









前言
非专业选手,此篇博文内容基于书本和网络资源整理,可能理解的较为狭隘,起点较低,就事论事。如发现有纰漏,请指正,非常感谢!!!
查看Apollo中关于MPC_controller的代码可以发现,它的主体集成了横纵向控制,在计算控制命令时,计算了横纵向误差:
ComputeLongitudinalErrors(&trajectory_analyzer_, debug);
ComputeLateralErrors(com.x(), com.y(),
VehicleStateProvider::instance()->heading(),
VehicleStateProvider::instance()->linear_velocity(),
VehicleStateProvider::instance()->angular_velocity(),
trajectory_analyzer_, debug);
下文将从MPC原理入手,结合横纵向控制进行分析。
模型预测控制
可以先结合官方的教学视频对MPC进行一个简单的了解:模型预测控制。
根据维基百科,模型预测控制是一种先进的过程控制方法,在满足一定约束条件的前提下,被用来实现过程控制,它的实现依赖于过程的动态模型(通常为线性模型)。在控制时域(一段有限时间)内,它主要针对当前时刻进行优化,但也考虑未来时刻,求取当前时刻的最优控制解,然后反复优化,从而实现整个时域的优化求解。
也就是说,模型预测控制实际上是一种时间相关的,利用系统当前状态和当前的控制量,来实现对系统未来状态的控制。而系统未来的状态是不定的,因此在控制过程中要不断根据系统状态对未来的控制量作出调整。而且相较于经典的的PID控制,它具有优化和预测的能力,也就是说,模型预测控制是一种致力于将更长时间跨度、甚至于无穷时间的最优化控制问题,分解为若干个更短时间跨度,或者有限时间跨度的最优化控制问题,并且在一定程度上仍然追求最优解1。
可以通过下图对模型预测控制进行一个简单的理解:
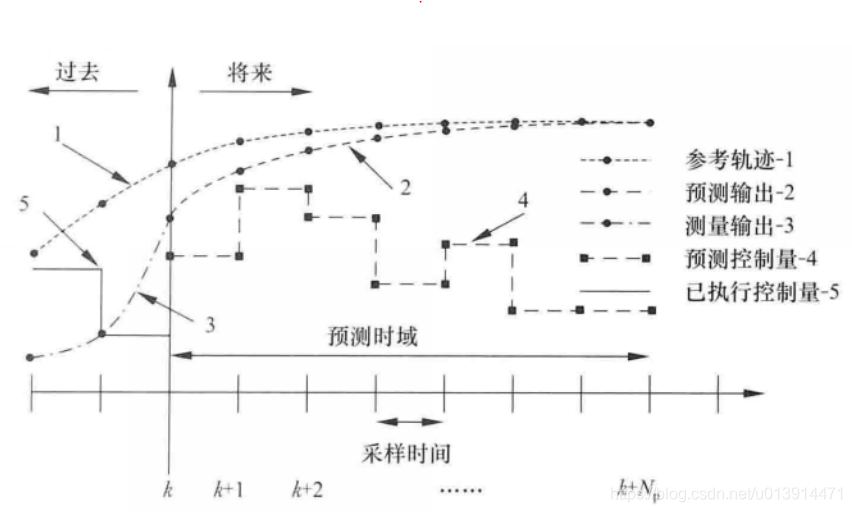
图1中,k轴为当前状态,左侧为过去状态,右侧为将来状态。可结合无人驾驶车辆模型预测控制2第3.1.2节来理解此图。
模型预测控制在实现上有三个要素:
- 预测模型,是模型预测控制的基础,用来预测系统未来的输出;
- 滚动优化,一种在线优化,用于优化短时间内的控制输入,以尽可能减小预测模型输出与参考值的差距;
- 反馈矫正,在新的采样时刻,基于被控对象的实际输出,对预测模型的输出进行矫正,然后进行新的优化,以防模型失配或外界干扰导致的控制输出与期望差距过大。
下面从三要素入手对模型预测控制进行分析。
预测模型
无论是运动学模型,还是动力学模型,所搭建的均为非线性系统,而线性模型预测控制较非线性模型预测控制有更好的实时性,且更易于分析和计算。对于无人车来说,实时性显然很重要,因此,需要将非线性系统转化为线性系统,而非线性系统的线性化的方法大体可分为精确线性化和近似线性化,多采用近似的线性化方法。
线性化
此部分内容主要参考《无人驾驶车辆模型预测控制》23.3.2节,本人对对线性化、离散化等问题也理解的不深,不理解的可以自行查找一些其他的文章。
非线性系统线性化的方法有很多种,大致分为:
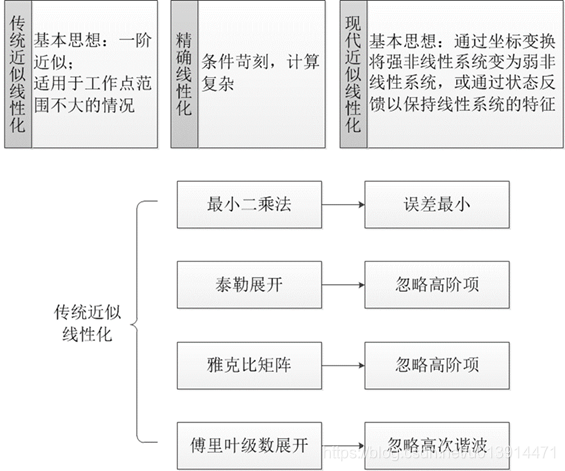
下面以泰勒展开的方法为例,结合《无人驾驶车辆模型预测控制》23.3.2节非线性系统线性化方法,展示一种存在参考系统的线性化方法。存在参考系统的线性化方法假设参考系统已经在规划轨迹上完全跑通,得出每个时刻上相应的状态量 X r X_r Xr和控制量 U r U_r Ur,然后通过处理参考系统与当前系统的偏差,利用模型预测控制器来跟踪期望路径。
假设车辆参考系统在任意时刻的状态和控制量满足如下方程:
(1)
X
˙
r
=
f
(
X
r
,
U
r
)
\dot{X}_r=f(X_r, U_r) \tag{1}
X˙r=f(Xr,Ur)(1)
在任意点
(
X
r
,
U
r
)
(X_r, U_r)
(Xr,Ur)处泰勒展开,只保留一阶项,忽略高阶项,有:
(2)
X
˙
=
f
(
X
r
,
U
r
)
+
∂
f
∂
X
(
X
−
X
r
)
+
∂
f
∂
U
(
U
−
U
r
)
\dot{X}=f(X_r, U_r)+\frac{\partial f}{\partial X}(X - X_r)+\frac{\partial f}{\partial U}(U - U_r) \tag{2}
X˙=f(Xr,Ur)+∂X∂f(X−Xr)+∂U∂f(U−Ur)(2)
公式2与公式1相减可得:
(3)
X
~
˙
=
A
(
t
)
X
~
+
B
(
t
)
U
~
\dot{\widetilde{X}}=A(t)\widetilde{X}+B(t)\widetilde{U} \tag{3}
X
˙=A(t)X
+B(t)U
(3)
其中,
X
~
˙
=
X
˙
−
X
˙
r
\dot{\widetilde{X}}=\dot{X}-\dot{X}_r
X
˙=X˙−X˙r,
X
~
=
X
−
X
r
\widetilde{X}=X-X_r
X
=X−Xr,
U
~
=
U
−
U
r
\widetilde{U}=U-U_r
U
=U−Ur,
A
(
t
)
A(t)
A(t)为
f
(
X
,
U
)
f(X, U)
f(X,U)对
X
X
X的雅克比矩阵,
B
(
t
)
B(t)
B(t)为
f
(
X
,
U
)
f(X, U)
f(X,U)对
U
U
U的雅克比矩阵。
此时,通过雅克比矩阵,将非线性系统近似转化为一个连续的线性系统,但并不适于模型预测控制器的设计,然后对其离散化处理可得,
(4)
X
~
˙
(
k
)
=
X
~
(
k
+
1
)
−
X
~
(
k
)
T
=
A
(
k
)
X
~
(
k
)
+
B
(
k
)
U
~
(
k
)
\dot{\widetilde{X}}(k)=\frac{\widetilde{X}(k+1)-\widetilde{X}(k)}{T}=A(k)\widetilde{X}(k)+B(k)\widetilde{U}(k) \tag{4}
X
˙(k)=TX
(k+1)−X
(k)=A(k)X
(k)+B(k)U
(k)(4)
得到线性化时变模型:
(5)
X
~
(
k
+
1
)
=
A
~
(
k
)
X
~
(
k
)
+
B
~
(
k
)
U
~
(
k
)
\widetilde{X}(k+1)=\widetilde{A}(k)\widetilde{X}(k)+\widetilde{B}(k)\widetilde{U}(k) \tag{5}
X
(k+1)=A
(k)X
(k)+B
(k)U
(k)(5)
其中:
A
~
(
t
)
=
I
+
T
A
(
t
)
,
B
~
(
t
)
=
T
B
(
t
)
,
I
\widetilde{A}(t)=I+TA(t) ,\widetilde{B}(t)=TB(t),I
A
(t)=I+TA(t),B
(t)=TB(t),I为单位矩阵。
至此,得到一个非线性系统在任意一参考点线性化后的线性系统,该系统是设计模型预测控制算法的基础。
以运动学模型中的式1.15为例,低速情况下的车辆运动学模型可表达为:
(6)
[
x
˙
y
˙
ψ
˙
]
=
[
cos
ψ
sin
ψ
tan
δ
f
/
l
]
v
\begin{bmatrix} \dot{x} \\ \dot{y} \\ \dot\psi \end{bmatrix}= \begin{bmatrix} \cos\psi \\ \sin\psi \\ \tan{\delta_f}/l \end{bmatrix}v \tag{6}
⎣⎡x˙y˙ψ˙⎦⎤=⎣⎡cosψsinψtanδf/l⎦⎤v(6)
其状态变量和控制变量分别为:
X
=
[
x
y
ψ
]
,
U
=
[
v
δ
f
]
X= \begin{bmatrix} x \\ y \\ \psi \end{bmatrix}, U= \begin{bmatrix} v\\ \delta_f \end{bmatrix}
X=⎣⎡xyψ⎦⎤,U=[vδf]
对应的雅克比矩阵:
(7)
A
=
[
0
0
−
v
sin
ψ
0
0
v
cos
ψ
0
0
0
]
,
B
=
[
cos
ψ
0
sin
ψ
0
tan
δ
f
l
v
l
cos
2
δ
f
]
A= \begin{bmatrix} 0 & 0 & -v\sin{\psi} \\ 0 & 0 & v\cos{\psi} \\ 0 & 0 & 0 \end{bmatrix}, B= \begin{bmatrix} \cos{\psi} & 0\\ \sin{\psi} & 0\\ \frac{\tan{\delta_f}}{l} & \frac{v}{l\cos^2{\delta_f}} \end{bmatrix} \tag{7}
A=⎣⎡000000−vsinψvcosψ0⎦⎤,B=⎣⎡cosψsinψltanδf00lcos2δfv⎦⎤(7)
其线性时变模型为:
X
~
˙
=
A
~
X
~
+
B
~
U
~
\dot{\widetilde{X}}=\widetilde{A}\widetilde{X}+\widetilde{B}\widetilde{U}
X
˙=A
X
+B
U
其中,
(8)
X
~
=
[
x
