






Takumi Shibata 和 Yuichi Miyamura
德勤分析研发部,德勤日本有限公司
{takumi.shibata, yuichi.miyamura}@tohmatsu.co.jp
摘要
最近大型语言模型(LLMs)的进步使得零样本自动作文评分(AES)成为可能,为减少相对于人工评分的作文评分成本和工作量提供了有希望的方法。然而,大多数现有的零样本方法依赖于LLMs直接生成绝对分数,这通常由于模型偏差和评分不一致而与人类评估结果存在差异。为了解决这些局限性,我们提出了基于LLM的比较作文评分(LCES),这是一种将AES公式化为配对比较任务的方法。具体而言,我们指示LLMs判断两篇作文中哪一篇更好,收集许多这样的比较,并将它们转换为连续分数。考虑到可能的比较数量随着作文数量的平方增长,我们通过使用RankNet有效地将LLM偏好转换为标量分数来提高可扩展性。使用AES基准数据集进行的实验表明,LCES在保持计算效率的同时,在准确性方面优于传统的零样本方法。此外,LCES在不同的LLM骨干网络上表现出鲁棒性,突显了其在实际零样本AES中的适用性。
1 引言
自动作文评分(AES)旨在使用自然语言处理和机器学习技术评估书面作文的质量。AES因其作为降低相对于人工评分的成本和确保公平性的手段而备受关注(Uto, 2021;Do 等人,2023)。
大多数传统AES方法集中在特定提示的方法上 1 { }^{1} 1,这些方法针对每个作文提示训练机器学习模型或神经网络(Alikaniotis 等人,2016;Dong 等人,2017;Yang 等人,2020;Xie 等人,2022;Shibata 和 Uto,2022;Wang
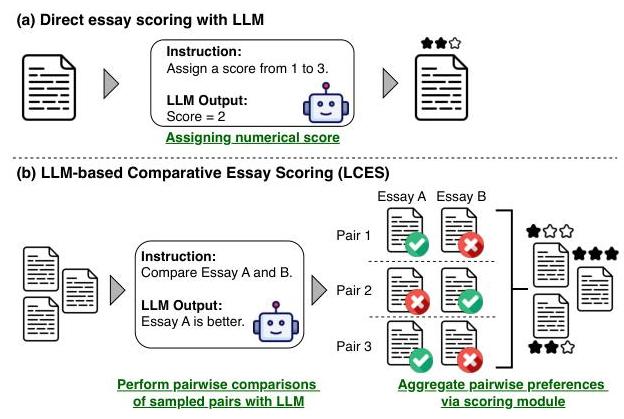
图1:(a) 使用LLMs直接评分和(b) 我们提出的LCES框架之间的比较。
和 Liu,2025)。然而,这种方法需要为每个提示收集大量的评分作文,导致巨大的成本。为了解决这个问题,最近的研究提出了利用领域适应或领域泛化技术的跨提示AES方法(Ridley 等人,2021;Chen 和 Li,2023;Do 等人,2023;Chen 和 Li,2024;Li 和 Pan,2025)。在这些技术中,模型在源提示的评分作文上进行训练,并在不同的目标提示上进行评估。尽管这些方法即使在目标提示的评分作文很少或没有的情况下仍能保持高评分准确性,但它们仍然需要一定数量的评分作文数据用于训练,未能解决满足数据需求的基本挑战。
与此同时,大型语言模型(LLMs)最近在零样本设置的各种自然语言处理任务中展示了显著的能力(Kojima 等人,2022),促使人们努力将其应用于无需使用评分作文的AES。典型的零样本AES方法指示一个LLM结合评分标准和作文生成数值分数(Mizumoto 和 Eguchi,2023)。一种更先进的方法首先使用LLMs将原始评分标准转换为特质级评分标准,然后使用LLMs独立预测每个特质的分数,最后汇总这些分数以估计总分(Lee 等人,2024)。尽管这些方法很有前景,但它们仍然存在直接生成分数的一些局限性。它们往往对LLM提示的措辞敏感,并容易受到模型偏差的影响,经常表现出与人类评分者不一致的评分行为(Zheng 等人,2023;Liu 等人,2024;Mansour 等人,2024;Li 等人,2025)。
为了解决上述问题,我们探索了一种替代的AES公式。我们不是预测绝对分数,而是指示LLM执行配对比较,其中确定两篇作文中较好的那一篇。这种方法受到最近基于LLM的自然语言生成(Liu 等人,2024;Liusie 等人,2024a)、对话系统(Park 等人,2024)和信息检索(Qin 等人,2024)评估的启发,其中配对比较已显示出更强的人类偏好一致性。尽管它具有前景,但在AES文献中配对比较仍很大程度上未被探索。
在此背景下,我们提出了基于LLM的比较作文评分(LCES),这是一个新颖的零样本AES框架,首先使用LLMs收集配对比较,然后估计连续作文分数。如图1所示,LCES与传统的LLM评分不同,从直接分数生成转向相对偏好建模。为了将这种方法扩展到大型作文数据集,我们采用了RankNet(Burges 等人,2005),这允许从配对比较中高效训练,而无需穷举所有作文对。这缓解了通常在配对比较中看到的项目数量的二次复杂度(Liusie 等人,2024b)。
通过使用标准AES基准数据集进行的全面实验,我们证明LCES显著优于现有的零样本评分方法。此外,LCES对LLM的选择具有鲁棒性,几乎可以适用于任何模型,使其非常适合实际部署。
本工作的贡献总结如下:(1)我们引入了第一个基于LLM生成的配对比较的AES框架,解决了直接分数生成的关键局限性。(2)我们利用RankNet将LLM生成的偏好转换为连续分数,
实现了准确且计算高效的零样本AES。(3)广泛的实验证实LCES优于传统的零样本AES基线,并在不同类型的LLMs中表现出鲁棒性。
2 相关工作
自动作文评分。早期的AES系统大多是特定提示的,开始时采用手工特征模型(Yannakoudakis 等人,2011),后来采用神经网络(Dong 等人,2017;Xie 等人,2022)。因为为每个新提示收集评分作文是昂贵的,因此提出了跨提示方法来训练能够在提示间泛化的模型(Ridley 等人,2020;Chen 和 Li,2023,2024)。最近,使用LLMs的零样本AES已经出现(Mizumoto 和 Eguchi,2023;Yancey 等人,2023;Wang 等人,2024;Mansour 等人,2024;Lee 等人,2024),能够在不使用评分作文的情况下生成分数。Mizumoto 和 Eguchi(2023)使用OpenAI的text-davinci-003根据评分标准和作文内容评分。在一个名为多特质规范(MTS)的零样本框架中,Lee 等人(2024)指示一个LLM生成特质级评分标准,然后用它们通过单独评分每个特质并汇总结果来评估作文。Mansour 等人(2024)表明LLM生成的分数对给模型的指令高度敏感,引发了对其可靠性的担忧。虽然零样本AES提供了一个有希望的方向,但其评分准确性仍然落后于监督的特定提示和跨提示方法。
基于LLM的评估。随着LLMs零样本能力的增长,LLM-as-a-judge范式(Zheng 等人,2023)作为一种通用框架获得了关注,用于在评估任务中使用LLMs。尽管直接分数生成很常见,但它通常遭受LLM提示敏感性(Li 等人,2025)和与人类判断不一致的问题(Liu 等人,2024)。为了提高可靠性,最近在自然语言生成(Liu 等人,2024;Liusie 等人,2024a)、对话系统(Park 等人,2024)和信息检索(Qin 等人,2024)方面的研究指示LLMs进行配对比较,选择两个候选者中更好的那个。与绝对评分相比,这种方法要求LLMs进行较少的推理步骤,并产生更一致和更符合人类判断的结果。然而,它在AES中仍
未得到充分探索。
评分比较。将配对比较转化为连续分数,这可以解释为解释观察到的比较的项目质量潜在测量值,已被广泛研究。Elo评分系统(Elo,1978)根据比赛结果迭代更新分数。Bradley-Terry模型(Bradley 和 Terry,1952)使用项目之间潜在分数的差异估计获胜概率,这些潜在分数通过最大化观察到的比较的可能性推断出来。RankNet(Burges 等人,2005)通过神经配对损失函数从输入特征学习潜在分数扩展了这一想法。我们使用RankNet将LLM生成的作文比较转化为潜在分数,实现准确且计算高效的零样本AES。
3 提出的方法
我们从一组未评分的作文集合 D = { x i } i = 1 N \mathcal{D}=\left\{x_{i}\right\}_{i=1}^{N} D={xi}i=1N开始,其中 x i x_{i} xi表示第 i i i篇作文, N N N是作文总数。LCES的目标是为每篇作文 x i x_{i} xi估计一个潜在分数 s ^ i \hat{s}_{i} s^i,代表其在集合 D \mathcal{D} D内的相对质量。根据评估目标,估计的分数 s ^ i \hat{s}_{i} s^i可以转换为排名 r ^ i \hat{r}_{i} r^i或与预定义评分标准一致的分数 y ^ i \hat{y}_{i} y^i。
