







文章目录
1.本章内容概要
本章将从一个统一的视角看待model-based RL(DP\heuristic search)和model-free RL(MC\TD)。Model-based方法主要通过planning(规划)方法,而model-free方法则更强调learning。他们也有相似之处:他们的核心都是值函数的计算;都是基于looking ahead未来事件,计算backed-up值,并用它作为update target估计值函数。前面单独介绍了MC和TD以及他们的结合n-step方法,本章则融合model-based和model-free方法,探索混合的方式。
这里提前说明一下,本章所指的 planning 和我们前面介绍的 learning 方法是类似的,只不过 planning 中经验来自于仿真模型,而 learning 中经验来自于实际环境。

2.模型和规划
给定一个state和action,model能预测下一个state和reward,模型可以是随机的也可以是确定的。有些models给出了所有可能性及他们的概率,这些叫做distribution models;另一些则只给出一个依概率的采样,这些叫做sample models。
DP假设的model就是distribution model,而blackjack例子中用的就是sample model。Distribution models比sample models更强大,可以用来产生样本,然而大多时候我们只能得到sample models,例如多个色子点数之和的问题,仿真这个过程很容易,然而求出最后和点数的分布却比较困难。
models可以用来模拟或者仿真经验;给定一个起始状态,则sample model可以给出一个episode,distribution model则可以给出所有的episodes和他们的概率。
planning在多个领域中都有定义,我们这里指给定一个模型求解或者改进策略的计算过程,在AI中,有两种planning方法:state-space planning,在状态空间搜索,以得到到达目标的最优策略或者路径,动作导致state transitions,value函数针对每个state计算;plan-space planning,采用规划而不是搜索的方法,把一个plan转化为另一个plan,值函数是针对plans空间定义的,包括进化方法(遗传算法什么的)、偏序规划等,这类方法难于高效地应用在随机序列决策任务中(强化学习核心问题),后面我们就不考虑了。
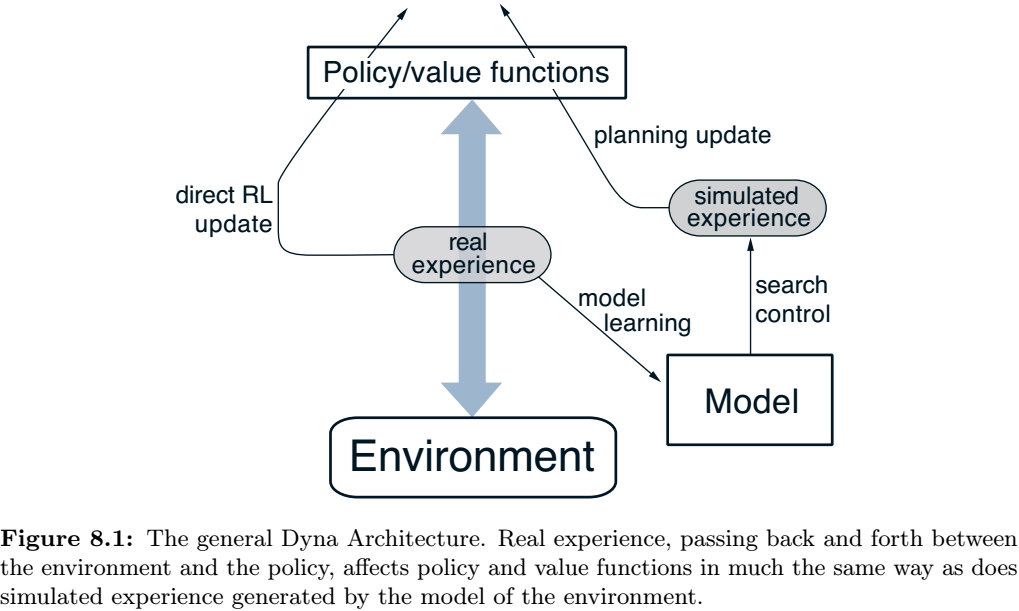
本章的统一视角:建立一个适用所有state-space planning方法的通用框架,有两个基本的思想:所有的state-space planning方法都通过计算值函数的方法提升策略;并基于仿真经验通过update或者backup操作计算值函数。下图给出了核心过程的框架。

DP方法是适用这个过程的,本章将说明各种的state-space planning方法都是适用这个框架的,不过是updates过程、顺序、backed-up信息保持多久有区别。
这样的视角实际上强调了planning方法和learning方法的关系,learning和planning方法的核心都是通过back-up update操作更新值函数,区别是planning使用模型的仿真经验,而learning使用实际环境经验,这也导致了一系列派生的差别。但是通用框架意味着很多思想和算法可以在planning和learning之间互换,尤其是,很多时候,learning算法可以将关键的update步替换为planning方法,learning方法只需要经验作为输入,而很多时候planning也可被feed以仿真的经验从而学习出模型,下面给出了一个基于one-step表格Q-learning的规划方法的例子,samples从sample model获得,叫做random-sample one-step tabular Q-planning,如果所有的state-action pair都被访问无穷多次,且α逐渐降低的话,能像one-step tablar Q-learning一样收敛到模型的最优策略。

