






预印本
易子若
北德克萨斯大学 ziruoyi@my.unt.edu
肖婷
北德克萨斯大学 ting.xiao@unt.edu
马克·V·阿尔伯特
北德克萨斯大学
mark.albert@unt.edu
2025年5月16日
摘要
放射科报告生成(RRG)旨在从医学影像中自动生成诊断报告,有可能提升临床工作流程并减少放射科医生的工作量。虽然最近利用多模态大语言模型(MLLMs)和检索增强生成(RAG)的方法取得了显著成果,但仍面临事实不一致、幻觉和跨模态对齐错误等挑战。我们提出了一种多模态多智能体框架用于RRG,该框架与逐步临床推理工作流程相一致,其中任务特定的智能体负责检索、草稿生成、视觉分析、细化和综合。实验结果表明,我们的方法在自动指标和基于LLM的评估中均优于强基线,生成了更准确、结构化和可解释的报告。这项工作突显了与临床对齐的多智能体框架在支持可解释和可信的临床AI应用方面的潜力。
关键词 放射科报告生成 ⋅ \cdot ⋅ 多模态大语言模型 ⋅ \cdot ⋅ 多智能体系统 ⋅ \cdot ⋅ 检索增强生成
1 引言
放射学在现代医疗保健中扮演着至关重要的角色,支持诊断、治疗规划和结果预测。它涉及多种数据来源,如胸部X光图像、实验室结果和临床记录。在放射学中的多模态任务中,放射科报告生成(RRG)尤其具有影响力,因为它直接支持临床工作流程和决策。近期研究进一步强调了RRG的重要性,因为它与放射科医生的文档记录紧密相关[1, 2]。RRG通常涉及两个关键模态:提供患者状况视觉证据的胸部X光图像,以及以自然语言捕捉临床细节的相应放射科报告。然而,放射检查需求的增加和放射科医生的短缺导致了延误,迫使临床医生在没有放射指导的情况下做出关键决策,这可能导致错误或与经验丰富的放射科医生不同的结论[3,4]。
随着人工智能(AI)、计算机视觉(CV)和自然语言处理(NLP)的进步,多模态学习作为一种整合和分析多样化数据源的强大范式已崭露头角[5, 6]。最近,大型语言模型(LLMs)和大型视觉模型(LVMs),包括GPT-4V [7]、LLaMA 3 [8]和DALL
⋅
\cdot
⋅E 3 [9],获得了广泛关注。基于这些进展,多模态大语言模型(MLLMs)在诸如图像标题生成[10]和视觉语言对话[11]等任务上表现出色。在医学领域,MLLMs如Med-PaLM 2 [12]和LLaVA-Med [13]在药物研究[14]和临床支持[15]方面取得了显著进展。对于RRG,MLLMs整合视觉和文本信息以生成详细且临床准确的报告[16, 17],促进结构化文档编制并支持临床决策。这些应用扩展了放射科医生的能力,减少了工作量,并协助经验不足的临床医生。尽管取得了这些进展,现有的基于MLLM的方法在RRG中仍面临关键限制。首先,尽管MLLMs可以有效处理视觉输入,但它们在处理文本信息或需要跨模态推理时往往遇到困难。其次,大多数现有系统缺乏灵活集成提示工程技术的统一架构,这限制了它们适应RRG新要求的能力。第三,当前方法通常缺乏中间验证或细化阶段,容易出现事实不一致和幻觉。
检索增强生成(RAG)[18, 19, 20]作为一种提升医学MLLMs事实准确性的有前途方法已崭露头角。通过整合外部可靠来源,RAG丰富了模型的知识并支持更有根据的生成。它已被应用于诸如视觉问答(VQA)[21]和报告生成[22, 23]等任务。然而,将RAG应用于医学MLLMs引入了几个新挑战。检索到的上下文过少可能遗漏相关信息,而检索过多则可能引入噪声和冗余,使模型更难识别相关内容,最终降低输出质量。
