







🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
1. 背景介绍
Zhang J, Wang K, Xu R, et al. Navid: Video-based vlm plans the next step for vision-and-language navigation[J]. arXiv preprint arXiv:2402.15852, 2024.
🚀以上学术论文翻译由ChatGPT辅助。
视觉与语言导航(Vision-and-language navigation, VLN)是具身人工智能(Embodied AI)中的核心研究问题,旨在使智能体能够根据自然语言指令在未知环境中进行导航。在这一领域中,泛化能力始终是一项长期挑战,无论是针对分布外的场景,还是从模拟到真实环境(Sim2Real)的迁移。
本文提出了一种基于视频的视觉语言大模型(VLM)——NaVid,以缓解上述泛化难题。NaVid 首次展示了 VLM 能够在 无需地图、里程计或深度信息 的条件下,达到当前最先进的导航性能。
在执行任务时,NaVid 仅依赖于机器人上搭载的单目 RGB 摄像头所提供的实时视频流,并依据人类语言指令输出下一步动作。该方法模拟了人类导航的方式,自然规避了由里程计噪声带来的问题,以及使用地图或深度信息造成的模拟到真实的迁移差异。
此外,我们的基于视频的方法能够有效地将机器人的历史观察编码为时空上下文信息,以支持决策制定与指令理解。在训练过程中,我们使用了来自连续环境中共计 51 万个导航样本,包括动作规划与指令推理数据,同时结合了 76.3 万规模的大型网页数据。
大量实验表明,NaVid 在仿真环境与真实世界中均实现了最先进的性能,并展现出卓越的数据集间迁移与 Sim2Real 能力。因此,我们相信该视觉语言大模型方案不仅为导航智能体规划了“下一步”,也为整个研究领域的未来发展提供了新方向。
作为具身人工智能(Embodied AI)中的基础任务之一,视觉语言导航(Vision-and-Language Navigation, VLN)[32, 70] 要求智能体根据自由形式的语言指令,在多样化、特别是未见过的环境中进行导航。这一任务要求机器人能够理解复杂多变的视觉观测,并同时解析细粒度的语言指令(如“go up the stairs and stop in the doorway”),因此一直是极具挑战性的研究课题。
为了应对这一挑战,大量研究 [85, 18, 104, 98, 69, 48, 4] 在简化设置中开展,即在离散环境中进行决策(例如在 MP3D 模拟器 [12] 中的 R2R [46])。具体而言,真实环境被抽象为连通图,导航任务被建模为图上航点的“瞬移”。尽管这些方法不断发展并取得了显著成果 [85, 121, 63, 104],但离散化环境的设置带来了额外的挑战,例如对地标图的依赖 [45, 47],以及需要本地模型完成地标之间的导航 [84, 87, 83]。
为实现更真实、自然的建模,在连续环境中进行导航(如 R2R-CE、RxR-CE)逐渐引起关注。尽管已有许多研究致力于缓解模拟到真实(Sim-to-Real)的差距 [47, 37, 108, 9],但仍面临严重的泛化挑战,这源于数据稀缺以及输入模态(如 RGBD、里程计、地图)之间的域间差异。