LCES包含三个主要步骤:(1) 配对比较生成:从 D \mathcal{D} D中采样作文对,并使用LLM根据给定的评分标准判断哪篇作文更好,或者它们质量相同;(2) 潜在分数估计:在比较数据集上训练RankNet模型,为每篇作文估计潜在分数 s ^ i \hat{s}_{i} s^i;(3) 输出转换:根据评估目标将潜在分数 s ^ i \hat{s}_{i} s^i转换为排名 r ^ i \hat{r}_{i} r^i或分数 y ^ i \hat{y}_{i} y^i。以下小节详细描述了每个步骤。
3.1 配对比较生成
为了生成配对比较,我们使用了一个LLM提示模板 T \mathcal{T} T,该模板指导LLM根据给定的评分标准评估两篇作文。简化版的这个模板如图2所示,完整版可以在附录A中找到。给定作文提示 p p p、评分标准 r r r和两篇作文 x i x_{i} xi和 x j x_{j} xj,我们通过将每个输入插入模板中相应的占位符来构造查询 T ( p , r , x i , x j ) \mathcal{T}\left(p, r, x_{i}, x_{j}\right) T(p,r,xi,xj)。具体来说,占位符、、和分别替换为
| LLM提示模板 T \mathcal{T} T |
|---|
| # 指令: |
| 阅读以下两篇作文并根据评分标准指南进行评估。然后,指出哪篇作文整体更好。如果两篇作文都被认为得分相同,请评价为“平局”。 |
| # 提示: |
| # 评分标准指南: |
| # 作文1: |
| # 作文2: |
| 提供你的推理和最终决定。 |
| 推理: (此处填写你的推理) |
| 决定: (选择"Essay 1", “Essay 2”, 或 “tie”)。 |
图2:用于配对作文比较的简化LLM提示模板
T
\mathcal{T}
T。
分别为
p
,
r
,
x
i
p, r, x_{i}
p,r,xi和
x
j
x_{j}
xj。为了提高比较的可靠性和可解释性,我们使用了链式思维提示(Wei et al., 2022)。这鼓励LLM在做出最终决定之前解释其推理过程。对于被判断为更好的作文,LLM输出一个分类标签
w
i
j
w_{ij}
wij,该标签可以是"Essay 1"、“Essay 2"或"tie”。我们将此转换为一个数字标签
c
i
j
c_{ij}
cij,分别为"Essay 1"、"Essay 2"和"tie"分配1、0和0.5的分数。
LLMs对两篇作文呈现顺序可能很敏感(Zheng et al., 2023)。为了减少这种位置偏差,我们对每对作文进行两次查询。一次查询按 ( x i , x j ) (x_i, x_j) (xi,xj)呈现作文,另一次按 ( x j , x i ) (x_j, x_i) (xj,xi)呈现。设 c i j c_{ij} cij为第一次查询的数字标签, c j i c_{ji} cji为第二次查询的标签。我们定义最终去偏标签 c ~ i j \tilde{c}_{ij} c~ij如下:
c ~ i j = { c i j 如果 c i j = 1 − c j i 0.5 否则 \tilde{c}_{ij}= \begin{cases}c_{ij} & \text { 如果 } c_{ij}=1-c_{ji} \\ 0.5 & \text { 否则 }\end{cases} c~ij={cij0.5 如果 cij=1−cji 否则
如果两次结果一致,则保留原始标签。如果结果相互矛盾或其中一个表明平局,则将这对视为平局。
为了应用这一比较过程,我们构建了一组作文对。设 I = { ( i , j ) ∣ \mathcal{I}=\{(i, j) \mid I={(i,j)∣ i ≠ j , i , j ∈ { 1 , 2 , … , N } } i \neq j, i, j \in\{1,2, \ldots, N\}\} i=j,i,j∈{1,2,…,N}}为所有可能的有序作文对的集合。由于比较所有 N ( N − 1 ) N(N-1) N(N−1)对在计算上代价高昂,我们随机抽取一个子集 I s ⊂ I \mathcal{I}_s \subset \mathcal{I} Is⊂I,其中包含 M M M对,其中 M ≪ N ( N − 1 ) M \ll N(N-1) M≪N(N−1)。对于每个抽样对,我们按照上述方法获得一个去偏标签 c ~ i j \tilde{c}_{ij} c~ij。这产生了配对比较数据集 D pair = { ( x i , x j , c ~ i j ) ∣ ( i , j ) ∈ I s } \mathcal{D}_{\text {pair }}=\left\{\left(x_{i}, x_{j}, \tilde{c}_{i j}\right) \mid(i, j) \in \mathcal{I}_{s}\right\} Dpair ={(xi,xj,c~ij)∣(i,j)∈Is},用于训练RankNet模型。
3.2 潜在分数估计
使用在第3.1节中生成的配对比较数据集
D
pair
\mathcal{D}_{\text {pair }}
Dpair ,我们为每篇作文
x
i
x_{i}
xi估计一个潜在分数
s
^
i
\hat{s}_{i}
s^i。为此,我们采用
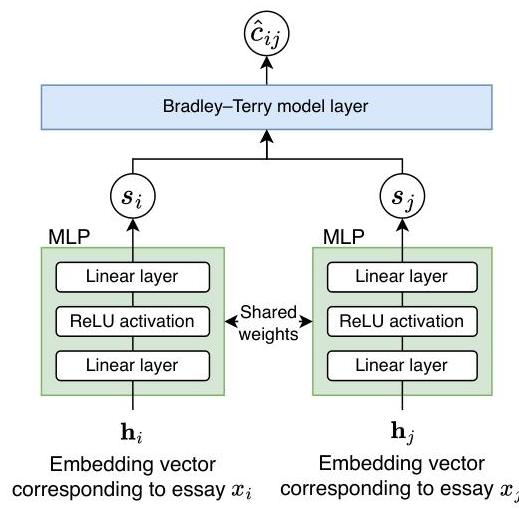
图3:用于从配对比较中估计潜在作文分数 s ^ i \hat{s}_{i} s^i的RankNet模型架构。
RankNet(Burges 等人,2005),这是一种设计用来从配对偏好中学习潜在分数的神经模型。
如图3所示,RankNet使用两个共享权重的平行多层感知器(MLP)。它们构成一个评分模型,记为 f f f,将输入作文表示映射为标量分数。具体来说,我们首先使用任何合适的文本嵌入模型将每篇作文 x i x_{i} xi转换为嵌入向量 h i \boldsymbol{h}_{i} hi,然后计算其分数为 s i = f ( h i ) s_{i}=f\left(\boldsymbol{h}_{i}\right) si=f(hi)。每个MLP由两个线性层组成,在第一层后应用ReLU激活(Agarap,2019)。
给定两篇作文 x i x_{i} xi和 x j x_{j} xj,模型使用共享网络 f f f计算分数 s i s_{i} si和 s j s_{j} sj,并估计 x i x_{i} xi优于 x j x_{j} xj的概率为:
c ^ i j = σ ( s i − s j ) = 1 1 + exp ( − ( s i − s j ) ) \hat{c}_{i j}=\sigma\left(s_{i}-s_{j}\right)=\frac{1}{1+\exp \left(-\left(s_{i}-s_{j}\right)\right)} c^ij=σ(si−sj)=1+exp(−(si−sj))1
这里, σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示sigmoid函数。这种公式与Bradley-Terry模型(Bradley 和 Terry,1952)相呼应,能够对配对偏好进行概率建模。
模型训练的目标是最小化预测偏好 c ^ i j \hat{c}_{i j} c^ij与去偏目标标签 c ~ i j \tilde{c}_{i j} c~ij之间的差异。我们使用二元交叉熵损失 L \mathcal{L} L:
L = − 1 M ∑ ( i , j ) ∈ I n [ c ~ i j log c ^ i j + ( 1 − c ^ i j ) log ( 1 − c ^ i j ) ] \mathcal{L}=-\frac{1}{M} \sum_{(i, j) \in \mathcal{I}_{n}}\left[\tilde{c}_{i j} \log \hat{c}_{i j}+\left(1-\hat{c}_{i j}\right) \log \left(1-\hat{c}_{i j}\right)\right] L=−M1(i,j)∈In∑[c~ijlogc^ij+(1−c^ij)log(1−c^ij)]
设 S = { s i } i = 1 N \mathcal{S}=\left\{s_{i}\right\}_{i=1}^{N} S={si}i=1N表示潜在作文分数的集合。通过最小化损失函数,得到优化后的分数 S ^ = { s ^ i } i = 1 N \hat{\mathcal{S}}=\left\{\hat{s}_{i}\right\}_{i=1}^{N} S^={s^i}i=1N: S ^ = arg min S L \hat{\mathcal{S}}=\arg \min _{\mathcal{S}} \mathcal{L} S^=argminSL。