−
x
0
y
−
y
0
ψ
−
ψ
0
]
,
U
~
=
[
v
−
v
0
δ
f
−
δ
f
0
]
,
A
~
=
I
+
T
A
=
[
1
0
−
v
sin
ψ
T
0
1
v
cos
ψ
T
0
0
1
]
,
B
~
=
T
B
=
[
cos
ψ
T
0
sin
ψ
T
0
tan
δ
f
T
l
v
T
l
cos
2
δ
f
]
\widetilde{X}= \begin{bmatrix} x-x_0 \\ y-y_0 \\ \psi-\psi_0 \end{bmatrix}, \widetilde{U}= \begin{bmatrix} v-v_0 \\ \delta_f-\delta_{f0} \end{bmatrix},\\ \widetilde{A}=I+TA= \begin{bmatrix} 1 & 0 & -v\sin{\psi}T \\ 0 & 1 & v\cos{\psi}T \\ 0 & 0 & 1 \end{bmatrix}, \widetilde{B}=TB= \begin{bmatrix} \cos{\psi}T & 0\\ \sin{\psi}T & 0\\ \frac{\tan{\delta_f}T}{l} & \frac{vT}{l\cos^2{\delta_f}} \end{bmatrix} \tag{8}
X
=⎣⎡x−x0y−y0ψ−ψ0⎦⎤,U
=[v−v0δf−δf0],A
=I+TA=⎣⎡100010−vsinψTvcosψT1⎦⎤,B
=TB=⎣⎡cosψTsinψTltanδfT00lcos2δfvT⎦⎤(8)
单车模型
预测模型仍以单车模型为主,结合运动学模型和动力学模型对车辆运动状态进行分析。
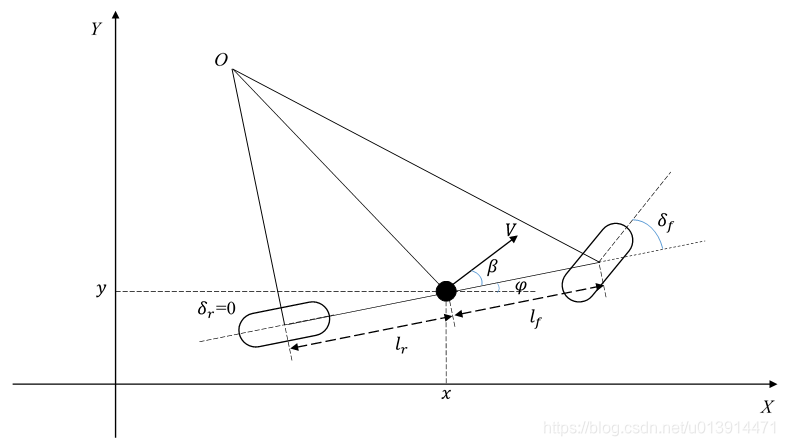
根据化代码可知,Apollo的MPC模块中的状态变量共有6个:
matrix_state_ = Matrix::Zero(basic_state_size_, 1);
// State matrix update;
matrix_state_(0, 0) = debug->lateral_error();
matrix_state_(1, 0) = debug->lateral_error_rate();
matrix_state_(2, 0) = debug->heading_error();
matrix_state_(3, 0) = debug->heading_error_rate();
matrix_state_(4, 0) = debug->station_error();
matrix_state_(5, 0) = debug->speed_error();
m
a
t
r
i
x
_
s
t
a
t
e
_
=
[
l
a
t
e
r
a
l
_
e
r
r
o
r
l
a
t
e
r
a
l
_
e
r
r
o
r
_
r
a
t
e
h
e
a
d
i
n
g
_
e
r
r
o
r
h
e
a
d
i
n
g
_
e
r
r
o
r
_
r
a
t
e
s
t
a
t
i
o
n
_
e
r
r
o
r
s
p
e
e
d
_
e
r
r
o
r
]
matrix\_state\_= \begin{bmatrix} lateral\_error\\ lateral\_error\_rate\\ heading\_error\\ heading\_error\_rate\\ station\_error\\ speed\_error\\ \end{bmatrix}
matrix_state_=⎣⎢⎢⎢⎢⎢⎢⎡lateral_errorlateral_error_rateheading_errorheading_error_ratestation_errorspeed_error⎦⎥⎥⎥⎥⎥⎥⎤
它们的计算请参考上一篇Apollo代码学习(五)—横纵向控制:
{
m
a
t
r
i
x
_
s
t
a
t
e
_
(
0
,
0
)
=
d
y
∗
cos
φ
−
d
x
∗
sin
φ
m
a
t
r
i
x
_
s
t
a
t
e
_
(
1
,
0
)
=
V
x
∗
sin
Δ
φ
=
V
x
∗
sin
e
2
m
a
t
r
i
x
_
s
t
a
t
e
_
(
2
,
0
)
=
φ
−
φ
d
e
s
m
a
t
r
i
x
_
s
t
a
t
e
_
(
3
,
0
)
=
φ
˙
−
φ
˙
d
e
s
m
a
t
r
i
x
_
s
t
a
t
e
_
(
4
,
0
)
=
−
(
d
x
∗
cos
φ
d
e
s
+
d
y
∗
sin
φ
d
e
s
)
m
a
t
r
i
x
_
s
t
a
t
e
_
(
5
,
0
)
=
V
d
e
s
−
V
∗
cos
Δ
φ
/
k
\begin{cases} matrix\_state\_(0, 0)=dy*\cos{\varphi}-dx*\sin{\varphi}\\ matrix\_state\_(1, 0)=V_x*\sin{\Delta\varphi} =V_x*\sin{e_2}\\ matrix\_state\_(2, 0)=\varphi-\varphi_{des}\\ matrix\_state\_(3, 0)=\dot{\varphi}-\dot{\varphi}_{des}\\ matrix\_state\_(4, 0)=-(dx*\cos{\varphi_{des}} + dy*\sin{\varphi_{des}})\\ matrix\_state\_(5, 0)=V_{des} - V*\cos{\Delta\varphi}/k\\ \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧matrix_state_(0,0)=dy∗cosφ−dx∗sinφmatrix_state_(1,0)=Vx∗sinΔφ=Vx∗sine2matrix_state_(2,0)=φ−φdesmatrix_state_(3,0)=φ˙−φ˙desmatrix_state_(4,0)=−(dx∗cosφdes+dy∗sinφdes)matrix_state_(5,0)=Vdes−V∗cosΔφ/k
控制变量有2个:
Eigen::MatrixXd control_matrix(controls_, 1);
control_matrix << 0, 0;
并结合代码去分析 c o n t r o l _ m a t r i x control\_matrix control_matrix内包含的变量:
// 解mpc,输出一个vector,control内有10个control_matrix
SolveLinearMPC(matrix_ad_, matrix_bd_, matrix_cd_, matrix_q_updated_,
matrix_r_updated_, lower_bound, upper_bound, matrix_state_, reference,
mpc_eps_, mpc_max_iteration_, &control)
// 已知,mpc仅取第一组解为当前时刻最优控制解,即control[0]
// control中第一个矩阵中的第一个值用于计算方向盘转角
double steer_angle_feedback = control[0](0, 0) * 180 / M_PI *
steer_transmission_ratio_ /
steer_single_direction_max_degree_ * 100;
double steer_angle = steer_angle_feedback + steer_angle_feedforwardterm_updated_;
// control中第一个矩阵中的第二个值用于计算加速度
debug->set_acceleration_cmd_closeloop(control[0](1, 0));
double acceleration_cmd = control[0](1, 0) + debug->acceleration_reference();
可得
c
o
n
t
r
o
l
_
m
a
t
r
i
x
=
[
δ
f
a
]
control\_matrix= \begin{bmatrix} \delta_f \\ a \end{bmatrix}
control_matrix=[δfa]
其中,
δ
f
\delta_f
δf为前轮转角,
a
a
a为加速度补偿。
结合方向盘控制的动力学模型:
(9)
d
d
t
[
e
1
e
˙
1
e
2
e
˙
2
]
=
[
0
1
0
0
0
−
2
C
a
f
+
2
C
a
r
m
V
x
2
C
a
f
+
2
C
a
r
m
−
2
C
a
f
ℓ
f
+
2
C
a
r
ℓ
r
m
V
x
0
0
0
1
0
−
2
C
a
f
ℓ
f
−
2
C
a
r
ℓ
r
I
z
V
x
2
C
a
f
ℓ
f
−
2
C
a
r
ℓ
r
I
z
−
2
C
a
f
ℓ
f
2
+
2
C
a
r
ℓ
r
2
I
z
V
x
]
[
e
1
e
˙
1
e
2
e
˙
2
]
+
[
0
2
C
α
f
m
0
2
C
α
f
ℓ
f
I
z
]
δ
f
+
[
0
−
2
C
a
f
ℓ
f
−
2
C
a
r
ℓ
r
m
