







目标检测算法资源总结
目标检测是什么:
图像分类,检测及分割是计算机视觉领域的三大任务。
- 图像分类模型是将图像划分为单个类别,通常对应于图像中最突出的物体。
但是现实世界的很多图片通常包含不只一个物体,此时如果使用图像分类模型为图像分配一个单一标签其实是非常粗糙的,并不准确。对于这样的情况,就需要目标检测模型 - 目标检测模型可以识别一张图片的多个物体,并可以定位出不同物体(给出边界框)。
目标检测在很多场景有用,如无人驾驶和安防系统等。
目标检测方法
https://www.zhihu.com/question/53438706
https://blog.csdn.net/l7H9JA4/article/details/79620247
传统方法
1.(2001CVPR Paul Viola, Michael J. Jones)级联分类器框架:Haar/LBP/积分HOG/ACF feature+Adaboost
- boosting由简单弱分类拼装强分类器的过程
- 实践:https://docs.opencv.org/2.4.11/modules/objdetect/doc/cascade_classification.html?highlight=haar

2.(2005CVPR)HOG+SVM | Histograms of oriented gradients for human detection
- 由于原始的Haar特征太简单,只适合做刚性物体检测,无法检测行人等非刚性目标,所以又提出了HOG+SVM结构
- 实践:https://docs.opencv.org/2.4.11/modules/gpu/doc/object_detection.html?highlight=hog

3.(2010 PAMI)Discriminatively trained deformable part models(DPM)
- 使用弹簧模型进行目标检测,进行了多尺度+多部位检测,底层图像特征抽取采用的是fHoG
- 实践:http://www.rossgirshick.info/latent/

传统方法总结
- 需要手动提取图像特征,模型性能的好坏与手动提取的特征直接相关,手动提取特征方法需要不断尝试以得到好的特征
基于深度学习方法
- 随着2012年AlexNet的一举成名,CNN成了计算机视觉应用中的不二选择,掀开了深度学习的再一次研究浪潮
two stage算法:将检测问题划分为两个阶段,首先产生候选区域,然后对候选区域分类并确定位置
1.(2014CVPR)R-CNN:Regions with Convolutional Neural Network Features
- 论文地址:http://islab.ulsan.ac.kr/files/announcement/513/rcnn_pami.pdf
- Github:https://github.com/rbgirshick/rcnn
- 主要内容:先基于region proposal方法(文中选取的是selective search方法)来获得候选区域,之后使用CNN对这些候选区域进行特征提取并分类。
- 详细介绍:一张图片,R-CNN基于selective search方法大约生成2000个候选区域,然后每个候选区域被resize成固定大小227x227大小后送入一个CNN模型中,最后得到一个4096-d的特征向量。然后该特征向量送入一个多类别SVM分类器中,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型。
- 实现细节:R-CNN模型的训练是多管道的,CNN模型首先使用2012 ImageNet中的图像分类竞赛数据集进行预训练。然后在检测数据集上对CNN模型进行finetuning,其中那些与真实框的IoU大于0.5的候选区域作为正样本,剩余的候选区域是负样本(背景)。共训练两个版本,第一版本使用2012 PASCAL VOC数据集,第二个版本使用2013 ImageNet中的目标检测数据集。最后,对数据集中的各个类别训练SVM分类器(注意SVM训练样本与CNN模型的funetuning不太一样,只有IoU小于0.3的才被看成负样本)
- 优缺点:不用手动提取特征,使用CNN网络自动提取特征,将目标检测问题转换为分类问题;每个候选区域都要送入CNN模型计算特征向量,非常费时,固定图像输入大小

2.(2014)SPP-net:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文地址:https://arxiv.org/pdf/1406.4729.pdf
- Github: https://github.com/ShaoqingRen/SPP_net
- 主要内容:提出空间金字塔池化层(Spatial Pyramid Pooling Layer, SPP),SSP-net在CNN层与全连接层之间插入了空间金字塔池化层来解决图像分类中要求输入图片固定大小可能带来识别精度损失的问题,之后过程与RCNN类似
- 实现细节:在R-CNN中,由于每个候选区域大小是不同,所以需要先resize成固定大小才能送入CNN网络,SPP-net正好可以解决这个问题。继续上前一步,就是R-CNN每次都要挨个使用CNN模型计算各个候选区域的特征,这是极其费时的,不如直接将整张图片送入CNN网络,然后抽取候选区域的对应的特征区域,采用SPP层,这样可以大大减少计算量,并提升速度。基于SPP层的R-CNN模型在准确度上提升不是很大,但是速度却比原始R-CNN模型快24-102倍。
- 优缺点:改善RCNN网络需要固定图像输入尺寸的问题,加快了模型的速度。