除了研究统一框架,本章还分析了在planning中采用small incremental steps(增量式方法)的优势,这大大降低了计算量,且能更好地解决大规模问题。
3.Dyna:综合规划和学习的框架
当 planning 在线完成后,和环境交互时,从交互中得到的新信息可能会改变model并与planning相互作用。如果decision making和model learning都是计算敏感的,那么有限的计算资源必须要合理划分给它们。
这里给出Dyna-Q,一个简单的结合了在线planning agent所需主要功能的框架,Dyna-Q中的每个功能都是很简单的,后面我们会讨论如何实现这些功能及它们之间的权衡方法。
在一个planning agent中,真实经验有两个作用:提高模型精度(model learning)、利用RL方法估计值函数和提高策略(direct RL)。下图给出了将它们结合起来的框架,箭头表示影响关系,通过经验学习模型并规划从而指导值函数/策略的过程叫indirect RL。

direct方法和indirect方法各有优缺,indirect方法对有限经验利用得更充分,因此能在较少交互下找到更好的策略;而direct方法则更简单,且不容易受到模型偏差的影响。对这两个方法有很多争论,而本书作者认为我们不要过分夸大它们的差别,要注意到它们的相似之处。
Dyna-Q包含了上面图示所有的内容:planning、acting、model-learning和direct RL。planning方法是random-sample one-step tabular Q-planning方法(上面介绍的),direct RL方法是one-step tabular Q-learning,model-learning方法是table-based的并假设环境是确定性的,也就是给定 S t S_t St, A t A_t At查表出 R t + 1 R_{t+1} Rt+1, S t + 1 S_{t+1} St+1,只保存最后的观测。
在planning阶段,Q-planning算法随机从经验池中采样state-action对,注意model不能查询它从没有信息的pair。
下面给出了Dyna-Q算法的框架图。search control表示从所学表格中选择starting states和actions来产生仿真经验的过程。model是利用RL方法学习仿真经验实现的,planning则基于这个model,因此RL既从真实经验中学习,也从仿真经验中学习。这使得learning和planing深度融合了起来。
planning、acting、model-learning和direct RL在Dyna智能体中同步进行,acting、model-learning和direct RL的计算代价都较小,每个step的剩余时间都可以用来planning,我们假设剩余时间能完成n次planing,从而有如下算法伪代码。如果是serial计算机(时间片调度),则我们需要指定每个time step中的运算order。

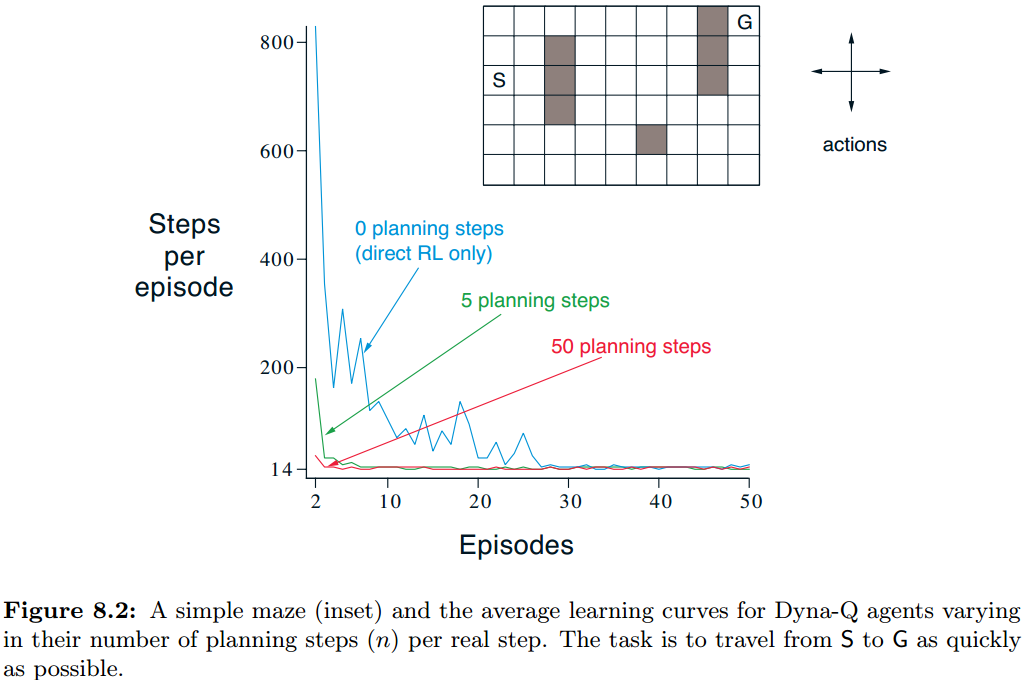
example 8.1 Dyna Maze
gridworld迷宫问题,动作为上下左右,一次移动一个格子,如果动作方向是障碍或者边界,则不移动,reward一直为0,除了到达goal时reward为+1且episode结束返回起点。折扣因子 γ = 0.95 \gamma=0.95 γ=0.95。
采用Dyna-Q框架解决这个问题。α=0.1,ε=0.1,变化planning的步数n,观察不同n的收敛曲线(纵坐标是steps数目,横坐标是episode序号,取30次run的平均)。所有repetition都用同样的随机种子,因此无论n为多少,第一个episode的steps都是一样的,图中没有显示出来这个,可以看到n越大算法收敛越快。
下图分析了为什么含有planning的智能体比nonplanning的智能体要快很多。第一个图是n=0的,由于每次eipsode目标信息只能向前传动1step,所以在episode2时只有与G挨着的grid是学习到的;而对于n=50的情况,则通过planning自动向前传播了很多steps,大大加速了学习的进度。