V
x
−
V
x
0
−
2
C
a
f
ℓ
f
2
+
2
C
a
r
ℓ
r
2
I
z
V
x
]
φ
˙
\frac{d}{dt} \begin{bmatrix} e_1 \\ \dot{e}_1 \\ e_2 \\ \dot{e}_2 \end{bmatrix}= \begin{bmatrix} 0 & 1 & 0 & 0 \\ 0 & -\frac{2C_{af}+2C_{ar}}{mV_x} & \frac{2C_{af}+2C_{ar}}{m} & \frac{-2C_{af}\ell_f+2C_{ar}\ell_r}{mV_x}\\ 0 & 0 & 0 & 1 \\ 0 & -\frac{2C_{af}\ell_f-2C_{ar}\ell_r}{I_zV_x} & \frac{2C_{af}\ell_f-2C_{ar}\ell_r}{I_z} & -\frac{2C_{af}\ell_f^2+2C_{ar}\ell_r^2}{I_zV_x} \end{bmatrix} \begin{bmatrix} e_1 \\ \dot{e}_1 \\ e_2 \\ \dot{e}_2 \end{bmatrix} \\ +\begin{bmatrix} 0 \\ \frac{2C_{\alpha f}}{m} \\ 0 \\ \frac{2C_{\alpha f}\ell_f}{I_z} \end{bmatrix}\delta_f+ \begin{bmatrix} 0 \\ -\frac{2C_{af}\ell_f-2C_{ar}\ell_r}{mV_x} -V_x\\ 0 \\ -\frac{2C_{af}\ell_f^2+2C_{ar}\ell_r^2}{I_zV_x} \end{bmatrix}\dot{\varphi} \tag{9}
dtd⎣⎢⎢⎡e1e˙1e2e˙2⎦⎥⎥⎤=⎣⎢⎢⎢⎡00001−mVx2Caf+2Car0−IzVx2Cafℓf−2Carℓr0m2Caf+2Car0Iz2Cafℓf−2Carℓr0mVx−2Cafℓf+2Carℓr1−IzVx2Cafℓf2+2Carℓr2⎦⎥⎥⎥⎤⎣⎢⎢⎡e1e˙1e2e˙2⎦⎥⎥⎤+⎣⎢⎢⎡0m2Cαf0Iz2Cαfℓf⎦⎥⎥⎤δf+⎣⎢⎢⎢⎡0−mVx2Cafℓf−2Carℓr−Vx0−IzVx2Cafℓf2+2Carℓr2⎦⎥⎥⎥⎤φ˙(9)
和mpc_controller.cc、mpc_slover.cc中的代码注释,
// 初始化矩阵
Status MPCController::Init(const ControlConf *control_conf) {
...
// Matrix init operations.
matrix_a_ = Matrix::Zero(basic_state_size_, basic_state_size_);
matrix_ad_ = Matrix::Zero(basic_state_size_, basic_state_size_);
...
// TODO(QiL): expand the model to accomendate more combined states.
matrix_a_coeff_ = Matrix::Zero(basic_state_size_, basic_state_size_);
...
matrix_b_ = Matrix::Zero(basic_state_size_, controls_);
matrix_bd_ = Matrix::Zero(basic_state_size_, controls_);
...
matrix_bd_ = matrix_b_ * ts_;
matrix_c_ = Matrix::Zero(basic_state_size_, 1);
...
matrix_cd_ = Matrix::Zero(basic_state_size_, 1);
...
}
// 更新矩阵
void MPCController::UpdateMatrix(SimpleMPCDebug *debug) {
const double v = VehicleStateProvider::instance()->linear_velocity();
matrix_a_(1, 1) = matrix_a_coeff_(1, 1) / v;
matrix_a_(1, 3) = matrix_a_coeff_(1, 3) / v;
matrix_a_(3, 1) = matrix_a_coeff_(3, 1) / v;
matrix_a_(3, 3) = matrix_a_coeff_(3, 3) / v;
Matrix matrix_i = Matrix::Identity(matrix_a_.cols(), matrix_a_.cols());
matrix_ad_ = (matrix_i + ts_ * 0.5 * matrix_a_) *
(matrix_i - ts_ * 0.5 * matrix_a_).inverse();
matrix_c_(1, 0) = (lr_ * cr_ - lf_ * cf_) / mass_ / v - v;
matrix_c_(3, 0) = -(lf_ * lf_ * cf_ + lr_ * lr_ * cr_) / iz_ / v;
matrix_cd_ = matrix_c_ * debug->heading_error_rate() * ts_;
}
// 求解MPC
// discrete linear predictive control solver, with control format
// x(i + 1) = A * x(i) + B * u (i) + C
bool SolveLinearMPC(const Matrix &matrix_a, const Matrix &matrix_b,
const Matrix &matrix_c, const Matrix &matrix_q,
const Matrix &matrix_r, const Matrix &matrix_lower,
const Matrix &matrix_upper,
const Matrix &matrix_initial_state,
const std::vector<Matrix> &reference, const double eps,
const int max_iter, std::vector<Matrix> *control)
可得MPC控制模型:
(10)
d
d
t
[
l
a
t
e
r
a
l
_
e
r
r
o
r
l
a
t
e
r
a
l
_
e
r
r
o
r
_
r
a
t
e
h
e
a
d
i
n
g
_
e
r
r
o
r
h
e
a
d
i
n
g
_
e
r
r
o
r
_
r
a
t
e
s
t
a
t
i
o
n
_
e
r
r
o
r
s
p
e
e
d
_
e
r
r
o
r
]
=
[
0
1
0
0
0
0
0
−
C
f
+
C
r
m
V
C
f
+
C
r
m
C
r
ℓ
r
−
C
f
ℓ
f
m
V
0
0
0
0
0
1
0
0
0
C
r
ℓ
r
−
C
f
ℓ
f
I
z
V
C
f
ℓ
f
−
C
r
ℓ
r
I
z
−
C
r
ℓ
r
2
+
C
f
ℓ
f
2
I
z
V
0
0
0
0
0
0
0
1
0
0
0
0
0
0
]
[
l
a
t
e
r
a
l
_
e
r
r
o
r
l
a
t
e
r
a
l
_
e
r
r
o
r
_
r
a
t
e
h
e
a
d
i
n
g
_
e
r
r
o
r
h
e
a
d
i
n
g
_
e
r
r
o
r
r
a
t
e
s
t
a
t
i
o
n
_
e
r
r
o
r
s
p
e
e
d
_
e
r
r
o
r
]
+
[
0
0
C
f
m
0
0
0
C
f
ℓ
f
I
z
0
0
0
0
−
1
]
[
δ
f
a
]
+
[
0
C
r
ℓ
r
−
C
f
ℓ
f
m
V
−
V
0
−
C
r
ℓ
r
2
+
C
f
ℓ
f
2
I
z
V
0
1
]
φ
˙
\frac{d}{dt} \begin{bmatrix} lateral\_error\\ lateral\_error\_rate\\ heading\_error\\ heading\_error\_rate\\ station\_error\\ speed\_error\\ \end{bmatrix}= \begin{bmatrix} 0 & 1 & 0 & 0 & 0 & 0\\ 0 & -\frac{C_f+C_r}{mV} & \frac{C_f+C_r}{m} & \frac{C_r\ell_r-C_f\ell_f}{mV} & 0 & 0\\ 0 & 0 & 0 & 1 & 0 & 0\\ 0 & \frac{C_r\ell_r-C_f\ell_f}{I_zV} & \frac{C_f\ell_f-C_r\ell_r}{I_z} & -\frac{C_r\ell_r^2+C_f\ell_f^2}{I_zV} & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 & 0 \end{bmatrix} \begin{bmatrix} lateral\_error\\ lateral\_error\_rate\\ heading\_error\\ heading\_error_rate\\ station\_error\\ speed\_error\\ \end{bmatrix} \\ +\begin{bmatrix} 0 & 0\\ \frac{C_f}{m} & 0\\ 0 & 0\\ \frac{C_f\ell_f}{I_z} & 0\\ 0 & 0\\ 0 & -1 \end{bmatrix} \begin{bmatrix} \delta_f \\ a \end{bmatrix}+ \begin{bmatrix} 0\\ \frac{C_r\ell_r-C_f\ell_f}{mV}-V\\ 0\\ -\frac{C_r\ell_r^2+C_f\ell_f^2}{I_zV}\\ 0\\ 1 \end{bmatrix} \dot{\varphi} \tag{10}