3.3 输出转换
估计的潜在分数 s ^ i \hat{s}_{i} s^i可以根据评估目标转换为标准AES输出,例如数值分数或排名。
为了生成范围在 [ y min , y max ] \left[y_{\min }, y_{\max }\right] [ymin,ymax]内的分数 y ^ i \hat{y}_{i} y^i,我们对潜在分数进行线性变换:
y ^ i = s ^ i − s min s max − s min × ( y max − y min ) + y min \hat{y}_{i}=\frac{\hat{s}_{i}-s_{\min }}{s_{\max }-s_{\min }} \times\left(y_{\max }-y_{\min }\right)+y_{\min } y^i=smax−smins^i−smin×(ymax−ymin)+ymin
其中 s min = min i s ^ i s_{\min }=\min _{i} \hat{s}_{i} smin=minis^i和 s max = max i s ^ i s_{\max }=\max _{i} \hat{s}_{i} smax=maxis^i是所有作文中最低和最高的潜在分数。如果评分标准定义了离散分数级别,结果 y ^ i \hat{y}_{i} y^i可以选择四舍五入到最接近的有效级别。
或者,可以通过按潜在分数 s ^ i \hat{s}_{i} s^i降序排序作文来获得排名 r ^ i \hat{r}_{i} r^i。这在只需要相对作文质量的场景中是有用的。
4 实验
我们通过使用AES基准数据集的实验来经验性地评估LCES的有效性,重点关注评分性能和与现有方法的比较。
4.1 数据集
我们使用了以下两个基准数据集,这些数据集在AES研究中常用(Taghipour 和 Ng,2016;Chen 和 Li,2023;Lee 等人,2024;Wang 等人,2024):
ASAP(自动化学生评估奖)是由Kaggle竞赛发布的数据集
2
{ }^{2}
2。它包括八个不同提示下的12,978篇作文,每篇都有人类评分。
TOEFL11 是由非母语英语考生参加TOEFL iBT考试所写的一系列作文数据集(Blanchard 等人,2013)。它包含了八个不同提示下的12,100篇作文,每篇都有人类评分。
表1总结了ASAP和TOEFL11数据集的统计信息。
4.2 基准方法
我们采用了以下两种零样本AES方法作为与LCES比较的基准:
2
{ }^{2}
2 https://www.kaggle.com/c/asap-aes
表1:ASAP和TOEFL11数据集的统计信息。
l
/
m
/
h
\mathrm{l} / \mathrm{m} / \mathrm{h}
l/m/h 表示低/中/高。
| 数据集 | 提示 | 作文数量 | 平均长度 | 得分范围 |
|---|---|---|---|---|
| ASAP | 1 | 1,783 | 427 | 2 − 12 2-12 2−12 |
| 2 | 1,800 | 432 | 1 − 6 1-6 1−6 | |
| 3 | 1,726 | 124 | 0 − 3 0-3 0−3 | |
| 4 | 1,772 | 106 | 0 − 3 0-3 0−3 | |
| 5 | 1,805 | 142 | 0 − 4 0-4 0−4 | |
| 6 | 1,800 | 173 | 0 − 4 0-4 0−4 | |
| 7 | 1,569 | 206 | 0 − 30 0-30 0−30 | |
| 8 | 723 | 725 | 0 − 60 0-60 0−60 | |
| TOEFL11 | 1 | 1,656 | 342 | l/m/h |
| 2 | 1,562 | 361 | l/m/h | |
| 3 | 1,396 | 346 | l/m/h | |
| 4 | 1,509 | 340 | l/m/h | |
| 5 | 1,648 | 361 | l/m/h | |
| 6 | 960 | 360 | l/m/h | |
| 7 | 1,686 | 339 | l/m/h | |
| 8 | 1,683 | 344 | l/m/h |
Vanilla. 一种直接评分方法,LLM为每篇作文生成一个与评分标准相符的分数而不进行配对比较。它使用链式思维提示来激发评分前的推理。我们使用了与Lee等人(2024)相同的LLM提示和超参数。
MTS. 如第二节所述,MTS(Lee等人,2024)是一种最先进的零样本AES框架。原始实现使用GPT-3.5从原始评分标准生成特质级评分标准。在我们的实验中,由于GPT-3.5不再可用,我们改用了GPT-4o。所有其他LLM提示和超参数都遵循原始实现。
4.3 实验设置
LLMs. 我们使用了五个不同的LLMs进行评估,分别是Mistral-7B (-instructv0.2)(Jiang等人,2023)、Llama-3.2-3B (-Instruct)、Llama-3.1-8B (-Instruct)(Grattafiori等人,2024)、GPT-4o-mini (-2024-07-18)和GPT-4o (-202408-06)(OpenAI,2024)。所有LLM推理都在温度设置为0.1的情况下进行。
实现细节。用于构建 D pair \mathcal{D}_{\text {pair }} Dpair 数据集的采样配对比较数量 M M M设置为5,000。作文嵌入向量 h i \boldsymbol{h}_{i} hi使用OpenAI的text-embedding-v3-large模型生成。使用替代嵌入模型获得的结果见附录B。RankNet模型使用Adam(Kingma 和 Ba,2015)优化器进行了100个epoch的训练,学习率为0.001。完整的超参数集见附录C。
评分标准。对于ASAP数据集内的配对比较,我们使用了数据集中提供的原始评分标准。对于TOEFL11数据集,与先前的研究一致(Mizumoto 和 Eguchi,2023;Lee 等人,2024),我们使用了IELTS Task 2 Writing Band Descriptors作为评分标准。
评估指标。我们使用AES中的两个标准指标来评估模型性能,即二次加权kappa(QWK)(Cohen,1960)和Spearman等级相关系数。遵循先前工作的常见做法(Taghipour 和 Ng,2016;Alikaniotis 等人,2016;Dong 等人,2017;Do 等人,2023),我们主要报告QWK。Spearman相关性的结果见附录D。对于ASAP数据集,我们跟随Lee 等人(2024)的做法,从每个提示中随机抽取10%的作文进行评估。对于TOEFL11,我们使用了预先定义的测试分割,包括八个提示下的1,100篇作文。
评分策略。对于基于QWK的评估,我们将预测分数 y ^ i \hat{y}_{i} y^i四舍五入以与ASAP数据集中每个提示的分数范围对齐。对于TOEFL11数据集,我们首先通过第3.3节中描述的线性变换将潜在分数转换为[1,5]尺度,然后使用2.25和3.75的阈值将它们映射到低/中/高类别,遵循先前研究(Blanchard 等人,2013;Lee 等人,2024)中使用的方法。
4.4 结果与讨论
表2中的结果显示,LCES在大多数情况下优于MTS和Vanilla,实现了更高的平均QWK分数,特别是在ASAP数据集上的提升尤为显著。唯一的例外是TOEFL11与Mistral-7B,LCES的表现不如MTS。正如第5.2节所示,Mistral-7B在作文顺序反转时表现出较高的不一致性(51.4 %),表明它难以可靠地识别更好的作文。值得注意的是,Mistral-7B在TOEFL11的MTS设置下取得了最高性能,超过了更近期或更大的模型如GPT-4o和Llama-3.1-8B。这表明MTS和LCES可能偏向不同的模型能力。尽管LCES在使用Mistral-7B时表现不如MTS,但它与其他所有LLMs一致地优于MTS,凸显了LCES框架的普遍有效性。
表2:ASAP和TOEFL11中每个作文提示的QWK分数。粗体表示每个提示的最佳方法。P1-8指代Prompt 1至Prompt 8。
