







前言
本文一开始是属于此文《HumanPlus——斯坦福ALOHA团队开源的人形机器人:融合影子学习技术、RL、模仿学习》的,但由于人体姿态估计WHAM与手势估计HaMeR比较重要,特别是在重定向的步骤中,故导致越写越长,故独立抽取出来成为本文了
越往后,看paper 研究paper 解读paper,已成日常,核心还是给我司人形机器人开发团队的一系列落地工作(当然,我司在人形方向的落地,短期内还是侧重面向工厂特定场景的算法解决方案),探路
第一部分 姿态估计之 WHAM
1.1 WHAM的整体架构
根据arXiv的记录,此篇论文WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion的提交记录为[Submitted on 12 Dec 2023 (v1), last revised 18 Apr 2024 (this version, v2)],其对应的GitHub地址则为:yohanshin/WHAM
如下图所示,WHAM的输入是由可能具有未知运动的相机捕获的原始视频数据,接下来的目标是预测对应的SMPL模型参数序列
,以及在世界坐标系中表达的根方向
和平移
,具体做法是

- 使用ViTPose [54] 检测2D关键点
,从中使用Motion Encoder获得运动特征
- 此外,使用预训练的Image Encoder[7,21,25] 提取静态图像特征
,然后将这个图像特征与上面的运动特征
结合,以获得细粒度的运动特征
1.1.1 Motion Encoder and Decoder
对于 Motion Encoder and Decoder而言,与之前的方法使用固定时间窗口不同,这里使用RNN来作为运动编码器、运动解码器
- 运动编码器
的目标是基于当前和之前的2D 关键点(keypoints)和初始隐藏状态
而提取运动上下文
,即
过程中,We normalize keypoints to a bounding box around the person and concatenate the box’s center and scale to the keypoints,similar to CLIFF [ 25]. - 运动解码器
的作用是从运动特征历史中恢复:
SMPL参数
即
其中的如上面说过的,是图像特征与运动特征结合而成的细粒度运动特征
其中有一个关键点是咱们需要利用时间上的人体运动上下文,将2D关键点提升到3D网格,那如何做到呢,一个比较好的办法便是利用图像线索来增强这些2D关键点信息
具体而言,可以
- 先使用一个图像编码器,在人体网格恢复这个任务上做预训练,以提取图像特征
,这些特征包含与3D人体姿态和形状相关的密集视觉上下文信息
- 然后我们训练一个特征整合网络
,将
与
1.1.2 全局轨迹解码器Global Trajectory Decoder
作者团队还设计了一个额外的解码器,用于从运动特征
中预测粗略的全局根方向
和根速度
