




1 常微分方程
常微分方程只包含单个自变量 t t t,未知函数 y ( t ) y(t) y(t)和未知函数的导数 y ′ ( t ) y'(t) y′(t)的等式,例如: y ′ ( t ) = 2 t y'(t)=2t y′(t)=2t。可以写成如下通用的形式:
y ( 0 ) = y 0 ; d y d t ( t ) = f θ ( t , y ( t ) ) (1) y(0)=y_{0}; \frac{dy}{dt}(t)=f_{\theta}(t, y(t)) \tag{1} y(0)=y0;dtdy(t)=fθ(t,y(t))(1)
其中, f θ ( t , y ( t ) ) f_{\theta}(t, y(t)) fθ(t,y(t))表示由 t t t与 y ( t ) y(t) y(t)组成的某个函数,函数的常数为参数 θ \theta θ。
求解常微分方程的方式有两种:
1)求出解析解,得到 y ( t ) y(t) y(t)的具体形式,例如: y ′ ( t ) = 2 t y'(t)=2t y′(t)=2t的通解为 y ( t ) = t 2 + C y(t)=t^2+C y(t)=t2+C, C C C由 y ( 0 ) = y 0 y(0)=y_0 y(0)=y0代入确定;
2)求出数值解,例如:欧拉法,迭代求解出
y
(
t
)
y(t)
y(t)在某
t
t
t位置的函数值,其核心思想是用切线逐步逼近求解函数:
y
n
+
1
=
y
n
+
f
θ
(
t
n
,
y
n
)
(
t
n
+
1
−
t
n
)
(2)
y_{n+1}=y_{n}+f_{\theta}(t_n, y_{n})(t_{n+1}-t_n)\tag{2}
yn+1=yn+fθ(tn,yn)(tn+1−tn)(2)
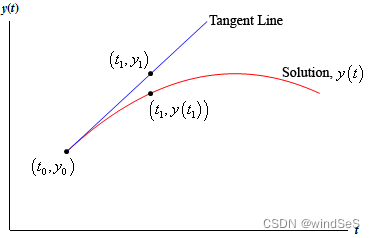
对于实际问题,大部分情况下都无法得到解析解。因此,求出数值解就成了唯一可行的方式。如下面示意图所示,在知道常微分方程的形式(公式(1)),我们便可以 ( t 0 , y 0 ) → ( t 1 , y 1 ) → . . . (t_0, y_0)\rightarrow(t_1, y_1)\rightarrow ... (t0,y0)→(t1,y1)→...迭代的出解出目标位置处的解析解。
2 从残差网络到常微分方程
一层残差网络可形式化为下图:
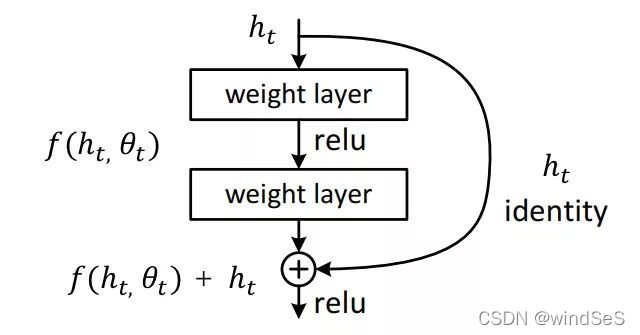
我们可以将上面的残差网络表式成以下方程:
h t + 1 = h t + f θ ( h t ) (3) h_{t+1}=h_t+f_{\theta}(h_t) \tag{3} ht+1=ht+fθ(ht)(3)
重新变化式(2)与式(3)得:
常微分离散化形式:
y
n
+
1
−
y
n
t
n
+
1
−
t
n
=
f
θ
(
t
n
,
y
n
)