泛化问题是大规模真实世界部署中的关键挑战,包括:
- 从已见场景向新场景迁移;
- 从模拟环境向现实世界迁移(Sim-to-Real)。
近年来,**大规模视觉语言模型(VLM)**的发展在多个领域展现出前所未有的潜力 [109, 52, 3]。本文旨在探讨:大模型能否同样推动 VLN 向更强泛化能力方向发展。
本文贡献
我们首次尝试利用大规模基础视觉语言模型(VLM)的能力,将 VLN 泛化到真实世界,并提出了基于视频的导航智能体 NaVid。该模型仅依赖于机器人单目摄像头的视频流与自然语言指令,即能端到端地输出下一步动作。
我们将 NaVid 放置于以下三类模型的对比背景下:
-
与 AGI 类模型或“导航通才”模型对比:
- NaVid 是一个实用的视觉-语言-动作(VLA)模型,能推理出可执行动作及其参数(如移动距离、旋转角度),因而可直接部署于真实世界。
-
与使用大语言模型(LLM)作为导航规划器的 VLN 模型对比:
- NaVid 以连续环境中的真实建模替代离散空间建模;
- 其视觉观测以视频形式编码,而非文本描述 [69, 121, 63, 14]。
-
与现有专业化 VLN 模型对比:
- NaVid 完全不依赖深度信息、里程计或地图,从根源上避免了由此带来的泛化问题,使其更易于部署。
据我们所知,NaVid 是首个用于连续环境中 VLN 的基于视频的 VLM 模型,可在仅有 RGB 输入的条件下,实现类似人类的导航行为。
技术架构
NaVid 使用预训练的视觉编码器处理视频观测,并使用预训练的大语言模型(LLM)推理导航动作。通过这种方式,大规模预训练中获得的通用知识可以迁移至导航任务,提升学习效率和泛化能力。
我们借鉴了视频视觉语言模型 LLaMA-VID [57] 的设计思路:
- 每一帧图像由两类 token 表示:
- 指令相关 token:用于提取与当前指令高度相关的视觉特征;
- 指令无关 token:全局编码细粒度视觉信息,token 数量决定特征粒度。
NaVid 中历史观测帧的 token 数量可以与当前帧不同,从而使历史轨迹编码更具适应性和表达力,相比于之前方法中的文本描述或离散图结构,更符合视频建模的要求。
该建模方式对输入要求极高——不引入除视频之外的任何信息(如深度图、里程计或地图),因此可有效缓解泛化问题。
实验结果
我们在模拟和真实环境中对 NaVid 进行了大量评估,具体结果如下:
- 在 VLN-CE R2R 数据集上,NaVid 达到 SOTA 级别表现;
- 在 **跨数据集评估(R2R → RxR)**上也有显著提升;
- 在 Sim-to-Real 实验中,NaVid 仅使用 RGB 视频作为输入,在 4 个真实室内场景中完成 200 条指令,成功率约为 66%,表现出极强的现实部署能力。

II. 相关工作(Related Works)
Vision-and-Language Navigation(视觉语言导航)
大多数视觉语言导航(VLN)任务聚焦于在离散化的模拟环境中学习如何根据人类指令进行导航 [7, 49, 72, 97]。在这类环境中,智能体在预定义的导航图节点之间“瞬移”,通过对齐语言与视觉观测进行决策 [64, 101, 27, 96, 42, 29, 71, 35]。虽然这种方式在训练效率上具有优势,但将离散空间中训练的模型直接迁移到现实机器人系统中并不可行。