「We design an additional decoder, DT , to predict the rough global root orientation Γ(t)0 and root velocity v(t)0 from the motion feature ϕ(t)m」
但由于是从相机坐标系中的输入信号派生的,因此将人类和相机运动从中解耦是非常具有挑战性的。为了解决这种模糊性,我们将相机的角速度
,附加到运动特征
,创建一个与相机无关的运动上下文。 这种设计选择使WHAM兼容现成的SLAM算法 [46, 47] 和现代数字相机广泛提供的陀螺仪测量
再之后,使用单向RNN递归预测全局方向
1.1.3 通过脚是否触地:做接触感知轨迹的优化(Contact Aware Trajectory Refinement)
具体来说,新轨迹优化器旨在解决脚滑问题,并使WHAM能够很好地泛化到各种运动(包括爬楼梯),而这个新轨迹优化涉及两个阶段
首先,根据从运动解码器估计的脚-地面接触概率
,调整自我中心的根速度
以最小化脚滑
其中,是当接触概率
高于阈值时,脚趾和脚跟在世界坐标中的平均速度。 然而,当接触和姿态估计不准确时,这种速度调整往往会引入噪声平移
因此,我们提出了一种简单的学习机制,其中轨迹优化网络更新根部方向和速度以解决此问题。 最后,通过展开操作计算全局平移:
1.2 WHAM的两阶段训练:先AMASS上预训练,然后视频数据集上微调
分两个阶段进行训练:
- 使用合成数据进行预训练
- 使用真实数据进行微调
1.2.1 在AMASS上进行预训练
预训练阶段的目标是教会运动编码器从输入的2D关键点序列中提取运动上下文。 然后,运动和轨迹解码器将此运动上下文映射到相应的3D运动和全局轨迹空间(即它们将编码提升到3D)
作者使用AMASS数据集[32]生成由2D关键点序列和真实SMPL参数组成的大量合成对。为了从AMASS合成2D关键点,作者创建了虚拟摄像机,将从真实网格派生的3D关键点投影到这些摄像机上
与MotionBERT[62]和ProxyCap[61]使用静态摄像机进行关键点投影不同,我们采用了结合旋转和平移运动的动态摄像机。 这个选择有两个主要动机
- 首先,它考虑到了在静态和动态相机设置中捕捉到的人类运动的固有差异
- 其次,它使得能够学习与相机无关的运动表示,从中轨迹解码器可以重建全局轨迹
作者还通过噪声和掩蔽来增强2D数据
1.2.2 在视频数据集上微调
从预训练网络开始,作者在四个视频数据集上微调WHAM:
- 3DPW[49]
- Human3.6M [11]
- MPI-INF-3DHP [33]
- InstaVariety [15]
对于人类网格恢复任务,作者在AMASS和3DPW的真实SMPL参数、Human3.6M和MPI-INF-3D
HP的3D关键点以及InstaVariety的2D关键点上监督WHAM
对于全局轨迹估计任务,作者使用AMASS、Human3.6M和MPI-INF-3DHP
此外,在训练期间,作者尝试添加BEDLAM [1],这是一个具有真实视频和真实SMPL参数的大型合成数据集
微调有两个目标:1)使网络暴露于真实的2D关键点,而不是仅在合成数据上训练,2)训练特征整合网络以聚合运动和图像特征
为了实现这些目标,我们在视频数据集上联合训练整个网络,同时在预训练模块上设置较小的学习率
