









最近一直在看无监督学习相关的只是,在前面了解了kmeans聚类算法和层次聚类之后,今天我们来探索一下没那么简单的Gassian Mixture Model哈,感受一下数学所带来的震撼和又一次多了对高斯这个神一般的男人的好奇,现在开始转入正题哈!
高斯混合模型,顾名思义,使用多个不同的高斯模型混合而成,用来拟合任意形状的概率分布,至于原因嘛,大家可以看看为什么高斯模型混合模型(GMM)理论上可以拟合任意形状的概率分布呢?,相信一定会小有收获的,因为高斯混合模型这么强,任何形状的概率分布都可以拟合,我们为什么不使用呢?从高斯混合模型这个名字来看,我们需要求的参数包括每个高斯分布的
μk,δk
,以及对应与每一个高斯分布的权重
πk
(假设该分布由k个高斯分布组成),那么如何求解这些参数呢?
思路:
针对一批数据,带上GMM滤镜来分析一个点,可以看做两步:1)首先随机的从k个高斯分布中选择一个,被选中的概率即为πk;2)然后从被选中的高斯分布中选取当前点,这样就可以转化为已知的高斯分布求解。
如何用GMM来求解聚类问题呢?首先我们利用已知的数据推出对应的GMM概率分布,k个高斯模型对应的即为k个簇,根据数据推测概率密度成为密度估计,当我们假定了概率密度的形式此时来求解参数时成为参数估计!
GMM的概率密度函数:

GMM的似然函数:

有了这些似然函数形式后,我们下面来决定如何来求解这些问题!
解法:
通过观察上面的似然函数形式,我们发现无法使用最大似然估计进行求解对应的参数,因为log里面还有Σ求和,通过最大似然估计无法求解,因此我们选择类似于k-means方法的EM方法进行求解,思路是不断迭代直至似然函数的值收敛为止,即可得到满足条件的πk,μk,δk,下面就来讲一下解法步骤:
1)估计每个数据由k个component产生的概率,类似于kmeans中计算每个点距离不同质心的距离,该概率的解法为:
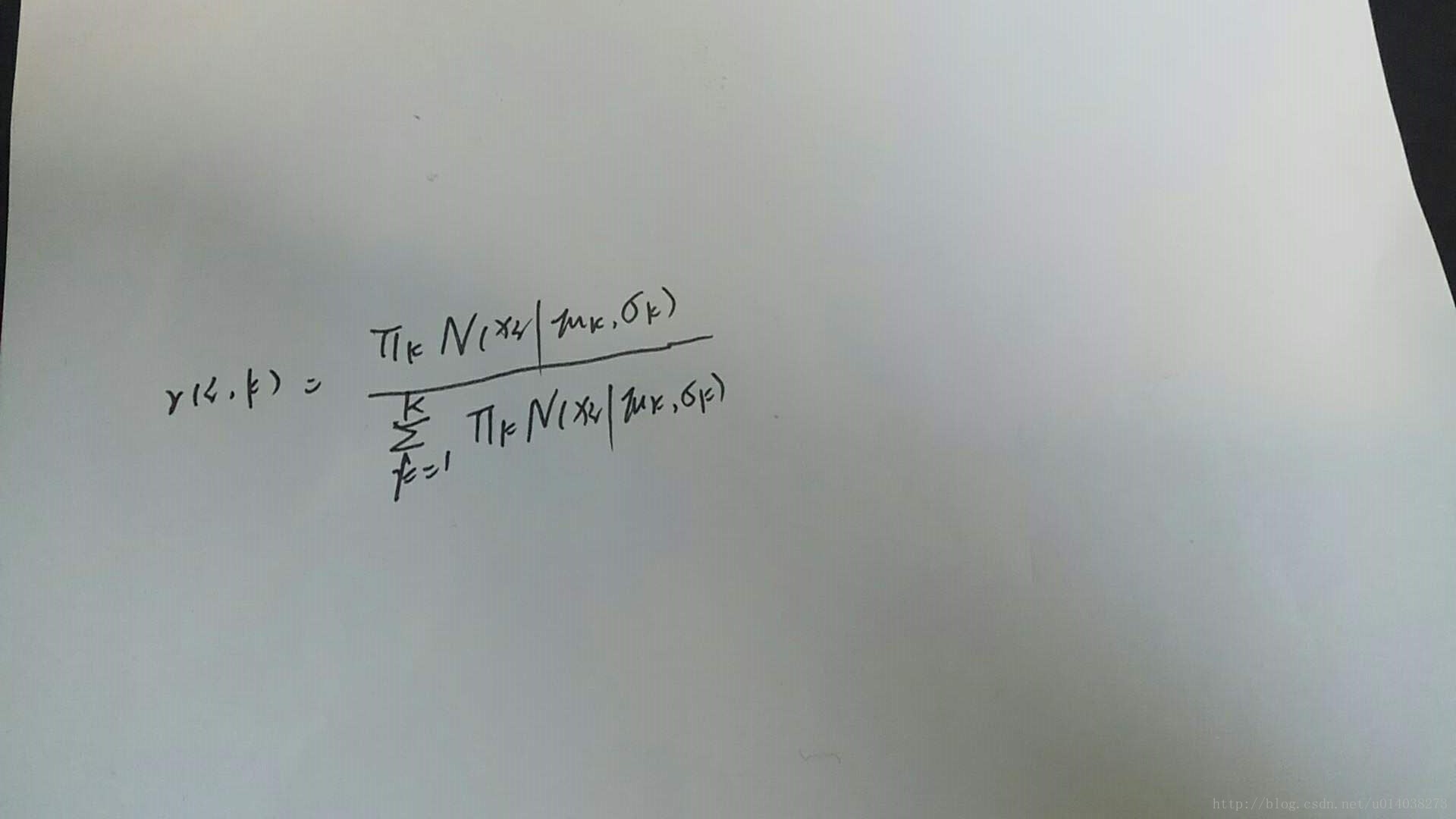
这个式子里面μk,δk都是我们要求解的,我们采用迭代法,当前要求解的μ,δ,π我们选取μk-1,δk-1,πk-1的值或者初值,注意初值的选取,进行迭代计算;
2)求解出了不同的r(i,k),即第i个数据属于第k个高斯分布簇的概率之后,我们就可以怎样了?对了,就是可以将Σ展开,所以llog函数中就变成了没有Σ的πk*N(xi|μk,δk)加和了,然后我们利用最大似然估计即可求出πk,μk,δk三个参数,或者换一种思路理解,第k个高斯分布生成的数据为r(i,k)xi(i=1~N),然后利用最大似然估计即可求出μk,δk以及πk,求解公式为:

3)判断GMM的似然函数的值是否收敛,若收敛,则停止,否则重复迭代1),2)步。
详见:
漫谈 Clustering (3): Gaussian Mixture Model
高斯混合模型(GMM)及其EM算法的理解
请参看:
还有针对k-means算法的新的优化算法,感兴趣的同学可以看一下啦,聚类算法——ISODATA算法















 5013
5013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