dtd⎣⎢⎢⎢⎢⎢⎢⎡lateral_errorlateral_error_rateheading_errorheading_error_ratestation_errorspeed_error⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡0000001−mVCf+Cr0IzVCrℓr−Cfℓf000mCf+Cr0IzCfℓf−Crℓr000mVCrℓr−Cfℓf1−IzVCrℓr2+Cfℓf200000000000010⎦⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎡lateral_errorlateral_error_rateheading_errorheading_errorratestation_errorspeed_error⎦⎥⎥⎥⎥⎥⎥⎤+⎣⎢⎢⎢⎢⎢⎢⎡0mCf0IzCfℓf0000000−1⎦⎥⎥⎥⎥⎥⎥⎤[δfa]+⎣⎢⎢⎢⎢⎢⎢⎢⎡0mVCrℓr−Cfℓf−V0−IzVCrℓr2+Cfℓf201⎦⎥⎥⎥⎥⎥⎥⎥⎤φ˙(10)
其中,
C
f
,
C
r
C_f,C_r
Cf,Cr分别为前/后轮转弯刚度,
ℓ
f
,
ℓ
r
\ell_f,\ell_r
ℓf,ℓr分别为前悬/后悬长度,
m
m
m为车身质量,
V
V
V为车速,
I
z
I_z
Iz为车辆绕
z
z
z轴转动的转动惯量,
φ
˙
\dot{\varphi}
φ˙为转向速度。
对应的状态矩阵、控制矩阵、扰动矩阵等如下:
(11)
A
=
[
0
1
0
0
0
0
0
−
C
f
+
C
r
m
V
C
f
+
C
r
m
C
r
ℓ
r
−
C
f
ℓ
f
m
V
0
0
0
0
0
1
0
0
0
C
r
ℓ
r
−
C
f
ℓ
f
I
z
V
C
f
ℓ
f
−
C
r
ℓ
r
I
z
−
C
r
ℓ
r
2
+
C
f
ℓ
f
2
I
z
V
0
0
0
0
0
0
0
1
0
0
0
0
0
0
]
,
B
=
[
0
0
C
f
m
0
0
0
C
f
ℓ
f
I
z
0
0
0
0
−
1
]
,
C
=
[
0
C
r
ℓ
r
−
C
f
ℓ
f
m
V
−
V
0
−
C
r
ℓ
r
2
+
C
f
ℓ
f
2
I
z
V
0
1
]
A=\begin{bmatrix} 0 & 1 & 0 & 0 & 0 & 0\\ 0 & -\frac{C_f+C_r}{mV} & \frac{C_f+C_r}{m} & \frac{C_r\ell_r-C_f\ell_f}{mV} & 0 & 0\\ 0 & 0 & 0 & 1 & 0 & 0\\ 0 & \frac{C_r\ell_r-C_f\ell_f}{I_zV} & \frac{C_f\ell_f-C_r\ell_r}{I_z} & -\frac{C_r\ell_r^2+C_f\ell_f^2}{I_zV} & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 & 0 \end{bmatrix},\\ B=\begin{bmatrix} 0 & 0\\ \frac{C_f}{m} & 0\\ 0 & 0\\ \frac{C_f\ell_f}{I_z} & 0\\ 0 & 0\\ 0 & -1 \end{bmatrix}, C=\begin{bmatrix} 0\\ \frac{C_r\ell_r-C_f\ell_f}{mV}-V\\ 0\\ -\frac{C_r\ell_r^2+C_f\ell_f^2}{I_zV}\\ 0\\ 1 \end{bmatrix} \tag{11}
A=⎣⎢⎢⎢⎢⎢⎢⎢⎡0000001−mVCf+Cr0IzVCrℓr−Cfℓf000mCf+Cr0IzCfℓf−Crℓr000mVCrℓr−Cfℓf1−IzVCrℓr2+Cfℓf200000000000010⎦⎥⎥⎥⎥⎥⎥⎥⎤,B=⎣⎢⎢⎢⎢⎢⎢⎡0mCf0IzCfℓf0000000−1⎦⎥⎥⎥⎥⎥⎥⎤,C=⎣⎢⎢⎢⎢⎢⎢⎢⎡0mVCrℓr−Cfℓf−V0−IzVCrℓr2+Cfℓf201⎦⎥⎥⎥⎥⎥⎥⎥⎤(11)
对应的线性化系数应为(欧拉映射离散法):
A
~
=
I
+
T
A
,
B
~
=
T
B
,
C
~
=
T
C
\widetilde{A}=I+TA,\widetilde{B}=TB,\widetilde{C}=TC
A
=I+TA,B
=TB,C
=TC
但代码中实际线性化系数为(双线性变换离散法):
matrix_ad_ = (matrix_i + ts_ * 0.5 * matrix_a_) *
(matrix_i - ts_ * 0.5 * matrix_a_).inverse();
matrix_bd_ = matrix_b_ * ts_;
matrix_cd_ = matrix_c_ * debug->heading_error_rate() * ts_;
(12)
A
~
=
(
I
+
T
A
/
2
)
(
I
−
T
A
/
2
)
−
1
,
B
~
=
T
B
,
C
~
=
T
C
∗
h
e
a
d
i
n
g
_
e
r
r
o
r
_
r
a
t
e
\widetilde{A}=(I+TA/2)(I-TA/2)^{-1},\widetilde{B}=TB,\widetilde{C}=TC*heading\_error\_rate \tag{12}
A
=(I+TA/2)(I−TA/2)−1,B
=TB,C
=TC∗heading_error_rate(12)
对于
C
~
\widetilde{C}
C
的形式不同,个人认为是由于
h
e
a
d
i
n
g
_
e
r
r
o
r
_
r
a
t
e
heading\_error\_rate
heading_error_rate是计算横向误差之后才有的,无法直接获取,在矩阵更新的时候才将
h
e
a
d
i
n
g
_
e
r
r
o
r
_
r
a
t
e
heading\_error\_rate
heading_error_rate作为系数更新到矩阵中,也就是公式10中的
φ
˙
\dot{\varphi}
φ˙,其实对于
C
~
\widetilde{C}
C
来说,仍是
C
~
=
T
C
\widetilde{C}=TC
C
=TC的形式。
A
~
\widetilde{A}
A
的形式不一样,是因为此处采用了双线性变换离散法。感谢博友LLCCCJJ的友情提示。 关于连续系统离散化的方法可参考:连续系统离散化方法。
最终得到形如公式13的离散线性模型:
(13)
x
(
k
+
1
)
=
A
x
(
k
)
+
B
u
(
k
)
+
C
x(k+1)=Ax(k)+Bu(k)+C\tag{13}
x(k+1)=Ax(k)+Bu(k)+C(13)
系统的输出方程为:
y
(
k
)
=
D
x
(
k
)
y(k)=Dx(k)
y(k)=Dx(k)。
则在预测时域内有状态变量方程和输出变量方程如下:
(14)
x
(
k
)
=
A
k
x
(
0
)
+
∑
i
=
0
k
−
1
A
i
B
u
(
k
−
1
−
i
)
+
∑
i
=
0
k
−
1
A
i
C
x(k)=A^kx(0)+\sum_{i=0}^{k-1}A^iBu(k-1-i)+\sum_{i=0}^{k-1}A^iC \tag{14}
x(k)=Akx(0)+i=0∑k−1AiBu(k−1−i)+i=0∑k−1AiC(14)
(15)
y
(
k
)
=
D
A
k
x
(
0
)
+
∑
i
=
0
k
−
1
D
A
i
B
u
(
k
−
1
−
i
)
+
∑
i
=
0
k
−
1
D
A
i
C
y(k)=DA^kx(0)+\sum_{i=0}^{k-1}DA^iBu(k-1-i)+\sum_{i=0}^{k-1}DA^iC \tag{15}
y(k)=DAkx(0)+i=0∑k−1DAiBu(k−1−i)+i=0∑k−1DAiC(15)
假设
(16)
ξ
(
k
∣
t
)
=
[
x
(
k
∣
t
)
u
(
k
−
1
∣
t
)
]
\xi(k|t)= \begin{bmatrix} x(k|t)\\ u(k-1|t) \end{bmatrix} \tag{16}
ξ(k∣t)=[x(k∣t)u(k−1∣t)](16)
可得到新的状态空间表达式:
(17)
ξ
(
k
+
1
∣
t
)
=
A
~
ξ
(
k
∣
t
)
+
B
~
Δ
u
(
k
∣
t
)
+
C
~
η
(
k