与之前的工作一致[6, 17, 30, 43, 52],我们采用预训练和固定权重的图像编码器[21]来提取图像特征。然而,为了利用最近的网络架构和训练策略,我们在以下部分中还尝试了不同类型的编码器[1, 7, 25]
以下是有关训练的部分细节
- 在预训练阶段,我们在AMASS上训练WHAM 80个周期,学习率为5 × 10−4。 然后我们在3DPW、MPI-INF-3DHP、Human3.6M和InstaVariety上微调WHAM 30个周期
- 在微调期间,对特征整合器使用的学习率为 1 × 10−4,对预训练组件使用的学习率为1×10−5。在训练期间,使用Adam优化器和批量大小
第二部分 AMASS的详解:大型且多样化的人体运动数据库
AMASS,这是一个大型且多样化的人体运动数据库,它通过在通用框架和参数化中表示 15 种不同的基于光学标记的动作捕捉数据集来统一它们,其对应的论文为《AMASS: Archive of Motion Capture as Surface Shapes》
- 其使用一种新方法 MoSh++ 来实现这一点,该方法将动作捕捉数据转换为由装配身体模型表示的逼真的 3D 人体网格
这里使用 SMPL [https ://doi.org/10.1145/2816795.2818013 ],它被广泛使用并提供标准骨架表示以及完全装配的表面网格。该方法适用于任意标记集,同时恢复软组织动态和逼真的手部运动 - 其使用与基于标记的运动捕捉(marker-based mocap)联合记录的 4D 身体扫描新数据集来评估 MoSh++ 并调整其超参数。AMASS 的一致表示使其可轻松用于动画、可视化和生成深度学习的训练数据。我们的数据集比以前的人体运动集合丰富得多,拥有超过 40 小时的运动数据,涵盖 300 多个主题,超过 11,000 个动作
// 待更
第三部分 SMPL-X的详解
3.1 整体理解SMPL-X——基于单张RGB图像建模3D人体和脸部
3.1.1 之前工作(包括SMPL在内)的局限
为了理解人类行为,需要捕捉的不仅仅是身体的主要关节——还需要身体、手和面部的完整3D表面。由于缺乏合适的3D模型和丰富的3D训练数据,目前还没有系统能够做到这一点
比如下图「身体的主要关节不足以代表这一点,当前的3D模型也不够具表现力。从左到右:RGB图像、主要关节、骨架、SMPL(女性),哪怕是最右侧的SMPL,在其脸部可以发现,眼睛没睁开、嘴巴也没张开,相当于没有体现面部表情」
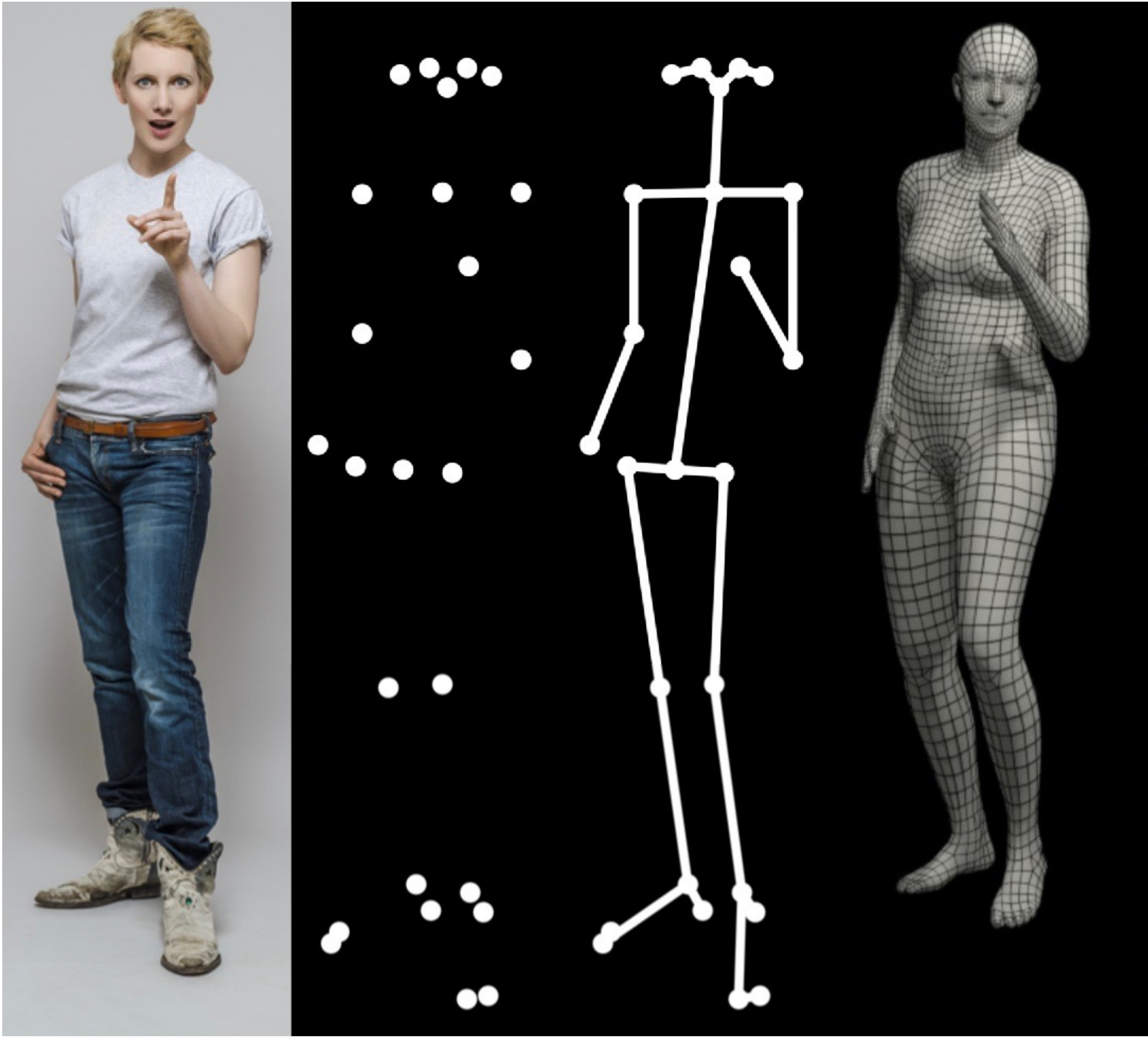
总之,仅使用稀疏的2D信息或缺乏手部和面部细节的3D表示来解释具有表现力和交流性的图像是困难的
为了解决这个问题
- 首先,需要一个能够表示人脸、手和身体姿态复杂性的3D模型
- 其次,需要一种从单张图像中提取这种模型的方法
神经网络的进步和大量手动标注图像的数据集已经使得2D人体“姿态”估计取得了快速进展。所谓“姿态”,该领域通常指身体的主要关节。这不足以理解人类行为
