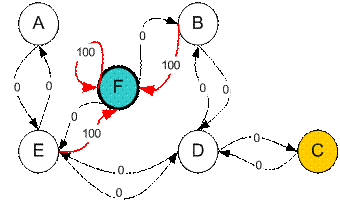
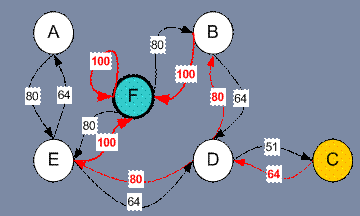
假设在一个建筑里有5个房间通过门连通如下图所示,我们给5个房间依次命名为A~E。现在考虑我们站在外面的一个大房间F,且房间F覆盖了建筑其余所有空间。也就是从F可以进入B或E房间。
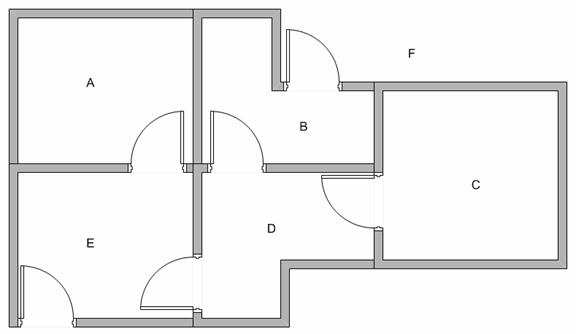
我们可以将每个房间表示为一个节点,每扇门作为一条边。
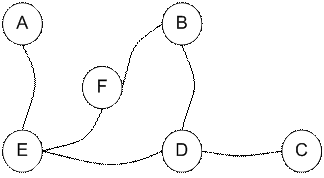
我们想要到达一个目标房间。如果将一个agent放入任一一个房间,我们希望agent可以走出这个建筑。换句话说,目标房间就是F。这里我们为每扇门引入一个回报值(例如图中的边长)。如果一扇门可以瞬时到达目标F则回报值为100(如下图所示,即红色箭头所示),其他门无法直接到达F则回报值为0。因为门是双向的(从A可以到达E,从E也可以到达A),所以每两个节点都有两个相反的箭头所指向,每个箭头都包含一个瞬时回报值。图变成了一个状态状图,如下图所示。
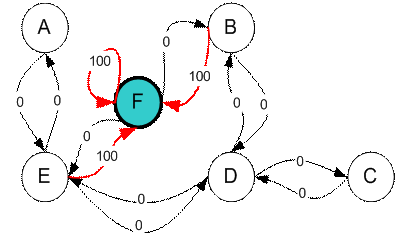
注意F节点有一个最大回报值自循环(F back to F),所以如果一个agent到达目标节点,它将永远停在这里,我们称其为吸引节点(absorbing goal)。因为agent到达这个目标状态,它将一直维持这个状态。
Agent,状态(state)和行为(Action)介绍
假设我们的agent是一个机器人并且可以通过行走来学习。机器人在对环境未知的情况下从一间房间走进另间房间。更加不知道如果如果选择走过哪扇门从而走出建筑。
Suppose we want to model some kind of simple evacuation of an agent from any room in the building. 现在我们假设机器人当前时刻在C,并且希望机器人可以通过学习走到F。
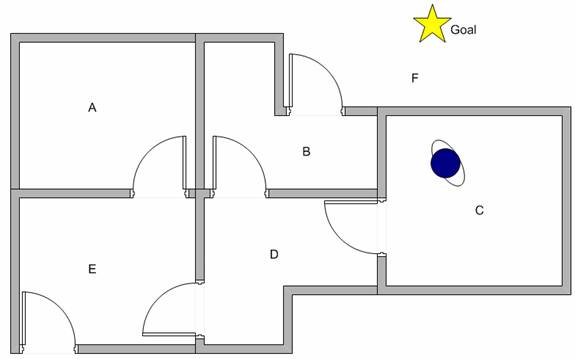
如何让机器人从行走中不断学习?
在我们讨论机器人学习(Q-learning)之前,让我们了解下术语状态(state)和行为(action)。
我们将每间房间(包括目标房间)作为state。机器人从一间房间移动到另一间房间称作action。回想下上面的状态装换图。通过状态图的节点描述state,用箭头代表action。
假设现在机器人在stateC,从stateC,机器人只能到达stateD。从stateD可以到达stateB,stateE或者回到stateC,如果在stateE,机器人可以有三种action,即到stateA,stateF或者stateD,如果机器人在stateB,它既可以到达stateF,也可以到达stateD。
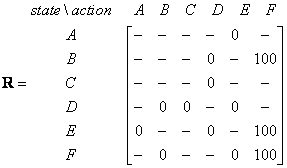
我们现在将状态装换图和瞬时回报值放入回报表R中
| | Action to go to state | |||||
| Agent now in state | A | B | C | D | E | F |
| A | - | - | - | - | 0 | - |
| B | - | - | - | 0 | - | 100 |
| C | - | - | - | 0 | - | - |
| D | - | 0 | 0 | - | 0 | - |
| E | 0 | - | - | 0 | - | 100 |
| F | - | 0 | - | - | 0 | 100 |
Q-Learning
在前面我们建立了环境模型和回报系统。这部分我们将讲解学习算法Q-Learning(它是对强化学习的简化)。
我们建立环境回报系统矩阵R
现在我们将一个类似于矩阵的Q放入机器人的大脑,Q将保存机器人通过行走获得的环境信息。矩阵Q的行头代表机器人状态,Q的列头代表行为所指向的下一个转换状态。
开始,机器人对环境信息一无所知。因此Q是一个零矩阵。在本例中,为了方便讲解,我们假设状态数已知(状态数为6),一般情况下,我们可以将Q矩阵初始化为一个空矩阵(Q=[])。之后当发现一个新状态时就增加Q矩阵的行和列。
Q-Learning的转换规则如下:
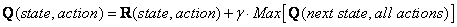
这个公式的意思是矩阵Q等于当前状态的瞬时回报R加上从所有可能的action中选择到达某一相应状态得到的最大Q值与γ的乘积,这里γ为学习参数(0<=γ<1)。
Q-Learning 算法
机器人在无监督的情况下(无监督学习)。机器人通过一个状态到一个状态的搜索直到到达目标节点。这里我们称一次起始节点搜索到达目标节点为一个episode,当一个episode结束,程序进入下一个episode。收敛证明请点击(See
Q-Learning 总结
假设:状态转换图带有一个目标状态(用矩阵R来表示)。
寻找:从起始状态到达目标状态最短路径(用矩阵Q来表示)。
| Q Learning Algorithm
End Do End For |
γ的在[0,1)之间,当γ趋近于0时,机器人趋向于仅考虑瞬时回报,如果γ接近1,机器人将以比较大的比重考虑未来的回报,也即延迟回报。
这里使用Q矩阵,机器人从初始状态知道目标状态不断跟踪状态序列。算法仅仅是找到一个行为去使得当前状态下获得最大Q。
具体步骤:
我们假设γ为0.8。初始状态为B,首先设置Q为零矩阵。