为提升现实性,研究者提出了连续环境中的 VLN(即 VLN-CE)[45, 81]。在这种设置下,智能体可以自由移动到模拟器中任何无障碍位置,具体方式包括:
- 预测底层控制动作 [78, 40, 15, 31, 16];
- 或从航点预测器估计的候选子目标中选择 [37, 47, 44]。
与此同时,受益于基于大规模图文对数据学习通用视觉-语言表示 [20, 56, 91, 53, 95] 的成功,许多 VLN 模型也引入了大型视觉语言模型(VLM) [55, 36, 18, 19] 以及面向 VLN 的预训练机制 [34, 67, 33, 107, 73]。
近期的研究显示,随着导航训练数据规模的扩大,VLN 智能体在权威数据集 R2R [46] 上的表现已接近人类水平 [104],这进一步增强了将 VLN 技术应用于实际机器人导航的可行性与紧迫性。
VLN 的 Sim-to-Real 迁移问题
尽管已有重大进展,目前大多数 VLN 方法仍然仅在仿真环境中构建与评估,忽视了现实世界的复杂性与不可预测性。在 Sim-to-Real 转移方面,目前系统性研究仍十分有限,目前唯一明确指出迁移难点的文献来自 Anderson 等人 [8],其揭示了由于动作空间与视觉域差异,导致现实环境中的成功率下降超过 50%。
此外,还有一个重要挑战在于对自然语言指令的泛化能力不足:即使训练数据高达百万量级,模型也常常无法理解风格不同的指令 [104, 41]。
为应对上述问题,许多最新研究开始利用大规模(视觉)语言模型的卓越泛化能力来提升 VLN 的适应性。具体方向包括:
- 探索大语言模型(LLM)本身的导航推理能力 [121, 69, 120, 63, 14, 82, 58];
- 将 LLM 以模块化方式集成至导航系统中,例如用于指令解析 [17] 或注入常识知识 [74]。
本文沿着上述方向进一步探索,尝试统一使用大模型来进行底层动作预测,并考察其在真实场景中的泛化能力。这种方法不仅致力于利用 LLM 的通用理解能力推动 VLN 的进展,也旨在缩小仿真环境与现实世界之间的性能鸿沟。
大模型在具身智能中的应用(Large Models as Embodied Agents)
近年来,研究者不断探索将大模型应用于多个具身智能场景 [26, 121, 59, 86, 90, 82, 39]。例如:
- PaLM-E [26]:将来自多模态的信息(如图像、文本)编码为 token,生成高层次的机器人指令,支持移动操控、路径规划、桌面操作等任务。
- RT-2 [11]:进一步发展为可生成底层动作的闭环控制系统,支持真实环境中的机器人部署。
- GR-1 [106]:构建了类似 GPT 的模型 [75, 121, 63],面向多任务、语言条件下的视觉机器人操控 [111],能够基于语言指令、图像观测和机器人状态预测动作与未来图像。
- RoboFlamingo [54]:提出了一种基于预训练视觉语言模型的操控策略学习框架,目标是构建高性能、低成本的机器人操控解决方案 [22, 94, 111, 89]。
- EMMA-LWM [112]:开发了一个用于驾驶代理的世界模型,通过语言交互进行控制,在数字游戏环境中取得了良好表现 [100]。
本文则聚焦于另一个关键具身智能任务:视觉语言导航(VLN),它要求机器人在未见过的环境中,精准理解人类语言指令并完成导航任务。