在Dyna-Q中,learning和planning都是通过相同的算法完成的,在real经验中的就叫learning,在simulated经验中的就叫planning。agent与real environment的交互是反应式的和审慎的,而planning和model的拟合在后台进行。
4.当模型是错的
上一节介绍的maze例子中,初始化model(也就是 S t , A t → R t + 1 , S t + 1 S_t, A_t \rightarrow R_{t+1}, S_{t+1} St,At→Rt+1,St+1映射表)为empty,然后填入观测到的正确信息,task中也没什么不确定性。而大多时候环境是随机的,而且只能观测到有限的samples,模型的函数估计器也可能有泛化误差,甚至环境会发生变化但是模型来不及改变,这些导致模型是不准确的,因而planning更像计算次优策略。
有时,planning计算出的次优策略导致模型误差的快速发现和矫正,当model对预测更大的reward和更好的state transitions比实际更乐观时这就能实现。下面举例说明(其中Dyna Q+后面再介绍):
example 8.2 Blocking Maze
对于maze问题,在1000个steps后,把障碍移动一下,这时即出现modeling error,图中曲线给出了平均累积回报的变化趋势(Dyna-Q和Dyna-Q+)。曲线前半段说明两个Dyna都找到了最短路径(斜率一样),环境变化后则曲线变平,agent在这段时间修复模型并重新寻找新环境下的策略。

当环境比以前更好时,Dyna无法改进策略(因为model实际上是更不乐观的),modeling error可能很长时间都不能被检测到并更正(概率非常低)。
example 8.3 Shortcut Maze
shortcut maze示意了当环境变好时的情况,迷宫中3000个steps后环境中出现了一条近路,然而Dyna受到错误model的影响,即使有ε-greedy帮助探索,探索性却不够发现新的短路,而Dyna-Q+则表现得很好。
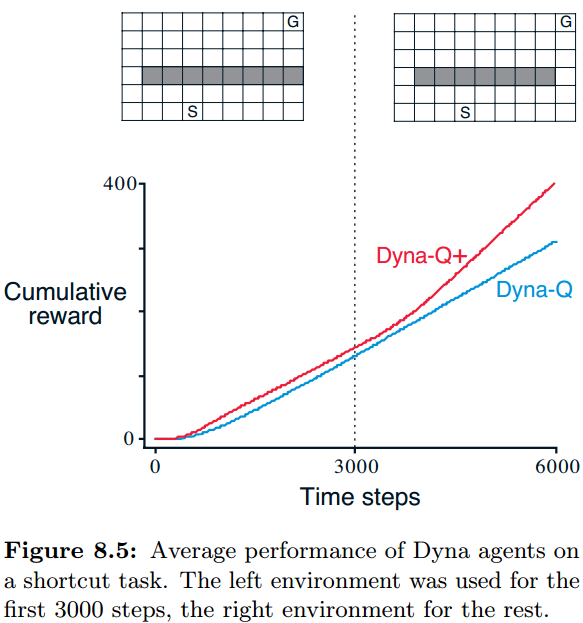
这个问题显示了探索和利用在另外角度的矛盾。在planning中,探索亦为之改进模型精度,而利用则基于模型探索更好的策略。我们希望agent能发现环境的变化,同时尽量少地降低其性能。与之前几章讨论的探索和利用的冲突一样,这可能没有好的解决办法,但是加入些启发信息会非常有效。
Dyna-Q+中引入了bonus reward的概念。对于每个state-action pair,我们记录其已经有多少steps没被访问了(在与真实环境交互中),记为 τ \tau τ, k k k是个小的系数,则我们把回报改为 r + k ∗ τ r+k*\sqrt{\tau} r+k∗τ。这种额外的探索虽然有代价,但是在一些问题中表现得很好。
5.优先权扫描
Dyna agent中的simulated transitions是从所有的经验state-action对中随机选取的,而有时候随机选择不一定是好的,如果更偏重于特定的某些state-action对,planning可能更高效。
拿之前第一版本的maze举例,从second episode开始就进行实质性地plan了,然而只有直接导向goal的state-action对才能有效更新,其它位置更新后仍然是0,因此随机地选择state-action对是低效的。对于更复杂的问题,如果我们随机选择,会导致更严重的低效率。
maze例子表明,如果从goal(或者任何能导致值变化的state)反向选取可能会不错。如果某个state的value改变了,意味着前面的一系列states的value也应该改变,但是注意通常one-step只能向前传播一步。因此,我们可以随机选择一个值发生改变/终结propagation的state-action对,然后反向依次选择更新,这叫做planning计算的backward focusing。
还需要注意,值变化的大小决定了这个状态的重要性,一个变化大的值会导致向前一串较大的更新;在随机环境中,模型估计的转移概率的变更,也对更新的变化量及紧迫程度有贡献。因此,利用紧迫性考虑更新次序是比较合适的,这叫做优先扫描prioritized sweeping。
用一个队列记录更新较大的state-action对。新的state-action根据优先性插入到队列中合适的位置;每次从queue的顶部选择pair更新,如果对前面state-action值的影响也超过了阈值,则把这个前辈也根据优先权插入到队列,如果已经在队列中存在,就保留最大优先权。这样就能高效更新了。