3.(2015)Fast R-CNN:Fast Region-based Convolutional Network
- 论文地址:https://arxiv.org/pdf/1504.08083.pdf
- Github:https://github.com/rbgirshick/fast-rcnn
- 主要内容:借鉴SPP-net减少候选区域使用CNN模型提取特征向量所消耗时间的思想,提出ROI层以得到固定大小的特征图
- 实现细节:其CNN模型的输入是整张图片,然后结合RoIs(Region of Interests)pooling和Selective Search方法从CNN得到的特征图中提取各个候选区域的所对应的特征。对于每个候选区域,使用RoI pooling层来从CNN特征图中得到一个固定长和宽的特征图(长和宽是超参数,文中选用7* 7),RoI pooling的原理很简单,其根据候选区域按比例从CNN特征图中找到对应的特征区域,然后将其分割成几个子区域(根据要输出的特征图的大小),然后在每个子区域应用max pooling,从而得到固定大小的特征图。
- 优缺点:采用ROI层减少了候选区域提取特征消耗的时间,另外采用了softmax分类器而不是SVM分类器,训练过程较R-CNN而言更加简单

4.(2016) Faster R-CNN: The Faster Region-based Convolutional Network
- 论文地址:https://arxiv.org/pdf/1506.01497.pdf
- Github: https://github.com/rbgirshick/py-faster-rcnn
- 主要内容:引入了RPN (Region Proposal Network)直接产生候选区域,Faster R-CNN可以看成是RPN和Fast R-CNN模型的组合体
- 实现细节:对于RPN网络,先采用一个CNN模型接收整张图片并提取特征图。然后在这个特征图上采用一个N* N(文中是3* 3)的滑动窗口,对于每个滑窗位置都映射一个低维度的特征(如256-d)。然后这个特征分别送入两个全连接层,一个用于分类预测,另外一个用于回归窗口大小。总的步骤分为四步:(1)首先在ImageNet上预训练RPN,并在PASCAL VOC数据集上finetuning;(2)使用训练的PRN产生的region proposals单独训练一个Fast R-CNN模型,这个模型也先在ImageNet上预训练;(3)用Fast R-CNN的CNN模型部分(特征提取器)初始化RPN,然后对RPN中剩余层进行finetuning,此时Fast R-CNN与RPN的特征提取器是共享的;(4)固定特征提取器,对Fast R-CNN剩余层进行finetuning。
- 优缺点:采用RPN代替启发式region proposal的方法,加快了训练速度和精度

5.(2017) Mask R-CNN
- 论文地址:https://arxiv.org/pdf/1703.06870.pdf
- Github:https://github.com/matterport/Mask_RCNN
- 主要内容:把原有的Faster-RCNN进行扩展,添加一个分支使用现有的检测对目标进行并行预测
- 实现细节:首先对图片做检测,找出图像中的ROI,对每一个ROI使用ROIAlign进行像素校正,然后对每一个ROI使用设计的FCN框架进行预测不同的实例所属分类,最终得到图像实例分割结果。
- 优缺点:解决特征图与原始图像上的RoI不对准问题,将检测与分割和在一起,此外可以很容易泛化到其它任务上。比如,可以在同一个框架中估计人物的动作

以上算法都是two stage检测算法,其将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修)。与之相对的是one stage检测算法,这类算法不需要region proposal阶段,直接产生物体的类别概率和位置坐标值。二者相比较而言,two stage检测算法胜在精度,one stage检测算法胜在速度,但随着研究的发展,两类算法都在两个方面做改进。