\frac{y_{n+1}-y_{n}}{t_{n+1}-t_n}=f_{\theta}(t_n, y_{n})
tn+1−tnyn+1−yn=fθ(tn,yn)
残差网络形式:
h
t
+
1
−
h
t
1
=
f
θ
(
h
t
)
\frac{h_{t+1}-h_t}{1}=f_{\theta}(h_t)
1ht+1−ht=fθ(ht)
可知残差网络是状态步长为1,且不显式地包含自变量 t t t的常微分方程。要使得残差网络能表示更一般的常微分方程,可以设计如下的网络结构(主要在输入增加变量t):
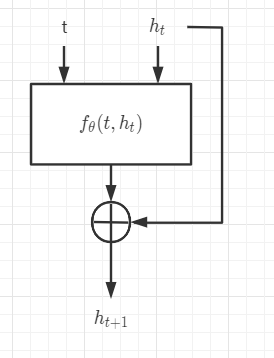
从上可以分析得出,残差网络(本质上和欧拉法一样)可用来计算常微分方程的数值解。通过给
f
θ
(
t
,
h
t
)
f_{\theta}(t, h_t)
fθ(t,ht)乘上可变的步长
d
t
dt
dt,便得到更加一般的形式:
h
t
+
1
=
h
t
+
f
θ
(
t
,
h
t
)
d
t
h_{t+1}=h_t+f_{\theta}(t, h_t)dt
ht+1=ht+fθ(t,ht)dt
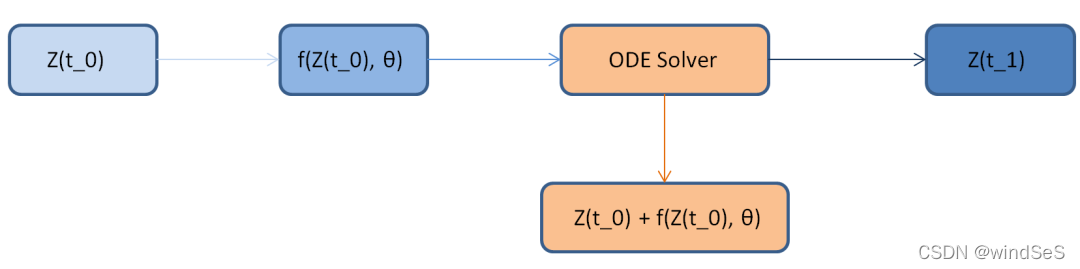
但是,用欧拉法与残差网络来计算常微分方程的数值解太过粗糙。如果用一个抽象的概念来代替欧拉法与残差网络,例如ODESolver网络,其中ODESolver是一个函数,它提供了ODE的解决方法,其精度比欧拉法高得多。这就是神经常微分方程(把ODESolver当成一个黑盒):
3 怎么训练神经常微分方程
在算法 1 1中,陈天琦等研究者展示了如何借助另一个 OED Solver 一次性求出反向传播的各种梯度和更新量。要理解算法 1,首先我们要熟悉 ODESolver 的表达方式。例如在 ODEnet 的前向传播中,求解过程可以表示为 ODEsolver(z(t_0), f, t_0, t_1, θ),我们可以理解为从 t_0 时刻开始令 z(t_0) 以变化率 f 进行演化,这种演化即 f 在 t 上的积分,ODESolver 的目标是通过积分求得 z(t_1)。

同样我们能以这种方式理解算法 1,我们的目的是利用 ODESolver 从 z(t_1) 求出 z(t_0)、从 a(t_1) 按照方程 4 积出 a(t_0)、从 0 按照方程 5 积出 dL/dθ。最后我们只需要使用 dL/dθ 更新神经网络 f(z(t), t, θ) 就完成了整个反向传播过程。
4. 伴随法BP的推导
动态微分系统的数据集中的元素可以由<时间,状态>对表示,标记为 ( z , t ) (z, t) (z,t)。
假定我们要学习的动态微分系统的形式为:
d
z
d
t
=
f
(
z
(
t
)
,
t
)
(4)
\frac{dz}{dt}=f(z(t), t) \tag{4}
dtdz=f(z(t),t)(4)
用于学习的观测数据集为
{
(
z
0
,
t
0
)
,
(
z
1
,
t
1
)
,
.