III. 问题定义(Problem Formulation)
本文研究的连续环境中的视觉语言导航任务(VLN-CE)可表述如下:
在时间步 t t t,给定一条由 l l l 个词组成的自然语言指令 I I I,以及当前的视觉观测序列 O t = { x 0 , x 1 , . . . , x t } O_t = \{x_0, x_1, ..., x_t\} Ot={x0,x1,...,xt}(视频帧序列),智能体需输出下一步的底层动作 a t + 1 ∈ A a_{t+1} \in \mathcal{A} at+1∈A,以推进导航并获得新的观测帧 x t + 1 x_{t+1} xt+1。
整个决策过程可建模为部分可观马尔可夫决策过程(POMDP),表示为 { x 0 , a 1 , x 1 , a 2 , … , x t } \{x_0, a_1, x_1, a_2, \dots, x_t\} {x0,a1,x1,a2,…,xt}。
在本任务中:
- 观测空间 O \mathcal{O} O 来自单目 RGB 相机采集的视频帧,无需额外传感器;
- 动作空间 A \mathcal{A} A 包括定性动作类型和定量动作参数(即低层控制动作 [45])。
这种设定模拟了人类视觉导航的自然范式:观测仅依赖视觉,而动作可直接执行。
IV. 所提出的 NaVid 智能体(The Proposed NaVid Agent)
为解决上述问题,本文提出了基于视频大模型的导航智能体 NaVid,首次将通用视频语言模型的知识迁移应用到现实导航任务中。
A. 整体架构
NaVid 构建于通用视频语言模型 LLaMA-VID [57] 之上,在其基础上集成任务特定模块以增强泛化能力。
如图 2 所示,NaVid 包括:
- 视觉编码器(采用 EVA-CLIP [92]);
- 指令感知查询生成器;
- 大语言模型(LLM);
- 两个跨模态投影器。
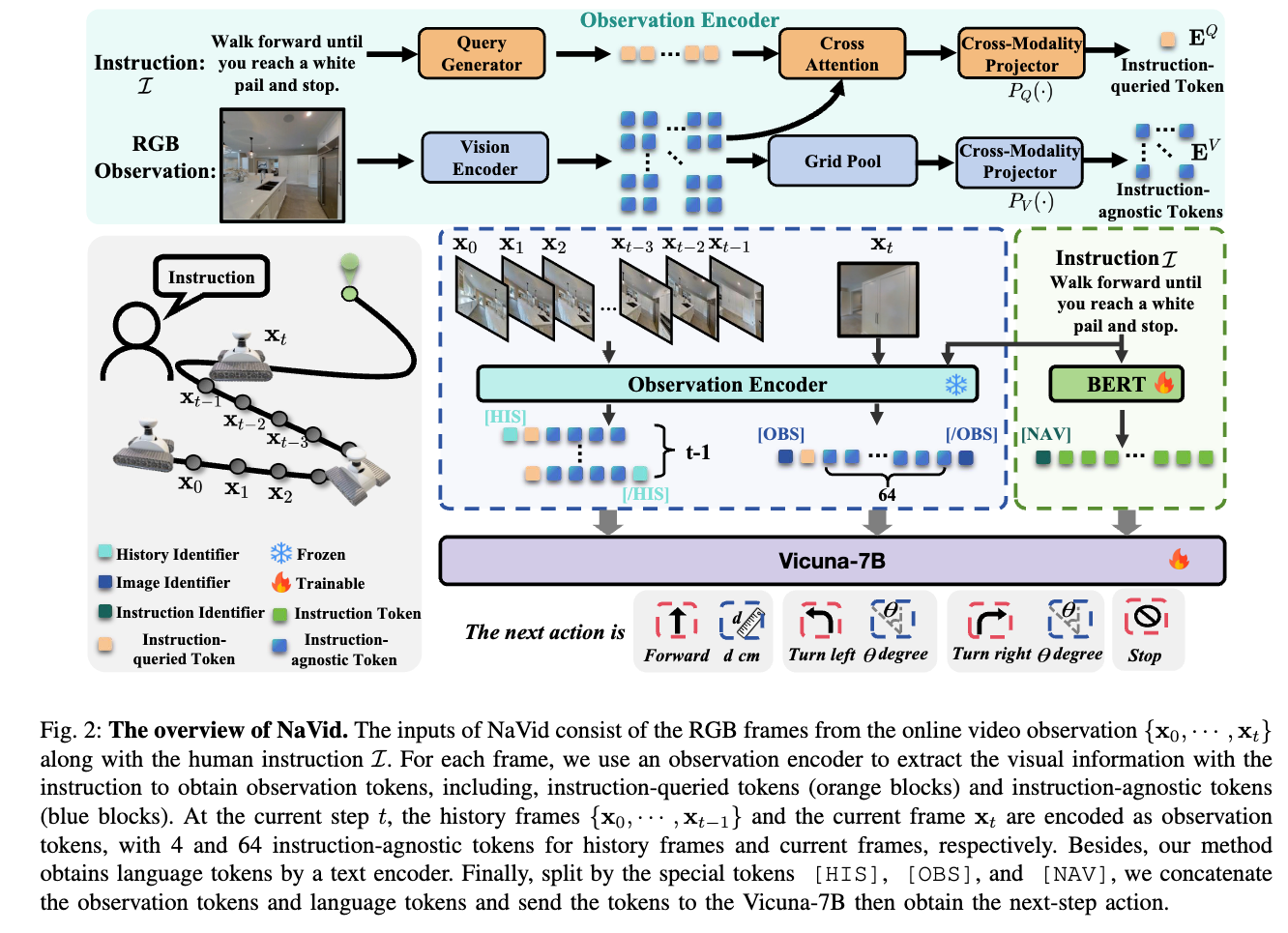
处理流程如下:
- 将时间步 t t t 前的视频帧输入视觉编码器,得到一组图像 token;
- 使用查询生成器生成与指令相关的查询向量;
- 将视觉 token 与语言指令 token 合并,输入 LLM;
- LLM 输出下一步的动作,格式为自然语言。
B. NaVid 的 VLN-CE 建模细节
观测编码
设当前视频帧序列为 O t = { x 0 , . . . , x t } O_t = \{x_0, ..., x_t\} Ot={x0,...,xt},每帧图像 x t x_t xt 经视觉编码器编码为 X t ∈ R N x × C X_t \in \mathbb{R}^{N_x \times C} Xt∈RNx×C,其中 N x = 256 N_x = 256 Nx=256 为 patch 数量, C C C 为嵌入维度。
- 指令相关(instruction-queried)token:
通过 Q-Former 模块生成查询 Q t Q_t Qt:
Q t = G Q ( X t , I ) Q_t = G_Q(X_t, I) Qt=GQ(Xt,I)
再通过交叉注意力获取最终 token:
E t Q = P Q ( Pool ( Softmax ( Q t X t ⊤ ) X t ) ) , E t Q ∈ R 1 × C E^Q_t = P_Q\left(\text{Pool}(\text{Softmax}(Q_t X_t^\top) X_t)\right), \quad E^Q_t \in \mathbb{R}^{1 \times C} EtQ=PQ(Pool(Softmax(QtXt⊤)Xt)),EtQ∈R1×C
- 指令无关(instruction-agnostic)token:
通过 Grid Pooling 压缩 patch token:
E t V = P V ( GridPool ( X t ) ) , E t V ∈ R N v × C E^V_t = P_V(\text{GridPool}(X_t)), \quad E^V_t \in \mathbb{R}^{N_v \times C} EtV=PV(GridPool(Xt)),EtV∈RNv×C
为增强几何信息表示,当前帧使用 64 个 agnostic token,历史帧使用 4 个。
特殊 token 标记机制
在输入 LLM 之前,使用以下特殊 token 组织数据:
<HIS>/</HIS>:标记历史帧 token;<OBS>/</OBS>:标记当前帧;<NAV>:引导 LLM 输出动作预测。
动作规划机制
NaVid 输出自然语言格式的动作,包含:
- 动作类型(从 {FORWARD, TURN-LEFT, TURN-RIGHT, STOP} 中选取);
- 定量参数(如前进距离、旋转角度)。
采用正则表达式解析动作 [43],可适用于验证与现实部署。
C. NaVid 的训练策略
由于 VLN 训练数据在多样性与真实性上仍有限,本文设计了一种混合训练策略,包含两项关键手段:
非 oracle 轨迹采样(Non-oracle Trajectory Collection)
借鉴 DAgger 策略 [80]:
- 首先使用 R2R 数据集采集 61 个 MP3D 场景下的 oracle 轨迹,共 32 万步;
- 在 oracle 轨迹上训练 NaVid;
- 将其部署在 VLN-CE 环境中,收集新的非 oracle 轨迹,得 18 万步;
- 合并两类数据进行最终训练(见图 3 上半部分)。

辅助任务协同训练(Co-training with Auxiliary Tasks)
为提升环境理解与指令匹配能力,引入两个辅助任务:
- 指令反推(Instruction Reasoning):根据视频轨迹预测原始指令(共 1 万条轨迹);
- 视频问答(Video QA):用于提升指令匹配能力与预训练知识保持(细节见 [57])。
D. 实现细节
训练配置
- 训练平台:24 块 NVIDIA A100;
- 总时间:约 28 小时,共计 672 GPU 小时;
- 视频数据帧率:1 FPS(去冗余);
- 模型:加载预训练的 EVA-CLIP、Q-Former、BERT、Vicuna-7B;
- 训练轮数:LLaMA 与文本编码器训练 1 个 epoch。
推理与评估
- 输出动作解析:基于正则表达式 [43],在 VLN-CE 的 val-unseen 上动作解析成功率为 100%;
- 实地部署:通过远程服务器运行 NaVid,控制机器人;
- 推理时延:约 1.2–1.5 秒每帧;