为了解决现有MLLM和RAG方法的局限性,我们提出了一种用于RRG的多模态多智能体框架,将任务分解为五个专业智能体。我们的框架结合了RAG与协作多智能体系统,在其中专业智能体共同处理和整合视觉和文本信息。它从一个检索智能体开始,该智能体为给定的胸部X光图像选择最相似的前
k
k
k 份报告。这些检索到的示例被传递给草稿智能体,该智能体生成报告的初始版本。然后,细化智能体从草稿和检索到的上下文中提取关键发现,以突出重要诊断信息。同时,视觉智能体生成描述胸部X光图像视觉观察的摘要。最后,综合智能体整合视觉、检索和细化智能体的输出以生成最终报告。这种由智能体驱动的工作流程遵循逐步临床推理过程,以模块化和可解释的方式为智能体分配不同角色。我们工作的贡献在于:(1)我们提出了一种与临床对齐的多智能体框架用于RRG,实现了跨任务特定智能体的模块化协作,并结合RAG以增强事实性和可控性。(2)我们进行了广泛的实验,证明我们的方法在自动指标和基于LLM的评估中始终优于强单智能体基线。
2 相关工作
用于RRG的MLLMs。MLLMs最近作为自动化RRG的有前途解决方案崭露头角[24, 25, 26, 27, 28]。诸如R2GenGPT [29]、XrayGPT [30]和MAIRA-1 [31]之类的模型将视觉编码器(例如Swin Transformer [32]、MedCLIP [33])与LLMs(例如LLaMA [8]、Vicuna [34])结合,对齐视觉特征与文本表示,在基准数据集上表现出色。尽管取得成功,这些模型仍存在关键局限,包括事实不一致性[35, 36]、幻觉[37]和灾难性遗忘[38, 39]。这些问题在RRG中尤为关键,因为事实准确性和可靠性对临床应用至关重要。
检索增强生成。RAG已被广泛采用以通过整合外部数据集中的上下文信息来增强事实准确性[18, 40]。它已被应用于RRG以减少幻觉并增强内容相关性[41, 42, 43, 44, 45]。然而,当前的RAG技术面临关键挑战:检索到的上下文数量和质量,以及过度依赖这些参考的风险,这两者都可能降低模型性能或引入事实错误[46]。此外,现有的RAG方法通常独立检索和处理文本和图像信息,限制了其进行集成多模态推理的能力[47]。这些局限性在RRG中尤为严重,因为它依赖于检索知识与视觉证据之间的精细对齐。
多智能体系统。多智能体系统在自然语言处理(NLP)和医疗保健AI中获得越来越多的关注[48, 49, 50,
51
,
52
,
53
]
51,52,53]
51,52,53]。它们将不同任务分配给专业智能体,这些智能体协作完成单一模型常难以应对的复杂目标。初步尝试已探索用于RRG的多智能体范式,显示出有希望的结果[54, 55]。然而,将多智能体系统应用于多模态任务引入了新的挑战。特别是,简单地组合来自孤立视觉和文本智能体的输出往往无法捕捉准确解释所需的跨模态关系。此外,使智能体交互与特定领域的逐步临床推理等工作流程对齐仍然是当前系统的关键挑战。为了解决这些局限性,我们提出了一种与逐步临床推理对齐的多模态多智能体框架,其中任务特定的智能体以模块化和可解释的方式处理检索、草稿生成、细化、视觉分析和综合。