.
.
,
(
z
N
,
t
N
)
}
\{(z_0, t_0), (z_1, t_1), ..., (z_N, t_N)\}
{(z0,t0),(z1,t1),...,(zN,tN)}。
我们利用可学习的网络模型 f ^ ( z , t , θ ) \hat{f}(z, t, \theta) f^(z,t,θ)来近似动态系统真实的微分函数 f ( z , t ) f(z, t) f(z,t)。
若以某状态 z 0 z_0 z0为起始状态(假定 z 0 z_0 z0在数据集中的时间标记为 t 0 t_0 t0),我们验证所学到的网络模型是否很好的近似了真实的微分函数 f ( z , t ) f(z, t) f(z,t)的基本方式为:
- 以
z
0
z_0
z0作为起始状态,以网络模型作为微分函数,利用
ODE Solver求得 t 1 t_1 t1时刻的状态 z ^ 1 \hat{z}_1 z^1; - 从数据集中找到时间标记为 t 1 t_1 t1的状态 z 1 z_1 z1;
- 利用 z ^ 1 \hat{z}_1 z^1与 z 1 z_1 z1的差异来度量学习效果,一种可能的损失函数为 L ( z ^ 1 ) = 1 2 ∣ ∣ z ^ 1 − z 1 ∣ ∣ 2 2 L(\hat{z}_1)=\frac{1}{2}||\hat{z}_1-z_1||_2^2 L(z^1)=21∣∣z^1−z1∣∣22。
实际数据不可能只有一个样本,那么损失函数的一般形式采用如下所示的均方误差(MSE):
L = 1 N ∑ i = 1 N ∣ ∣ z ^ i − z i ∣ ∣ 2 2 = 1 N ∑ i = 1 N ∣ ∣ ∫ t i − 1 t i f ^ ( z , t , θ ) d t − z i ∣ ∣ 2 2 = 1 N ∑ i = 1 N ∣ ∣ O D E S o l v e r ( z i − 1 , f , t i − 1 , t i , θ ) − z i ∣ ∣ 2 2 (5) L=\frac{1}{N}\sum_{i=1}^{N}||\hat{z}_i-z_i||_2^2=\frac{1}{N}\sum_{i=1}^{N}||\int_{t_{i-1}}^{t_i}\hat{f}(z, t, \theta)dt-z_i||_2^2=\frac{1}{N}\sum_{i=1}^{N}||ODESolver(z_{i-1}, f, t_{i-1}, t_i, \theta)-z_i||_2^2 \tag{5} L=N1i=1∑N∣∣z^i−zi∣∣22=N1i=1∑N∣∣∫ti−1tif^(z,t,θ)dt−zi∣∣22=N1i=1∑N∣∣ODESolver(zi−1,f,ti−1,ti,θ)−zi∣∣22(5)
我们要更新的模型参数为
θ
\theta
θ,因此,我们最终需要得到的是
d
L
d
θ
\frac{dL}{d\theta}
dθdL。但是,从
z
(
t
i
−
1
)
z(t_{i-1})
z(ti−1)到
z
(
t
i
)
z(t_i)
z(ti)利用了ODESolver算子,一个python版本的ODESolver算子如下所示:
def ode_solve(z0, t0, t1, f):
"""
Simplest Euler ODE initial value solver
"""
h_max = 0.05
n_steps = math.ceil((abs(t1 - t0)/h_max).max().item())
h = (t1 - t0)/n_steps
t = t0
z = z0
for i_step in range(n_steps):
z = z + h * f(z, t)
t = t + h
return z
当系统是时变的,输入 t t t是作为网络的输入,当系统是时不变的, t t t在此处对函数的输出没有影响。一个时不变的 f f f例子给出如下:
class LinearODEF(ODEF):
def __init__(self, W):