注意,对于确定性model,这个算法比较容易实现,因为我们能够确定地记录每个能导向状态S的 S ˉ , A ˉ \bar{S}, \bar{A} Sˉ,Aˉ对。
example 8.4 Prioritized Sweeping on Mazes
回到迷宫例子,这里不改变障碍物的分布,然后记录Dyna-Q和Prioritized sweeping找到最优策略的步数,画出曲线,可以看到本节提出的方法大大加速了找到最优策略的速度。

example 8.5 Prioritized Sweeping for Rod Maneuvering
杆机动问题,在有限的区域里,杆子要从起始位置移动到goal位置,只能水平移动、竖直移动、旋转,每次旋转正负10度,每次移动work space的1/20,这是个无随机性的问题。图中给出了最优策略,这是由prioritized sweeping得到的,而用unprioritized方法则求解起来太复杂了,因为可以上下左右各移动一格或者正负旋转,共14400种状态。

prioritized sweeping 可以直接扩展到随机环境中,model记录每个state-action对experienced的数量及下个states是什么(及次数);更新pair是利用expected update,考虑所有的下一步states和转移概率(次数)。prioritized sweeping是提高planning效率的一种分布计算方法,但不一定是最好的,它有局限性:它利用了expected updates,这导致在低概率转移上浪费大量计算,其实有时候sample updates在保证低计算量的同时,能比expected updates更靠近真实值,尽管它的方差大一些。
samples updates 能表现得更好,是因为把全局的 back-up 计算分解成了小的pieces,使得那些影响大的pieces发挥更大作用。如果这种单步的更新选择合理的更新顺序,有可能大大提高planning的效率。
我们现在已经看到,所谓state-space planning就是一系列值更新,不过是更新方式(expected or sample)、步长(small or large)、顺序的区别。本节介绍了backward focusing方法,其实还有别的方法,如forward focusing,把更新聚焦于从已经高频visited的states较容易达到的那些状态。
6.期望更新 vs. 采样更新
前面几个小节给出了一些结合learning和planning的方法,本章剩余部分则分析这其中的一些思想。首先分析expected和sample updates的相对优势。
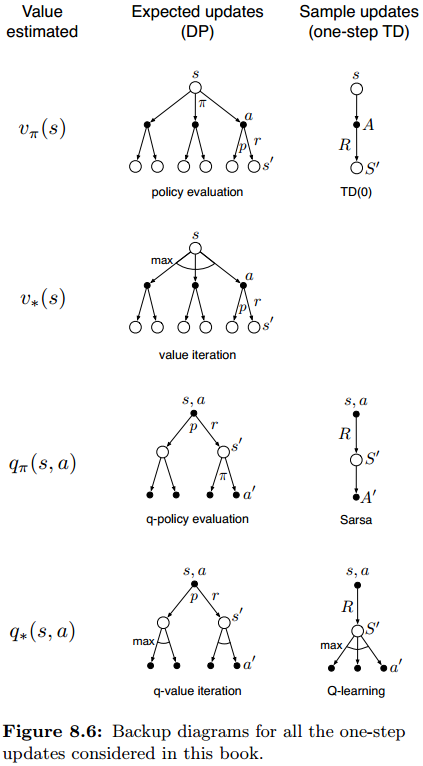
本书的大部分内容都在介绍各种各样的值函数更新,我们已经考虑了多种变体。对于one-step updates来说,主要有三个binary dimensions的区别:更新state values还是action values;估计最优策略的值还是任意给定的策略的值;更新expected updates还是sample updates。这共构成了八种组合,都与特定的算法相关(下侧的七个backup图)。这些方法都能用在planning中,对于随机问题,prioritized sweeping使用expected updates之一。
如果没有分布模型,则expected updates是无法实现的,而sample updates却可以(利用sample transitions)。一般我们倾向于使用expected updates,这似乎比sample方法要好,但是他们真的更好吗?
expected updates不会受到sampling error干扰,可以得到更好的估计,但是计算量也会更大,而计算资源在planning种是很受限的。为了正确评估expected/sample updates的优点,我们需要控制他们的计算资源,比较同等计算量下的效果。
我们考虑估计q*的问题,只分析离散states和actions,且用lookup-table表示值函数和model。下面分别给出了state-action对的expected update,和sample、Q-learning-like update。
Q ( s , a ) ← ∑ s ′ , r p ^ ( s ′ , r ∣ s , a ) [ r + γ max a ′ Q ( s ′ , a ′ ) ] Q(s, a) \leftarrow \sum_{s^{\prime}, r} \hat{p}\left(s^{\prime}, r | s, a\right)\left[r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)\right] Q(s,a)←∑s′,rp^(s′,r∣s,a)[r+γmaxa′Q(s′,a′)]
Q ( s , a ) ← Q ( s , a ) + α [ R + γ max a ′ Q ( S ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a)+\alpha\left[R+\gamma \max _{a^{\prime}} Q\left(S^{\prime}, a^{\prime}\right)-Q(s, a)\right] Q(s,a)←Q(s,a)+α[R+γmaxa′Q(S′,a′)−Q(s,a)]
expected和sample updates的区别受环境随机性影响。如果没有随机性,那我们可以设置α=1,这样expected和sample就是一样的,如果有随机性,则expected是精确求解的,只受到下一步值函数准确性的约束;而sample则还受到sampling error影响。sample的计算量较小,而expected的计算量受到branching factor b影响(s, a的后续状态转移概率不为0的个数),expected的计算复杂度是sample的b倍。
如果计算能力足够的话,expected是比sample好的,如果没有足够的时间计算(这往往是实际中的情形),则sample往往更好。
那么,在单位计算量下,是expected updates还是b倍的sample updates好呢?下图给出了分析,画出了分支数b不同时,值函数估计的RMS误差与 m a x a ′ Q ( s ′ , a ′ ) max_{a'}Q(s',a') maxa′Q(s′,a′)操作数量之间的关系图。
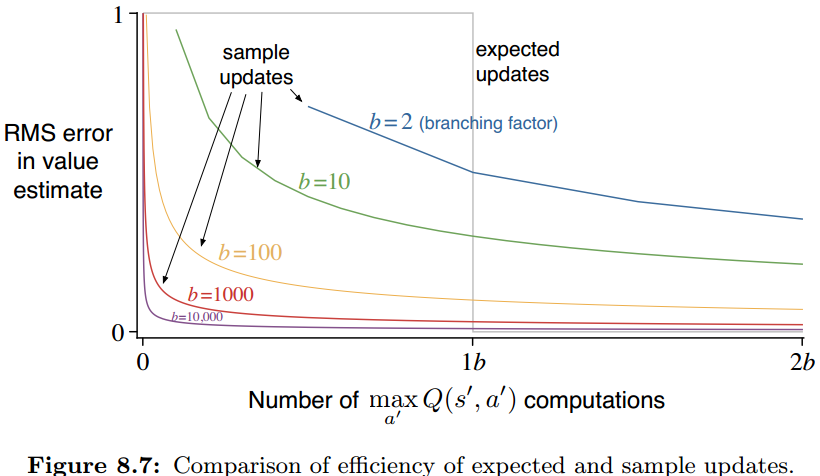
设定初始误差为1,后续状态误差为0,则expected在b个计算后直接RMS衰减到0,而在b较大时,sample在很小的计算下(远小于b)就能快速衰减,且最终会收敛到与expected差不太多的程度,其误差降低曲线公式为: b − 1 b t \sqrt\frac{b-1}{bt} btb−1,其中b表示sample updates的次数[这里的结果取 α = 1 / t \alpha=1/t α=1/t,也就是步长随着时间增长缩小]。因此在b较大时,sample比expected好很多。
此外,在实际问题中,后续states的值也是估计的,也是逐渐收敛的,固定步长sample update能更重视新近的更新。因此在大规模随机分支因子问题/有很多状态的问题中往往sample比expected要更优先考虑。
7.轨迹采样
这一节比较两种选择更新哪一个state值或者state-action对值的方法。