| 数据集 | 模型 | 方法 | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ASAP | Mistral-7B | Vanilla | 0.429 | 0.439 | 0.387 | 0.518 | 0.576 | 0.534 | 0.276 | 0.209 | 0.429 |
| MTS | 0.546 | 0.479 | 0.481 | 0.683 | 0.706 | 0.519 | 0.501 | 0.175 | 0.511 | ||
| LCES | 0.600 | 0.603 | 0.698 | 0.614 | 0.729 | 0.792 | 0.591 | 0.315 | 0.617 | ||
| Llama-3.2-3B | Vanilla | 0.254 | 0.405 | 0.410 | 0.009 | 0.397 | 0.330 | 0.438 | 0.276 | 0.315 | |
| MTS | 0.197 | 0.452 | 0.353 | 0.507 | 0.460 | 0.462 | 0.146 | 0.190 | 0.346 | ||
| LCES | 0.555 | 0.608 | 0.647 | 0.603 | 0.717 | 0.756 | 0.580 | 0.612 | 0.635 | ||
| Llama-3.1-8B | Vanilla | 0.129 | 0.023 | 0.243 | 0.550 | 0.301 | 0.341 | 0.006 | − 0.042 -0.042 −0.042 | 0.194 | |
| MTS | 0.516 | 0.483 | 0.284 | 0.461 | 0.479 | 0.378 | 0.328 | 0.199 | 0.391 | ||
| LCES | 0.669 | 0.599 | 0.662 | 0.651 | 0.710 | 0.707 | 0.727 | 0.636 | 0.670 | ||
| GPT-4o-mini | Vanilla | 0.106 | 0.402 | 0.314 | 0.602 | 0.577 | 0.470 | 0.425 | 0.517 | 0.426 | |
| MTS | 0.472 | 0.386 | 0.448 | 0.552 | 0.708 | 0.419 | 0.479 | 0.412 | 0.485 | ||
| LCES | 0.537 | 0.602 | 0.679 | 0.638 | 0.709 | 0.737 | 0.614 | 0.521 | 0.630 | ||
| GPT-4o | Vanilla | 0.216 | 0.498 | 0.447 | 0.681 | 0.710 | 0.571 | 0.535 | 0.411 | 0.509 | |
| MTS | 0.380 | 0.547 | 0.513 | 0.621 | 0.500 | 0.515 | 0.421 | 0.432 | 0.491 | ||
| LCES | 0.531 | 0.592 | 0.702 | 0.626 | 0.747 | 0.766 | 0.669 | 0.593 | 0.653 | ||
| Mistral-7B | Vanilla | 0.235 | 0.128 | 0.174 | 0.106 | 0.050 | 0.046 | 0.106 | 0.222 | 0.133 | |
| MTS | 0.634 | 0.496 | 0.571 | 0.607 | 0.603 | 0.573 | 0.578 | 0.689 | 0.594 | ||
| LCES | 0.415 | 0.514 | 0.663 | 0.519 | 0.508 | 0.496 | 0.532 | 0.644 | 0.536 | ||
| Llama-3.2-3B | Vanilla | 0.184 | 0.117 | 0.291 | 0.195 | 0.149 | 0.206 | 0.067 | 0.149 | 0.170 | |
| MTS | 0.361 | 0.389 | 0.454 | 0.456 | 0.341 | 0.364 | 0.323 | 0.299 | 0.373 | ||
| LCES | 0.615 | 0.542 | 0.709 | 0.678 | 0.582 | 0.479 | 0.555 | 0.708 | 0.608 | ||
| TOEFL11 | Llama-3.1-8B | Vanilla | − 0.036 -0.036 −0.036 | 0.148 | 0.003 | 0.021 | 0.019 | − 0.023 -0.023 −0.023 | − 0.029 -0.029 −0.029 | 0.063 | 0.021 |
| MTS | 0.368 | 0.408 | 0.407 | 0.311 | 0.351 | 0.285 | 0.335 | 0.379 | 0.356 | ||
| LCES | 0.597 | 0.570 | 0.727 | 0.697 | 0.652 | 0.550 | 0.558 | 0.717 | 0.633 | ||
| GPT-4o-mini | Vanilla | 0.094 | 0.202 | 0.182 | 0.107 | 0.041 | 0.101 | 0.126 | 0.124 | 0.122 | |
| MTS | 0.439 | 0.529 | 0.548 | 0.521 | 0.603 | 0.501 | 0.536 | 0.591 | 0.533 | ||
| LCES | 0.655 | 0.559 | 0.722 | 0.692 | 0.633 | 0.649 | 0.629 | 0.724 | 0.658 | ||
| GPT-4o | Vanilla | 0.206 | 0.208 | 0.365 | 0.189 | 0.211 | 0.245 | 0.226 | 0.252 | 0.238 | |
| MTS | 0.480 | 0.539 | 0.607 | 0.545 | 0.469 | 0.526 | 0.426 | 0.664 | 0.532 | ||
| LCES | 0.604 | 0.545 | 0.734 | 0.671 | 0.713 | 0.572 | 0.580 | 0.739 | 0.645 |
此外,LCES在各种基础LLMs上表现出强大的鲁棒性。在ASAP上,其在五个基础模型上的平均性能的标准差仅为0.021,而MTS为0.072,Vanilla为0.122。在TOEFL1------
1上,LCES同样表现出较低的变异性,模型间的标准差为0.048,优于MTS(0.106)和Vanilla(0.079)。这些较低的模型间变异表明,无论选择何种基础模型,LCES都能保持稳定,而MTS和Vanilla则波动较大,使得它们的表现更难以预测。
总之,LCES在多种设置下表现出高零样本准确性,并且对LLM选择具有鲁棒性,能够可靠地随着模型规模扩展。即使当模型难以区分作文质量时,如Mis
------tral-7B在TOEFL11上的表现,LCES仍然保持竞争力,支持其在现实世界AES场景中的实用性。
5 分析
我们进行了一系列分析,以进一步考察所提出的
表3:LCES与监督学习基线在所有ASAP提示下的平均QWK分数。
| 方法 | 平均QWK |
|---|---|
| 特定提示 | |
| NPCR (Xie 等人, 2022) | 0.792 |
| BERT-base-uncased (Devlin 等人, 2019) | 0.740 |
| RoBERTa-base (Liu 等人, 2019) | 0.743 |
| 跨提示 | |
| PAES (Ridley 等人, 2020) | 0.678 |
| PMAES (Chen 和 Li, 2023) | 0.658 |
| 零样本 | |
| LCES (Llama-3.1-8B) | 0.670 |
框架除整体性能指标之外的效果和特性。
5.1 与监督模型的比较
尽管LCES是一种零样本方法,我们还在ASAP数据集上将其与几个监督学习基线进行比较,如表3所示。我们包括了特定提示和跨提示模型。特定提示模型在来自单一提示的90%的作文上进行训练,并在剩余的10%上进行评估,使用
表4:在每个数据集的所有提示中计算的,当作文对顺序反转时,LLM判断发生变化的平均百分比。
| 模型 | ASAP (%) | TOEFL11 (%) |
|---|---|---|