3 方法
我们提出了一种模块化的多智能体框架用于RRG,设计用于通过结合案例检索、视觉解读和结构化文本综合来模拟临床工作流程。给定一张胸部X光图像,系统依次激活五个专业智能体:检索智能体、草稿智能体、细化智能体、视觉智能体和综合智能体。每个智能体履行特定的功能角色并独立操作,使用任务特定的提示
(针对LLM/VLM智能体)或基于嵌入的检索(针对检索模块)。如图1所示,智能体通过结构化的中间输出进行通信,逐步将放射学观察精炼成最终连贯的印象。此设计促进事实准确性、提高可解释性,并帮助确保一致的报告生成。
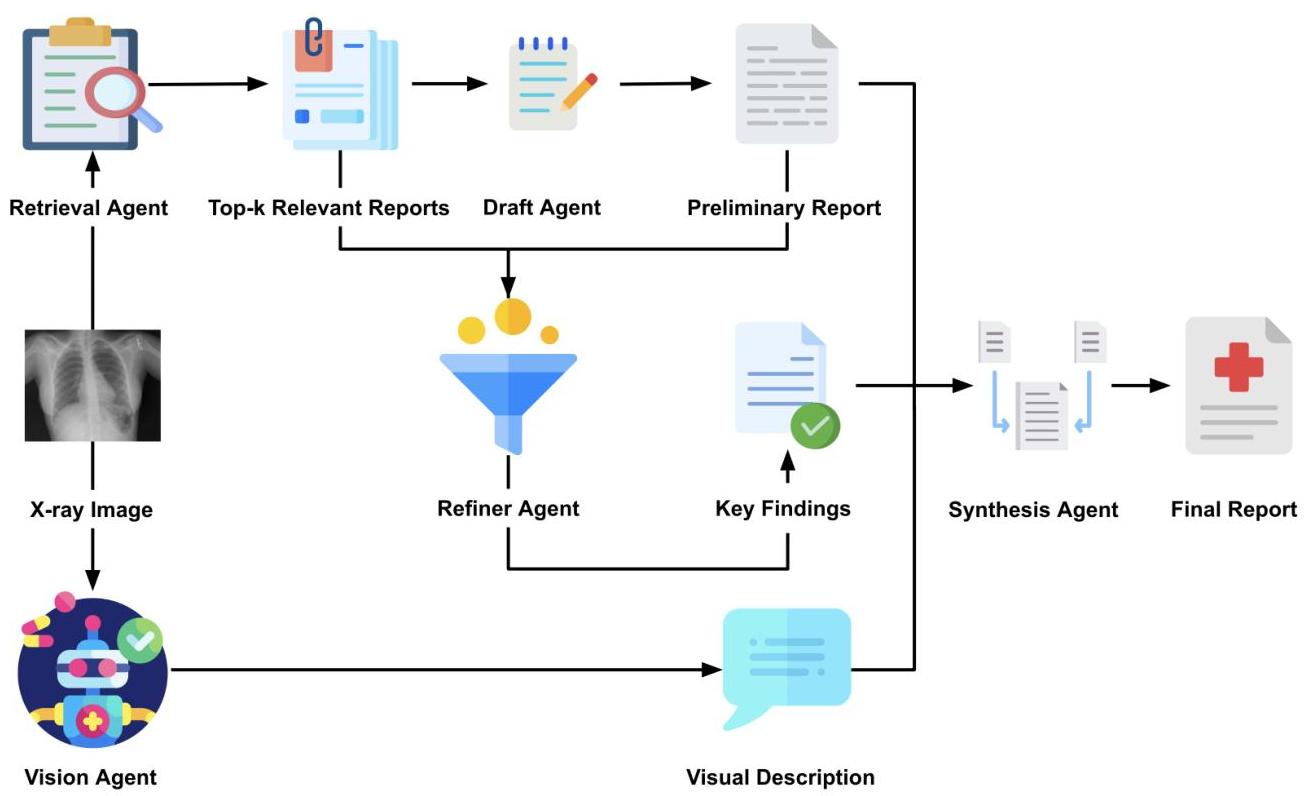
图1:我们提出的用于自动化RRG的多智能体框架概述。系统将任务分解为五个智能体:(1)检索智能体选择最相似的前k份报告。(2)草稿智能体从检索到的文本中生成初步报告。(3)细化智能体提炼关键临床发现。(4)视觉智能体生成图像的视觉描述。(5)综合智能体整合这些输出以生成最终报告。
3.1 检索智能体
检索智能体通过跨模态检索识别与给定胸部X光图像语义相似的先前放射科报告。受CLIP [56]设计的启发,该智能体将输入图像编码为视觉嵌入,并使用余弦相似度将其与报告嵌入进行比较。基于相似度得分选择最相似的前- k k k 份报告,其中 k k k 是平衡检索覆盖率和效率的预定义参数。这些报告提供了相关的诊断背景,如临床发现和报告风格,作为下游生成的指导。
3.2 草稿智能体
草稿智能体通过合成检索智能体选出的前-k份报告中的信息来组成初步的放射科报告。受放射科医生审查类似先前病例的启发,该智能体识别共享的临床发现并优先考虑医学相关的观察。然后,它将此信息组织成反映初步诊断印象的临床聚焦报告。这一中间输出为后续智能体的处理提供了结构化的文本基础。
3.3 细化智能体
细化智能体从草稿和检索智能体的输出中提炼关键临床发现。它旨在识别持续得到输入支持的临床重要观察。与生成广泛初步报告的草稿智能体不同,
细化智能体专注于发现层面的内容。它接收初步报告和原始检索报告作为输入,并输出包含最重要发现的简洁单段落摘要。为确保事实性,该智能体实施检索为基础的约束:每句话必须由输入明确支持,不得超出事实重写的推测或改写。输出为下游综合提供了结构化的临床信号。
3.4 视觉智能体
视觉智能体生成胸部X光图像的视觉描述,以补充前序智能体提供的文本信息。它使用医疗MLLM根据输入图像中的可见观察生成基于图像的描述。输出是一个描述关键胸部区域(如肺部和纵隔)的标题。该智能体旨在避免模糊陈述和无关内容,确保标题基于可见证据并采用放射科报告风格。此步骤引入输入图像的视觉线索以支持最终综合。
3.5 综合智能体
综合智能体通过整合前序智能体生成的初步报告、关键发现和视觉标题来生成最终的放射科报告。为确保事实一致性和风格连贯性,最终报告仅包括由文本或视觉输入明确支持的观察。该智能体旨在避免无依据的发现和不必要的重写,同时保留每个输入的核心临床内容,并以逻辑一致的方式将其结合。此最终步骤通过生成临床依据充分且结构良好的放射科报告,完成了多智能体管道。
4 实验
在本节中,我们通过解决以下问题来评估我们的多模态多智能体框架:(1)多智能体设计是否相比基线提高了生成放射科报告的临床准确性?(2)每个智能体在生成过程中是否发挥了有意义的作用?(3)该框架如何提升生成报告的整体质量?
