







前面几章已经讲了model-based (如:动态规划)和model-free (蒙特卡洛、时序差分)方法。这两种方法的区别在于计算价值函数的时候是否已知模型(这里指状态转移概率)。虽然这两种强化学习方法不同,但也有相同的地方,比如:两种方法的核心都在于计算价值函数,还都是根据未来的奖励来估算当前状态价值。
既然有相同之处,这两种强化学习方法能否统一起来呢?这就是本章的内容,其中,model-based方法视为规划方法,model-free方法视为学习方法。
文章目录
1. 模型与规划
模型是指能够对agent所处状态和动作做出反应的东西。也可以理解为模型是模仿环境来做一些反应的。
常见的有两种不同类型的模型,一种是抽样模型,一种是分布模型。
- 抽样模型:给定一个状态和动作,抽样模型给出即时奖励和agent下一时刻所处的状态。
- 分布模型:给定一个状态和动作,分布模型给出所有可能的即时奖励和所有可能的下一时刻状态,以及它们发生的概率。
模型可以用来仿真经验,即agent不需要和真实环境交互,而是跟模型交互。对于抽样模型来说,给定初始状态和动作,与模型交互,就可以得到这个经验序列(episode)。
规划是指通过agent和模型交互,产生仿真的经验序列,根据经验序列更新价值函数,更新策略。过程如下:

动态规划就满足上面的规划过程,其模型是分布模型。对于一个状态-动作对,模型会遍历所有可能的奖励和所有可能到达的下一个状态。利用这些状态转移来计算价值函数,并且迭代得到最优策略。
可以看出,规划和学习的区别在于:规划使用的是模型产生的模拟的经验;学习是使用agent和环境交互产生的真实经验。
下面给出了利用表格的一步规划算法过程,可以看出跟之前学过的Q-learning算法的唯一区别就在于状态转移是根据采样模型得到的。而Q-learning中,状态转移是和真实环境交互得到的。

2. Dyna: 规划和学习的统一框架
从上面的内容中可以看出,规划和学习的区别仅在于真实经验和仿真经验上。但两者都是可以用来计算价值函数、更新策略的,所以基于这样同一个目标,我们可以将规划和学习统一起来。框架如下:

上图可以看到,experience扮演了两个角色,一个是direct RL,即直接根据经验计算价值函数、更新策略。另一个是利用经验学习模型,然后利用模型进行规划,简介计算价值函数、更新策略。
整个过程还可以用下面的图来表示:

图中中间部分是和环境交互得到的真实经验,向左的箭头是direct RL,向右的indirect RL。
下面给出Dyna计算价值函数的伪代码,(d)是根据真实经验计算动作价值的,(f)是根据模拟经验计算动作价值的。

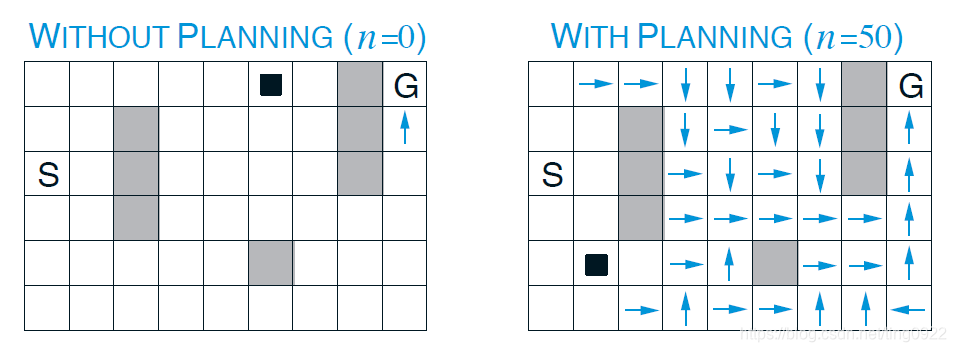
例子:方格游戏
任务目标是从起点S以最短的路径到达终点G,其中阴影的部分表示障碍物。这里主要想用这个例子来展示规划对于该任务的作用。
在上图中,蓝色的线是指没有进行规划的,仅使用真实经验计算价值函数、更新策略。绿色的线表示每进行一个direct RL,会进行5次规划。红色的线则是每进行一个direct RL,会进行50次规划。
可以看出,红色的线在刚开始的几个episode中就能够以很少的步数到达终点。
原因如下:
在第二个episode时,对于没有规划的学习来说,只有到达终点之前的一个状态的价值会更新,其他的还是0。但是对于有50步规划的方法来说,第二个episode就已经可以更新大部分状态的价值。

