







注:两篇关于 L-Mul 算法的文章。
LLM 合集:L-Mul 算法 – 在 Transformer 中以整数加法替代乘法,节省高达 95% 算力
原创 AI-PaperDaily
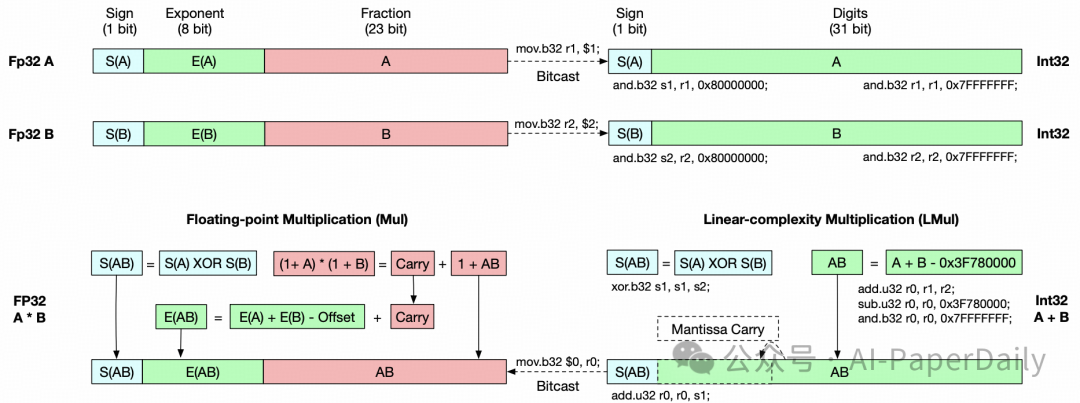
1. Addition is All You Need for Energy-efficient Language Models
~
 ~
~
大型神经网络在大多数计算中用于浮点张量乘法。在本文中,我们发现浮点乘法可以由一个高精度的整数加法器近似。我们提出了线性复杂度乘法 L-Mul 算法,该算法使用整数加法运算近似浮点数乘法。与 8 位浮点乘法相比,新算法消耗的计算资源显著减少,但精度更高。由于浮点数乘法比整数加法消耗更多算力,将 L-Mul 操作应用于张量处理硬件可以潜在地减少 95% 的元素级浮点张量乘法算力成本和 80% 的点积算力成本。
我们计算了 L-Mul 的理论误差期望值,并在包括自然语言理解、结构推理、数学和常识问答在内的广泛文本、视觉和符号任务上评估了该算法。我们分析实验与理论误差估计相符,表明具有 4 位尾数的 L-Mul 与 float8_e4m3 乘法具有可比精度,而具有 3 位尾数的 L-Mul 优于 float8_e5m2。在流行基准上的评估结果表明,直接将 L-Mul 应用于注意力机制几乎是无损失的。我们进一步证明,在 transformer 模型中用 3 位尾数的 L-Mul 替换所有浮点乘法操作,与使用 float8_e4m3 作为累积精度的浮点数乘法在微调和推理中具有同等精度。
论文: https://arxiv.org/pdf/2410.00907
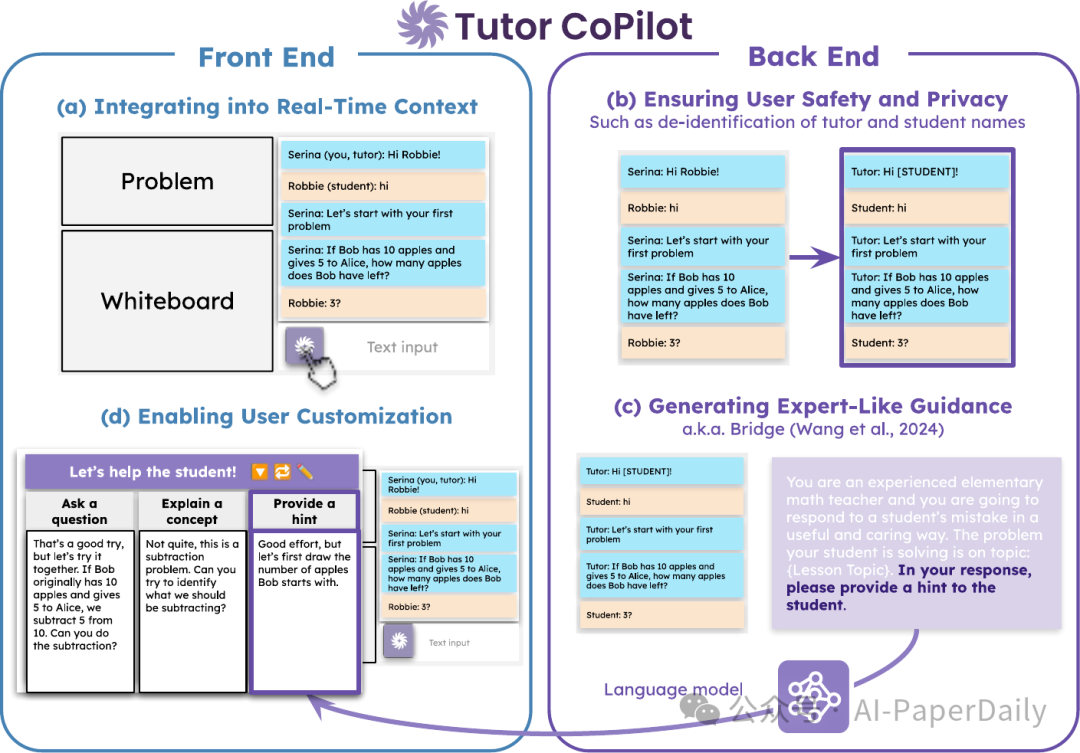
2. Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise
~
 ~
~