| Mistral-7B | 42.8 | 51.4 |
| Llama-3.2-3B | 28.8 | 39.0 |
| Llama-3.1-8B | 21.6 | 23.8 |
| GPT-4o-mini | 13.8 | 10.5 |
| GPT-4o | 10.4 | 17.0 |
相同的评估分割描述于第4.3节。跨提示模型在除了待评估提示外的所有提示的作文上进行训练,并同样在目标提示的10%分割上进行评估。
具体来说,我们将NPCR(Xie等人,2022)作为对照,它据报道在ASAP上提供了最先进的结果,以及在相同特定提示分割上微调的BERT(Devlin等人,2019)和RoBERTa(Liu等人,2019)。我们还包含了PAES(Ridley等人,2020)和PMAES(Chen和Li,2023),这两个是强大的跨提示基线。
如表3所示,使用Llama-3.1-8B的LCES在零样本实验中所有测试的LLMs中实现了最高的整体性能,获得了与几个监督学习模型相当的QWK分数。虽然NPCR、BERT和RoBERTa仍然优于LCES,但与之前报告的零样本方法相比,性能差距已显著缩小。此外,LCES在强跨提示基线PAES和PMAES上取得了相当的性能 3 { }^{3} 3。这种水平的性能在零样本AES方法中是前所未有的。这些结果突显了在没有评分作文的情况下该方法的有效性。
5.2 位置偏差
我们通过计算当作文顺序反转时配对比较发生变化的百分比来衡量位置偏差的影响。表4显示了每个LLM在用于构建 D pair \mathcal{D}_{\text {pair }} Dpair 的相同比较对上的不一致性率,针对ASAP和TOEFL11。正如预期的那样,较大的模型如GPT-4o表现出较低的不一致性,表明对位置偏差更强的鲁棒性。相比之下,Mistral-7B在TOEFL11上表现出特别高的
表5:有和无位置偏差校正的ASAP和TOEFL11的平均QWK。
| 数据集 | 模型 | 平均QWK | |
|---|---|---|---|
| 无去偏 | 去偏 | ||
| ASAP | Mistral-7B | 0.611 | 0.617 |
| Llama-3.2-3B | 0.630 | 0.635 | |
| Llama-3.1-8B | 0.661 | 0.670 | |
| GPT-4o-mini | 0.633 | 0.630 | |
| GPT-4o | 0.649 | 0.653 | |
| TOEFL11 | Mistral-7B | 0.510 | 0.536 |
| Llama-3.2-3B | 0.588 | 0.608 | |
| Llama-3.1-8B | 0.628 | 0.633 | |
| GPT-4o-mini | 0.664 | 0.658 | |
| GPT-4o | 0.648 | 0.645 |
不一致性率为51.4%,表明对作文顺序高度敏感。
为了评估位置偏差校正的效果,我们比较了有和无位置偏差校正的平均QWK分数。如表5所示,不一致性率较高的模型,如Mistral-7B和Llama-3.2-3B,往往从校正中受益更多。这些结果表明,所提出的校正方法通常对不一致性较高的模型更有效,而对于已经表现出低不一致性的模型,其效果有限。
5.3 潜在分数转换方法的比较
我们通过比较我们的RankNet方法与Bradley-Terry模型和Elo评级系统来评估不同潜在分数转换技术的有效性,后者是第2节中描述的代表性方法。该实验考察了从50到10,000变化的配对比较数量 M M M如何影响基于QWK的ASAP和TOEFL11数据集上的评分准确性。鉴于其在这两个数据集上的稳健表现,该实验采用GPT-4o作为LLM。
图4展示了性能趋势。随着 M M M的增加,所有方法的准确性都得到了提高,突显了额外偏好数据的好处。其中,RankNet方法在两个数据集的整个 M M M范围内始终优于Bradley-Terry模型和Elo评级系统。值得注意的是,即使在比较次数较少的情况下(例如, M = 50 M=50 M=50或 M = 100 M=100 M=100),RankNet也能实现高QWK分数,这在数据有限的情况下表现尤为强劲。这一优势可能源于RankNet能够直接从作文中结合文本特征
3
{ }^{3}
3由于GPU限制(RTX 4090),PMAES以较小的批量运行,可能导致性能下降。
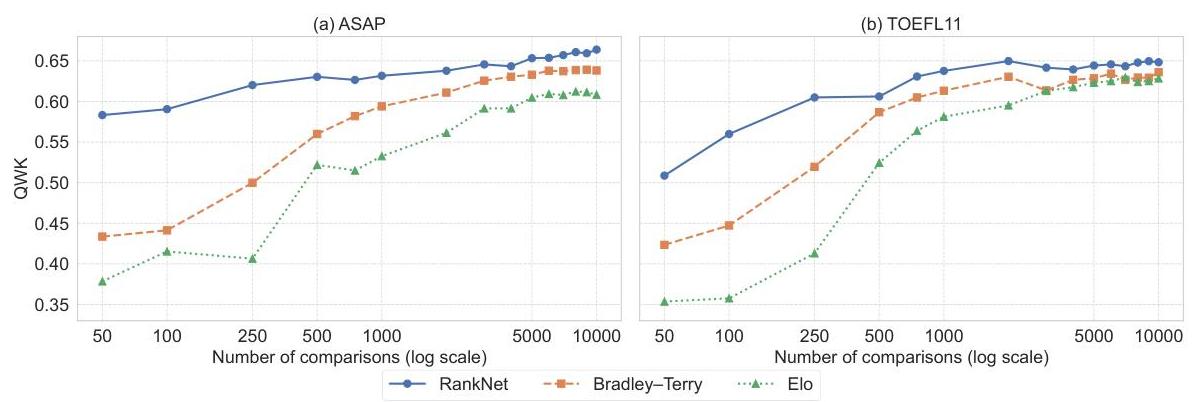
图4:配对比较次数(对数尺度)与QWK分数之间的关系。(a) ASAP数据集。(b) TOEFL11数据集。
表6:在归纳和演绎设置下使用GPT-4o-mini评估的LCES的QWK分数。
| 数据集 | 设置 | P 1 \mathbf{P 1} P1 | P 2 \mathbf{P 2} P2 | P 3 \mathbf{P 3} P3 | P 4 \mathbf{P 4} P4 | P 5 \mathbf{P 5} P5 | P 6 \mathbf{P 6} P6 | P 7 \mathbf{P 7} P7 | P 8 \mathbf{P 8} P8 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| ASAP | 演绎 | 0.537 | 0.602 | 0.679 | 0.638 | 0.709 | 0.737 | 0.614 | 0.521 | 0.630 |
| 归纳 | 0.611 | 0.622 | 0.588 | 0.631 | 0.707 | 0.783 | 0.487 | 0.603 | 0.629 | |
| TOEFL11 | 演绎 | 0.655 | 0.559 | 0.722 | 0.692 | 0.633 | 0.649 | 0.629 | 0.724 | 0.658 |
| 归纳 | 0.624 | 0.613 | 0.715 | 0.617 | 0.622 | 0.615 | 0.616 | 0.707 | 0.641 |
直接从文章中获取文本特征,而基线方法仅依赖于比较结果。
这些结果表明,RankNet在基于配对的文章评分中非常有效。其卓越的准确性和更高的数据效率使其非常适合实际环境中收集广泛比较数据可能昂贵或不可行的情况。
5.4 在归纳设置下的表现
在LCES中,LLM预测的成对偏好被用来训练评分函数 f f f。当所有目标文章同时可用时,可以直接在它们之间进行比较。我们称此为演绎设置,这对应于本文贯穿使用的主实验设置。相反,在归纳设置中假设新文章必须单独评分,无需额外比较。而是应用在先前比较上训练的学习函数 f f f来进行评分估计。因为 f f f将文章嵌入映射到标量分数,因此它可以推广到新的文章,而无需进一步的成对信息。
为了模拟这种情况,我们在每个数据集(ASAP或TOEFL11)的90%文章上构造成对比较,以此训练评分函数 f f f,并用它预测剩余10%的分数。我们使用GPT-4o-mini,因其计算效率高且API成本低。
归纳设置下的QWK分数接近
演绎设置下的分数,ASAP为0.629 vs. 0.630,TOEFL11为0.641 vs. 0.658(表6)。这些结果表明
f
f
f能有效地推广到未见的文章。这种无需为新文章构建额外涉及它们的比较即可评分的能力,使LCES非常适合归纳场景。相比之下,如Bradley-Terry模型或Elo模型等模型需要为每篇文章生成新的比较,从而在归纳设置下增加了部署开销。
6 结论
在本研究中,我们提出了基于大型语言模型的比较作文评分(LCES),这是一种利用LLM驱动的成对比较来解决直接评分生成关键局限性的零样本AES框架。LCES指示LLM判断两篇作文中哪一篇更好,然后训练RankNet模型来估计连续的作文分数。
在两个基准数据集ASAP和TOEFL11上的实验结果表明,LCES在评分准确性方面始终优于现有的零样本方法。即使在比较次数有限的情况下,它仍能保持强劲表现,并对LLM的选择具有鲁棒性。此外,LCES可以在归纳设置下应用,而无需为新文章进行额外的比较。这些特性使LCES非常适合现实世界的AES应用。
局限性
尽管LCES具有优势,但它也存在一些局限性。首先,它依赖于由LLM生成的成对偏好标签,这些标签可能包含噪声或不一致之处。这些不完美的标签直接影响到所学评分函数 f f f的质量。
其次,尽管LCES在提供足够数量的比较 M M M时往往能可靠运行,但如何确定适当的 M M M值尚不清楚。这限制了系统控制评分质量的能力。