4.1 实验设置
实现细节。我们的框架由五个智能体组成:检索智能体、草稿智能体、细化智能体、视觉智能体和综合智能体。我们遵循RULE [46]的检索设置来构建检索智能体,该智能体在MIMIC-CXR上微调CLIP,使用对比学习以适应医疗领域。LLaVA-Med 1.5 (7B) [13]用作视觉智能体的主干,而GPT-4o [7]为草稿、细化和综合智能体提供支持。检索智能体选择最相似的前-
k
k
k 份报告(默认
k
=
5
k=5
k=5),然后将其传递给草稿智能体作为输入。
数据集。我们使用两个公开可用的胸部X光数据集:MIMIC-CXR [57]和IU X-ray [58]。我们使用MIMIC-CXR中的3,000个图像-报告对来微调检索智能体,这是一个包含关联放射科报告的大规模胸部X光数据集。为了评估,我们使用IU X-ray数据集,其中包括胸部X光片及其对应的诊断报告。按照[59]的数据分割,过滤后IU X-ray数据集包含2,068个训练和590个测试图像-报告对。我们使用训练集构建检索数据库,并使用测试集评估框架的性能。
评估指标。我们的多智能体框架的性能使用标准文本生成指标进行评估,包括BLEU [60]、ROUGE-1、ROUGE-2、ROUGE-L [61]和BERTScore [62]。这些指标侧重于生成和参考印象之间的表面级相似性,主要基于词汇或标记重叠。为了补充这些自动指标,我们采用LLM-as-a-Judge范式 [63],并使用Anthropic开发的最先进的LLM Claude 3 Opus [64]来评估生成报告的语义准确性和临床相关性。
4.2 结果
在本节中,我们在IU X-ray数据集上全面评估我们的多智能体框架,将其与使用LLaVA-Med的单智能体基线进行比较,后者模拟了无法访问先前报告或临床线索的放射科医生。
4.2.1 定量分析
标准指标。我们使用标准指标(包括BLEU、ROUGE、METEOR和BERTScore)评估我们的框架性能。该评估结果列于表1。我们的多智能体框架BLEU得分为0.0466,显著优于LLaVA-Med的0.0036。ROUGE-1、ROUGE-2和ROUGE-L分数分别从0.2398、0.0278和0.1537提升至0.3652、0.1292和0.2471,表明所有ROUGE指标均有所改善。对于METEOR,分数从0.1437提升至0.3618,显示更好的词汇多样性和内容覆盖。在BERTScore上,框架达到0.8819,相较于基线的0.8617,表明生成和参考文本之间更强的语义一致性。这些结果表明,多智能体设计在RRG中大幅提升了文本质量和语义连贯性。
表1:我们的多智能体框架与单一MLLM之间的定量性能比较。
| 模型 | BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | METEOR | BERTScore |
|---|---|---|---|---|---|---|
| Llava-Med | 0.0036 | 0.2398 | 0.0278 | 0.1537 | 0.1437 | 0.8617 |
| 我们的 | 0.0466 \mathbf{0 . 0 4 6 6} 0.0466 | 0.3652 \mathbf{0 . 3 6 5 2} 0.3652 | 0.1292 \mathbf{0 . 1 2 9 2} 0.1292 | 0.2471 \mathbf{0 . 2 4 7 1} 0.2471 | 0.3618 \mathbf{0 . 3 6 1 8} 0.3618 | 0.8819 \mathbf{0 . 8 8 1 9} 0.8819 |
LLM-as-a-Judge。为了补充标准指标,我们进一步使用Claude 3 Opus [64]评估生成报告的临床和语言质量,重点关注五个关键方面:关键发现覆盖、与原始报告的一致性、诊断准确性、风格一致性及简洁性。每个方面评分从1到10,分数越高表示质量越好。如表2总结,我们的多智能体框架在五个评估维度中的四个表现优于LLaVAMed。其诊断准确率得分为8.26,相较于7.78,显示出更强的临床推理能力。我们的框架在风格一致性上得分为8.16,简洁性得分为7.26,均超越基线分数7.98和6.98。这些改进反映了与临床报告写作标准更强的对齐。关键发现覆盖从5.86提升至6.36,显示出更清晰的临床相关信息呈现。尽管LLaVA-Med在一致性上略有领先(6.94 vs. 6.74),整体结果突显了我们的多智能体设计在增强临床可靠性和写作质量方面的有效性。
