







 斯坦福推出的UMI刷盘机器人采用低成本手持夹持器收集训练数据,通过视觉SLAM和扩散策略实现高效动作预测,展现了出色的泛化能力和任务完成度。
斯坦福推出的UMI刷盘机器人采用低成本手持夹持器收集训练数据,通过视觉SLAM和扩散策略实现高效动作预测,展现了出色的泛化能力和任务完成度。
前言
没想到今年年初的斯坦福mobile aloha的热度刚过,而到今年2月的下旬,斯坦福另一个团队又推出了UMI刷盘机器人,且这两个团队还互相认识、还在一块共同切磋(顺带小小感叹一下,斯坦福的氛围是真好而且真高产)
斯坦福UMI刷盘机器人
- 其与mobile aloha(以及AirExo: Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild)最大的不同在于其收集数据处理的非真实的机器人,而是一个手持夹持器(从而大幅降低成本)
- 而其与此文《模仿学习的集中爆发:从Dobb·E、Gello到斯坦福Mobile ALOHA/UMI、FMB、DexCap》中第一部分的纽约大学Dobb·E最大的不同,则在于Dobb·E需要针对特定环境进行动作策略上的微调,而UMI面对陌生环境有比较好的泛化能力
后来,我司七月在线总算把斯坦福的UMI、DexCap成功复现了(应该是国内最早复现这两模型的团队或之一了)
- 至于复现过程中所遇到的问题或困难,有的同学因为没实际尝试过复现的话,便会想当然的觉得「github上的代码逻辑很顺,UMI的环境直接用了docker,预训练数据都有的,好像如果只是复现原视频,则难度不大」,实则不然
一方面,如我司机器人技术负责人姚博士所说,“其实主要问题他们在论文中也说了,就是视觉SLAM,这种方法信息量还是不够的,成功率没那么高 ”
故要么增加数据源,要么类似上海AI实验室一团队在UMI的基础上改进出Fast-UMI:用RealSense T265替代SLAM且实现机械臂的迁移与平替
二方面, UMI对硬件的解耦不够,使得原始的那套UMI框架想让其接近它原始论文中的效果,则需要用它论文中的原装硬件——比如其对UR5e有着过高的依赖「其实,即便都弄成原装硬件,效果也不一定能达到原论文效果的100%,详见此文:机器人领域中的scaling law:通过复现斯坦福机器人UMI——探讨数据规模化定律(含UMI的复现关键)
而在国产替代过程中,有很多坑我们是逐个踩过去的,比如针对国产替代写了另外的脚本,毕竟国产替代就两种方法:
1) 相对直接粗暴的是更改通讯脚本 以匹配目标机械臂,比如可以根据UR5e的更改——做硬解耦,当然 缺点也很明显,即每来一套机械臂,就得比较费劲的写对应的通讯脚本
2) 相对从长计议的是改造通讯方式 - 而后者改造通讯方式又存在两种路径,一个是改成ROS,一个是做通用化改写
对于ROS,因为UMI的脚本不是基于ROS的,而是单独通讯的
为了解除这种强依赖,可以尝试ROS,使得所有机械臂都能用(避免每来一套机械臂,就得比较费劲的写对应的通讯脚本),且还能和Isaac sim集成性非常好,可以做强化学习,当然,缺点是实时性比较差
- 如何理解这个「实际改写时 目标是去适配iDP3,从而借助iDP3达到对外通用化的目的」呢?
换言之,我们是借助iDP3的代码来做通用化改写的,其本质在于iDP3 留好了一个和各种机械臂通讯的接口——比如此文里分析的deploy.py以及其他部分,使得不论对接哪种机械臂,只需要发送对应信息 就可以接收了「相当于虽然还是得根据机器人写对应通讯脚本,但工作量小很多,且也模块化了」,而不是UMI只能在上位机硬改
另,为帮助更多个人更好的学习/转型/复现、更多公司更好的赋能自身业务,且同时寻找更多合作伙伴
故推出:具身智能机器人复现实战营 [含UMI/DexCap/DP3/iDP3],欢迎加入
此外,我司七月还可以帮采购UMI全套硬件(且过程中可帮调试/复现),详见下文的2.4节
最新更新,截止到24年10月份,目前我们把umi、dexcap这两个方向用的很熟了
我司「七月在线」第N次复现斯坦福UMI,让其摆杯子
觉得复现很简单的同学,大可以实际试一下,毕竟纸上谈兵永远简单。此外,复现之外,主要还是要想训练自己的功能,所有的算法逻辑都要很熟悉才可,所以我司还在优化dexcap
不过,dexcap代码是不全的,但是我们尝试了仿真 + 借助iDP3的代码做通用化改写
再补充一下上面提到的iDP3,其实之所以关注到iDP3,原因在于
- 一方面可以通过很简单的改通讯协议以达到控制多种机械臂之外
- 还因为它是人形上的动作策略,而我司于24年年底,开始在人形上做持续的探索
详见此文《斯坦福通用人形策略iDP3——同一套策略控制各种机器人:改进3D扩散策略,不再依赖相机校准和点云分割(含DP3的详解)》

