








 超级会员免费看
超级会员免费看


AI 大模型 LLM 推理加速技术原理与应用
文章目录
- AI 大模型 LLM 推理加速技术原理与应用
- AI大模型LLM推理加速技术原理与应用1
- AI大模型LLM推理加速技术原理与应用2
- AI大模型LLM推理加速技术原理与应用3
- AI大模型LLM推理加速技术原理与应用4
- AI 大模型 LLM 推理加速技术原理与应用5
AI大模型LLM推理加速技术原理与应用1
1. 背景介绍
1.1 问题的由来
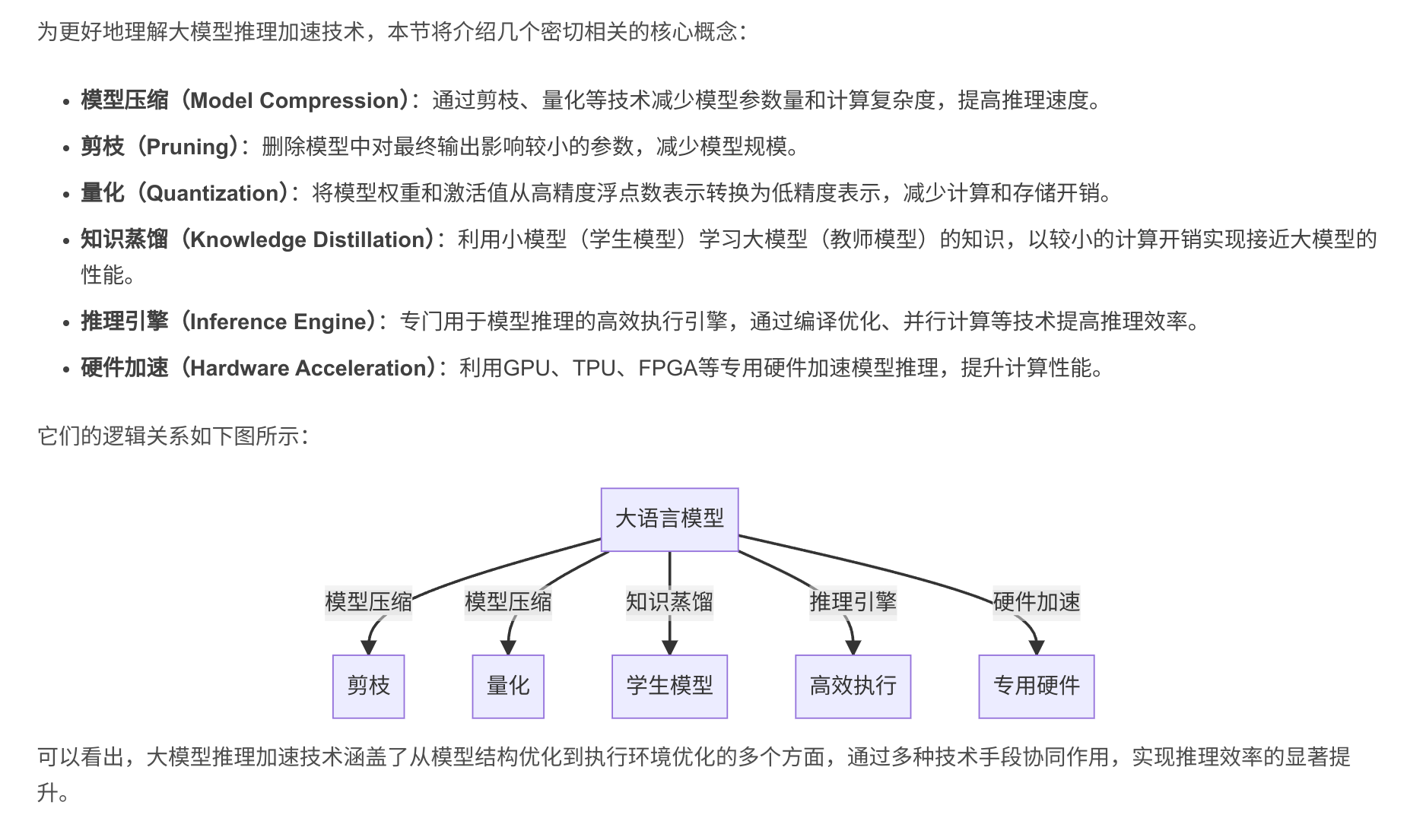
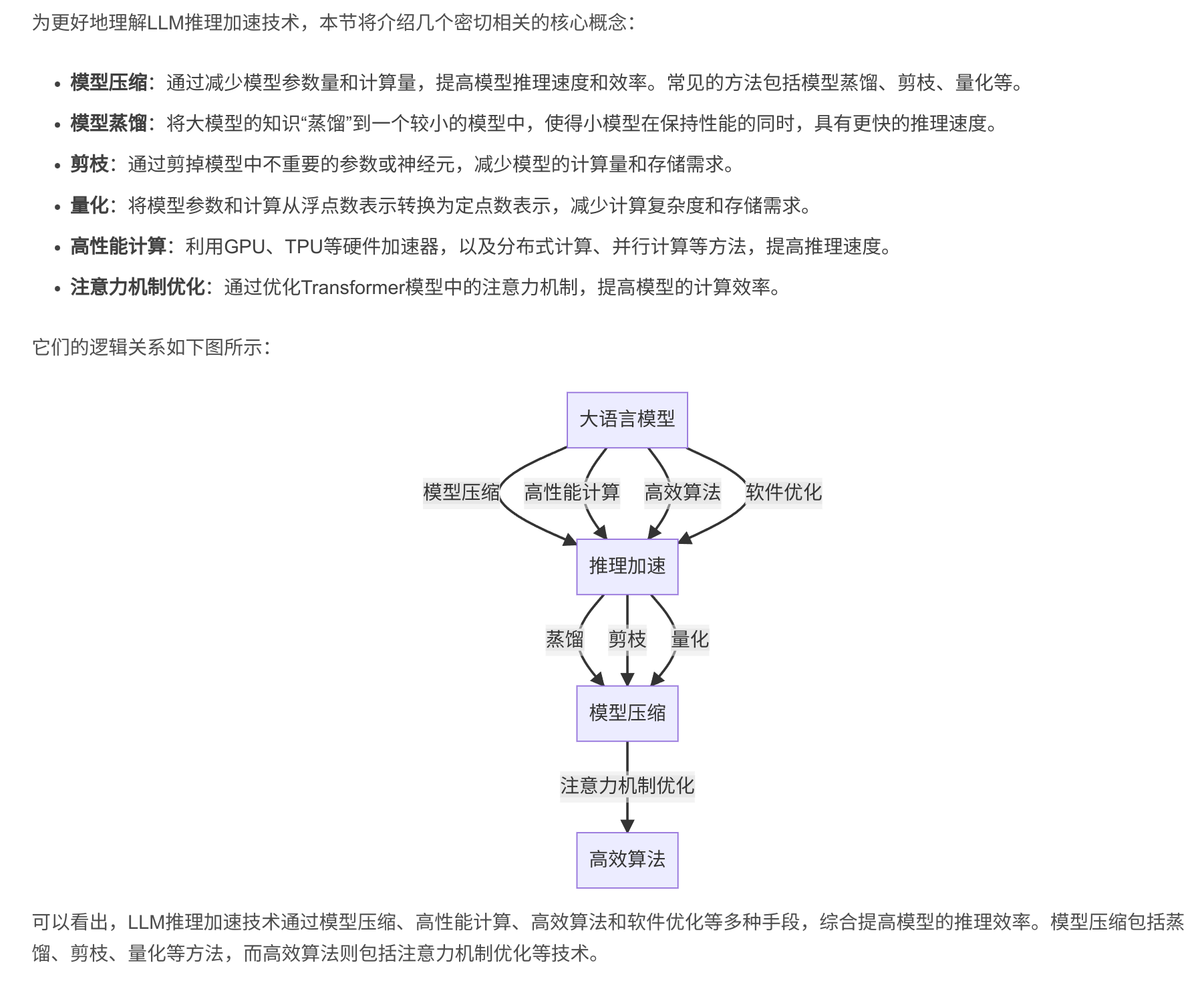
大语言模型(Large Language Models, LLMs)如GPT-3、PaLM、BLOOM等,在自然语言处理领域取得了突破性的进展。这些模型通过在海量文本数据上进行预训练,可以执行各种自然语言任务,如对话、问答、摘要、翻译等,展现出接近甚至超越人类的语言理解和生成能力。
然而,LLM的强大性能是以庞大的模型参数量为代价的。动辄上百亿甚至上千亿参数的模型,对计算资源和推理时间提出了严峻挑战。如何在保证模型效果的同时,提高推理速度、降低资源占用,成为LLM落地应用必须解决的问题。
1.2 研究现状
近年来,学术界和工业界围绕LLM推理加速开展了大量研究。主要思路可分为硬件优化和软件优化两大类:
硬件优化方面,通过使用更强大的AI芯片如GPUs、TPUs、NPUs等专用硬件来加速矩阵乘等关键操作。此外还探索了一些新型计算架构,如稀疏计算、近似计算等。
软件优化则从算法和工程实现层面入手,主要包括:
- 模型压缩&#x

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