表2:我们的多智能体框架与单一MLLM之间的定性性能比较。
| 模型 | 发现 | 一致性 | 诊断 | 风格 | 简洁性 |
|---|---|---|---|---|---|
| LLaVA-Med | 5.86 | 6.94 \mathbf{6 . 9 4} 6.94 | 7.78 | 7.98 | 6.98 |
| 我们的 | 6.36 \mathbf{6 . 3 6} 6.36 | 6.74 | 8.26 \mathbf{8 . 2 6} 8.26 | 8.16 \mathbf{8 . 1 6} 8.16 | 7.26 \mathbf{7 . 2 6} 7.26 |
4.2.2 定性分析
图2展示了一个代表性案例,比较了仅由视觉智能体生成的报告与我们完整的多智能体框架生成的报告。这个案例突显了通过我们的多智能体管道纳入检索报告和提取关键发现的好处。尽管视觉智能体的输出在风格上合理,但缺乏具体性且遗漏了重要观察。相比之下,多智能体输出提供了更完整且更符合临床标准的摘要。它遵循常见于先前报告中的术语和结构,例如包含“胸腔积液”和“脊柱出现退行性变化”,更好地与原始报告对齐。这些改进得益于结构化的智能体协作:检索智能体提供相关的上下文示例,细化智能体提取关键临床发现,综合智能体将它们与视觉标题结合成结构化报告。最终输出更加简洁、组织更好且临床可靠,展示了检索依据和智能体协作如何生成比仅视觉智能体更高的质量报告。
4.3 讨论
我们的结果显示,所提出的多智能体框架在标准自动指标和基于LLM的临床评估中始终增强RRG。通过为每个智能体分配特定功能,如检索、抽象、细化、视觉标题生成和综合,该框架引入了更清晰的结构和职责分离。这种模块化设计使生成更具可控性和可解释性,允许每个智能体专注于临床推理或风格一致性的一个特定方面。生成的报告更完整且风格更一致。它们还表现出更强的临床依据和更好的遵循放射科报告惯例。
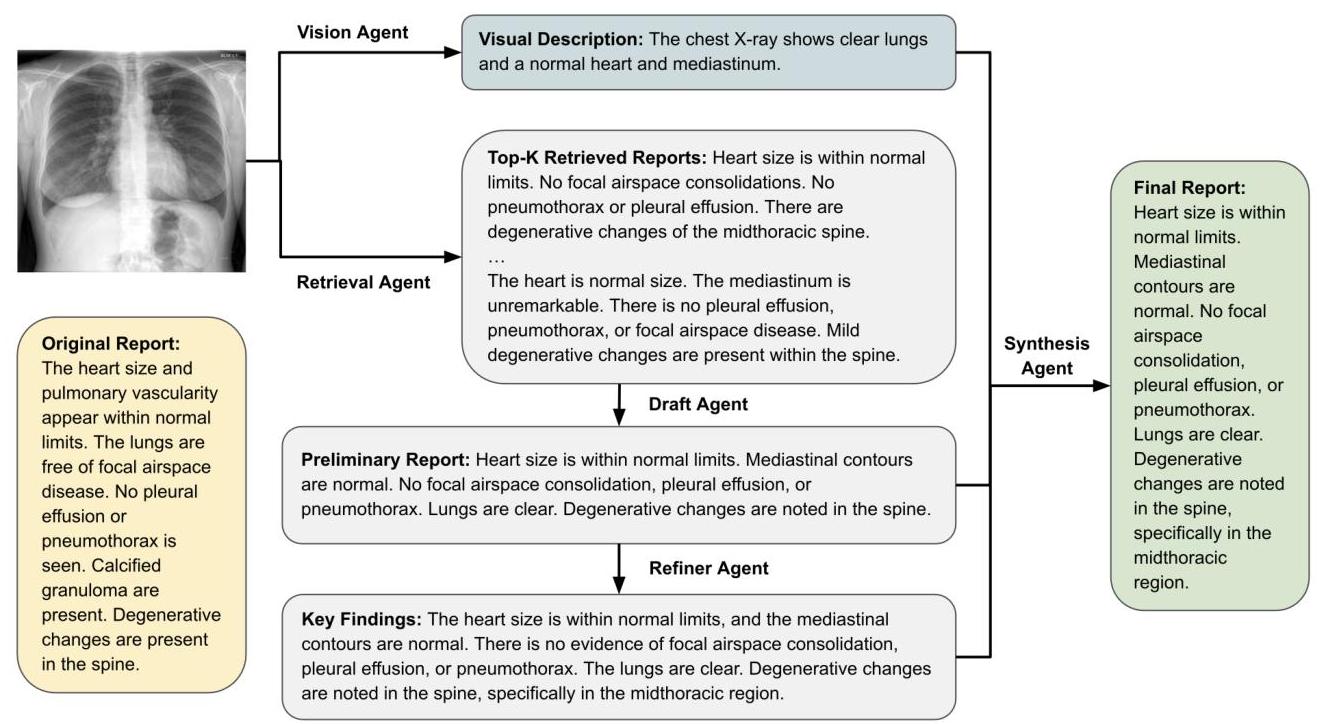
图2:案例研究表明检索和关键发现如何帮助克服仅视觉智能体的局限性。
尽管我们的框架展示了显著改进,但我们观察到一致性较基线略有下降。类似发现已在先前工作中报道[54],其中RAG可能引入冗余或无关内容,降低整体连贯性。在我们的情况下,检索报告、细化发现和视觉描述的结合引入了额外的复杂性,可能影响最终输出的整体一致性。尽管存在这一局限性,我们的实验表明,多智能体框架相比强大的单智能体基线在临床准确性和报告质量方面有所提升,这一点得到了自动和基于LLM的评估的验证。案例研究进一步突出了个别智能体在增强事实性和结构方面的独特贡献。未来工作包括更系统的调查,特别是通过智能体级别的消融。
5 结论
我们提出了一个用于RRG的多模态多智能体框架,将任务分解为专门用于检索、草稿、细化、视觉解读和综合的智能体。我们的方法遵循诊断推理过程,如通过自动指标和基于LLM的评估所示,优于强大的单智能体MLLM基线。通过智能体之间的协作,该框架生成的报告更具临床依据、连贯性和风格一致性。这种模块化设计为其他需要诊断推理和临床精确性的多模态医疗任务提供了一种通用方法。
参考文献
[1] Nur Yildirim, Hannah Richardson, Maria Teodora Wetscherek, Junaid Bajwa, Joseph Jacob, Mark Ames Pinnock, Stephen Harris, Daniel Coelho De Castro, Shruthi Bannur, Stephanie Hyland, et al. 多模态医疗保健AI:识别和设计放射学相关的视觉语言应用。在2024 CHI计算系统中的人为因素会议论文集,第1-22页,2024年。
[2] 易子若,肖婷,马克 V 阿尔伯特。放射学中用于报告生成和视觉问答的多模态大语言模型综述。信息,16(2):136, 2025.