第一部分 比Mobile Aloha成本更低的UMI刷盘机器人
1.1 之前机器人训练数据的收集方式:遥操作、视频学习、手持夹持器
在此之前,机器人收集训练数据一般有以下这几种方式:遥操作、视频学习、手持夹持器,以下分别阐述这三种方式
1.1.1 遥操作:数据质量很高 但获取难度大 数据量小
行为克隆(BC)利用遥操作机器人演示,以其直接的可转移性脱颖而出。然而,遥操作真实机器人进行数据收集面临重大挑战
- 以前的方法使用了诸如3D空间鼠标[9, 54]、VR或AR控制器[35, 3, 13, 19, 31, 51, 12]、智能手机[44, 45, 22],和触觉设备[38,47, 43, 26, 4] 用于遥操作
然这些方法要么非常昂贵,要么由于高延迟和缺乏用户直观性而难以使用。虽然最近诸如ALOHA [53-Learning fine-grained bimanual manipulation with low-cost hardware, 15-Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation] 和GELLO [46]的进展提供了具有直观和低成本界面的希望,但它们在数据收集过程中需要依赖真实机器人,此举限制了系统在“野外”数据采集中可以访问的环境类型和数量
此外,后续还有通过RGB相机到VR远程控制机器人的UC San Diego的三大机器人:AnyTeleop、Open-TeleVision、Bunny-VisionPro
以及斯坦福ALOHA团队推出的HumanPlus——斯坦福ALOHA团队开源的人形机器人:融合影子学习技术、RL、模仿学习 - 至于外骨骼 [14,20] 虽然消除了在数据收集过程中对真实机器人的依赖,但在部署时需要使用遥操作的真实机器人数据进行微调
此外,上面这些设备生成的数据和策略是特定于具体体现的,无法用于不同的机器人
1.1.2 来自人类视频的视觉演示:数据质量一般 获取容易 数据量很大
有的工作致力于从视频数据——例如YouTube视频中进行策略学习
即最常见的方法是从各种被动的人类演示视频中学习,利用被动的人类演示,先前的工作学习了任务成本函数 [37, 8, 1, 21]、可供性函(affordance function) [2]、密集物体描述符[40, 24, 39]、动作对应 [33, 28] 和预训练的视觉表示 [23-R3m: A universal visual representation for robot manipulation,48-Masked visual pre-training for motor control]
然而,这种方法遇到了三个主要挑战
- 首先,大多数视频演示缺乏明确的动作信息(这对于学习可推广的策略至关重要)
为了从被动的人类视频中推断动作数据,先前的工作采用了手部姿态检测器 [44-Mimicplay: Long-horizon imitation learning by watching human play, 1-Human-to-robot imitation in the wild, 38-Videodex: Learning dexterity from internet videos, 28- Dexmv: Imitation learning for dexterous manipulation from human videos],或将人类视频与域内遥操作机器人数据结合以预测动作 [33, 20, 34, 28] - 其次,人类和机器人之间明显的embodiment(物理本体,有的翻译为体现)差距阻碍了动作转移(the evident embodiment gap between humans and robots hinders action transfer)
弥合这一差距的努力包括通过手势重定向学习人类到机器人的动作映射 [38-Videodex: Learning dexterity from internet videos, 28-Dexmv: Imitation learning for dexterous manipulation from human videos] ,或提取与体现无关的关键点 [即embodiment-agnostic keypoint,49]
尽管有这些尝试,固有的embodiment差异仍然使得从人类视频到物理机器人的策略转移变得复杂 - 第三,这一领域的工作中,由embodiment差距引起的固有观察差距在训练/推理时间观察数据之间引入了不可避免的不匹配,尽管在对齐演示观察与机器人观察方面做出了努力 [20, 28],但仍加剧了所产生策略的可转移性
1.1.3 用于准静态操作的手持夹持器(Hand-Held Grippers for Quasi-static Action)及动作捕捉
手持夹持器 [41- Grasping in the wild: Learning 6dof closedloop grasping from low-cost demonstrations, 50, 10, 32, 27, 25] 在操作数据收集中最小化了观察体现差距,提供了便携性和直观界面,从而在野外高效收集数据
然而,从这些设备中准确且稳健地提取六自由度 (6DoF) 末端执行器 (EE) 姿态仍然具有挑战性,阻碍了从这些数据中学习到的机器人策略在细粒度操作任务中的部署
此外,还有类似DexCap那种动作捕捉数据——DexCap——斯坦福李飞飞团队泡茶机器人:带灵巧手和动作捕捉的数据收集系统(含硬件改进VIVE)
值得一提的是,和UMI类似的工作有哪些呢?
- 之前有一些手持的数据收集设备,但并不是特别多。主要问题在于它们的动作控制不够精确。以前使用的结构光成像技术只能告诉你当前运动的方向,但无法得知绝对的三维坐标,即位置和旋转。这涉及到六个自由度,即三个位置和三个旋转
- 以前的方法无法准确获取这些六个参数。相比之下,UMI主要使用GoPro相机结合SLAM技术,可以更精确地进行六自由度的跟踪。这是相对于以前工作的优势之一
1.2 斯坦福UMI的主要特点和手持夹持器的设置
24年2.19,斯坦福和哥伦比亚大学、丰田研究所的研究者(Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, Shuran Song等8人)发布了一个通用操控界面UMI,借助这个UMI,可以自由的完成刷盘等各种任务「一个任务收一类数据,然后训练一个模型」