super(LinearODEF, self).__init__()
self.lin = nn.Linear(2, 2, bias=False)
self.lin.weight = nn.Parameter(W)
def forward(self, x, t):
return self.lin(x)
虽然,构建的网络模型基于函数
f
f
f,但是完整的网络是基
f
f
f与ODESolver,并采用一个设定时间步
d
t
dt
dt的累积函数
z
^
n
=
N
e
t
(
z
0
,
θ
,
t
0
,
t
1
)
=
z
0
+
∑
i
=
1
n
f
(
z
^
i
−
1
,
t
i
−
1
,
θ
)
d
t
\hat{\mathbf{z}}_{n}=Net(\mathbf{z}_0, \theta, t_0, t_1)=\mathbf{z}_0+\sum_{i=1}^{n}f(\hat{\mathbf{z}}_{i-1}, t_{i-1}, \theta)dt
z^n=Net(z0,θ,t0,t1)=z0+∑i=1nf(z^i−1,ti−1,θ)dt,其中,
n
=
t
1
−
t
0
d
t
n=\frac{t_1-t_0}{dt}
n=dtt1−t0。为了得到
d
L
d
θ
\frac{dL}{d\theta}
dθdL,我们需要采用与反向传播算法一样的链式法则,同时需要计算
d
L
d
z
^
,
d
L
d
t
\frac{dL}{d\hat{\mathbf{z}}},\frac{dL}{dt}
dz^dL,dtdL。
令
a
(
t
)
=
d
L
d
z
^
(
t
)
\mathbf{a}(t)=\frac{dL}{d\hat{\mathbf{z}}(t)}
a(t)=dz^(t)dL,我们有:
d
a
(
t
)
d
t
=
−
a
(
t
)
∂
f
(
z
(
t
)
,
t
,
θ
)
∂
z
(
t
)
(6)
\frac{d\mathbf{a}(t)}{dt}=-\mathbf{a}(t)\frac{\partial f(\mathbf{z}(t),t,\theta)}{\partial \mathbf{z}(t)}\tag{6}
dtda(t)=−a(t)∂z(t)∂f(z(t),t,θ)(6)
式(6)的证明:
其中第二行中分子的第二项证明(上面第三行为泰勒展开):
z ( t + ϵ ) = ∫ t t + ϵ f ( z ( t ) , t , θ ) d t + z ( t ) = T ϵ ( z ( t ) , t ) \mathbf{z}(t+\epsilon)=\int_{t}^{t+\epsilon}f(\mathbf{z}(t),t,\theta)dt+\mathbf{z}(t)=T_{\epsilon}(\mathbf{z}(t),t) z(t+ϵ)=∫tt+ϵf(z(t),t,θ)dt+z(t)=Tϵ(z(t),t)
d L ∂ z ( t ) = d L d z ( t + ϵ ) d t + ϵ d z ( t ) ⇒ a ( t ) = a ( t + ϵ ) ∂ T ϵ ( z ( t ) , t ) ∂ z ( t ) \frac{dL}{\partial \mathbf{z}(t)}=\frac{dL}{d\mathbf{z}(t+\epsilon)}\frac{d\mathbf{t+\epsilon}}{d\mathbf{z}(t)}\Rightarrow \mathbf{a}(t)=\mathbf{a}(t+\epsilon)\frac{\partial T_{\epsilon}(\mathbf{z}(t), t)}{\partial \mathbf{z}(t)} ∂z(t)dL=dz(t+ϵ)dLdz(t)dt+ϵ⇒a(t)=a(t+ϵ)∂z(t)∂Tϵ(z(t),t)
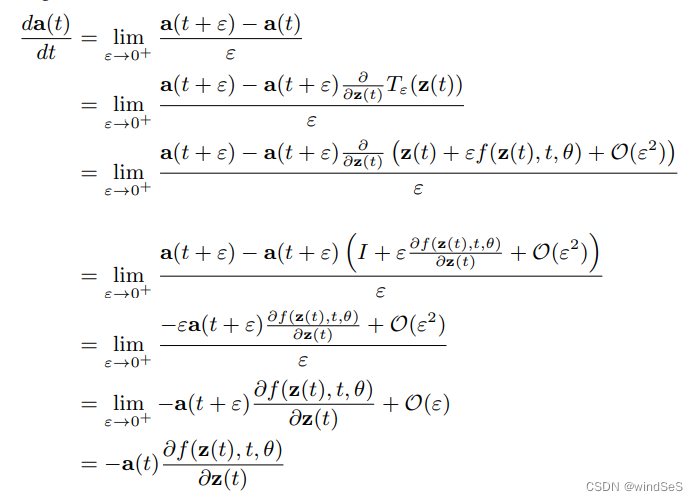
假如,我们从
{
(
z
0
,
t
0
)
,
(
z
1
,
t
1
)
,
.