[3] Robert J McDonald, Kara M Schwartz, Laurence J Eckel, Felix E Diehn, Christopher H Hunt, Brian J Bartholmai, Bradley J Erickson, and David F Kallmes. 截面成像利用率变化和技术进步对放射科医生工作量的影响。学术放射学,22(9):1191-1198, 2015.
[4] Bruno Petinaux, Rahul Bhat, Keith Boniface, and Jaime Aristizabal. 急诊科放射影像读取的准确性。美国急诊医学杂志,29(1):18-25, 2011.
[5] 黄宇,杜晨壮,薛子惠,陈宣尧,赵航,黄龙波。什么使得多模态学习比单模态更好(可证明)。神经信息处理系统进展,34:1094410956, 2021.
[6] Asim Waqas, Aakash Tripathi, Ravi P Ramachandran, Paul A Stewart, and Ghulam Rasool. 深度神经网络时代的肿瘤学多模态数据整合:综述。人工智能前沿,7:1408843, 2024.
[7] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 等。Gpt-4 技术报告。arXiv预印本 arXiv:2303.08774, 2023.
[8] AI Meta. 推介 Meta Llama 3:迄今为止最强大的开源 LLM。Meta AI, 2024.
[9] OpenAI. DALL-E3, 2023. https://openai.com/index/dall-e-3/.
[10] 李俊楠,李东旭,Silvio Savarese,Steven Hoi。BLIP-2:通过冻结图像编码器和大型语言模型引导的语言-图像预训练启动。在国际机器学习会议,第19730-19742页。PMLR, 2023.
[11] Huang Yupan, Meng Zaiqiao, Liu Fangyu, Su Yixuan, Nigel Collier, Lu Yutong. Sparkles:解锁多图像聊天的多模态指令跟随模型。arXiv 预印本 arXiv:2308.16463, 2023.
[12] Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, 等。通过大型语言模型实现专家水平的医学问题回答。自然医学,第1-8页,2025.
[13] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: 在一天内训练出用于生物医学的大型语言和视觉助手。神经信息处理系统进展,36:28541-28564, 2023.
[14] Francesca Grisoni. 化学语言模型用于从头药物设计:挑战与机遇。结构生物学当前观点,79:102527, 2023.
[15] Stephen R Ali, Thomas D Dobbs, Hayley A Hutchings, and Iain S Whitaker. 使用 ChatGPT 编写患者诊所信件。柳叶刀数字健康,5(4):e179-e181, 2023.
[16] 刘正亮,李一伟,舒鹏,钟傲潇,杨龙涛,居超,吴志豪,马冲,罗杰,陈成,等。Radiology-llama2:放射学最佳大型语言模型。arXiv 预印本 arXiv:2309.06419, 2023.
[17] Manuela Daniela Danu, George Marica, Sanjeev Kumar Karn, Bogdan Georgescu, Awais Mansoor, Florin Ghesu, Lucian Mihai Itu, Constantin Suciu, Sasa Grbic, Oladimeji Farri, 等。通过协同知识生成胸部X光的放射学发现。Procedia Computer Science,221:1102-1109, 2023.
[18] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, 和 Haofen Wang. 面向大型语言模型的检索增强生成:综述。arXiv 预印本 arXiv:2312.10997, 2:1, 2023.
[19] Qu Xiaoye, Chen Qiyuan, Wei Wei, Sun Jishuo, 和 Dong Jianfeng. 通过主动检索增强减轻大型视觉语言模型的幻觉。arXiv 预印本 arXiv:2408.00555, 2024.
[20] Qu Xiaoye, Sun Jiashuo, Wei Wei, 和 Cheng Yu. 看、比较、决定:通过多视图多路径推理减轻大型视觉语言模型的幻觉。arXiv 预印本 arXiv:2408.17150, 2024.
[21] Yuan Zheng, Jin Qiao, Tan Chuanqi, Zhao Zhengyun, Yuan Hongyi, Huang Fei, 和 Huang Songfang. Ramm:通过多模态预训练实现带有检索增强的生物医学视觉问答。在第31届ACM国际多媒体会议论文集,第547-556页,2023.
[22] Yogesh Kumar 和 Pekka Marttinen. 使用专家注释改进医疗多模态对比学习。在欧洲计算机视觉会议,第468-486页。Springer, 2024.