其主要特点有:
- UMI本质是一个用于数据收集和策略学习的框架,其使用手持夹持器可以简单快速且低成本的收集一系列训练机器人的数据
- 且其更考虑了三方面的延迟:机器人观察环境存在延迟(传感器导致)、拿到环境数据后做推理有延迟、推理完成到做出动作亦有延迟
- 使用鱼眼镜头感知环境,且通过改造SLAM与GoPro内置的IMU传感器结合使用,并在夹持器上的两端各自添加一面镜子,以提供立体观察
如下图所示,从左到右分别表示人类做示范的手持夹持器、观测空间、机器人设置,其中
①是一个相机,④是“相机① ”中自带的IMU感知姿态跟踪器
②是带有广角视野的鱼眼镜头,③是两个侧面镜用于提供立体视觉,⑤是对夹持器的跟踪
⑥是基于运动学的数据过滤
这六个部分的细节很快将在下文逐一阐述
- 使用扩散策略进行动作预测,当然,也可以换成mobile aloha所用的ACT算法
扩散策略的更多细节在本文第三部分进行阐述
1.2.1 GoPro摄像头、鱼眼镜头(扩大视野)、侧面镜(深度信息)、IMU感知跟踪(捕捉精确动作)
首先,在手腕上安装一个GoPro摄像头作为输入观察,此外,无需任何外部摄像头设置。之后在机器人上部署UMI时,将GoPro相机放置在与手持夹持器上相对应的3D打印手指的同一位置
其次,如下图所示,如果将一个大的155°视场图像矫正为针孔模型会严重拉伸外围视野(蓝线外),同时将中心最重要的信息压缩到一个小区域(红线内),故UMI策略使用原始鱼眼图像作为观测

接着,为看弥补单目相机视野中缺乏深度感知的问题,在相机的左右两端分别放置了一块镜子,如下图所示,UMI侧面镜,从而使得超广角相机与位置合理的镜子相结合,实现了隐式立体深度估计