生成式 AI,特别是语言模型(LMs),有潜力改变现实世界的应用领域,特别是在专家资源有限的领域。例如,在教育方面,用专家指导来培训新手教师至关重要,但成本高昂,从而在大规模提高教育质量方面形成重大障碍。这一挑战不成比例地影响了来自未服务社区的学生,他们最能从高质量教育中获益。我们介绍了 Tutor CoPilot,这是一种创新的人工智能方法,利用专家思维模型为辅导者提供类似专家的指导。这是首次在实时辅导中进行的人工智能系统的随机对照试验,涉及 900 名辅导者和 1,800 名来自历史上未服务社区的 K-12 学生。按照预先注册的分析方案,我们发现使用 Tutor CoPilot 的辅导者的学生更有可能掌握知识点(增加了 4 个百分点,p<0.01)。值得注意的是,低评价辅导者的学生成为最大受益者,提高掌握程度 9 个百分点。我们发现 Tutor CoPilot 每年每辅导者仅需 20 美元。我们分析了超过 550,000 条消息,使用分类器识别教学策略,并发现使用 Tutor CoPilot 的辅导者更有可能使用高质量策略来促进学生理解(例如,提出引导性问题),且更不可能直接告诉答案。辅导者访谈强调了 Tutor CoPilot 如何帮助辅导者回应学生需求,尽管他们指出了一些问题,如生成不合适的年级水平的建议。
论文: https://arxiv.org/pdf/2410.03017
3. NL-Eye: Abductive NLI for Images
~
 ~
~
基于视觉语言模型(VLM)的机器人是否会警告我们地板湿滑可能会滑倒?最近的 VLM 展示了令人印象深刻的性能,但它们推断结果和原因的能力仍然有待探索。为了解决这个问题,我们引入了 NL-Eye,一个旨在评估 VLM 视觉演绎推理能力的基准。NL-Eye 将演绎自然语言推理(NLI)任务改编到视觉领域,要求模型根据前提图像评估假设图像的合理性,并解释其决策。NL-Eye 包含 350 个精心策划的三元组示例(1050 张图像),涵盖多种推理类别:物理、功能、逻辑、情感、文化和社会。数据策划过程包括两个步骤 —— 编写文本描述和使用文本到图像模型生成图像,两者都需要大量的人工参与以确保高质量和具有挑战性的场景。我们的实验表明,VLM 在 NL-Eye 上的表现显著困难,经常表现得像随机基线水平,而人类在合理性判断和解释质量方面表现出色。这表明现代 VLM 在演绎推理能力方面存在缺陷。NL-Eye 代表了朝着开发适用于现实世界应用的稳健多模态推理能力的 VLM 的重要一步,包括事故预防机器人和生成视频验证。