∣
t
)
=
D
~
ξ
(
k
∣
t
)
\begin{matrix} \xi(k+1|t)=\widetilde{A}\xi(k|t)+\widetilde{B}\Delta u(k|t)+\widetilde{C} \\ \eta(k|t)=\widetilde{D}\xi(k|t) \end{matrix}\tag{17}
ξ(k+1∣t)=A
ξ(k∣t)+B
Δu(k∣t)+C
η(k∣t)=D
ξ(k∣t)(17)
其中,
(18)
A
~
=
[
A
B
0
I
]
,
B
~
=
[
B
I
]
,
C
~
=
[
C
0
]
,
D
~
=
[
D
0
]
\begin{matrix} \widetilde{A}= \begin{bmatrix} A & B \\ 0 & I \end{bmatrix}, \widetilde{B}= \begin{bmatrix} B \\ I \end{bmatrix}, \widetilde{C}= \begin{bmatrix} C \\ 0 \end{bmatrix}, \widetilde{D}=[D\ \ \ 0] \end{matrix}\tag{18}
A
=[A0BI],B
=[BI],C
=[C0],D
=[D 0](18)
可将公式16、公式18代入公式17,验证公式18的由来。
则在预测时域内的状态变量和输出变量可用如下算式计算:
(19)
ξ
(
k
+
N
p
∣
t
)
=
A
~
t
N
p
ξ
(
t
∣
t
)
+
A
~
t
N
p
−
1
B
~
t
Δ
u
(
t
∣
t
)
+
A
~
t
N
p
−
1
C
~
t
+
⋯
+
B
~
t
Δ
u
(
t
+
N
p
−
1
∣
t
)
+
C
~
t
η
(
k
+
N
p
∣
t
)
=
D
~
t
A
~
t
N
p
ξ
(
t
∣
t
)
+
D
~
t
A
~
t
N
p
−
1
B
~
t
Δ
u
(
t
∣
t
)
+
D
~
t
A
~
t
N
p
−
1
C
~
t
+
⋯
+
D
~
t
B
~
t
Δ
u
(
t
+
N
p
−
1
∣
t
)
+
D
~
t
C
~
t
\begin{matrix} \xi(k+N_p|t)=\widetilde{A}_t^{N_p}\xi(t|t)+\widetilde{A}_t^{N_p-1}\widetilde{B}_t\Delta u(t|t)+\widetilde{A}_t^{N_p-1}\widetilde{C}_t+\cdots +\widetilde{B}_t\Delta u(t+N_p-1|t)+\widetilde{C}_t \\ \eta(k+N_p|t)=\widetilde{D}_t\widetilde{A}_t^{N_p}\xi(t|t)+\widetilde{D}_t\widetilde{A}_t^{N_p-1}\widetilde{B}_t\Delta u(t|t)+\widetilde{D}_t\widetilde{A}_t^{N_p-1}\widetilde{C}_t+\cdots +\widetilde{D}_t\widetilde{B}_t\Delta u(t+N_p-1|t)+\widetilde{D}_t\widetilde{C}_t \end{matrix} \tag{19}
ξ(k+Np∣t)=A
tNpξ(t∣t)+A
tNp−1B
tΔu(t∣t)+A
tNp−1C
t+⋯+B
tΔu(t+Np−1∣t)+C
tη(k+Np∣t)=D
tA
tNpξ(t∣t)+D
tA
tNp−1B
tΔu(t∣t)+D
tA
tNp−1C
t+⋯+D
tB
tΔu(t+Np−1∣t)+D
tC
t(19)
将系统未来时刻的状态和输出以矩阵形式表达为:
(20)
X
(
t
)
=
Ψ
t
ξ
(
t
∣
t
)
+
Φ
t
Δ
U
(
t
∣
t
)
+
Υ
t
Y
(
t
)
=
D
~
t
X
(
t
)
\begin{matrix} X(t)=\Psi_t\xi(t|t)+\Phi_t\Delta U(t|t)+\Upsilon_t \\ Y(t)=\widetilde{D}_tX(t) \end{matrix} \tag{20}
X(t)=Ψtξ(t∣t)+ΦtΔU(t∣t)+ΥtY(t)=D
tX(t)(20)
其中,
(21)
X
(
t
)
=
[
ξ
(
t
+
1
∣
t
)
ξ
(
t
+
2
∣
t
)
ξ
(
t
+
3
∣
t
)
⋮
ξ
(
t
+
N
p
∣
t
)
]
,
Y
(
t
)
=
[
η
(
t
+
1
∣
t
)
η
(
t
+
2
∣
t
)
η
(
t
+
3
∣
t
)
⋮
η
(
t
+
N
p
∣
t
)
]
,
Δ
U
=
[
Δ
u
(
t
∣
t
)
Δ
u
(
t
+
1
∣
t
)
Δ
u
(
t
+
2
∣
t
)
⋮
Δ
u
(
t
+
N
p
−
1
∣
t
)
]
,
Υ
t
=
[
C
~
A
~
C
~
+
C
~
A
~
2
C
~
+
A
~
C
~
+
C
~
⋮
∑
i
=
0
N
p
−
1
A
~
i
C
~
]
,
Ψ
t
=
[
A
~
t
A
~
t
2
A
~
t
3
⋮
A
~
t
N
p
]
,
Φ
t
=
[
B
~
t
0
0
⋯
0
A
~
t
B
~
t
B
~
t
0
⋯
0
⋮
⋮
⋯
⋯
⋯
A
~
t
N
p
−
1
B
~
t
A
~
t
N
p
−
2
B
~
t
⋯
⋯
B
~
t
]
X(t)=\begin{bmatrix} \xi(t+1|t)\\ \xi(t+2|t)\\ \xi(t+3|t)\\ \vdots\\ \xi(t+N_p|t)\\ \end{bmatrix}, Y(t)=\begin{bmatrix} \eta(t+1|t)\\ \eta(t+2|t)\\ \eta(t+3|t)\\ \vdots\\ \eta(t+N_p|t)\\ \end{bmatrix}, \Delta U=\begin{bmatrix} \Delta u(t|t)\\ \Delta u(t+1|t)\\ \Delta u(t+2|t)\\ \vdots\\ \Delta u(t+N_p-1|t)\\ \end{bmatrix}, \Upsilon_t=\begin{bmatrix} \widetilde{C}\\ \widetilde{A}\widetilde{C} + \widetilde{C}\\ \widetilde{A}^2\widetilde{C} + \widetilde{A}\widetilde{C} + \widetilde{C}\\ \vdots\\ \sum_{i=0}^{N_p-1}\widetilde{A}^i\widetilde{C} \end{bmatrix},\\ \Psi_t=\begin{bmatrix} \widetilde{A}_t\\ \widetilde{A}_t^2\\ \widetilde{A}_t^3\\ \vdots\\ \widetilde{A}_t^{N_p}\\ \end{bmatrix}, \Phi_t=\begin{bmatrix} \widetilde{B}_t & 0 & 0 & \cdots & 0\\ \widetilde{A}_t\widetilde{B}_t & \widetilde{B}_t & 0 & \cdots & 0\\ \vdots & \vdots & \cdots & \cdots & \cdots \\ \widetilde{A}_t^{N_p-1}\widetilde{B}_t & \widetilde{A}_t^{N_p-2}\widetilde{B}_t & \cdots & \cdots & \widetilde{B}_t\\ \end{bmatrix} \tag{21}
X(t)=⎣⎢⎢⎢⎢⎢⎡ξ(t+1∣t)ξ(t+2∣t)ξ(t+3∣t)⋮ξ(t+Np∣t)⎦⎥⎥⎥⎥⎥⎤,Y(t)=⎣⎢⎢⎢⎢⎢⎡η(t+1∣t)η(t+2∣t)η(t+3∣t)⋮η(t+Np∣t)⎦⎥⎥⎥⎥⎥⎤,ΔU=⎣⎢⎢⎢⎢⎢⎡Δu(t∣t)Δu(t+1∣t)Δu(t+2∣t)⋮Δu(t+Np−1∣t)⎦⎥⎥⎥⎥⎥⎤,Υt=⎣⎢⎢⎢⎢⎢⎢⎡C
A
C
+C
A
2C
+A
C
+C
⋮∑i=0Np−1A
iC
⎦⎥⎥⎥⎥⎥⎥⎤,Ψt=⎣⎢⎢⎢⎢⎢⎢⎡A
tA
t2A
t3⋮A
tNp⎦⎥⎥⎥⎥⎥⎥⎤,Φt=⎣⎢⎢⎢⎡B
tA
tB
t⋮A
tNp−1B
t0B
t⋮A
tNp−2B
t00⋯⋯⋯⋯⋯⋯00⋯B
t⎦⎥⎥⎥⎤(21)
通过公式20我们可以看出,预测时域内的状态和输出量都可以通过从系统当前的状态量
ξ
(
t
∣
t
)
\xi(t|t)
ξ(t∣t)和控制增量
Δ
U
(
t
∣
t
)
\Delta U(t|t)
ΔU(t∣t)求得,这也即是模型预测控制算法中“预测”功能的实现。
结合mpc_slover.cc,对MPC的模型进行分析:
unsigned int horizon = reference.size(); // horizon =10
// Update augment reference matrix_t
// matrix_t为60*1的矩阵,存储的参考轨迹信息
Matrix matrix_t = Matrix::Zero(matrix_b.rows() * horizon, 1);
...