- (a):每个镜子的视角有效地创建了两个虚拟相机,其姿态相对于主相机沿镜子平面反射
- (b):盘子上的番茄酱在主相机视野中被遮挡,但在右侧镜子内可见,证明镜子模拟具有不同光学中心的相机
- (c):对镜子内的内容进行数字反射以进行策略观察。 请注意,在反射后,杯子把手的方向在所有3个视图中保持一致
最后,UMI通过利用GoPro内置的IMU传感器来记录IMU数据(加速度计和陀螺仪)到标准的mp4视频文件中(UMI captures rapid move-ments with absolute scale by leveraging GoPro’s built-incapability to record IMU data (accelerometer and gyroscope) into standard mp4 video files)
且通过联合优化视觉跟踪和惯性姿态约束,基于OBR-SLAM3的惯性单目SLAM系统(By jointly optimizing visual tracking and inertial pose constraints, our Inertial-monocular SLAM system based on OBR-SLAM3 [7——Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam]),即使在由于运动模糊或缺乏视觉特征,导致视觉跟踪失败(例如俯视桌子)的情况下,仍能维持一段时间的跟踪
一开始,他们发现OBR-SLAM3 [7]的原始单目惯性SLAM系统不适用于他们的应用。特别是,ORB-SLAM3有一个初始化过程,其中前几个地图点和关键帧以及IMU校准参数是通
过启发式方法计算的他们发现这个初始化过程在快速运动下特别脆弱且耗时,在此期间无法估计相机姿态,导致大量数据浪费
为了解决这个问题,他们实现了两个功能:地图初始化和标记增强初始化
- 地图初始化
原始的ORB-SLAM3有一个定位模式,可以定位到现有地图而不以任何方式更改地图,包括创建更多地图点或执行任何全局优化,且发现现有的定位模式在UMI操作动态改变场景时不够稳健
为了解决这个问题,他们修改了ORB-SLAM3,使其在重新定位到从磁盘加载的现有地图后继续正常的SLAM操作,有效地将现有地图仅用作优化的初始值- 标记增强初始化(Marker-enhanced initialization)
由于单目SLAM公式的固有模糊性,ORB-SLAM3的现有初始化在特征点距离较远(户外环境)或特征点匹配错误较多(repeated patterns, trees等)时表现不佳
他们修改了ORB-SLAM3,使其可以选择利用已知尺寸的基准标记[16]来消除特征匹配中可能出现的歧义「We modified ORB-SLAM3 to optionally take advantage of fiducial markers [16] with known sizes to disambiguate possible explanations of feature matches」,且发现该特性显著提升了实际环境中建图的鲁棒性
当然,请注意,演示视频中不会包含这些基准标记,它们仅用于映射
1.2.2 连续夹持器控制与基于运动学的数据过滤
与之前的机器人一般使用的二进制开合动作(要么抓住、要么放开),但如果连续指定夹持器的夹持宽度则可以执行更多任务,比如投掷一个球时,需要在一个准确的时刻来扔掉物体
由于物体具有不同的宽度,二进制夹持器的动作很难满足精度要求。 在 UMI 夹爪上,指宽通过标记物进行连续跟踪。利用串联弹性末端执行器原理 [42],UMI 可以通过连续控制夹爪宽度来调节软指的变形,从而隐式地记录和控制抓取力(On UMI gripper, finger width is continuously tracked via fiducial markers [16] (Fig. 2 left). Using series-elastic end effectors principle [42], UMI can implicitly record and control grasp forces by regulating the deformation of soft fingers through continuous gripper width control)
此外,虽然数据收集过程与机器人本身无关,故可以应用简单的基于运动学的数据过滤来选择不同机器人embodiments的有效轨迹,具体而言
- 当知道机器人基座位置和它的运动学特性时,使用SLAM技术得到终端执行器(如机器人手臂的末端)的精确位置信息,可以允许对演示数据进行运动学和动力学的可行性过滤
- 通过在这些经过筛选的数据集上进行训练,可以确保机器人的行为策略不仅是可行的,而且符合其结构的特定运动限制(when the robot’s base location and kinematics are known, the absolute end-effector pose recovered by SLAM allows kinematics and dynamics feasibility filtering on the demonstration data. Training on the filtered dataset ensures policies comply with embodiment-specific kinematic constraint)
最终,UMI夹持器重量为780g,外部尺寸为 L310mm × W 175mm ×H210mm,手指行程为80mm
3D打印的夹持器的BoM成本为 $73,而GoPro相机及配件的总成本为 $298
说白了,不含「计算电脑和那两UR5机械臂」的仅用于数据收集的硬件成本为400刀,当然 好的机械臂才贵
1.3 UMI的策略接口设计
1.3.1 三种延迟:观察延迟、策略推理延迟、执行延迟
正如人在路上开车一样
- 从开始观察到真正感知到环境时 有观测反应时间,即观测延迟
- 而感知到环境做决策时,则有决策时的反应时间,即推理延迟
- 最后,决策好之后 做出行动 也会有一个执行时间,即执行延迟
机器人在实际操控当中,也是类似的,也会一一存在
- 观察延迟(observation latency):
- 策略推断延迟(policy inference latency):
- 执行延迟(execution latency):
,且简单地丢弃过时的动作,只执行每个硬件在
之后具有所需时间戳的动作
下图表示的是UMI 策略接口设计
- (b) UMI 策略接收一系列同步观察结果(RGB 图像、6自由度末端执行器姿态、和夹持器宽度),并输出一系列期望的末端执行器姿态和夹持器宽度作为动作
相当于先感知环境,然后做出动作预测 - (a) 同步不同的观察流,以弥补物理测量的延迟
- (c) 提前发送动作命令以补偿机器人的执行延迟
为方便大家理解,把上图中的英文描述翻译如下