典型的是DP那种遍历穷举方法,但问题比较大时这是很有问题的,很多任务中大量的states都是没什么用的,因为他们只会在策略非常差的时候才出现,出现概率很低;原则上,更新可以按照我们希望的一个分布进行sweep,只要保证当时间趋于无穷时,每个state-action对都能被visited无数次以保证收敛就行,实际中exhaustive sweeps是常被采用的;
第二种方法是从state或state-action空间中根据某个概率采样(注意和sweep的区别)。可以随机采样,就像Dyna-Q智能体一样,但是这和exhaustive sweeps面临类似的问题;更好的方法是根据on-policy分布决定更新顺序,这种分布的优点是比较容易生成,只需遵循策略与环境交互就行了,也就是只更新依照当前策略遇到的那些states或者state-action对,我们管这种生成经验和更新的方法叫做trajectory sampling。
除了trajectory sampling,很难想出根据on-policy分布进行distributing updates的方法。这是因为:虽然如果我们有on-policy分布的明确形式,那么就能sweep所有的状态,并依据on-policy分布给update加权,但是这也会导致穷举sweeps的巨大计算;或许我们可以从分布中采样和更新state-action对,但是即使这可行,那与trajectory sampling相比有什么好处呢?其实想得到on-policy的分布也是不可能的,它随着策略提升而一直变化,计算分布则需要和完全的策略评估差不多的计算量。这让trajectory sampling看起来是最有效和优雅的。
但是按照on-policy分布的更新是好的吗?直觉上看至少比平均分布好(棋类游戏我们只关注可能出现的局势);Part2部分介绍的函数拟合方法则更显示出on-policy分布的重要优势。
example:
[这个例子原文描述得也很不清楚,主要了解其结论即可]
假定我们拥有准确模型,我们使用one-step tabular updates,对于平均分布更新,我们循环所有的state-action对,轮流更新;对于on-policy分布更新,所有的episodes从同一个state开始,无折扣地随机生成episodic任务。在任何状态s下,都有两个动作可选,每个state-action对都导致b个后续状态,对于所有的transitions,有0.1的概率到达terminal state,结束episode,每个transition的reward是从N(0,1)采样的。
下图给出了不同分支数时,平均分布和on-policy分布更新的收敛曲线(200个sample tasks上的平均),可以看到on-policy一开始都收敛很快,而且能维持较长时间的优势,尤其是b较小的时候,而当states变多的时候,也会导致持续得更久(下图),这是on-policy具有很大的优势。
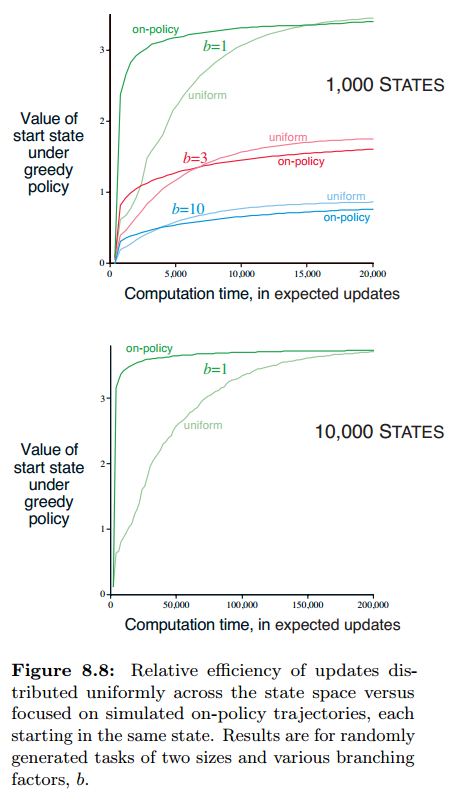
短期来看,on-policy分布帮助聚焦于start state的邻近后代状态,如果states数大且branching factor比较小,则会效果会持续很久;长期来看on-policy分布可能有害,因为总是在更新那些已经估计正确了的状态值,而不去探索未估计的,或许效果更好的值,因此至少对小问题,平均分布updates在长期来看效果更好。
8.实时动态规划
实时动态规划(Real-time Dynamic Programming,RTDP),是DP值迭代算法的on-policy trajectory-sampling版本,它和传统的sweep-based值迭代直接相关,因此RTDP清楚地展示了on-policy trajectory sampling能提供的优势。RTDP通过expected tabular值迭代更新修改visited states的值,上一小节图中的on-policy曲线就是RTDP产生的。
基于DP的一些理论可以解释RTDP,RTDP是异步DP算法的一个例子,即并不系统地sweep状态集,RTDP其实只按照在real或者simulated轨迹中的状态顺序更新。
如果只能从一个给定的start states集合开始轨迹,且根据指定策略完成预测问题,则on-policy trajectory sampling允许我们跳过那些在给定策略下无法从start states集合到达的状态。如图所示。对于控制问题,目标是寻找最优策略而不是评估给定策略,最优策略可能也有些状态不能到达,这种策略叫做optimal partial policy。
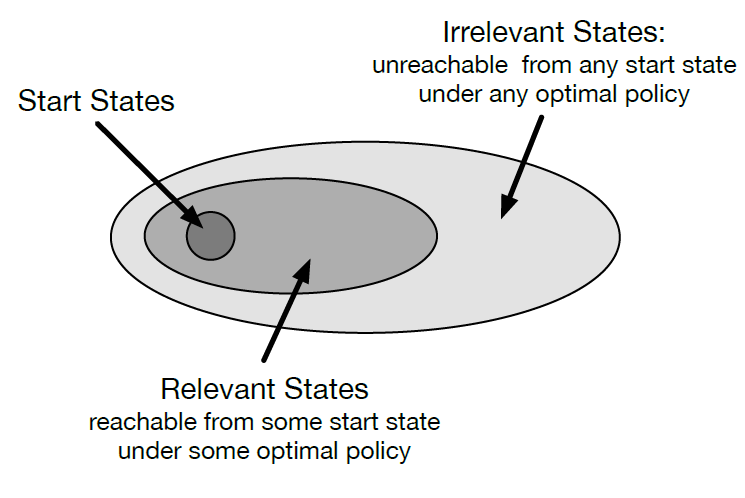
但是利用on-policy trajectory-sampling控制方法,找到这样的optimal partial policy(e.g. Sarsa)往往需要保证能够无数次访问所有的state-action对,即使是那些最优策略无法到达的。这可以通过exploring starts实现,对于RTDP也是这样的,exploring starts下可以证明RTDP能收敛到最优策略。
对于一些满足合理条件的特定类型问题,RTDP有时不需访问每个state无数次,甚至某些状态一次都不需要访问,实际上,在一些问题上,只有一小部分状态需要访问,这对于复杂问题来说是巨大的优势。
对于考虑absorbing goal states的episodic task,上面的结论也成立。在每个step,RTDP选择贪婪动作,然后利用expected value-iteration更新当前状态值,当然也可以向后搜索几步(只考虑有限几步能到达的状态,不要求在trajectory上),把后续部分状态也更新。
满足以下几个条件,则如果每个episode从start states集合随机选择起始状态,RTDP以概率1收敛到最优策略:1.初始时目标状态的值都是0;2.至少存在一个策略保证目标状态能以概率1从起始状态达到;3.所有起始于非目标状态的transitions的rewards都严格为负;4.所有的初始值都是相等的,或者比最优值大。
满足上述性质的任务叫做随机最优路径问题,我们常常用最小代价代替最大回报(这里用负数reward转换)来构造以上条件,典型问题:最小时间控制任务、最小杆数golf等。
RTDP是一种异步DP方法,它本质上是一种DP方法,不过是按照trajectory sampling选择更新那个状态动作对的值罢了,因此更新公式得按照DP那种求期望的方式。注意这和Expected Sarsa那种只对 π ( a ∣ s ) \pi(a|s) π(a∣s)求期望是不同的,RTDP要求必须已知模型。
example 8.6 RTDP on the Racetrack
寻找最短的从start到goal的路径问题就是随机最优路径问题,对比RTDP和DP的值迭代可以看到on-policy trajectory sampling的优势。我们前几章介绍了Racetrack问题,这里去掉车的速度限制,这样状态就是无限了,注意,在任何策略下从start states能到达的状态集合是有限的,这可以当作问题的状态集合,否则DP方法就无法工作了。
起点从起点线上每次都随机选取。到达终点线之前reward都是-1。下表给出了DP和RTDP解决这个问题的对比。DP使用穷举sweep,而RTDP只更新visited state。DP的收敛条件是一个sweep最大值更新小于10^-4,而RTDP则考虑20个episodes中到达终点线都不再变化。
两个方法都能找到14~15steps的好策略,但是RTDP比DP要少更新一半;RTDP中,有80.51%的状态更新不超过10次,290个状态从来没更新过。