// Update augment control matrix_v
// matrix_v为20*1的矩阵,存储控制信息
Matrix matrix_v = Matrix::Zero((*control)[0].rows() * horizon, 1);
...
// matrix_a_power为含有10个矩阵的容器,每个矩阵为6*6,matrix_a为6*6矩阵
std::vector<Matrix> matrix_a_power(horizon);
...
// matrix_k为60*20的矩阵,matrix_b为6*2矩阵
Matrix matrix_k =
Matrix::Zero(matrix_b.rows() * horizon, matrix_b.cols() * horizon);
...
令
R
e
f
=
m
a
t
r
i
x
_
t
,
C
t
r
=
m
a
t
r
i
x
_
v
,
A
=
m
a
t
r
i
x
_
a
,
A
P
=
m
a
t
r
i
x
_
a
_
p
o
w
e
r
,
B
=
m
a
t
r
i
x
_
b
,
K
=
m
a
t
r
i
x
_
k
Ref=matrix\_t, Ctr=matrix\_v, A=matrix\_a, AP=matrix\_a\_power, B=matrix\_b, K=matrix\_k
Ref=matrix_t,Ctr=matrix_v,A=matrix_a,AP=matrix_a_power,B=matrix_b,K=matrix_k,根据代码有:
(22)
R
e
f
=
[
r
e
f
1
r
e
f
2
⋮
r
e
f
10
]
,
C
t
r
=
[
c
t
r
1
c
t
r
2
⋮
c
t
r
10
]
,
P
A
=
[
A
A
2
⋮
A
10
]
,
K
=
[
A
B
0
⋯
0
A
2
B
A
B
⋯
0
⋮
⋮
⋯
⋮
A
10
B
A
9
B
⋯
A
B
]
Ref=\begin{bmatrix} ref_1\\ ref_2\\ \vdots\\ ref_{10} \end{bmatrix}, Ctr=\begin{bmatrix} ctr_1\\ ctr_2\\ \vdots\\ ctr_{10} \end{bmatrix}, PA=\begin{bmatrix} A\\ A^2\\ \vdots\\ A^{10} \end{bmatrix},\\ K=\begin{bmatrix} AB & 0 & \cdots & 0 \\ A^2B & AB & \cdots & 0 \\ \vdots & \vdots & \cdots & \vdots \\ A^{10}B & A^9B & \cdots & AB \end{bmatrix}\tag{22}
Ref=⎣⎢⎢⎢⎡ref1ref2⋮ref10⎦⎥⎥⎥⎤,Ctr=⎣⎢⎢⎢⎡ctr1ctr2⋮ctr10⎦⎥⎥⎥⎤,PA=⎣⎢⎢⎢⎡AA2⋮A10⎦⎥⎥⎥⎤,K=⎣⎢⎢⎢⎡ABA2B⋮A10B0AB⋮A9B⋯⋯⋯⋯00⋮AB⎦⎥⎥⎥⎤(22)
其中,
r
e
f
i
ref_i
refi为参考轨迹序列,
c
t
r
i
ctr_i
ctri为预测控制序列,预测时域为10个采样周期。
滚动优化
MPC的线性优化问题可以结合无人驾驶车辆模型预测控制第3.3.1节及以下文章:Model predictive control of a mobile robot using linearization进行学习。
滚动优化的目的是为了求最优控制解,是一种在线优化,它每一时刻都会针对当前误差重新计算控制量,通过使某一或某些性能指标达到最优来实现控制作用。因此,滚动优化可能不会得到全局最优解,但是却能对每一时刻的状态进行最及时的响应,达到局部最优。
因此,需要设计合适的优化目标,以获得尽可能最优的控制序列,目标函数的一般形式可表示为状态和控制输入的二次函数:
(23)
J
(
k
)
=
∑
j
=
1
N
(
x
~
(
k
+
j
∣
k
)
T
Q
x
~
(
k
+
j
∣
k
)
+
u
~
(
k
+
j
−
1
∣
k
)
T
R
u
~
(
k
+
j
−
1
∣
k
)
)
J(k)=\sum_{j=1}^N(\widetilde{x}(k+j|k)^TQ\widetilde{x}(k+j|k)+\widetilde{u}(k+j-1|k)^TR\widetilde{u}(k+j-1|k)) \tag{23}
J(k)=j=1∑N(x
(k+j∣k)TQx
(k+j∣k)+u
(k+j−1∣k)TRu
(k+j−1∣k))(23)
其中,
N
N
N为预测时域,
Q
,
R
Q, R
Q,R为权重矩阵,且满足
Q
≥
0
,
R
>
0
Q\ge0, R>0
Q≥0,R>0的正定矩阵。形如
a
(
m
∣
n
)
a(m|n)
a(m∣n)表示,在
n
n
n时刻下预测的
m
m
m时刻的
a
a
a值。第一项反映了系统对参考轨迹的跟踪能力,第二项反映了对控制量变化的约束。此外,上式(公式23)在书写过程中,累加和函数
∑
\sum
∑后几乎都不加"()",但我看起来实在难受,所以自行将
x
,
u
x,u
x,u一起括起来。
优化求解的问题可以理解为在每一个采样点
k
k
k,寻找一组最优控制序列
u
~
t
∗
\widetilde{u}_t^*
u
t∗和最优开销
J
∗
(
k
)
J^*(k)
J∗(k),其中:
u
~
t
∗
=
arg
min
u
~
J
(
k
)
\widetilde{u}_t^*=\arg\min_{\widetilde{u}}{J(k)}
u
t∗=argu
minJ(k)
在MPC控制规律中,将控制序列中的第一个参数作为控制量,输入给被控系统。
对于车辆控制来说,就是找到一组合适的控制量,如 u = [ δ f , a ] T u=[\delta_f, a]^T u=[δf,a]T,其中, δ f \delta_f δf为前轮偏角, a a a为刹车/油门系数,使车辆沿参考轨迹行驶,且误差最小、控制最平稳、舒适度最高等。因此在设计目标函数的时候可以考虑以下几点:
- 看过Apollo官方控制模块视频的人,可能知道在设计代价函数时候,一般设计为二次型的样式,为的是避免在预测时域内,误差忽正忽负,导致误差相互抵消;此外,对于实在不理解为什么代价函数要采用平方形式的同学,也可以参考损失函数为什么用平方形式(二)。
- 可考虑的代价有:
a. 距离误差(Cross Track Error, CTE),指实际轨迹点与参考轨迹点间的距离,误差项可表示为: ( z i − z r e f , i ) 2 (z_i-z_{ref,i})^2 (zi−zref,i)2;
b. 速度误差,指实际速度与期望速度的差,误差项可表示为: ( v i − v r e f , i ) 2 (v_i-v_{ref,i})^2 (vi−vref,i)2;
c. 刹车/油门调节量,目的是为了保证刹车/油门变化的平稳性,误差项可表示为: ( a i + 1 − a i ) 2 (a_{i+1}-a_i)^2 (ai+1−ai)2;
d. 航向误差等… - 约束条件
a. 最大前轮转角
b. 最大刹车/油门调节量
c. 最大方向盘转角
d. 最大车速等
因此公式23中的第一项可表示为:
(24)
∑
j
=
1
N
x
~
(
k
+
j
∣
k
)
T
Q
x
~
(
k
+
j
∣
k
)
=
∑
j
=
1
N
(
w
1
(
z
i
−
z
r
e
f
,
i
)
2
+
w
2
(
v
i
−
v
r
e
f
,
i
)
2
+
w
3
(
a
i
+
1
−
a
i
)
2
+
.