1.3.2 延迟测量之相机延迟、本体感觉延迟、夹持器执行延迟、机器人执行延迟
准确校准机器人系统中各种延迟对于部署UMI策略至关重要, 特别是对于需要快速和动态动作的任务
1.3.2.1 相机延迟测量
为了在 UR5 和 Franka FR2 平台上进行策略观察,他们在每个机器人手臂上安装了一个腕部安装的 GoPro Hero 9 相机
- 为了从 GoPro 获取实时视频流,使用了 GoPro Media Mod 1.0(将 USB-C 转换为 HDMI)和 Elgato HD60X 外部采集卡(将 HDMI 转换为 USB-3.0 UVC 接口)的组合
- 为了测量相机管道的端到端延迟,用 GoPro 相机记录计算机显示器上滚动的二维码,该二维码显示每个视频帧的当前系统时间戳
,如下图所示
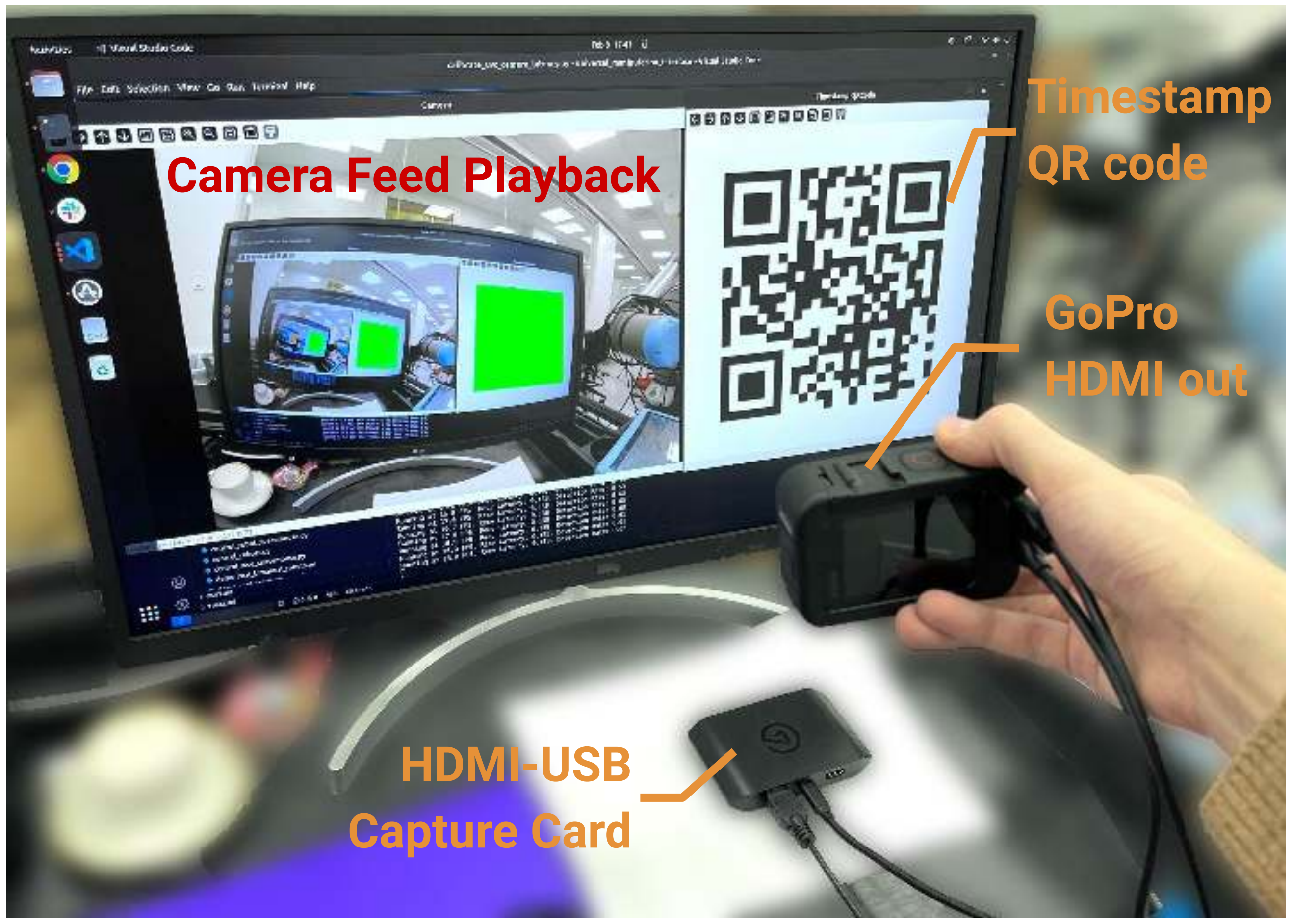
- 为了防止通过相机流叠加多次检测二维码,在相机回放中屏蔽了二维码,如上图的显示器左侧所示
最终,通过减去每帧的接收时间戳和解码的二维码时间戳
,并减去已知的显示刷新延迟
,便可以获得相机系统的端到端延迟「By subtracting the receiving timestamp for each frame trecv and the decoded QR code timestamp tdisplay, and subtracting the known latency of display refresh ldisplay, we can obtain the end-to-end latency of camera system」:
在双手操作确认中使用 UMI 时,通过扫描智能手机上的滚动二维码来同步两个GoPro 相机的内部时钟
“GoPro Labs”实验固件识别编码在二维码中的全球时间戳,并以
秒的精度校准其内部时钟。对于单臂任务,可以跳过此步骤
1.3.2.2 本体感觉延迟测量
当机器人硬件直接报告全局时间戳时,例如Franka FR2机器人,通过从策略接收时间戳 减去机器人发送时间戳
,来测量本体感觉延迟:
当机器人硬件时间戳不可用时,例如UR5机器人和Schunk WSG-50夹持器,他们用ICMP往返时间(即ping)的来近似本体感觉延迟「we approximat the proprioception latency with 1/2 of ICMP round-trip time(i.e. ping)」
1.3.2.3 夹持器执行延迟测量
为了获得夹持器执行延迟,他们通过本体感觉延迟
减去端到端延迟
为了测量,他们向夹持器发送一系列正弦位置命令,然后记录一系列夹持器宽度预感。通过交叉卷积计算所需夹持器宽度信号与实际接收的夹持器宽度信号之间的最佳对齐,可以获得
1.3.2.4 机器人执行延迟测量
类似于夹持器,他们还通过计算来测量机器人(UR5或Franka)的执行延迟,作为一系列期望末端执行器姿态与实际测量末端执行器姿态之间的最佳对齐
出于安全考虑,他们直接远程操作机器人以生成期望的末端执行器姿态序列
1.4 完成刷盘的任务
1.4.1 刷盘任务的拆解
任务机器人需要执行7个步骤顺序地独立动作(打开水龙头、抓住盘子、拿起海绵、洗涤并擦拭盘子直到番茄酱被清除、放置盘子、放置海绵并关闭水龙头),如下图所示