3. 当模型出错
模型其实是对环境的一个估计,模拟环境生成经验。但环境通常是随机的,会动态变化的。当环境发生变化,但模型还没有及时检测并调整,或是模型学到的价值函数不准确时,就会发生模型的错误。
当模型不正确时,规划过程会计算得到一个次优的策略,该策略会使得模型的错误更快的被发现和修正。下面给出两个例子,阐述在环境发生变化时,Dyna-Q等算法的表现。
3.1 环境变难
下图展示环境变化情况和各算法的调整。上左图是初始环境,从起始点S到终点G之间有右边的一条路可以连通。但在第1000个时间步,环境发生改变,原来的障碍物右移了一格,导致连通的路径改变。图的下半部分展示了两种算法随时间步的增加,累计奖励的变化情况。
其中,Dyna-Q算法是上一节中介绍的结合学习和规划的算法。Dyna-Q+算法是在Dyna-Q算法的基础上,考虑各个状态转移之间距离上次访问的时间,将奖励设置为 r + k τ r+k\sqrt{\tau} r+kτ,这里 r r r是即时奖励, k k k是一个很小的值, τ \tau τ表示已经有多少个时间步没有进行这个状态转移了。这样一个改变,就会鼓励agent去探索,相应的也能更好地应对环境的变化。
在上图中,1-1000个时间步,Dyna-Q和Dyna-Q+的累积奖励都在不断增加,且Dyna-Q+增加速度大于Dyna-Q。第1000个时间步时,环境发生变化,两个算法开始时都没有及时检测到变化,而是在尝试的过程中发现变化并调整。所以中间的一段累积奖励没有变化。调整后,各状态的价值函数发生了变化,从而适应了新的环境,累积奖励又不断增加。

3.2 环境变简单
初始环境中从起点S到终点G在左边有一条通路,在时间步3000时,环境发生变化,在S和G右边也出现了一条通路,这条路使得S和G之间路径更短。
上图给出了Dyna-Q和Dyna-Q+在环境变化前后得到的累积奖励。可以看出Dyna-Q在环境改变前后,并没有发生太大变化,Dyna-Q+累积奖励增加。
Dyna-Q中,模型已经探索到了右边路径是可以到达终点的, 那么就认为右边的相关状态价值更高,所以在规划的过程中,模型能给出的转移一直是右边通路的,即使在学习过程中使用了 ϵ \epsilon ϵ-greddy,也无法扭转局面。
但在Dyna-Q+中,agent会去尝试长时间没有访问到的动作,所以可以较快的检测到环境的变化,找到了一条更近的路径,累积奖励增加。

4. 优先遍历
前面涉及到规划过程总是在之前经历过的state-action pair中随机选择一个进行状态转移。但很多时候,并不是所有的state-action pair都要参与这一次的更新,可能更新之后值还是没有变化。比如方格游戏中,初始时,所有状态价值都为0,下一次更新时,只有终止状态的前一个状态的价值会得到更新,其他状态的价值仍然为0。所以这样的情况如果随机选择state-action pair就会导致计算浪费。
所以,每次更新的时候,应该对state-action pair有所侧重,怎样去选择影响最大的状态去更新呢?在方格游戏中,我们可以从终点状态倒推,去更新其他状态的价值。但有些情况下不存在终点状态,那么这种方法就不适用了。
所以,我们需要找到一种泛化性比较强的方法去计算所有的state-action pair的优先级,先更新优先级高的state-action pair。
要做到这件事情,我们需要做两件事情:一是要找到一种优先级计算的方法;二是要维护一个优先级队列,队列中的state-action pair根据其优先级排序。
优先级计算方法:根据之前的学习,可以知道如果一个状态的价值变化很大,那么它前面的状态价值也会有很大的变化。所以我们可以预测每个state-action pair的价值变化,根据价值变化大小插入到优先级队列中。
优先级队列:每次会选择队首的state-action pair进行更新,更新后调整队列。
下面给出确定环境下的优先级遍历算法伪代码:

上面的算法中,(e)步计算了状态S执行A动作的价值价值变化,如果变化大于一个阈值,就根据该变化值插入到优先级队列PQueue中。(g)步是进行规划的过程,取出队首的state-action pair,根据模型给出对应的状态转移,更新动作价值。然后对于所有可能到达状态S的state-action pair,计算其动作价值变化,如果超过阈值,也插入到优先级队列。
例子
下图展示了Dyna-Q算法和优先级排序算法在第2节的方格游戏中的表现。横轴是方格的大小(也是状态数),纵轴是在收敛到最优之前,两个算法对应的更新次数。
可以看出优先级遍历始终要比Dyna-Q的更新次数少。

5. 期望更新和采样更新
值函数的更新在强化学习的任务中是非常重要的,更新放方法也不相同。对于一步更新,总结来看,共有三个维度上的不同:
- 更新状态价值还是动作价值
- 估算给定策略的价值还是最优策略的价值
- 以期望更新还是采样更新
根据以上的三个维度,可以得到8种不同类别的更新方式,对应于下面给出的7种特定的算法(因为采样更新的方式没有办法直接计算最优策略的价值)。

期望更新相比采样更新会得到一个更好的估计,因为它不受采样的影响。但它往往需要更多的计算资源。所以需要权衡场景需求再选择这两种方式。
例子: Q ∗ Q^* Q∗的期望更新和采样更新
期望更新:
Q ( s , a ) ← ∑ s ′ P s s ′ a [ R s s ′
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1632
1632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