One stage算法: 不需要region proposal阶段,直接产生物体的类别概率和位置坐标值
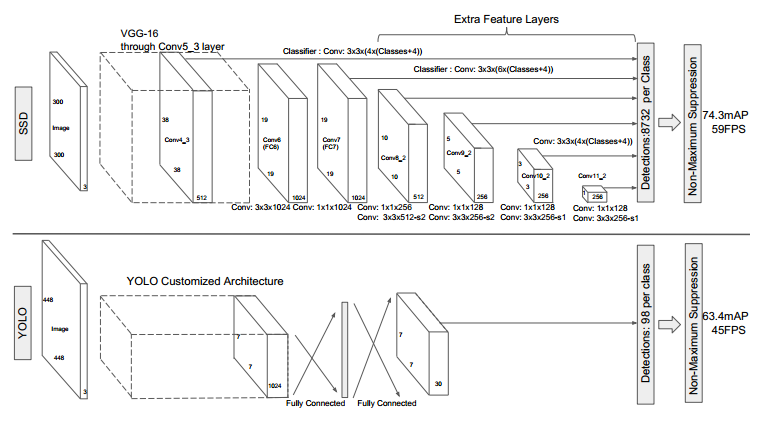
1.(2015)yolo : you only look once: Unified, Real-Time Object Detection
- 论文地址:https://arxiv.org/abs/1506.02640
- Github: https://pjreddie.com/darknet/yolov1/
- 主要内容:利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别
- 实现细节:1.将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object;2.每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值;3.每个网格还要预测一个类别信息,注意:class信息是针对每个网格的,confidence信息是针对每个bounding box;4.在测试的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score;5.得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果;
- 优缺点:对相互靠的很近的物体,还有很小的群体检测效果不好,泛化能力偏弱


2.(2016)yolo v2 |yolo 9000 : Better, Faster, Stronger
- 论文地址:https://arxiv.org/pdf/1612.08242v1.pdf
- Github: https://pjreddie.com/darknet/yolov2/
- 主要内容:包含两个内容:yolo v2 与 yolo9000,其中yolo v2在速度与精度之间实现了一个很好的平衡,yolo 9000则可以实时地检测超过9000种物体分类,混合检测数据集与识别数据集之中的数据。
- 实现细节:提出了一种新的训练方法–联合训练算法,该算法同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用监测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
- 优缺点:Better:改善recall,提升定位的准度,同时保持分类的精度;Faster:使用的是Darknet19网络,比VGG16和GoogleNet要快;Stronger:提出了WordTree,数据集混合训练,使得模型更加强健。



3.(2018) yolo v3:
- 论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
- Github: https://github.com/pjreddie/darknet
- 主要内容:再次改进YOLO模型,提供多尺度预测和更好的基础分类网络
- 实现细节:1.1.多尺度预测 (类FPN);2.更好的基础分类网络(类ResNet)和分类器 darknet-53;3.分类器-类别预测,分类损失采用binary cross-entropy loss.
- 优缺点:目前最优的one stage目标检测算法,模型更加复杂,可以通过改变模型结构的大小来权衡速度与精度