能力这项任务从几个方面推动了机器人操纵能力的边界:
- 这是一个超长视野任务,每个步骤的成功都依赖于前一个步骤
- 机器人需要感知和操纵复杂的流体,包括牛顿流体(即,水)和非牛顿流体(即,番茄酱)
- 擦拭动-作需要使用一个可变形工具(即,海绵)同时协调双臂相对于水流
- 操纵受限关节物体(即,打开和关闭水龙头)需要由软指提供的机械顺应性
- 策略也需要对“清洁度”的概念语义上的鲁棒性。当在洗涤过程中或即使洗涤阶段完成后添加了额外的番茄酱时,机器人需要继续洗涤和擦拭
1.4.2 微调一个CLIP预训练的ViT-B/16视觉编码器来训练扩散策略
对于这项任务,UMI通过微调一个CLIP 预训练的ViT-B/16视觉编码器来训练扩散策略,并在微调过程中实施了较低的学习率,设置为原来的 1/10
看到这句话时,我的第一反应是这个视觉编码器和DALLE 2在CLIP阶段所用的视觉编码器是一个意思,即下图右上角的img encoder(来自此文:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM )

总的来说,UMI达到了14/20 =70%的成功率。 此外,他们还展示了他们的策略对各种干扰物、酱料类型(芥末、巧克力糖浆、焦糖糖浆)以及对扰动的鲁棒性
而没有CLIP预训练的ViT视觉编码器「比如从头训练ResNet-34 [17]则任务完成度不行」,比如带有ResNet-34的基线策略学会了一种非反应性行为,并忽略了任何盘子或海绵位置的变化。 因此,它不能执行任务,0/10 = 0%