第三,LCES通过线性变换将潜在相对分数映射到绝对尺度,假定采样比较覆盖了整个分数范围。如果缺少低分或高分作文,该变换可能会产生不准确的绝对分数。虽然排名表现不会受到影响,但这可能会降低在需要精确或特定评分标准的任务中与人类判断的一致性。
最后,LCES的零样本性质意味着,在没有标注数据的情况下,其性能无法定量评估。对于实际部署,这需要手动评分一部分作文以建立评估基准。
致谢
这项研究是在德勤日本有限公司内部项目的一部分中进行的。作者要感谢Tomoaki Geka和Tomotake Kozu提供的有益讨论和支持。
伦理声明
LCES的主要伦理考虑在于其依赖LLM进行成对作文比较。LLM可能会继承并延续其广泛训练数据中存在的偏差。虽然我们的方法包括一个针对位置偏差的去偏步骤,但其他潜在偏差可能会影响在不同学生人口统计或写作风格间的评估公平性。我们建议在任何高风险部署LCES之前进行进一步的此类偏差审计。
本研究中的实验使用了公开可用和已建立的基准数据集(ASAP和TOEFL11)。本研究中未收集或使用任何新的个人可识别信息。
我们设想LCES作为一种辅助工具,以支持人工评分者,减少他们的工作量并可能提高一致性,而不是作为
完全替代人类判断的方法。鉴于其零样本性质,在将其应用于实际教育评估之前,对特定目标提示和评分标准进行彻底验证是至关重要的,以确保其可靠性并防止对学生造成潜在的负面影响。
参考文献
Abien Fred Agarap. 2019. 使用修正线性单元(ReLU)进行深度学习。预印本,arXiv:1803.08375.
Dimitrios Alikaniotis, Helen Yannakoudakis 和 Marek Rei. 2016. 使用神经网络的自动文本评分。在《计算语言学协会第54届年会论文集》中,页码 715 − 725 715-725 715−725。
Daniel Blanchard, Joel R. Tetreault, Derrick Higgins, A. Cahill 和 Martin Chodorow. 2013. TOEFL11:非母语英语语料库。ETS研究报告系列,2013:15。
Ralph Allan Bradley 和 Milton E. Terry. 1952. 不完全区组设计的等级分析:I. 成对比较法。Biometrika, 39:324-345。
Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton 和 Greg Hullender. 2005. 使用梯度下降进行排序学习。在《机器学习国际会议第22届会议论文集》中,页码 89-96。
Yuan Chen 和 Xia Li. 2023. PMAES:跨提示自动作文评分的提示映射对比学习。在《计算语言学协会第61届年会论文集》中,页码 1489-1503。
Yuan Chen 和 Xia Li. 2024. PLAES:跨提示自动作文评分的提示泛化和层级感知学习框架。在《2024年计算语言学、语言资源与评估联合国际会议论文集》中,页码 12775-12786。
Jacob Cohen. 1960. 名义尺度的一致性系数。教育与心理测量,20:37-46。
Jacob Devlin, Ming-Wei Chang, Kenton Lee 和 Kristina Toutanova. 2019. BERT:用于语言理解的深度双向Transformer预训练。在《北美计算语言学协会第2019年会议论文集》中,页码 4171-4186。
Heejin Do, Yunsu Kim 和 Gary Geunbae Lee. 2023. 提示和特质关系感知的跨提示作文特质评分。在《计算语言学协会发现论文集》中,页码 1538-1551。
Fei Dong, Yue Zhang 和 Jie Yang. 2017. 基于注意力的递归卷积神经网络用于自动作文评分。在《第21届计算自然语言学习会议论文集》中,页码 153-162。
Arpad E. Elo. 1978. 国际象棋选手的评分,过去与现在。阿科出版社。
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad AlDahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan 和其他1人. 2024. Llama 3模型群。预印本,arXiv:2407.21783。
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix 和 William El Sayed. 2023. Mistral 7B. 预印本,arXiv:2310.06825。
Diederik P. Kingma 和 Jimmy Ba. 2015. Adam:一种随机优化方法。在《第3届国际学习表示会议论文集》中。
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo 和 Yusuke Iwasawa. 2022. 大型语言模型是零样本推理者。在《第36届神经信息处理系统国际会议论文集》中。
Sanwoo Lee, Yida Cai, Desong Meng, Ziyang Wang 和 Yunfang Wu. 2024. 释放大型语言模型在零样本作文评分中的能力。在《计算语言学协会发现论文集》中,页码 181-198。
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng 和 Huan Liu. 2025. 从生成到判断:大型语言模型作为法官的机会与挑战。预印本,arXiv:2411.16594。
Xia Li 和 Wenjing Pan. 2025. KAES:跨提示自动评分的多方面共享知识发现与对齐。在《人工智能促进协会第39届人工智能会议论文集》中,卷39,页码 24476-24484。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer 和 Veselin Stoyanov. 2019. RoBERTa:一种稳健优化的BERT预训练方法。预印本,arXiv:1907.11692。
Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vulić, Anna Korhonen 和 Nigel Collier. 2024. 与人类判断一致:大型语言模型评估器中成对偏好的作用。
在第一届语言建模会议上发表的论文。
Adian Liusie, Potsawee Manakul 和 Mark Gales. 2024a. LLM比较评估:使用大型语言模型通过成对比较进行零样本NLG评估。在《欧洲计算语言学协会第18届会议论文集》中,页码 139-151,圣朱利安斯,马耳他。
Adian Liusie, Vatsal Raina, Yassir Fathullah 和 Mark Gales. 2024b. 高效LLM比较评估:成对比较的专家产品框架。在《2024年经验方法在自然语言处理中的应用会议论文集》中,页码 6835-6855。
Watheq Ahmad Mansour, Salam Albatarni, Sohaila Eltanbouly 和 Tamer Elsayed. 2024. 大型语言模型能否自动评分书面作文的熟练程度?在《2024年计算语言学、语言资源与评估联合国际会议论文集》中,页码 27772786。
Atsushi Mizumoto 和 Masaki Eguchi. 2023. 探索使用AI语言模型进行自动作文评分的潜力。应用语言学研究方法,2(2):100050。
OpenAI. 2024. GPT-4o系统卡。预印本,arXiv:2410.21276。
ChaeHun Park, Minseok Choi, Dohyun Lee 和 Jaegul Choo. 2024. PairEval:开放领域对话评价与成对比较。预印本,arXiv:2404.01015。
Zhen Qin, Rolf Jagerman, Kai Hui 和其他人. 2024. 大型语言模型是有效的文本排名器,具有成对排名提示功能。在《计算语言学协会发现论文集》中,2024年北美计算语言学协会年会论文集,页码 1504 − 1518 1504-1518 1504−1518。
Robert Ridley, Liang He, Xinyu Dai, Shujian Huang 和 Jiajun Chen. 2020. 提示无关的作文评分器:跨提示自动作文评分的领域泛化方法。预印本,arXiv:2008.01441。
