







 超级会员免费看
超级会员免费看
 本文介绍了大型语言模型(LLM)的发展历程,从基于规则的方法到神经网络模型,再到深度学习的递归神经网络和Transformer模型,如GPT系列。LLM的技术原理包括编码器和解码器、自注意力机制以及最大似然估计。未来,LLM的规模将持续扩大,效率提升,应用场景将更加广泛,同时模型的可解释性和安全性也将受到更多关注。
本文介绍了大型语言模型(LLM)的发展历程,从基于规则的方法到神经网络模型,再到深度学习的递归神经网络和Transformer模型,如GPT系列。LLM的技术原理包括编码器和解码器、自注意力机制以及最大似然估计。未来,LLM的规模将持续扩大,效率提升,应用场景将更加广泛,同时模型的可解释性和安全性也将受到更多关注。

【人工智能】LLM 大型语言模型发展历史
文章目录
前言
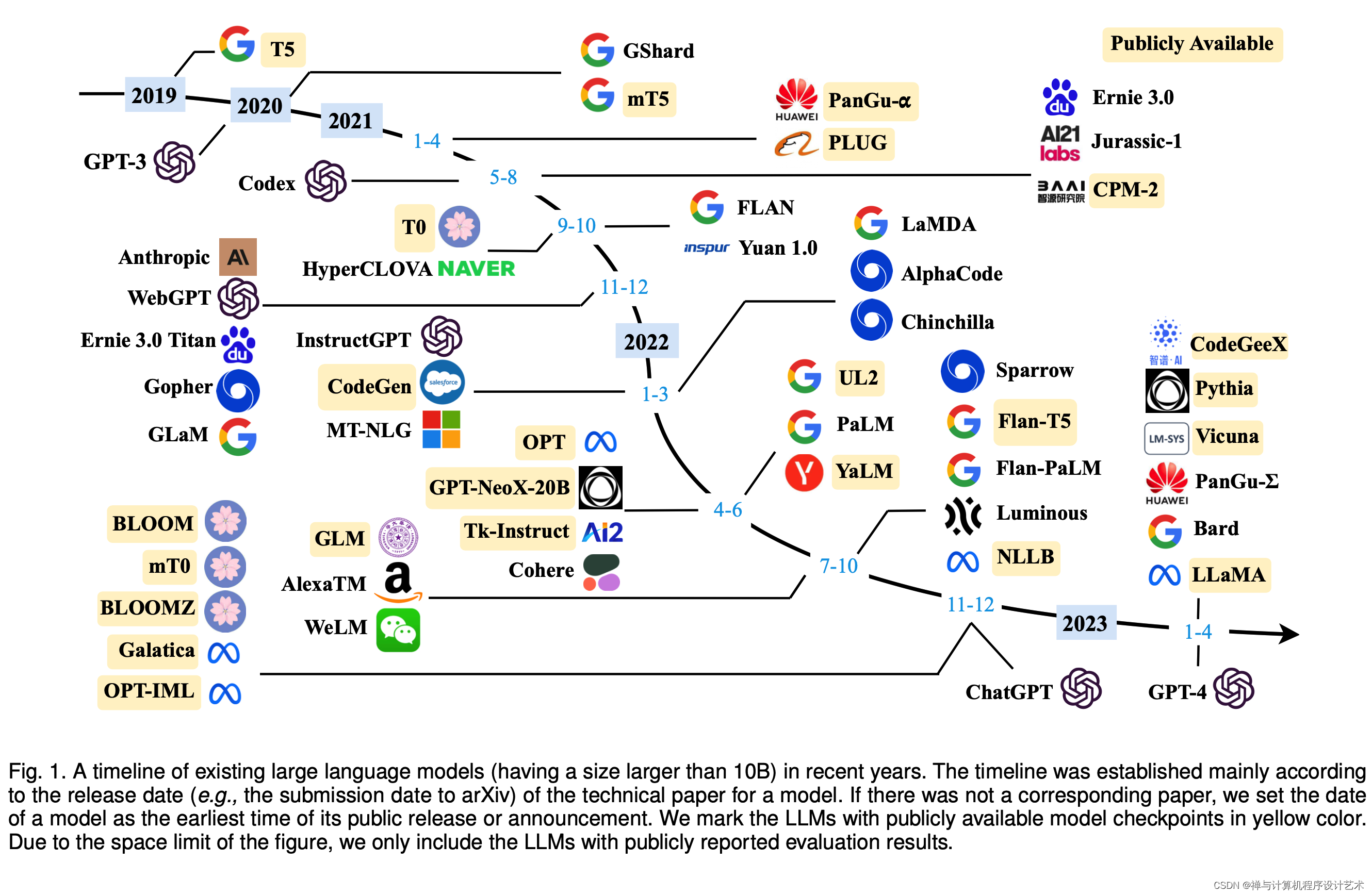
大型语言模型(Large Language Models,LLM)是指基于神经网络模型的自然语言处理技术,它可以通过大规模的训练数据和计算资源来预测自然语言文本的下一个词或句子。
近年来,由于技术的不断进步和计算资源的不断增加,LLM已成为自然语言处理领域的一个热门技术。
本文将从LLM的发展历史、技术原理、应用场景和未来发展趋势等方面进行介绍。
一、发展历史
通过编写一系列的规则
自然语言处理技术的发展可以追溯到20世纪50年代。当时,科学家们开始研究如何让计算机能够理解人类的语言。最初的方法是基于规则的,即通过编写一系列的规则来识别和理解文本。但是,这种方法需要大量的人工工作,并且难以应对复杂的语言结构。
尝试使用神经网络模型
随着神经网络技术的发展

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