第二部分 UMI的硬件安装指南
2.1 详细的3D打印/组装教程(引用来源)
- 3D打印教程: https://youtu.be/EJmAg1Bnp-k
- 夹持器组装教程:https://youtu.be/x3ko0v_xwpg
2.2 材料清单:配件、CAD、3D打印夹爪
2.2.1 各种小配件:胶布、螺丝、GoPro Hero9、鱼眼镜头
| Part | Quantity | Link | Price (per unit) |
| 夹持器Gripper Body | ~$62 | ||
| eSUN PLA PRO Warm White 1kg | 0.5 | $24.99 | |
| MGN9C 150mm Linear Rail | 2 | $17.89 | |
| M3 Screws and Nuts 14x M3x8mm 2x M3x12mm 4x M3x25mm 6x M3x35mm | 0.5 | $22.99 | |
| Compression Spring 10mm OD 0.7mm Wire size 50mm Free length | 0.2 | $5.49 | |
| M5 Nut | 1 | ||
| Plastic Stick-on Mirror | $9.99 | ||
| Super Lube-21030 | $10.00 | ||
| Double-sided Tape | $9.99 | ||
| Printed ArUcO tags (US letter) | |||
| Gripper Finger | ~$11 | ||
| Polymaker TPU 95A Orange 750g | 0.25 | $29.99 | |
| 3M TB641/GM641 Grip Tape 1 inch wide 1ft | 0.07 | $54.14 | |
| GoPro Camera | ~$298 | ||
| GoPro Hero9 | 1 | $209.99 | |
| GoPro Max Lens Mod 1.0 | 1 | $69.29 | |
| Micro SD Card V30 Rated | 1 | $17.99 | |












For all-day operations, consider purchasing 2x more batteries per gripper and one battery charger per gripper.
以上总费用(美元):$399.41,相当于400刀
总费用(人民币):¥2875.72
2.2.2 CAD Models
2.2.3 3D printing instructions
Checkout our CURA 3mf examples for more detailed parameters:
https://drive.google.com/drive/folders/15vFeCd-fEt-NOYkRXebhpDGm5D2zX3MM?usp=sharing
- Common Print Parameters (PLA+):
Nozzle diameter: 0.6mm
Layer height: 0.3mm
Wall thickness: 1.2mm
Top-bottom thickness: 1.2mm
Infill: 20% Gyroid
Temperature: 190C for eSun PLA+ - Finger Print Parameters (TPU):
Nozzle diameter: 0.6mm
Layer height: 0.3mm
Infill: 100% lines
Temperature: 255C for polymaker TPU 95A
Part specific print parameters:
| Part | Infill % | Support? | Wall mm | Top-bottom mm |
| Print 1: gripper_covers | ||||
| bottom_plate | ||||
| top_plate | ||||
| Print 2: gripper_internals | ||||
| grip | 100 | 1.8 | ||
| handle | ||||
| Cube | ||||
| finger_holder_left/right | Yes | |||
| gear_left/right | ||||
| linkage_left/right | 2.4 | 1.8 | ||
| Print 3: gripper_fingers | ||||
| finger | 100 | |||
2.2.4 夹爪的Photos
Reference for the position and orientation of ArUcO tags. Please note that left and right grippers have different tags! The ArUcO tags on the large cube are currently unused by the algorithm therefore completely optional.
Tag PDF for printing:
https://drive.google.com/drive/folders/1pCiuABTyev7k4EWJ3LQ-zKz3ZHjzeIDF?usp=sharing

2.3 Deployment Hardware Building Guide(含机械臂、WSG-50等)
Bill of Materials (per-arm)
| Part | Quantity | Link | Price (per unit) |
| Robot | |||
| UR5e or UR5-CB3 robot (with power and ethernet cable) | 1 | By Quote | |
| Weiss WSG-50 gripper (with power and ethernet cable, no fingers) | 1 | € 3875 | |
| Camera System | ~$546.58 | ||
| GoPro Hero9 | 1 | $209.99 | |
| GoPro Max Lens Mod 1.0 | 1 | $69.29 | |
| GoPro Media Mod | 1 | $79.99 | |
| Elgato HD60 X Capture Card | 1 | $147.34 | |
| Micro HDMI to HDMI cable 15 ft | 1 | $12.99 | |
| USB-C to USB-A cable 10ft | 2 | $13.49 | |