论文: https://arxiv.org/pdf/2410.02613
4. Accelerating Auto-regressive Text-to-Image Generation with Training-free Speculative Jacobi Decoding
~
 ~
~
当前的大型自回归模型可以生成高质量、高分辨率的图像,但在推理过程中,这些模型需要数百甚至数千步的下一个 token 预测,导致显著的时间消耗。在现有研究中,雅可比解码是一种迭代并行解码算法,已被用于加速自回归生成,并且可以在不进行训练的情况下执行。然而,雅可比解码依赖于确定性的标准来判断迭代的收敛性。因此,它适用于贪婪解码,但与当前自回归文本到图像生成中至关重要的基于采样的解码不兼容,后者对于视觉质量和多样性至关重要。在本文中,我们提出了一种无需训练的概率并行解码算法 —— 推测性雅可比解码(SJD),以加速自回归文本到图像生成。通过引入概率收敛标准,我们的 SJD 在保持基于采样的 token 解码的随机性的同时加速了自回归文本到图像生成的推理过程,并允许模型生成多样性的图像。具体来说,SJD 使模型能够在每一步预测多个 token,并基于概率标准接受这些 token,从而使模型能够生成比传统的下一个 token 预测范式所需的步骤更少的图像。我们还研究了利用视觉数据的空间局部性来进一步提高加速比的 token 初始化策略,以在特定场景下进一步提高加速效果。我们在多个自回归文本到图像生成模型上进行了 SJD 的实验,证明了在不牺牲视觉质量的情况下模型加速的有效性。
论文: https://arxiv.org/pdf/2410.01699
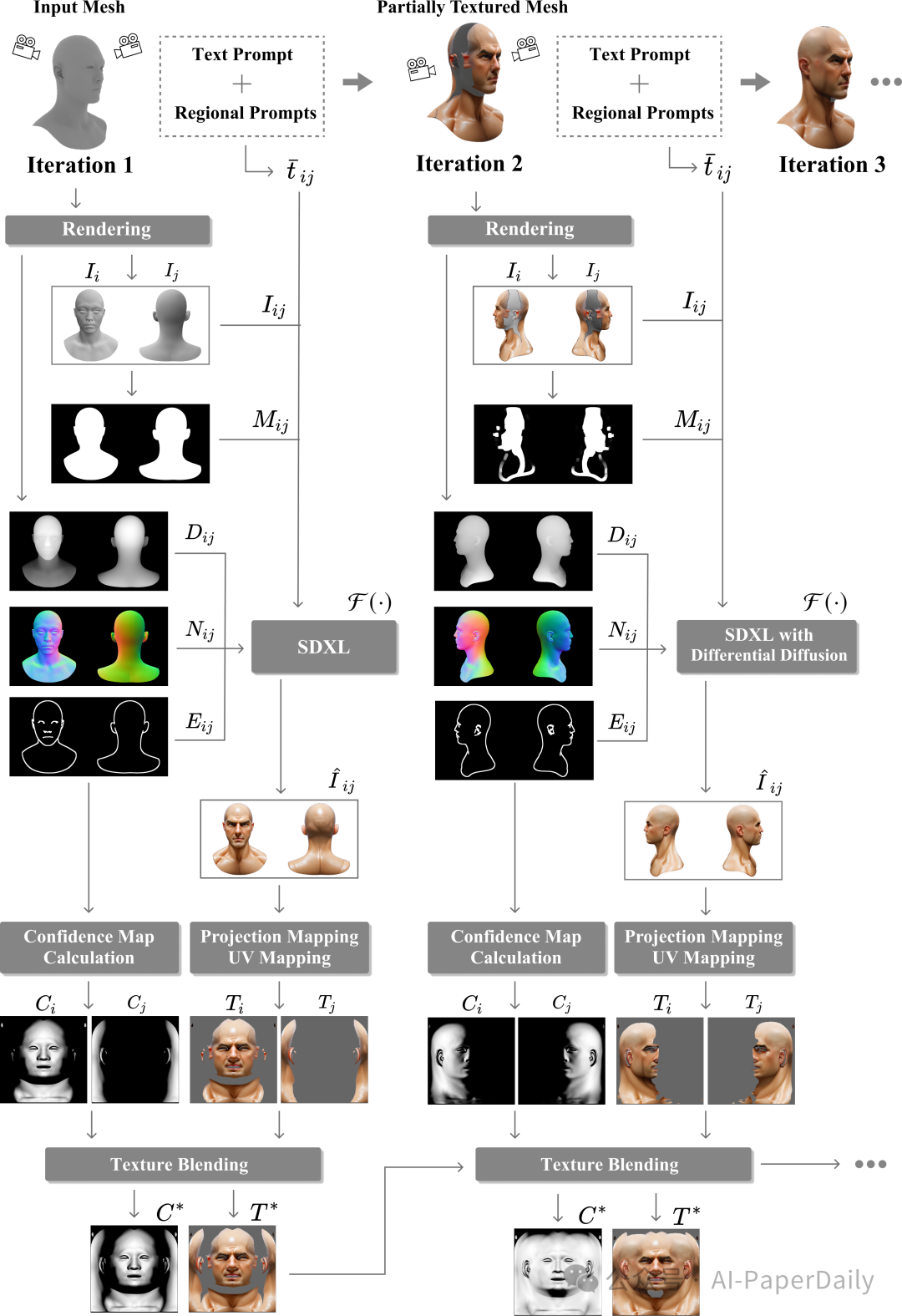
5. RoCoTex: A Robust Method for Consistent Texture Synthesis with Diffusion Models
~
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3448
3448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