- 可使用量化等技术 [61, 60] 进一步加速。
V. EXPERIMENTS
A. Experiment Setup
Simulated Environments
我们在 VLN-CE 基准测试上评估所提方法,该测试提供了基于重建真实场景的连续模拟环境 [45],用于执行低层级动作。所用数据集包括两个广泛认可的基准:R2R [46] 和 RxR [49]。所有方法均在 R2R 的 10,819 条训练轨迹上训练,在 R2R val-unseen(1,839 条)与 RxR val-unseen(1,517 条)上测试,以评估跨分割与跨数据集的泛化能力。
Real-world Environments
为评估真实场景中的表现,我们复现 [8, 108] 的实验设置,涵盖多种室内场景与指令难度。选取 4 个典型场景(会议室、办公室、实验室、休息区),每个场景设计 25 条简单地标类指令与 25 条复杂组合指令,共 200 个测试用例。
平台采用 Turtlebot4,配备 Kinect DK 相机采集 RGB 与深度图像,里程计使用 RPLIDAR A1M8 和 Nav2 工具箱 [65]。更多细节见附录。
Metrics
采用标准 VLN 指标 [6, 7, 46, 50]:
- 成功率(SR)
- Oracle 成功率(OS)
- 成功率加权路径长度(SPL)
- 轨迹长度(TL)
- 与目标的导航误差(NE)
其中 SPL 是主指标。VLN-CE 中判定成功的范围为目标点 3 m 3m 3m 内,真实场景为 1.5 m 1.5m 1.5m。
Baselines
我们与以下基线方法对比:
- Seq2Seq [45]:基于 RNN 的 RGBD/仅 RGB 输入方法。
- CMA [45]:使用 cross-modal attention。
- WS-MGMap [16]:多粒度语义地图建模方法。
B. Comparison on Simulated Environment
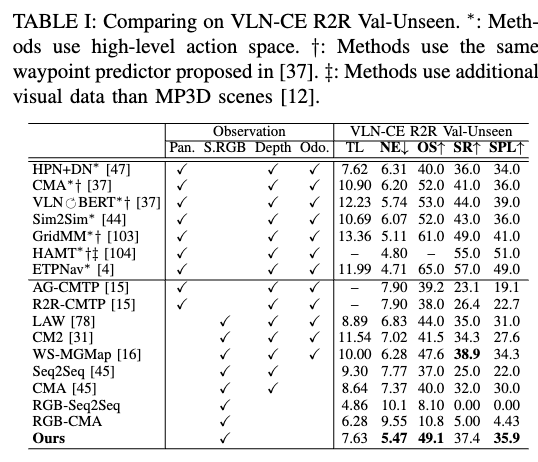
VLN-CE R2R
我们在 R2R val-unseen 上评估模型跨分割的泛化能力。结果显示,仅使用 RGB 的我们方法在 SPL、NE、OS 等指标上达成 SOTA,部分得益于与大规模视频数据协同训练,使得模型能处理更长时间窗口的历史信息。
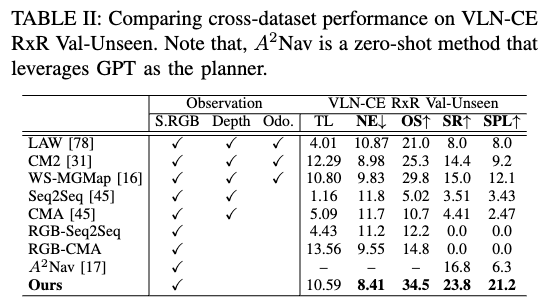
VLN-CE RxR
我们测试训练于 R2R 的模型在 RxR 上的 zero-shot 表现。RxR 指令更细致、轨迹更长。我们方法在 NE、OS、SR、SPL 上均大幅领先,SPL 比当前 SOTA(A2Nav)提升约 236 % 236\% 236%,证明了视频预训练模型在 VLN 中的泛化潜力。
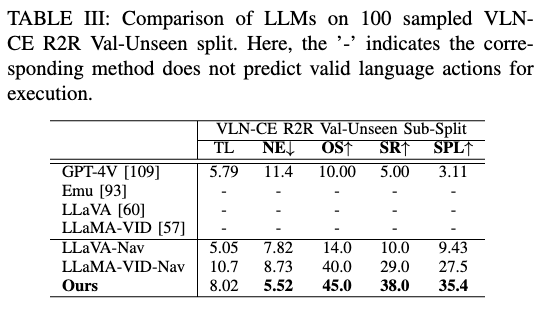
Comparison with Large Foundation Models
我们评估主流大模型(GPT-4V、Emu、LLaVA、LLaMA-VID)在 VLN 中的表现。原始模型在无导航数据训练情况下几乎无法执行动作,仅 GPT-4V 能勉强输出有效动作(5% SR)。经过导航数据微调的 LLaVA-Nav 与 LLaMA-VID-Nav 表现显著提升,LLaMA-VID-Nav 的有效动作输出率从 0 % → 91.3 % 0\% \rightarrow 91.3\% 0%→91.3%。