Robert Ridley, Liang He, Xin yu Dai, Shujian Huang 和 Jiajun Chen. 2021. 自动跨提示作文特质评分。在《第三十五届人工智能促进协会人工智能会议论文集》中,卷35,页码 13745-13753。
Takumi Shibata 和 Masaki Uto. 2022. 基于深度神经网络整合多维项目反应理论的解析自动作文评分。在《第29届国际计算语言学会议论文集》中,页码 2917-2926。
Kaveh Taghipour 和 Hwee Tou Ng. 2016. 神经方法的自动作文评分。在《2016年经验方法在自然语言处理中的应用会议论文集》中,页码 1882-1891。
Masaki Uto. 2021. 深度神经自动作文评分模型综述。行为计量学,48(2):1-26。
Jiong Wang 和 Jie Liu. 2025. T-MES:具有特质感知混合专家表示学习的多特质作文评分。在《第31届国际计算语言学会议论文集》中,页码 1224 − 1236 1224-1236 1224−1236。
Yupei Wang, Renfen Hu 和 Zhe Zhao. 2024. 超越一致:基于语言学知情反事实的自动作文评分方法诊断原理一致性。在《计算语言学协会发现论文集》中,2024年经验方法在自然语言处理中的应用会议论文集,页码 8906-8925。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le 和 Denny Zhou. 2022. 链式思维提示激发大语言模型中的推理。在《第36届神经信息处理系统国际会议论文集》中。
Jiayi Xie, Kaiwei Cai, Li Kong, Junsheng Zhou 和 Weiguang Qu. 2022. 基于成对对比回归的自动作文评分。在《第29届国际计算语言学会议论文集》中,页码 2724-2733。
Kevin P. Yancey, Geoffrey Laflair, Anthony Verardi 和 Jill Burstein. 2023. 使用GPT-4在CEFR量表上评分短L2作文。在《第18届创新使用NLP构建教育应用程序研讨会论文集》中,页码 576-584。
Ruosong Yang, Jiannong Cao, Zhiyuan Wen, Youzheng Wu 和 Xiaodong He. 2020. 通过微调预训练语言模型结合回归和排名增强自动作文评分性能。在《计算语言学协会发现论文集》中,2020年经验方法在自然语言处理中的应用会议论文集,页码 1560 − 1569 1560-1569 1560−1569。
Helen Yannakoudakis, Ted Briscoe 和 Ben Medlock. 2011. 新的数据集和方法用于自动分级ESOL文本。在《计算语言学协会第49届年会论文集》中,页码 180-189。
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez 和 Ion Stoica. 2023. 使用MT-bench和聊天机器人竞技场评判LLM-as-a-judge。在《第37届神经信息处理系统国际会议论文集》中。
A LLM提示
本节描述了在第3.1节比较步骤中用于从LLMs中引出成对偏好的LLM提示模板。我们为ASAP和TOEFL11数据集设计了单独的LLM提示,以反映它们的目标人群和评分标准。每个LLM提示包括定义评估者角色的系统消息和包含任务上下文、评分标准和两篇作文的用户消息。模型被指示以结构化的JSON格式返回简短的理由和最终决定,以便自动解析。我们的LLM提示格式基于Lee等人(2024)引入的模板。
A. 1 ASAP
系统提示
作为一名英语教师,您的主要职责是评估中学生在英语考试中撰写的作文的写作质量。在评估过程中,您将获得一个提示和一篇文章。首先,您应提供全面且具体的反馈,紧密联系作文内容。避免提供可以适用于任何作品的通用评论是非常重要的。
为了为学生和同行专家创建令人信服的评估,您应该引用作文的具体内容来证明您的评估。
接下来,您的任务是确定哪篇作文得分更高,是Essay 1还是Essay 2,或者如果它们得分相同,请回答“tie”。评估标准可以是总体评分标准的一部分或单独的评估标准。无论评分标准的类型如何,请确定哪篇作文取得更高的总体得分。
用户提示
# 提示
{prompt}
# 评分指南
{rubric}
# 注意
我已经尽力使用命名实体识别器(NER)从文章中删除个人身份信息。
相关实体在文本中被识别出来,然后替换为诸如“PERSON”、“ORGANIZATION”、“LOCATION”、“DATE”、“TIME”、“MONEY”、“PERCENT”、“CAPS”(任何大写字母单词)和“NUM”(任何数字)之类的字符串。请勿因匿名化而惩罚文章。
# Essay1
{essay1}
# Essay2
{essay2}
以json格式提供您的理由和最终决定:
{ “reasoning”: “此处填写一句话的您的理由。”, “preference”: “essay1” 或 “essay2” 或 “tie” }
A. 2 TOEFL11
系统提示
作为一名英语教师,您的主要职责是评估第二语言学习者在英语考试中撰写的作文的写作质量。在评估过程中,您将获得一个提示和一篇文章。
首先,您应提供全面且具体的反馈,紧密联系作文内容。避免提供可以适用于任何作品的通用评论是非常重要的。为了为学生和同行专家创建令人信服的评估,您应该引用作文的具体内容来证明您的评估。
接下来,您的任务是确定哪篇作文得分更高,是Essay 1还是Essay 2,或者如果它们得分相同,请回答“tie”。评估标准基于四个评估类别。使用这些类别全面评估和比较作文,并决定哪一篇取得更高的总体得分。
用户提示
# 提示
{prompt}
# 评分指南
{rubric}
# Essay1
{essay1}
表7:使用不同嵌入(使用GPT-4o)的LCES的QWK分数。
| 嵌入模型 | ASAP | TOEFL11 |
|---|---|---|
| text-embedding-v3-large | 0.653 | 0.645 |
| text-embedding-v3-small | 0.668 | 0.630 |
| BERT-base-uncased | 0.658 | 0.663 |
| RoBERTa-base | 0.655 | 0.601 |
表8:RankNet的超参数。
| 超参数 | 值 |
|---|---|
| 批量大小 | 4096 |
| Dropout率 | 0.3 |
| 隐藏单元 | 256 |
| 权重衰减 | 0.01 |
# Essay2
{essay2}
以json格式提供您的理由和最终决定:
{ “reasoning”: “此处填写一句话的您的理由。”, “preference”: “essay1” 或 “essay2” 或 “tie” }
B 嵌入模型
我们比较了四种用于将文章转换为固定长度向量以供RankNet使用的预训练嵌入模型。其中两种是OpenAI模型:text-embedding-v3-large(3072维度)和text-embedding-v3-small(1536维度),它们都是为语义相似任务设计的。另外两种是BERT-base和RoBERTa-base。对于这些模型,我们使用最终隐藏层的[CLS]标记作为文章表示。
表7显示了使用GPT-4o进行成对比较时ASAP和TOEFL11的平均QWK分数。对于ASAP,嵌入模型的选择对整体表现几乎没有影响。对于TOEFL11,我们观察到稍微更多的变化,但所有模型都表现出一致的高精度。这些结果表明LCES对嵌入编码器的选择具有鲁棒性。
C 超参数
表8显示了第3.2节中描述的RankNet模型的训练超参数。该模型由两个带有ReLU激活和位于它们之间的Dropout层的线性层组成。权重衰减作为
表9:ASAP和TOEFL11中每个提示的Spearman等级相关系数。粗体表示每个提示的最佳方法。
| 数据集 | 模型 | 方法 | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ASAP | Mistral-7B | Vanilla | 0.511 | 0.511 | 0.439 | 0.658 | 0.527 | 0.418 | 0.379 | 0.459 | 0.488 |