.
.
)
\sum_{j=1}^N\widetilde{x}(k+j|k)^TQ\widetilde{x}(k+j|k)=\sum_{j=1}^N(w_1(z_i-z_{ref,i})^2+w_2(v_i-v_{ref,i})^2+w_3(a_{i+1}-a_i)^2+...) \tag{24}
j=1∑Nx
(k+j∣k)TQx
(k+j∣k)=j=1∑N(w1(zi−zref,i)2+w2(vi−vref,i)2+w3(ai+1−ai)2+...)(24)
其中,
w
i
w_i
wi为该项误差的权重,对应权重矩阵Q中的某一项。
对于上述的目标函数(公式23),是有多个变量,且要服从于这些变量的线性约束的二次函数,因此可以通过适当处理将其转换为二次规划问题。
基于公式20,将控制量变为控制增量,以满足系统对控制增量的要求,则目标函数可以改写为:
(25)
J
(
ξ
(
t
)
,
u
(
t
−
1
)
,
Δ
U
(
t
)
)
=
∑
i
=
1
N
∣
∣
η
(
t
+
i
∣
t
)
−
η
r
e
f
(
t
+
i
∣
t
)
∣
∣
Q
2
+
∑
i
=
1
N
−
1
∣
∣
Δ
U
(
t
+
i
∣
t
)
∣
∣
R
2
J(\xi(t), u(t-1), \Delta U(t))=\sum_{i=1}^N||\eta(t+i|t)-\eta_{ref}(t+i|t)||_Q^2+\sum_{i=1}^{N-1}||\Delta U(t+i|t)||_R^2\tag{25}
J(ξ(t),u(t−1),ΔU(t))=i=1∑N∣∣η(t+i∣t)−ηref(t+i∣t)∣∣Q2+i=1∑N−1∣∣ΔU(t+i∣t)∣∣R2(25)
在此基础上满足一些约束条件,一般如下:
(26)
{
控
制
量
约
束
:
u
m
i
n
(
t
+
k
)
≤
u
(
t
+
k
)
≤
u
m
a
x
(
t
+
k
)
控
制
增
量
约
束
:
Δ
u
m
i
n
(
t
+
k
)
≤
Δ
u
(
t
+
k
)
≤
Δ
u
m
a
x
(
t
+
k
)
输
出
约
束
:
y
m
i
n
(
t
+
k
)
≤
y
(
t
+
k
)
≤
y
m
a
x
(
t
+
k
)
\begin{cases} 控制量约束:u_{min}(t+k) \le u(t+k) \le u_{max}(t+k) \\ 控制增量约束:\Delta u_{min}(t+k) \le \Delta u(t+k) \le \Delta u_{max}(t+k)\\ 输出约束:y_{min}(t+k) \le y(t+k) \le y_{max}(t+k) \end{cases}\tag{26}
⎩⎪⎨⎪⎧控制量约束:umin(t+k)≤u(t+k)≤umax(t+k)控制增量约束:Δumin(t+k)≤Δu(t+k)≤Δumax(t+k)输出约束:ymin(t+k)≤y(t+k)≤ymax(t+k)(26)
其中,
k
=
0
,
1
,
2
,
3
,
.
.
.
,
N
−
1
k=0,1,2,3,...,N-1
k=0,1,2,3,...,N−1。
将公式20代入公式23中,并将预测时域内输出量偏差表示为:
(27)
E
(
t
)
=
Ψ
t
ξ
(
t
∣
t
)
−
Y
r
e
f
(
t
)
E(t)=\Psi_t\xi(t|t)-Y_{ref}(t) \tag{27}
E(t)=Ψtξ(t∣t)−Yref(t)(27)
其中,
Y
r
e
f
=
[
η
r
e
f
(
t
+
1
∣
t
)
,
.
.
.
,
η
r
e
f
(
t
+
N
∣
t
)
]
T
Y_{ref}=[\eta_{ref}(t+1|t),...,\eta_{ref}(t+N|t)]^T
Yref=[ηref(t+1∣t),...,ηref(t+N∣t)]T。
经过一定的矩阵计算,可将目标函数调整为与控制增量相关的函数:
(28)
J
(
ξ
(
t
)
,
u
(
t
−
1
)
,
Δ
U
(
t
)
)
=
Δ
U
(
t
)
H
t
Δ
U
(
t
)
T
+
G
t
Δ
U
(
t
)
T
+
P
t
J(\xi(t), u(t-1), \Delta U(t))=\Delta U(t)H_t\Delta U(t)^T+G_t\Delta U(t)^T+P_t \tag{28}
J(ξ(t),u(t−1),ΔU(t))=ΔU(t)HtΔU(t)T+GtΔU(t)T+Pt(28)
其中,
H
t
=
Φ
T
Q
e
Φ
+
R
e
,
G
t
=
2
E
(
t
)
T
Q
e
Φ
,
P
t
=
E
(
t
)
T
Q
e
E
(
t
)
,
P
t
H_t=\Phi^TQ_e\Phi +R_e,G_t=2E(t)^TQ_e\Phi,P_t=E(t)^TQ_eE(t),P_t
Ht=ΦTQeΦ+Re,Gt=2E(t)TQeΦ,Pt=E(t)TQeE(t),Pt为常量,
Q
e
,
R
e
Q_e,R_e
Qe,Re为权重矩阵
Q
,
R
Q,R
Q,R的扩充矩阵。
结合mpc_slover.cc中的代码,
// Initialize matrix_k, matrix_m, matrix_t and matrix_v, matrix_qq, matrix_rr,
// vector of matrix A power
Matrix matrix_m = Matrix::Zero(matrix_b.rows() * horizon, 1); // 60*1
Matrix matrix_qq = Matrix::Zero(matrix_k.rows(), matrix_k.rows()); // 60*60
Matrix matrix_rr = Matrix::Zero(matrix_k.cols(), matrix_k.cols()); // 20*20
Matrix matrix_ll = Matrix::Zero(horizon * matrix_lower.rows(), 1); //20*1
Matrix matrix_uu = Matrix::Zero(horizon * matrix_upper.rows(), 1); //20*1
...
// Update matrix_m1, matrix_m2, convert MPC problem to QP problem done
Matrix matrix_m1 = matrix_k.transpose() * matrix_qq * matrix_k + matrix_rr;
Matrix matrix_m2 = matrix_k.transpose() * matrix_qq * (matrix_m - matrix_t);
...
// TODO(QiL) : change qp solver to box constraint or substitute QPOASES
// Method 1: QPOASES
Matrix matrix_inequality_constrain_ll =
Matrix::Identity(matrix_ll.rows(), matrix_ll.rows());
...