.
.
,
(
z
N
,
t
N
)
}
\{(\mathbf{z}_0, t_0), (\mathbf{z}_1, t_1), ..., (\mathbf{z}_N, t_N)\}
{(z0,t0),(z1,t1),...,(zN,tN)}中抽取一个样本
(
z
N
−
1
,
t
N
−
1
)
→
(
z
N
,
t
N
)
(\mathbf{z}_{N-1}, t_{N-1})\rightarrow (\mathbf{z}_{N}, t_N)
(zN−1,tN−1)→(zN,tN),表示以
z
N
−
1
\mathbf{z}_{N-1}
zN−1为起始状态,经过时间
t
N
−
t
N
−
1
t_N-t_{N-1}
tN−tN−1,动态系统(此处假设为时不变系统)的状态变为
z
N
\mathbf{z}_N
zN。由内嵌ODESolver算子的神经网络模型得到的状态为
z
^
N
\hat{\mathbf{z}}_N
z^N。
由于 z ^ N \hat{\mathbf{z}}_N z^N相当于一般学习任务的输出 y y y,所以 d L d z ^ ( t N ) = d d z ^ N ( 1 2 ∣ ∣ z ^ N − z N ∣ ∣ 2 2 ) \frac{dL}{d\hat{\mathbf{z}}(t_N)}=\frac{d}{d\hat{\mathbf{z}}_N}(\frac{1}{2}||\hat{\mathbf{z}}_N-\mathbf{z}_N||_2^2) dz^(tN)dL=dz^Nd(21∣∣z^N−zN∣∣22),直接能得到结果。
重要的是怎么得到
d
L
z
^
N
−
1
\frac{dL}{\hat{\mathbf{z}}_{N-1}}
z^N−1dL(从
z
^
N
−
1
\hat{\mathbf{z}}_{N-1}
z^N−1到
z
^
N
\hat{\mathbf{z}}_N
z^N的过程是一个多次累积的ODESolver算法),根据公式(6)有:
d
L
d
z
^
N
−
1
=
a
(
t
N
−
1
)
=
a
(
t
N
)
+
∫
t
N
t
N
−
1
d
a
(
t
)
d
t
d
t
=
a
(
t
N
)
−
∫
t
N
t
N
−
1
a
(
t
)
T
∂
f
(
z
^
(
t
)
,
t
,
θ
)
∂
z
^
(
t
)
(7)
\frac{dL}{d\hat{\mathbf{z}}_{N-1}}=\mathbf{a}(t_{N-1})=\mathbf{a}(t_{N})+\int_{t_N}^{t_{N-1}}\frac{d\mathbf{a}(t)}{dt}dt=\mathbf{a}(t_{N})-\int_{t_{N}}^{t_{N-1}}\mathbf{a}(t)^T\frac{\partial f(\hat{\mathbf{z}}(t), t, \theta)}{\partial \hat{\mathbf{z}}(t)}\tag{7}
dz^N−1dL=a(tN−1)=a(tN)+∫tNtN−1dtda(t)dt=a(tN)−∫tNtN−1a(t)T∂z^(t)∂f(z^(t),t,θ)(7)
我们可以看到,公式(7)用ODESolver算法就将梯度
d
L
d
z
^
N
\frac{dL}{d\hat{\mathbf{z}}_N}
dz^NdL反向传播给
d
L
d
z
^
N
−
1
\frac{dL}{d\hat{\mathbf{z}}_{N-1}}
dz^N−1dL。
如下图所示,数据是按
t
0
→
t
1
t_0\rightarrow t_1
t0→t1,
t
1
→
t
2
t_1\rightarrow t_2
t1→t2,…,
t