[23] Tao Yitian, Ma Liyan, Yu Jing, 和 Zhang Han. 基于记忆的跨模态语义对齐网络用于放射学报告生成。IEEE 生物医学与健康信息学杂志,2024.
[24] Ji Jia, Yongshuai Hou, Xinyu Chen, Youcheng Pan, 和 Yang Xiang. 从临床图像生成文本描述的视觉-语言模型:模型开发与验证研究。JMIR Formative Research, 8:e32690, 2024.
[25] Chang Liu, Yuanhe Tian, Weidong Chen, Yan Song, 和 Yongdong Zhang. 引导大型语言模型用于放射学报告生成。在AAAI人工智能会议论文集,卷38,第18635-18643页,2024.
[26] Yuhao Wang, Chao Hao, Yawen Cui, Xinqi Su, Weicheng Xie, Tao Tan, 和 Zitong Yu. Trrg:通过跨模态疾病线索增强大型语言模型实现真实的放射学报告生成。arXiv 预印本 arXiv:2408.12141, 2024.
[27] Zijian Zhou, Miaojing Shi, Meng Wei, Oluwatosin Alabi, Zijie Yue, 和 Tom Vercauteren. 具有临床质量强化学习的大型模型驱动放射学报告生成。arXiv 预印本 arXiv:2403.06728, 2024.
[28] Yuzhe Lu, Sungmin Hong, Yash Shah, 和 Panpan Xu. 有效微调以改进大型多模态模型用于放射学报告生成。arXiv 预印本 arXiv:2312.01504, 2023.
[29] Zhanyu Wang, Lingqiao Liu, Lei Wang, 和 Luping Zhou. R2genGPT:使用冻结LLM的放射学报告生成。Meta-Radiology, 1(3):100033, 2023.
[30] Omkar Thawkar, Abdelrahman Shaker, Sahal Shaji Mullappilly, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen, 和 Fahad Shahbaz Khan. XrayGPT:使用医疗视觉语言模型总结胸部X光片。arXiv 预印本 arXiv:2306.07971, 2023.
[31] Hyland Stephanie L, Bannur Shruthi, Bouzid Kenza, Castro Daniel C, Ranjit Mercy, Schwaighofer Anton, Pérez-García Fernando, Salvatelli Valentina, Srivastav Shaury, Thieme Anja, 等。Maira-1:用于放射学报告生成的专业大型多模态模型。arXiv 预印本 arXiv:2311.13668, 2023.
[32] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, 和 Baining Guo. Swin Transformer:使用移位窗口的分层视觉Transformer。在IEEE/CVF国际计算机视觉会议论文集,第10012-10022页,2021.
[33] Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, 和 Jimeng Sun. MedCLIP:从非配对医学图像和文本进行对比学习。在实证方法自然语言处理会议论文集。实证方法自然语言处理会议,卷2022,第3876页,2022.
[34] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, 等。Vicuna:一个开源聊天机器人,以90%*ChatGPT质量令人印象深刻,2023年3月。URL https://lmsys.org/blog/2023-03-30-vicuna, 3(5), 2023.
[35] Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, 等。CARES:医学视觉语言模型信任度的全面基准。神经信息处理系统进展,37:140334-140365, 2024.
[36] Su Zhaochen, Zhang Jun, Qu Xiaoye, Zhu Tong, Li Yanshu, Sun Jiashuo, Li Juntao, Zhang Min, 和 Cheng Yu. ConflictBank:评估知识冲突对LLM影响的基准。arXiv 预印本 arXiv:2408.12076, 2024.
[37] Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, 和 Wei Peng. 大型视觉语言模型幻觉的综述。arXiv 预印本 arXiv:2402.00253, 2024.
[38] Zhai Yuexiang, Tong Shengbang, Li Xiao, Cai Mu, Qu Qing, Lee Yong Jae, 和 Ma Yi. 探究多模态大型语言模型中的灾难性遗忘。arXiv 预印本 arXiv:2309.10313, 2023.
[39] Hikmat Khan, Nidhal C Bouaynaya, 和 Ghulam Rasool. 减轻灾难性遗忘的重要稳健特征。在2023 IEEE计算机与通信研讨会(ISCC)论文集,第752-757页。IEEE, 2023.
[40] Jiashuo Sun, Jihai Zhang, Yucheng Zhou, Zhaochen Su, Xiaoye Qu, 和 Yu Cheng. SURF:教导大型视觉语言模型选择性利用检索信息。arXiv 预印本 arXiv:2409.14083, 2024.
[41] Mercy Ranjit, Gopinath Ganapathy, Ranjit Manuel, 和 Tanuja Ganu. 使用OpenAI GPT模型的检索增强胸部X光报告生成。在医疗保健机器学习会议论文集,第650-666页。PMLR, 2023.
[42] Sun Liwen, Zhao James, Han Megan, 和 Xiong Chenyan. 事实感知的多模态检索增强以实现准确的医学放射学报告生成。arXiv 预印本 arXiv:2407.15268, 2024.
