







YOLO目标检测系列
YOLOv1
YOLOv1结构及工作流程
YOLO最早于2016年提出。它的核心思想就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置及所属的类别。YOLO最左边是一个InceptionV1网络,共20层。但作者对InceptionV1进行了改造,他没有使用inception模块,而是用一个1x1的卷积并联一个3x3的卷积来替代。
InceptionV1提取出的特征图再经过4个卷积层和2个全连接层,最后生成7x7x30的输出。
YOLO将一副448x448的原图分割成了7x7=49个网格,每个网格要预测两个bounding box的坐标(x, y, w, h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及物体属于20类别中每一类的概率(YOLO的训练数据为voc2012,它是一个20分类的数据集)。所以一个网络对应一个(4x2+2+20)=30维的向量。

输出
7x7网格内的每个grid(红色框),对应两个大小形状不同的bounding box(黄色框)。每个box的位置坐标为(x, y, w, h),x和y表示box中心店与该格子边界的相对值,w和h表示预测box的宽度和高度相对于整幅图像的宽度和高度的比例。(x, y, w, h)会限制在[0, 1]之间。与训练数据集上标定的物体真实坐标(Gx, Gy, Gw, Gh)进行对比训练,每个grid负责检查中心点落在该格子的物体。
这个置信度只是为了表达box内有无物体的概率(类似于Faster R-CNN中RPN层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类。

confidence置信度
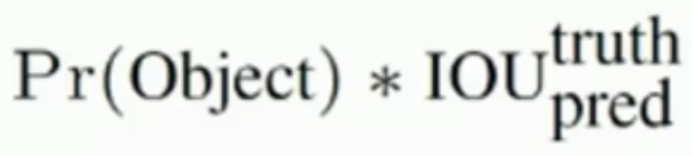
其中前一项表示有无人工标记的物体落入了网格内,如果有则为1,否则为0。第二项代表bounding box和真是标记的box之间的IoU。值越大则box越接近真是位置。
confidence是针对bounding box的,每个网格有两个bounding box,所以每个网格会有两个confidence与之对应。
YOLO-V1预测工作流程
- 每一个格子得到两个bounding boxes
- 每个网格预测的class信息和bounding boxes预测的confidence信息相乘,得到了每个bounding box预测具体物体的概率和位置重叠的概率PrIoU

- 对于每一个类别,对PrIoU进行排序,去除小于阈值的PrIoU,然后做非极大值抑制

YOLOv1代价函数讲解以及缺点分析
YOLO的loss函数包含三部分:位置误差、confidence误差、分类误差
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