这里矩阵R表示为当前环境下的回报矩阵

我们看R中第二行(状态B)。这里对于当前状态B有两个可能的动作,通过随机选择我们选择F作为我们的行为。
现在我们考虑假设我们处于状态F。回头看下回报矩阵R,有3种可选行为去到达B,E或者F。
Q(state,action) = R(state,action) + γ*MAX[Q(next state,all actions)]
Q(B,F) = R(B,F) + 0.8*MAX[Q(F,B),Q(F,E),Q(F,F)]=100 + 0.8*0 = 100
因为矩阵Q仍然是一个零矩阵,所以Q(F,B),Q(F,E),Q(F,F)都为零。
下个状态是F,现在F变成了当前状态。因为F是目标状态,我们就完成了一个episode。现在机器人包含了更新好的Q矩阵:

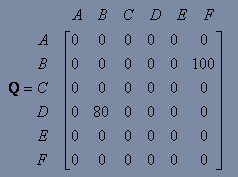
对于下一个episode,我们重新随机选择一个起始状态D。
回想回报矩阵R,在D下有三种可选行为,可以转换到B,C或者E。通过随机选择,我们选择B作为我们的行为。
现在我们假设我们在状态B下。查看R中的第二行,我们有两种选择可以到D或者F,我们现在计算Q值:
Q(state,action) = R(state,action) + γ*MAX[Q(next state, action, all actions]
Q(D,B) = R(D,B) + 0.8 MAX[Q(B,D),Q(B,F)] = 0 + 0.8*100 = 80
我们再次更新矩阵Q为如下:
则B变为当前状态,我们重复Q-learning以到达目标状态F。我们很幸运的选择行为F。
现在F有三种行为到达B,E或者F。我们计算Q值:
Q(state,action) = R(state,action) + γ*MAX[Q(next state,all actions)]
Q(B,F) = R(B,F) + 0.8*MAX[Q(F,B),Q(F,E),Q(F,F)]=100 + 0.8*0 = 100
因为F是目标状态,我们完成这次episode,机器人大脑中包含的已更新Q矩阵为:
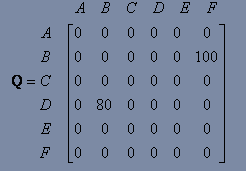
如果机器人经历了更多次episode,最终Q矩阵将达到收敛:

之后对Q进行归一化

当Q矩阵几乎收敛时,机器人可以获得一条到达目标状态的最优路径。跟踪状态序列,我们可以很容易的计算出通过一组什么样的行为可以获得最大Q值
例如我们将C作为初始状态,我们可以这样获得一条最优路径:
首先在状态C下产生一个行为D来获得最大Q;
之后再状态D下有两个状态B或者E可获得最大Q值,这里假设我们选择B;
在状态B下选择行为F;
因此路径序列为C-D-B-F















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