RTDP的另一个优点是,随着估计的值函数靠近 v ∗ v^* v∗,智能体产生的轨迹逐渐达到最优,而DP方法的收敛条件则完全是考虑值函数的,因此有可能在收敛条件到达之前很久就已经得到最优策略了,这导致了计算的浪费,可以参考example 4.1理解。
在Racetrack例子中,如果每次DP sweep后做几次on-policy sweep,则可能提早发现DP是否已经得到了最优策略(接近最优的),这可以减少DP算法的updates数目,但是还是比RTDP多一些。
本节的讨论虽然不是确定性的对比,但是已经足以证明on-policy trajectory sampling比DP的优势,RTDP比DP的计算量要少一半左右。
9.决策时规划
本小节开始的内容都是为了引出rollout算法和Monte Carlo Tree算法,如果这些小节较难理解的话,建议先看完,最后结合rollout算法和Monte Carlo Tree算法理解。
planning可以有两种应用方式。
1.background planning。使用planning基于仿真经验逐渐提高策略或者值函数(DP, Dyna)。planning与实际的当前状态 S t S_t St无关,因为planning时的states都是根据我们设计的方式从states中选择的。
2.decision-time planning。planning从实际遇到的新状态 S t S_t St开始,planning此时的作用是选择动作 A t A_t At,然后在真实环境中执行并状态转移到 S t + 1 S_{t+1} St+1依此继续。一个最简单的情形是,当只有state-values可得到时,可以通过afterstates方法选择动作(Tic-Tac-Toe)。更一般地,planning的这种用法可以看得更深一些(向后多步推算),评估多种后续多步序列的好坏(树搜索)。注意,这种方法只着眼于特定的(当前的)状态。
这两种planning的方式(利用仿真经验渐进地提高策略和值函数; 利用仿真经验为当前状态选择动作)可以自然地融合起来,但是目前还是分别研究这两种方式的。
即使planning只在decision time进行,仍然可以视作从仿真经验中处理updates和values从而产生policy。只是value和policy是着眼于当前的状态和可选动作的,planning针对当前状态产生values和policy,用后就丢弃掉(前提是模型我们已知,例如棋类游戏,我们能根据模型推算出一系列的后续状态,根据仿真的结果对当前状态下采取什么动作提供指导,AlphaGo的Monte Carlo树就是这个思想的一个实例,后面介绍),这是因为很多应用由于状态空间巨大,我们很难再回到当前这个状态了,当然有时我们也可以记下来供后续使用。
在棋类游戏中,由于对决策速度不敏感,可以向后搜索很多步,因而decison-time planning是很可行的(搜索多步)。如果对时间比较敏感的话,还是background planning更合适一些,可以快速为遇到的状态生成策略。
10.启发搜索
AI中经典的状态空间planning方法就是decision-time planning方法,叫做启发式搜索。在启发搜索中,对于每个遇到的状态,都依概率扩展出后续序列的树。而估计出的value函数则在leaf节点上使用然后backup回当前状态(根节点)。搜索树上的backing up操作类似于最大化expected updates。
backing up在当前状态的state-action对处停止。这是就可以选择最好的动作了,然后丢弃刚刚计算的backed-up值。
在传统的启发搜索中,没有通过修改估计value函数来保存backed-up值的部分,value函数是完全人工设计的,而我们可以引入值函数估计的自动提升机制,这可以使用启发搜索的backed-up值或者本书介绍的任何其它方法。实际上,ε-greedy、greedy和UCB其实就是小规模启发的,例如对于贪婪策略,我们基于模型和状态值函数,我们搜索不同动作的即时回报与下个状态值,综合起来决策。这其实就在计算backed-up值,但是并没有存储。因此启发搜索可以看作贪婪策略的多步扩展。
搜索多步的目的是获得更好的动作,当模型很好而action-value函数较差时,多步搜索往往会提高决策效果。搜索k步,以至 γ k \gamma^k γk很小时,我们就得到了次优的策略,但这会导致计算量增大(backgommon AI TD-Gammon就是个很好的例子,搜索越深效果越好,耗时越长;但是即使搜索较浅,效果也还是不错的)。
我们应该注意,启发搜索是聚焦于当前状态的,因此效率很高。下棋时,我们往往只考虑后续一些动作和局面的一个子集,而这些是应该被优先update的,这不仅仅是因为计算力不足,也因为内存不足,因此实际当中我们不能存储所有的状态值,而只存储那些最可能遇到的状态值(这个问题可以通过神经网络部分解决了),这也使得启发搜索变得效率很高。
因此updates的分布只考虑当前状态和最可能的一些后续状态,我们可以构建一个搜索树,然后从下向上进行update,如果用表格表示各个状态值,并利用深度优先启发搜索,则可以实现全局更新。任何状态空间搜索都能看作把大量单独的one-step update综合在一起。注意性能的提高并不是因为多步更新,而是因为相关后续状态搜索使得搜索得更深,通过大量的候选动作的计算,decision-time planning可以提供更好的决策。