N
−
1
→
t
N
t_{N-1}\rightarrow t_N
tN−1→tN组合作为训练数据的,但是
d
L
d
z
^
(
t
N
)
\frac{dL}{d\hat{\mathbf{z}}(t_N)}
dz^(tN)dL的梯度可以传播给
t
N
−
1
t_{N-1}
tN−1,也可以继续往后传播给
t
N
−
2
t_{N-2}
tN−2直至数据采集时的起点
t
0
t_0
t0。所有前方的数据都可以把梯度传播给它后方(下图右2为前,左为后)用于训练。

不要忘记了我们的目的,计算
d
L
d
θ
\frac{dL}{d\theta}
dθdL。
ODESolver算子以
z
^
i
\hat{\mathbf{z}}_i
z^i作为中间状态,我们根据链式法则有
a
θ
(
t
)
=
d
L
d
θ
=
d
L
d
z
^
d
z
^
d
θ
=
a
(
t
)
d
z
^
d
θ
\mathbf{a}_{\theta}(t)=\frac{dL}{d\theta}=\frac{dL}{d\hat{\mathbf{z}}}\frac{d\hat{\mathbf{z}}}{d\theta}=\mathbf{a}(t)\frac{d\hat{\mathbf{z}}}{d\theta}
aθ(t)=dθdL=dz^dLdθdz^=a(t)dθdz^
我们可以先求得
d
L
d
θ
=
∫
d
d
t
d
L
d
θ
d
t
\frac{dL}{d\theta}=\int\frac{d}{dt}\frac{dL}{d\theta}dt
dθdL=∫dtddθdLdt中的
d
d
t
d
L
d
θ
\frac{d}{dt}\frac{dL}{d\theta}
dtddθdL。
d
d
t
d
L
d
θ
=
d
d
θ
d
L
d
z
^
d
z
^
d
t
=
d
d
θ
a
(
t
)
f
(
z
^
,
t
,
θ
)
=
a
(
t
)
∂
f
(
z
^
,
t
,
θ
)
∂
θ
\frac{d}{dt}\frac{dL}{d\theta}=\frac{d}{d\theta}\frac{dL}{d\hat{\mathbf{z}}}\frac{d\hat{\mathbf{z}}}{dt}=\frac{d}{d\theta} \mathbf{a}(t)f(\hat{\mathbf{z}}, t, \theta)=\mathbf{a}(t)\frac{\partial f(\hat{\mathbf{z}}, t, \theta)}{\partial \theta}
dtddθdL=dθddz^dLdtdz^=dθda(t)f(z^,t,θ)=a(t)∂θ∂f(z^,t,θ)
将
a
θ
(
t
N
)
=
0
\mathbf{a}_{\theta}(t_N)=0
aθ(tN)=0,得:
a θ ( t N − 1 ) = d L d θ = − ∫ t N t N − 1 a ( t ) ∂ f ( z ^ , t , θ ) ∂ θ d t (8) \mathbf{a}_{\theta}(t_{N-1})=\frac{dL}{d\theta}=-\int_{t_N}^{t_{N-1}}\mathbf{a}(t)\frac{\partial f(\hat{\mathbf{z}}, t, \theta)}{\partial \theta}dt \tag{8} aθ(tN−1)=dθdL=−∫tNtN−1a(t)∂θ∂f(z^,t,θ)dt(8)
当然,还需要求(对于时变系统需要)
a
t
(
t
)
=
d
L
d
t
=
d
L
d
z
^
d
z
^
d
t
=
a
(
t
)
f
(
z
^
,
t
,
θ
)