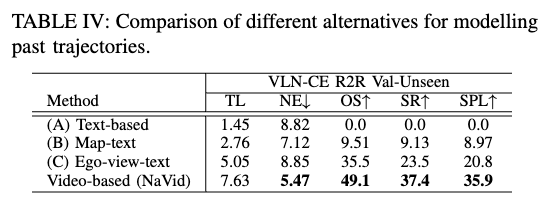
History Representation Ablation
我们分析不同历史建模方式对性能的影响:
- (A) 文字描述轨迹历史(SPL: 20.8%)
- (B) 文字 + Top-down 地图(SPL: 8.97%)
- © 文字 + 第一人称视角图像
- (D) 视频序列(本文方法,SPL: 35.9%)
结论:视频建模显著优于其他方式,既保留视觉细节,又能更高效执行推理(平均推理时间约减半)。
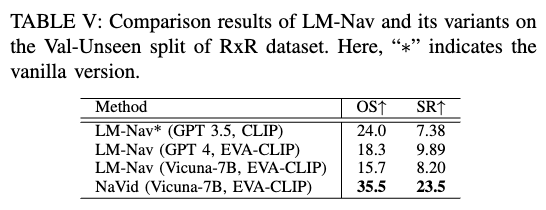
Comparison with LM-Nav and Variants
我们与 LM-Nav 系列方法比较,其基于离散环境和图结构。即便使用 oracle 地标,LM-Nav 仍在 RxR val-unseen 上被我们方法显著超越。主要原因在于:
- LM-Nav 忽视指令中的动词与空间关系;
- 复杂室内场景中的遮挡与同类物体容易误导其 landmark-based 导航策略。
C. Comparison on Real-world Environment
我们选取 Seq2Seq、CMA 和 WS-MGMap 三种方法,在 4 个场景下测试各 25 条简单与复杂指令。结果表明:
- 基于 end-to-end 的 Seq2Seq 与 CMA 在真实环境中效果极差;
- WS-MGMap 借助语义地图性能更稳定;
- 我们方法仅凭 RGB 视频即可完成 84 % 84\% 84% 总体任务与 48 % 48\% 48% 复杂任务,泛化能力强。
真实案例展示
- 图 5:在两个 stop 条件略有差异的指令下,NaVid 均准确完成任务。
- 图 6:面对具有语义相同物体的干扰目标,NaVid 成功执行转向并停靠正确位置。
- 图 7:更多真实世界导航样例展示,详见附录视频。
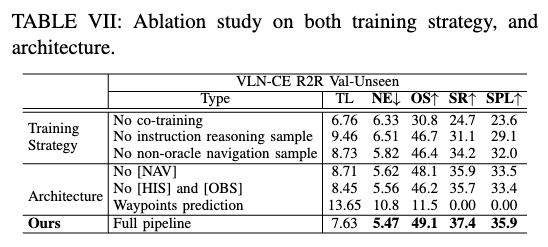
D. 消融实验
为了验证我们方法中各组件的有效性,我们在训练策略和网络结构两个方面进行了消融实验,结果列于表 VII。实验表明,联合微调数据(co-tuning data)对性能至关重要,缺乏这些数据将导致大模型丧失泛化能力。如预期所示,加入指令推理样本和 Dagger 的导航动作样本均提升了性能,这启发我们:进一步采集更多导航相关数据可能有望进一步提升模型表现,这也是未来 VLM 在 VLN 领域的一个重要方向。
在结构消融实验中,我们保留了内容 token(包括指令相关 token 和非指令 token),移除了特殊 token(任务标识 token [ NAV ] [\text{NAV}] [NAV],观察标识 token [ HIS ] [\text{HIS}] [HIS] 和 [ OBS ] [\text{OBS}] [OBS])。我们发现移除这些特殊 token 会导致明显的性能下降,证明其设计是有效的。Waypoint 预测变体将原始动作输出替换为连续位置和朝向(详见补充材料)。然而实验结果显示,这种连续位置和朝向的回归对 VLM 构成极大挑战,VLM 难以学习导航技能。