4.(2016)SSD: Single Shot MultiBox Detector
- 论文地址:https://arxiv.org/pdf/1512.02325.pdf
- Github:https://github.com/weiliu89/caffe/tree/ssd
- 主要内容:特征图上采用卷积核来预测一系列default bounding boxes的类别分数、偏移量;为了提高检测准确率,在不同尺度的特征图上进行预测,此外,还得到具有不同aspect ratio的结果
- 实现细节:YOLO中继承了将detection转化为regression的思路,同时一次即可完成网络训练;基于Faster RCNN中的anchor,提出了相似的prior box;加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,即在不同感受野的feature map上预测目标
- 优缺点:速度比yolo快,且保持了精度,效果媲美Faster RCNN
Image(url= “https://s1.ax1x.com/2018/06/06/C7osdH.png”)
目标检测工具API
(2017)Google TensorFlow Object Detection API(star 36000+)
- 论文地址:https://blog.csdn.net/yaoqi_isee/article/details/75051781
- Github:https://github.com/tensorflow/models/tree/master/research/object_detection
- 主要内容:论文主要对比分析了faster rcnn 、r-fcn以及ssd在精度与速度两个性能指标上的表现;相较于facebook开源的工具而言更容易训练
- 主要模型:
- ssd_mobilenet_v1_coco
- ssd_mobilenet_v2_coco
- ssdlite_mobilenet_v2_coco
- ssd_inception_v2_coco
- faster_rcnn_inception_v2_coco
- faster_rcnn_resnet50_coco
- faster_rcnn_resnet50_lowproposals_coco
- rfcn_resnet101_coco
- faster_rcnn_resnet101_coco
- faster_rcnn_resnet101_lowproposals_coco
- faster_rcnn_inception_resnet_v2_atrous_coco
- faster_rcnn_inception_resnet_v2_atrous_lowproposals_coco
- faster_rcnn_nas
- faster_rcnn_nas_lowproposals_coco
- mask_rcnn_inception_resnet_v2_atrous_coco
- mask_rcnn_inception_v2_coco
- mask_rcnn_resnet101_atrous_coco
- mask_rcnn_resnet50_atrous_coco
(2018)facebookresearch/Detectron (caffe2 star 14000+)
- 论文地址:
- Github:https://github.com/facebookresearch/Detectron
- 主要内容:Detectron是Facebook人工智能研究中心(FAIR)出品的软件系统,它实现了最先进的目标检测算法,包括Mask R-CNN。它是用Python编写的,并由Caffe2 深度学习框架提供动力。
- 主要模型:
- Feature Pyramid Networks for Object Detection
- Mask R-CNN - Marr Prize at ICCV 2017
- Detecting and Recognizing Human-Object Interactions
- Focal Loss for Dense Object Detection - RetinaNet – Best Student Paper Award at ICCV 2017
- Non-local Neural Networks
- Learning to Segment Every Thing
- Data Distillation: Towards Omni-Supervised Learning.
- Faster R-CNN
- RPN
- Fast R-CNN
- R-FCN
- 主要网络:
- ResNeXt{50,101,152}
- ResNet{50,101,152}
- Feature Pyramid Networks (with ResNet/ResNeXt)
- VGG16
目标检测数据集标注工具(https://www.zhihu.com/question/30626971)
图片标注工具LabelImg
- 教程:https://blog.csdn.net/jesse_mx/article/details/53606897
- Github:https://github.com/tzutalin/labelImg
MATLAB R2017a/b版本自带的trainingImageLabeler
- 网站:https://ww2.mathworks.cn/help/vision/ref/imagelabeler-app.html?s_tid=srchtitle
- 教程:https://blog.csdn.net/tsyccnh/article/details/50812632
labelme图像分割工具
yolo网络数据集标注专用工具
网络资源:
-
车辆检测竞赛
http://detrac-db.rit.albany.edu/DetRet 检测
http://detrac-db.rit.albany.edu/Tracking 跟踪 -
车辆检测
Evolving Boxes for Fast Vehicle Detection ICME 2017
http://zhengyingbin.cc/EvolvingBoxes/
https://github.com/Willy0919/Evolving_Boxes -
车辆检测
Small U-Net for vehicle detection
https://github.com/vxy10/p5_VehicleDetection_Unet -
目标检测 Faster RCNN + SSD
Single-Shot Refinement Neural Network for Object Detection
https://github.com/sfzhang15/RefineDet -
目标检测
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection ECCV2016
https://github.com/zhaoweicai/mscnn -
目标检测 — 加速候选区域提取
DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling ICCV2017
https://github.com/lachlants/denet -
【Dlib 19.5车辆检测】《Vehicle Detection with Dlib 19.5》
http://blog.dlib.net/2017/08/vehicle-detection-with-dlib-195_27.html -
目标检测
RON: Reverse Connection with Objectness Prior Networks for Object Detection CVPR2017
https://github.com/taokong/RON -
同时检测和分割,类似 Mask R-CNN
BlitzNet: A Real-Time Deep Network for Scene Understanding ICCV2017
https://github.com/dvornikita/blitznet -
目标检测
DSOD: Learning Deeply Supervised Object Detectors from Scratch ICCV2017
https://github.com/szq0214/DSOD -
目标检测:
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
https://github.com/sanghoon/pva-faster-rcnn -
目标检测
R-FCN: Object Detection via Region-based Fully Convolutional Networks
https://github.com/daijifeng001/r-fcn -
目标检测
A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection CVPR 2017
Caffe code : https://github.com/xiaolonw/adversarial-frcnn -
目标检测
Improving Object Detection With One Line of Code
https://github.com/bharatsingh430/soft-nms -
行人检测:
Is Faster R-CNN Doing Well for Pedestrian Detection? ECCV2016
https://github.com/zhangliliang/RPN_BF/tree/RPN-pedestrian -
检测
Accurate Single Stage Detector Using Recurrent Rolling Convolution
https://github.com/xiaohaoChen/rrc_detection
云栖社区总结
建议使用
网络
- YOLO V3
- Mask RCNN
- Faster RCNN
- YOLO V2
标注工具
- LabelImg
首发Github:https://github.com/UncleLLD/objective-detection-source.git
















 2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}