| MTS | 0.593 | 0.468 | 0.612 | 0.729 | 0.739 | 0.555 | 0.566 | 0.306 | 0.571 | ||
| LCES | 0.616 | 0.678 | 0.745 | 0.784 | 0.811 | 0.806 | 0.684 | 0.632 | 0.719 | ||
| Llama-3.2-3B | Vanilla | 0.068 | 0.109 | 0.452 | − 0.033 -0.033 −0.033 | 0.276 | 0.142 | 0.209 | 0.076 | 0.162 | |
| MTS | 0.205 | 0.528 | 0.500 | 0.712 | 0.606 | 0.527 | 0.210 | 0.276 | 0.445 | ||
| LCES | 0.665 | 0.693 | 0.725 | 0.767 | 0.741 | 0.738 | 0.589 | 0.684 | 0.700 | ||
| Llama-3.1-8B | Vanilla | 0.005 | 0.050 | 0.451 | 0.618 | 0.424 | 0.429 | 0.061 | − 0.090 -0.090 −0.090 | 0.245 | |
| MTS | 0.538 | 0.580 | 0.546 | 0.723 | 0.731 | 0.543 | 0.570 | 0.366 | 0.574 | ||
| LCES | 0.702 | 0.685 | 0.723 | 0.809 | 0.754 | 0.710 | 0.724 | 0.719 | 0.728 | ||
| GPT-4o-mini | Vanilla | 0.394 | 0.472 | 0.464 | 0.730 | 0.668 | 0.545 | 0.435 | 0.580 | 0.536 | |
| MTS | 0.560 | 0.523 | 0.509 | 0.672 | 0.763 | 0.565 | 0.498 | 0.555 | 0.580 | ||
| LCES | 0.588 | 0.678 | 0.736 | 0.817 | 0.761 | 0.727 | 0.636 | 0.693 | 0.705 | ||
| GPT-4o | Vanilla | 0.468 | 0.518 | 0.525 | 0.787 | 0.729 | 0.557 | 0.546 ------ | |||
| 0.549 | 0.585 | ||||||||||
| MTS | 0.417 | 0.642 | 0.639 | 0.771 | 0.557 | 0.576 | 0.502 | 0.608 | 0.58 | ||
| 9 | |||||||||||
| LCES | 0.578 | 0.682 | 0.750 | 0.833 | 0.812 | 0.776 | 0.713 | 0.713 | 0.732 | ||
| TOEFL11 | |||||||||||
| ------ | Mistral-7B | Vanilla | 0.272 | 0.126 | 0.185 | 0.145 | 0.030 | 0.042 | 0.141 | 0.241 | 0.148 |
| MTS | 0.717 | 0.587 | 0.674 | 0.649 | 0.703 | 0.634 | 0.640 | 0.740 | 0.669 | ||
| LCES | 0.470 | 0.565 | 0.638 | 0.665 | 0.560 | 0.495 | 0.562 | 0.681 | 0.579 | ||
| Llama-3.2-3B | Vanilla | 0.204 | 0.144 | 0.339 | 0.205 | 0.182 | 0.229 | 0.080 | 0.161 | 0.193 | |
| MTS | 0.649 | 0.572 | 0.720 | 0.644 | 0.532 | 0.549 | 0.608 | 0.563 | 0.604 | ||
| LCES | 0.663 | 0.628 | 0.748 | 0.722 | 0.636 | 0.505 | 0.627 | 0.721 | 0.656 | ||
| Llama-3.1-8B | Vanilla | − 0.077 -0.077 −0.077 | 0.166 | − 0.002 -0.002 −0.002 | − 0.005 -0.005 −0.005 | − 0.004 -0.004 −0.004 | − 0.047 -0.047 −0.047 | − 0.034 -0.034 −0.034 | 0.095 | 0.012 | |
| MTS | 0.665 | 0.609 | 0.791 | 0.686 | 0.647 | 0.542 | 0.622 | 0.663 | 0.653 | ||
| LCES | 0.751 | 0.668 | 0.759 | 0.755 | 0.723 | 0.582 | 0.690 | 0.767 | 0.712 | ||
| GPT-4o-mini | Vanilla | 0.131 | 0.252 | 0.261 | 0.172 | 0.044 | 0.123 | 0.151 | 0.177 | 0.164 | |
| MTS | 0.684 | 0.655 | 0.781 | 0.716 | 0.727 | 0.645 | 0.650 | 0.715 | 0.696 | ||
| LCES | 0.753 | 0.674 | 0.757 | 0.745 | 0.753 | 0.684 | 0.695 | 0.769 | 0.729 | ||
| GPT-4o | Vanilla | 0.257 | 0.244 | 0.440 | 0.239 | 0.253 | 0.270 | 0.258 | 0.323 | 0.285 | |
| MTS | 0.675 | 0.655 | 0.802 | 0.713 | 0.728 | 0.628 | 0.635 | 0.727 | 0.695 | ||
| LCES | 0.748 | 0.712 | 0.768 | 0.733 | 0.779 | 0.614 | 0.699 | 0.784 | 0.730 |
Adam优化器配置。
D Spearman等级相关系数评估
除了主要指标QWK外,我们还报告了Spearman等级相关系数以评估预测分数和黄金标准分数之间的序数一致性。该指标在保留文章的相对排名比匹配确切分数更重要的应用中特别相关。与基线方法相比,LCES通常在大多数提示和LLMs上实现更高的Spearman相关性(表9),支持其在保持排名顺序方面的优势。
E 一致率
为了进一步验证LLM生成的成对比较的可靠性,我们测量了LLM决策与人类注释在部分评估对上的同意率。我们报告了两个指标的结果(表10):All,反映包括平局在内的所有对的一致性;Excl. Ties,排除黄金标准标签表明平局的情况。后者专注于存在明确得分差异的对,因此更好地捕捉LLM检测有意义区别的能力。
表现更好的LLM如GPT-4o和Llama-3.1-8B显示出更高的同意率,特别是在排除平局时。这些结果与最终评分性能在QWK和Spearman相关性方面是一致的,
支持将一致率作为成对比较质量的指标使用。
表10:LLM与人类评估者在成对比较中的同意率(%)。
| 模型 | ASAP | TOEFL11 | |||
|---|---|---|---|---|---|
| All | Excl. Ties | All | Excl. Ties | ||
| Mistral-7B | 55.9 | 58.0 | 52.1 | 41.2 | |
| Llama-3.2-3B | 56.3 | 65.0 | 54.5 | 60.1 | |
| Llama-3.1-8B | 60.3 | 71.6 | 57.6 | 76.6 | |
| GPT-4o-mini | 59.9 | 75.1 | 55.9 | 86.6 | |
| GPT-4o | 64.3 | 80.0 | 57.8 | 83.0 |
参考论文:https://arxiv.org/pdf/2505.08498


















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