为了进一步评估“指令无关视觉 token”的有效性,我们测试了不同设置下的视觉 token 数量。我们分别使用每帧 1、4、16 个 token,对应对特征图进行平均池化,步长为 H H H、 H / 2 H/2 H/2 和 H / 4 H/4 H/4。结果见表 VIII,更多的视觉 token 能提升性能,因为提供了更丰富的视觉信息以支持动作预测。
- 从设置 (1) 到 (2):成功率提升了 56.4%,推理时间成本提升了 40.2%;
- 从设置 (2) 到 (3):成功率仅提升了 1.6%,但推理时间成本却提升了 122%。
这表明每帧使用 4 个视觉 token 是在性能与效率之间的最佳平衡点。
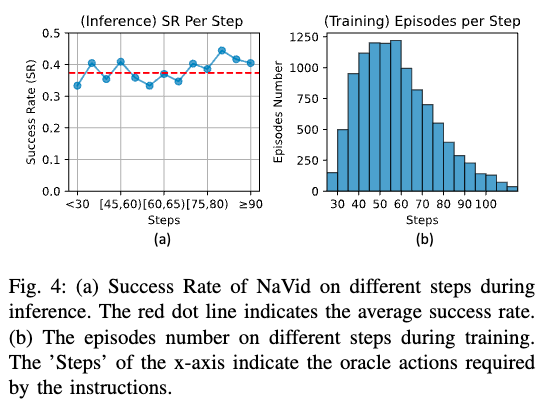
我们还进行了分阶段训练实验(见图 8),以分析导航数据的作用。我们将训练分为两阶段:预 Dagger 阶段(0 到 33 万步)与后 Dagger 阶段(33 万到 51 万步)。在预 Dagger 阶段中,随机采样导航数据训练,结果显示,当样本量少于 28 万时,SR、OS、SPL 和 NE 提升缓慢;当样本量达到 33 万时,性能明显提升,说明模型逐渐掌握了 VLN 任务。后 Dagger 阶段性能提升有限,原因是 R2R 训练集中的 Dagger 样本环境与指令信息有限,无法继续扩展模型的泛化能力。




VI. 讨论与结论
本文提出了一种基于视频的视觉语言导航方法 NaVid,该方法在不依赖里程计、深度信息或地图的条件下,达到了 SOTA 导航性能。具体而言,NaVid 将视频形式的历史导航轨迹与当前观测信息融合,并设计了自定义的特殊 token 实现轨迹建模与任务标识。在训练方面,我们收集了来自 R2R(32 万)与 Dagger(18 万)共 51 万条动作规划样本,以及 1 万条指令推理样本,以提升模型的视觉-指令理解能力。
- 在模拟环境中,NaVid 展现了仅使用单目视频输入也能达到 SOTA 的性能。
- 在真实世界环境中,NaVid 展现出良好的泛化能力,能够完成复杂的 VLN 任务。
局限性
尽管效果显著,NaVid 仍存在以下问题:
- 计算开销高,导致推理延迟较长,影响实际导航效率。可以通过引入 action chunk 技术 [119] 或量化技术 [61] 进行优化。
- 处理极长指令时性能下降,主要由于上下文 token 长度限制 [25],且缺乏高质量长视频标注数据加剧了此问题。未来可通过采用更先进的大模型 [57] 和使用长视频数据 [102] 进行缓解。
未来工作
我们将进一步探索 NaVid 在其他 embodied AI 任务中的应用潜力,如移动操控(mobile manipulation)任务 [110, 88, 116]。为此,我们将研究支持机器人手臂与底盘联合控制的动作设计,并采集一批具备物理交互标注的视频数据,帮助模型理解操作指令与环境交互。同时,我们还将持续提升模型运行效率,使其能在低成本硬件上更高速运行。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!




















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