[43] Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, 和 Huaxiu Yao. MMed-RAG:适用于医学视觉语言模型的多功能多模态RAG系统。arXiv 预印本 arXiv:2410.13085, 2024.
[44] Liang Siting, Pablo Sánchez, 和 Daniel Sonntag. 通过主动学习优化医学文本中的关系抽取:权衡的比较分析。在首届不确定性感知NLP(UncertaiNLP 2024)研讨会论文集,第23-34页,2024.
[45] Mario Luca Bernardi 和 Marta Cimitile. 通过检索增强生成和改进的图像-文本匹配从X射线成像生成报告。在2024年国际联合神经网络会议(IJCNN)论文集,第1-8页。IEEE, 2024.
[46] Peng Xia, Kangyu Zhu, Haoran Li, Hongtu Zhu, Yun Li, Gang Li, Linjun Zhang, 和 Huaxiu Yao. RULE:医学视觉语言模型中事实性的可靠多模态RAG。在2024年实证方法自然语言处理会议论文集,第1081-1093页,2024.
[47] Siwei Han, Peng Xia, Ruiyi Zhang, Tong Sun, Yun Li, Hongtu Zhu, 和 Huaxiu Yao. MDocAgent:一种用于文档理解的多模态多智能体框架。arXiv预印本 arXiv:2503.13964, 2025.
[48] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, 等。基于大型语言模型的自主智能体综述。计算机科学前沿,18(6):186345, 2024.
[49] Ling Yue 和 Tianfan Fu. CT-Agent:基于大型语言模型推理的临床试验多智能体。arXiv e-prints, 第arXiv-2404页, 2024.
[50] He Ke Yu, Yang Rui, Lie Sui An, Taylor Xin Yi Lim, Hairil Rizal Abdullah, Daniel Shu Wei Ting, 和 Liu Nan. 通过多智能体对话增强诊断准确性:使用大型语言模型减轻认知偏差。arXiv预印本 arXiv:2401.14589, 2024.
[51] Hao Wei, Jianing Qiu, Haibao Yu, 和 Wu Yuan. MedCo:基于多智能体框架的医学教育助理。arXiv预印本 arXiv:2408.12496, 2024.
[52] Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, 和 Mark Gerstein. MedAgents:作为零样本医学推理合作者的大型语言模型。arXiv预印本 arXiv:2311.10537, 2023.
[53] Andries Petrus Smit, Paul Duckworth, Nathan Grinsztajn, Kale-ab Tessera, Thomas D Barrett, 和 Arnu Pretorius. 我们疯了吗?基准测试医疗问答中语言模型之间的多智能体辩论。在NeurIPS 2023健康深度生成模型研讨会,2023.
[54] Fang Zeng, Zhiliang Lyu, Quanzheng Li, 和 Xiang Li. 通过多智能体系统增强放射学报告印象生成中的LLMs。arXiv预印本 arXiv:2412.06828, 2024.
[55] Hasan Md Tusfiqur Alam, Devansh Srivastav, Md Abdul Kadir, 和 Daniel Sonntag. 通过概念瓶颈实现可解释的放射学报告生成的多智能体RAG。在欧洲信息检索会议论文集,第201-209页。Springer, 2025.
[56] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 等。通过自然语言监督学习可转移的视觉模型。在国际机器学习会议论文集,第8748-8763页。PmLR, 2021.
[57] Alistair EW Johnson, Tom J Pollard, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, 和 Steven Horng. MIMIC-CXR-JPG,一个大规模公开可用的标注胸部X光数据库。arXiv预印本 arXiv:1901.07042, 2019.
[58] Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Sonya E Shooshan, Laritza Rodriguez, Sameer Antani, George R Thoma, 和 Clement J McDonald. 准备分发和检索的放射学检查集合。美国医学信息学协会杂志,23(2):304-310, 2016.
[59] Kang Liu, Zhuoqi Ma, Mengmeng Liu, Zhicheng Jiao, Xiaolu Kang, Qiguang Miao, 和 Kun Xie. 事实序列化增强:胸部X光报告生成的关键创新。arXiv预印本 arXiv:2405.09586, 2024.
[60] Kishore Papineni, Salim Roukos, Todd Ward, 和 Wei-Jing Zhu. BLEU:一种自动评估机器翻译的方法。在计算语言学协会第40届年会论文集,第311-318页,2002.
[61] Chin-Yew Lin. ROUGE:一种自动摘要评估包。在文本摘要分支扩展,第 74 − 81 , 2004 74-81,2004 74−81,2004页.
[62] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, 和 Yoav Artzi. BertScore:用BERT评估文本生成。arXiv预印本 arXiv:1904.09675, 2019.
[63] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, 等。用MT-Bench和Chatbot Arena评判LLM-as-a-Judge。神经信息处理系统进展,36:46595-46623, 2023.
[64] Anthropic. Claude 3 Haiku:我们最快的模型,2024. https://www.anthropic.com/news/ claude-3-haiku.
参考论文:https://arxiv.org/pdf/2505.09787


















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