\mathbf{a}_t(t)=\frac{dL}{dt}=\frac{dL}{d\hat{\mathbf{z}}}\frac{d\hat{\mathbf{z}}}{dt}=\mathbf{a}(t)f(\hat{\mathbf{z}}, t,\theta)
at(t)=dtdL=dz^dLdtdz^=a(t)f(z^,t,θ),由于我们想求任意时刻的
a
t
(
t
)
\mathbf{a}_t(t)
at(t),而网络模型的forward只输出
t
N
t_N
tN时刻的
f
(
z
N
^
,
t
N
,
θ
)
f(\hat{\mathbf{z}_{N}}, t_N,\theta)
f(zN^,tN,θ),依据此式,我们只能计算出
a
t
(
t
N
)
=
a
(
t
N
)
f
(
z
N
^
,
t
N
,
θ
)
\mathbf{a}_t(t_N)=\mathbf{a}(t_N)f(\hat{\mathbf{z}_{N}}, t_N,\theta)
at(tN)=a(tN)f(zN^,tN,θ)。,因此需要寻找其它计算形式:
我们可以令
d
L
d
t
=
∫
d
d
t
d
L
d
t
d
t
,
\frac{dL}{dt}=\int \frac{d}{dt}\frac{dL}{dt}dt,
dtdL=∫dtddtdLdt,
d
d
t
d
L
d
t
=
d
d
t
d
L
d
z
^
d
z
^
d
t
=
a
(
t
)
∂
f
(
z
^
,
t
,
θ
)
∂
t
\frac{d}{dt}\frac{dL}{dt}=\frac{d}{dt}\frac{dL}{d\hat{\mathbf{z}}}\frac{d\hat{\mathbf{z}}}{dt}=\mathbf{a}(t)\frac{\partial f(\hat{\mathbf{z}}, t,\theta)}{\partial t}
dtddtdL=dtddz^dLdtdz^=a(t)∂t∂f(z^,t,θ)
根据上面我们有
a
t
(
t
N
)
=
a
(
t
N
)
f
(
z
N
^
,
t
N
,
θ
)
\mathbf{a}_t(t_N)=\mathbf{a}(t_N)f(\hat{\mathbf{z}_{N}}, t_N,\theta)
at(tN)=a(tN)f(zN^,tN,θ)
则可得:
a
t
(
t
N
−
1
)
=
d
L
d
t
N
−
1
=
a
t
(
t
N
)
−
∫
t
N
t
N
−
1
a
(
t
)
∂
f
(
z
^
(
t
)
,
t
,
θ
)
∂
t
d
t
(9)
\mathbf{a}_t(t_{N-1})=\frac{dL}{dt_{N-1}}=\mathbf{a}_t(t_N)-\int_{t_N}^{t_{N-1}}\mathbf{a}(t)\frac{\partial f(\hat{\mathbf{z}}(t),t,\theta)}{\partial t}dt\tag{9}
at(tN−1)=dtN−1dL=at(tN)−∫tNtN−1a(t)∂t∂f(z^(t),t,θ)dt(9)
参考
Chen R, Rubanova Y, Bettencourt J and Duvenaud D. Neural Ordinary Differential Equations(PDF). NeurIPS 2018. ↩︎
Neural Ordinary Differential Equations(Jupyter notebook). ↩︎



















 5136
5136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