11.rollout算法
rollout算法是基于MC control的decision-time planning算法,用于simulated trajectories,且都从当前环境状态开始。这种方法在给定策略下,通过求这个状态下每个可能动作的后续仿真轨迹returns的均值评估动作,然后选择最好的执行。
rollout方法来自于backgammon游戏,即通过在某策略下虚拟地玩到游戏终结来评估这个位置的价值,而dice具有随机性,因此需要多次rolling out,用均值表示好坏。
和第五章介绍的MC控制方法不同,rollout并不估计完整的最优action-value函数q*/ q π q_\pi qπ,而是在给定策略下,只用MC方法估计当前状态的action values,该给定的策略叫做rollout policy。作为decision-time planning算法,rollout算法计算当前状态的动作值估计,使用它们,然后马上丢弃。这使得算法对存储要求小,且不需要估计整个的状态空间和状态-动作空间的值函数。
根据第四章讨论的策略提升原理,保持其它状态下的策略不变,只改变状态s下的策略,满足 q π ( s , a ′ ) ≥ v π ( s ) q_\pi(s,a')\geq v_\pi(s) qπ(s,a′)≥vπ(s),就能得到更好的策略,这就是rollout的基本原理,类似于one-step policy-iteration算法。也就是,rollout的目的不是找到最优策略,仅仅是提高rollout策略,实验表明这效果非常好(backgammon)。
有时即使rollout policy是随机的仍然能表现得很好,但是需要注意,rollout policy越好,MC估计的值越准确,那么rollout算法给出的策略越好。而这也是矛盾的,因为好的值估计需要更多的MC仿真,导致计算量很大;而作为decision-time planning算法,rollout算法的计算时间是不宽裕的。
对于任何rollout方法的应用来说,平衡这些因素是很重要的,虽然有多种方法可以减轻这个挑战。因为MC方法每个trial是彼此独立的,因而可以并行仿真;还可以基于存储的评估函数,截短仿真轨迹;剪枝掉没什么希望的候选动作,或者去掉那些值与当前最好动作相近的动作。
我们通常不把rollout方法当作learning算法,因为不存储反应长期效果的值/策略,但他反映了RL的一些特征:MC控制。这像通过trajectory sampling避免了穷举sweeps的DP,也不需要分布模型了。最后,rollout算法还吸收了值提升的方法。
12.蒙特卡洛树搜索
MCTS是近年来效果杰出的decision-time planning方法,它是一种rollout算法,但是加入了存储从MC仿真获得的值估计的均值,以指导仿真得到更高奖励的轨迹,在围棋中取得了出色的效果(Alpha Go),而MCTS已被证明可以用在多种类似的任务上(需要能快速多步仿真的模型)。
在每个遇到的状态执行MCTS以选择动作;作为一种rollout算法,每次execution都是一个迭代过程,从当前状态仿真很多轨迹直到终点(或者折扣到微不足道)。MCTS的核心思想是聚焦于从当前状态开始的多次仿真,扩展从之前仿真中找到的较好轨迹。MCTS不必存储值函数与策略,然而很多实现中都存储了。
对于大多部分,仿真轨迹中的动作都是用简单策略生成的,叫做rollout策略,如果rollout策略与模型不需要太多的计算,则可以仿真很多轨迹,像tabular MC方法一样,通过计算仿真returns的均值得到当前各种state-action对的值估计。MC值估计只保留几步内最可能达到的那些state-action对,构成一个从当前状态开始的树,MCTS增量地添加基于仿真轨迹最有希望的状态节点,所有仿真轨迹都会pass这个树然后从某个leaf节点离开,在tree外部和叶子节点处则通过rollout策略选择动作,而在树内部,就是那些我们有了一些动作值评估的节点,我们可以通过tree policy选择,以平衡探索和利用。tree policy可以采用ε-greedy或者UCB方法。