// 求解
std::unique_ptr<QpSolver> qp_solver(new ActiveSetQpSolver(
matrix_m1, matrix_m2, matrix_inequality_constrain,
matrix_inequality_boundary, matrix_equality_constrain,
matrix_equality_boundary));
auto result = qp_solver->Solve();
令
S
=
m
a
t
r
i
x
_
i
n
i
t
i
a
l
_
s
t
a
t
e
,
M
=
m
a
t
r
i
x
_
m
,
M
1
=
m
a
t
r
i
x
_
m
1
,
M
2
=
m
a
t
r
i
x
_
m
2
,
Q
=
m
a
t
r
i
x
_
q
,
R
=
m
a
t
r
i
x
_
r
,
Q
Q
=
m
a
t
r
i
x
_
q
q
,
R
R
=
m
a
t
r
i
x
_
r
r
,
L
L
=
m
a
t
r
i
x
_
l
l
,
U
U
=
m
a
t
r
i
x
_
u
u
S=matrix\_initial\_state, M=matrix\_m, M1=matrix\_m1, M2=matrix\_m2, Q=matrix\_q, R=matrix\_r, QQ=matrix\_qq, RR=matrix\_rr, LL=matrix\_ll, UU=matrix\_uu
S=matrix_initial_state,M=matrix_m,M1=matrix_m1,M2=matrix_m2,Q=matrix_q,R=matrix_r,QQ=matrix_qq,RR=matrix_rr,LL=matrix_ll,UU=matrix_uu,根据代码有:
(29)
M
=
[
A
S
(
t
∣
t
)
+
C
A
M
[
0
]
+
C
⋮
A
M
[
8
]
+
C
]
=
[
A
S
(
t
∣
t
)
+
C
A
2
S
(
t
∣
t
)
+
A
C
+
C
⋮
A
10
S
(
t
∣
t
)
+
∑
i
=
0
9
A
i
C
]
,
Q
Q
=
[
Q
0
⋯
0
0
Q
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
Q
]
,
R
R
=
[
R
0
⋯
0
0
R
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
R
]
,
M
1
=
K
T
∗
Q
Q
∗
K
+
R
R
=
H
t
,
M
2
=
K
T
∗
Q
Q
(
M
−
R
e
f
)
=
K
T
∗
Q
Q
∗
E
(
t
)
M=\begin{bmatrix} AS(t|t)+C\\ AM[0]+C \\ \vdots\\ AM[8]+C \end{bmatrix}=\begin{bmatrix} AS(t|t)+C \\ A^2S(t|t)+AC+C \\ \vdots\\ A^{10}S(t|t)+\sum_{i=0}^9 A^iC \end{bmatrix},\\ QQ= \begin{bmatrix} Q & 0 & \cdots & 0\\ 0 & Q & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & Q \end{bmatrix}, RR= \begin{bmatrix} R & 0 & \cdots & 0\\ 0 & R & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & R \end{bmatrix},\\ \ \\ M1=K^T*QQ*K+RR=H_t,M2=K^T*QQ(M-Ref)=K^T*QQ*E(t) \tag{29}
M=⎣⎢⎢⎢⎡AS(t∣t)+CAM[0]+C⋮AM[8]+C⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡AS(t∣t)+CA2S(t∣t)+AC+C⋮A10S(t∣t)+∑i=09AiC⎦⎥⎥⎥⎤,QQ=⎣⎢⎢⎢⎡Q0⋮00Q⋮0⋯⋯⋱⋯00⋮Q⎦⎥⎥⎥⎤,RR=⎣⎢⎢⎢⎡R0⋮00R⋮0⋯⋯⋱⋯00⋮R⎦⎥⎥⎥⎤, M1=KT∗QQ∗K+RR=Ht,M2=KT∗QQ(M−Ref)=KT∗QQ∗E(t)(29)
因此,对模型预测控制的每一步进行带约束条件的优化问题,可转换为如下的二次规划问题:
(30)
min
Δ
U
t
Δ
U
(
t
)
H
t
Δ
U
(
t
)
T
+
G
t
Δ
U
(
t
)
T
Δ
U
m
i
n
≤
Δ
U
t
(
k
)
≤
Δ
U
m
a
x
U
m
i
n
≤
u
(
t
−
1
)
+
∑
i
=
1
N
Δ
U
(
i
)
≤
U
m
a
x
Y
m
i
n
≤
Ψ
t
ξ
(
t
∣
t
)
+
Φ
t
Δ
U
(
t
∣
t
)
+
Υ
t
≤
Y
m
a
x
\min_{\Delta U_t}\Delta U(t)H_t\Delta U(t)^T+G_t\Delta U(t)^T \\ \Delta U_{min} \le \Delta U_t(k) \le \Delta U_{max}\\ U_{min} \le u(t-1)+\sum_{i=1}^N\Delta U(i) \le U_{max} \\ Y_{min} \le \Psi_t\xi(t|t)+\Phi_t\Delta U(t|t)+\Upsilon_t \le Y_{max} \tag{30}
ΔUtminΔU(t)HtΔU(t)T+GtΔU(t)TΔUmin≤ΔUt(k)≤ΔUmaxUmin≤u(t−1)+i=1∑NΔU(i)≤UmaxYmin≤Ψtξ(t∣t)+ΦtΔU(t∣t)+Υt≤Ymax(30)
此外,在mpc_slover.cc中有注释如下:
// Update matrix_m1, matrix_m2, convert MPC problem to QP problem done
// Format in qp_solver
/**
* * min_x : q(x) = 0.5 * x^T * Q * x + x^T c
* * with respect to: A * x = b (equality constraint)
* * C * x >= d (inequality constraint)
* **/
// TODO(QiL) : change qp solver to box constraint or substitute QPOASES
// Method 1: QPOASES
可知,Apollo将MPC的优化求解转化为二次规划(Quadratic Programming, QP)问题,且QP问题的求解采用QPOASES的方法,QPOASES方法详解请见:qpOASES: a parametric active-set algorithm for quadratic programming,可以结合active_set_qp_solver.cc以及矩阵计算库Eigen对QPOASES方法进行理解分析。
反馈矫正
2018.12.28更新
有博友提醒该步骤在Apollo代码中并未实现,我在学习的过程中,确实在Apollo代码中没有特别清晰的对应上这一步,可能是我理解的不够深吧。
但该步骤是我在参考书中看到的MPC求解的一般步骤,所以在此处我也写了。辩证地看待吧,我尽量保证我写的内容没有什么原则性的错误,感谢各位博友的提点和支持。
在每个控制周期内,按照公式30完成优化求解后,得到控制时域内的一系列控制增量:
(31)
Δ
U
t
∗
=
[
Δ
u
t
∗
,
Δ
u
t
+
1
∗
,
.
.
.
,
Δ
u
t
+
N
−
1
∗
]
\Delta U_t^*=[\Delta u_t^*,\Delta u_{t+1}^*,...,\Delta u_{t+N-1}^*] \tag{31}
ΔUt∗=[Δut∗,Δut+1∗,...,Δut+N−1∗](31)
将序列中的第一个控制增量作为实际的控制输入增量作用于系统,则有:
(32)
u
(
t
)
=
u
(
t
−
1
)
+
Δ
u
t
∗
u(t)=u(t-1)+\Delta u_t^* \tag{32}
u(t)=u(t−1)+Δut∗(32)
将
u
(
t
)
u(t)
u(t)作为此时的控制量输入给系统,直到下一个控制时刻,系统根据新的状态信息预测下一时段内的输出,然后通过优化得到一组新的控制序列。如此反复,直至完成整个控制过程。
总结
综上所述,MPC控制器的工作原理大致如下所示:
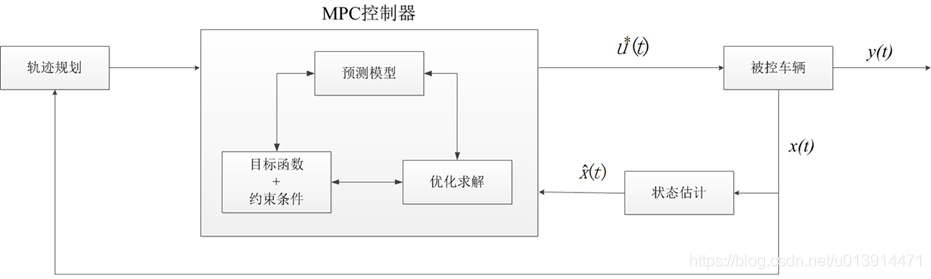
其中, x ( t ) x(t) x(t)为 t t t时刻车辆的观测状态, x ( t ) ^ \hat{x(t)} x(t)^为 t t t时刻车辆的估计状态, u ∗ ( t ) u^*(t) u∗(t)为t时刻的最优控制解, y ( t ) y(t) y(t)为 t t t时刻的系统输出。
模型预测控制的实现,依赖MPC控制器、被控车辆、状态估计器、轨迹规划等信息。结合图1和图4,模型预测控制器的一般工作步骤可以概括如下:
1、在
t
t
t时刻,结合历史信息和当前状态以及预测模型,预测
N
N
N步的系统输出;
2、结合约束条件等,设计目标函数,计算最优控制解
u
∗
(
t
)
u^*(t)
u∗(t),输入到被控车辆,使其在当前控制量下运动;
3、获取车辆状态
x
(
t
)
x(t)
x(t),输入到状态估计器中,对那些无法直接用传感器获取或观测成本较高的的状态量进行估计,然后将
x
^
(
t
)
\hat{x}(t)
x^(t)输入到MPC控制器,再次进行优化求解,以得到未来一段时间的预测控制序列;
4、然后在
t
+
1
t+1
t+1时刻重复上述步骤,如此,滚动地实现带约束的优化问题,从而实现对被控对象的连续控制。
此外,
x
(
t
)
x(t)
x(t)也可在需要的时候,被用来更新规划轨迹,以便得到更好的控制效果。

















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