以上的总费用为:$546.58(¥3935) + 两个Weiss WSG-50€ 3875 x 2(差不多¥6万) + UR5e机器人(1台大概¥20万-25万之间) = 差不多26-30万
2.4 我司七月可帮采购的UMI全套硬件(含帮调试/复现),及具身实战营
2.4.1 UMI的全套硬件设备汇总
经常有高校或公司的朋友私信我说,帮他们采购相关硬件,如需帮采购全套硬件(且过程中可帮调试/复现),皆可通过“CSDN私信”私我,费用更优惠的情况下帮少走弯路、少踩坑
| 序号 | 所属类别 | 具体型号 |
| 1 | 协作机器人 | ur5e umi开源的版本是不支持5的,必须是5e,不过,我司七月后来解决了该问题 且也可以换成ur7e |
| 2 | 国外原装电动夹爪WSG-50 Gripper | 5120008 WSG 50-110 Bundle(即带线缆和安装板) |
| 2 | 国产平替电动夹爪 | 大寰PGI |
| 3 | 机械臂托架 | 定制 |
| 4 | 视觉相机系统 | GoPro Hero 9(官方标配) |
| 5 | 视觉相机系统 | 鱼眼镜头(配合GoPro Hero 9) |
| 6 | 视觉相机系统 | 扩展接口(含麦克风外框) |
| 7 | 视觉相机系统 | 配件 (SD卡) |
| 8 | 视觉相机系统 | HDMI视频采集卡 + Micro HDMI转HDMI2.0转接线 |
| 9 | 交换机及网线等配件 | 亿佰特工业级RS485/232转以太网串口服务器模块 |
| 10 | 控制鼠标 | 3Dconnexion 3DX-700066 |
| 11 | 手持3D打印夹爪 | 组装好的umi手持模型(强化材料) |
| 12 | 同尺寸的电夹爪模型 | 组装好的umi电夹爪模型(强化材料) |
2.4.2 具身智能机器人复现实战营 [复现实战UMI/DexCap]
如本文开头所述,为帮助更多个人更好的学习/转型/复现、更多公司更好的赋能自身业务,且同时寻找更多合作伙伴
故推出:具身智能机器人复现实战营 [复现实战UMI/DexCap],欢迎加入,下面两张照片则拍摄于我司「七月在线」举办的具身机器人实战营


第三部分 Diffusion Policy:基于CNN或Transformer
如我组建的mobile aloha复现团队里的邓老师所说,mobile aloha也用了 diffusion,不过是作为对比实验的打击对象来用的
下面,我们便来解读下Diffusion Policy
3.1 什么是Diffusion Policy及其优势
3.1.1 什么是扩散策略
23年3月份,来自哥伦比亚大学Columbia University、Toyota Research Institute、MIT的研究者们提出了扩散策略
其将机器人的视觉运动策略表示为条件去噪扩散过程,从而来生成机器人行为(或者,说白了,Diffusion Policy就是应用Diffusion方法生成机器人动作的一种Policy,或者说的更直白点,扩散模型在图像生成领域已经应用广泛了,而扩散策略则探索的是扩散模型在机器人领域的动作生成)

- 其作者团队为:Cheng Chi1, Siyuan Feng2, Yilun Du3, Zhenjia Xu1, Eric Cousineau2, Benjamin Burchfiel2, Shuran Song1 (带下划线的表示同时也是UMI的作者)
直白讲,Diffusion Policy这个工作是哥伦比亚大学宋舒然团队和MIT教授Russ Tedrake带领的丰田机器人研究院共同创作
论文的一作迟宬目前是哥伦比亚大学的计算机科学博士生,在宋舒然的指导下做机器人操纵和感知相关的研究 - 其对应的论文为:Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 其对应的网站为:diffusion-policy.cs.columbia.edu
- 其对应的GitHub仓库为:real-stanford/diffusion_policy
进一步而言,如下图所示

- a)具有不同类型动作表示的显式策略(Explicit policy with different types of action representations)
- b)隐式策略学习以动作和观察为条件的能量函数,并优化能够最小化能量景观的动作
Implicit policy learns an energy function conditioned on both action and observation and optimizes for actions that minimize the energy landscape - c)通过“条件去噪扩散过程在机器人行动空间上生成行为”,即该扩散策略不是直接输出动作,而是根据视觉观察推断且经过K次去噪迭代的动作得分梯度
instead of directly outputting an action, the policy infers the action-score gradient, conditioned on visual observations, for K denoising iterations
....
由于Diffusion Policy的细节很多且重要性很高,故原本属于本第三部分的Diffusion Policy后已独立成文,见《Diffusion Policy——斯坦福刷盘机器人UMI所用的扩散策略(含Diff-Control、ControlNet详解)》
第四部分 UMI代码的整体解读
注意,以下解读基本来自我司大模型项目组的远根同学,之所以分享其中的部分出来,是想招纳可以针对UMI共同做二次开发的朋友,如有意敬请私我
本部分后来已抽取出来独立成文:《斯坦福UMI代码解析(刷盘机器人):Universal Manipulation Interface代码的整体解读》
更多欢迎加入本文开头所说的「具身智能机器人复现实战营 [含UMI/DexCap/DP3/iDP3]」


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