更具体地,MCTS每个迭代包含四个步骤:
1.选择:从root node开始,在tree内选择一条路径到达leaf node。
2.扩展:在某些迭代步,从选择的叶子节点扩展出一些新的节点。
3.仿真:从选择的节点和新加入的子节点,通过rollout策略仿真到终止。
4.回溯。计算return,回溯到root node。所有的rollout状态和动作都不保留,把最后的return直接反馈到树的叶子节点(rollout开始的地方)。
在规定时间内进行以上操作,最后根据树的累积统计特性选择动作执行(可以是从root开始树中最大q(s,a)的那个动作)。然后在下个状态,可以从之前的树把相关的部分裁剪出来,把新的状态作为root node。
MCTS最初是提出用来玩双人对抗游戏的,16.6节会介绍再AlphaGo中应用的结合ANN的自学习MCTS。
MCTS能取得这么好的效果,因为是基于MC control的decision-time planning算法,是一种rollout算法,从而具有online、incremental、sample-based值估计和策略提升的优势;此外,它存储了树上边的action-value的估计并利用RL sample updates更新,这使得MC轨迹实验可以聚焦于那些可能具有更好return的轨迹(先前仿真得到的);而且扩展tree,MCTS可以存储部分action-value函数,即用有限内存存储较好的sample轨迹。因此MCTS避免了全局估计值函数,并保留了使用过去经验引导探索的好处。
13.总结
planning需要环境的模型(sample model/distribution model),模型存储状态转移和回报。DP需要概率模型因为它采用了expected updates,而sample model可以支持sample updates中仿真与环境的交互,且更容易获得。
本章介绍了learning和planning之间的关联,他们都需要估计值函数,都可以通过backing-up操作增量地逼近。这使得我们可以令learning和planning更新同一个值函数,所有的learning都可以转化为planning方法(从仿真经验中学习)。
很容易想到把增量规划方法与acting/model-learning结合起来。planning、acting和model-learning按照环状交互,每个都提供另一个提升需要的数据。很自然的方法是把这三者的交互异步并行处理。
本章接触了很多state-space planning方法的各种维度的变体。其中更新规模是很重要的,越小的话planning就需要更多的增量,最小的更新是one-step sample更新(Dyna);另一个重要的维度是updates的分布,也就是搜索的区域。Prioritized sweeping反向寻找最近被更新的值的predecessors;on-policy trajectory sampling则着眼于agent在实际中遇到的state和state-action对,可以避免一些无关区域的计算;RTDP是一种on-policy trajectory sampling版本的值迭代方法,表现了on-policy方法相对于sweep-based值迭代的优势。
planning还可以向前着眼于相关的状态/状态-动作对,例如那些再实际中会遇到的状态,这种思想最终要的形式是在dicision time执行planning的,用planning来选择要执行的动作,这有几种典型的方法:启发搜索、rollout算法、MCTS。















 1372
1372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