虽然,OpenPose [15,59,69] 扩展了这一点,包括2D手部关节和2D面部特征,其捕捉了更多关于交流意图的信息,但它并不支持对表面和人类与三维世界互动的推理
而3D身体模型主要集中于捕捉身体的整体形状和姿态,不包括手和脸[2,3,6,26,48]。在3D中建模手[39,52,56,57,67,68,70,73,74]和脸[4,9,11,13,14,43,62,75,78]的文献也相当丰富,但这些通常是与身体其他部分隔离开的 - 直到最近,该领域才开始将身体与手[67]或与手和脸[36]一起建模
例如,Frank模型[36]结合了简化版的SMPL身体模型[48]、一个由艺术家设计的手部骨架和FaceWarehouse[14]面部模型
the Frank model parameters are estimated from multi-camera data by fitting the model to 3D keypoints and 3D point clouds. The capture environment is complex, using 140 VGA camerasfor the body, 480 VGA cameras for the feet, and 31 HDcameras for the face and hand keypoints. - 在此SMPL-X团队从大量3D扫描中学习一个新的整体身体模型,包括面部和手部
即,新的SMPL-X模型(SMPL eXpressive)基于SMPL,并保留了该模型的优点:与图形软件的兼容性、简单的参数化、小尺寸、高效、可微分等
且将SMPL与FLAME头部模型[43]和MANO手部模型[67]结合,然后将此组合模型注册到作者为质量策划的55863D扫描中。通过从数据中学习模型,作者捕捉到身体、面部和手部形状之间的自然关联,且结果模型没有伪影
比如下图所示,将SMPL-X拟合到富有表现力的RGB图像上
3.2.2 之前训练数据集SMPLify的局限性
然而,要估计带有手和面部的3D身体,目前没有合适的训练数据集。为了解决这个问题,作者遵循SMPLify的方法
- 首先,使用OpenPose[15,69,76]“自下而上”地估计2D图像特征,它检测身体、手、脚和面部特征的关节
- 然后,“自上而下”地将SMPL-X模型拟合到这些2D特征上,该方法称为SMPLify-X
为此,作者在SMPLify的基础上做了几项重大改进
- 具体来说,他们从一个大型动作捕捉数据集[47,50]中使用变分自编码器学习了一个新的、更高性能的姿态先验。这个先验至关重要,因为从2D特征到3D姿态的映射是模糊的
- 还定义了一个新的(自)相互穿透惩罚项,比SMPLify中的近似方法更准确和高效,同时保持可微性
且训练了一个性别检测器,并使用它自动确定使用哪种身体模型:男性、女性或性别中立 - 最后,直接回归方法训练SMPL参数的一个动机是因为SMPLify速度慢。作者通过PyTorch实现解决了这个问题,其速度至少比相应的Chumpy实现快8倍,利用了现代GPU的计算能力
3.3 深入SMPL-X的细节:从SMPL-X到SMPLify-X(从单张图像生成SMPL-X)
3.3.1 统一模型:SMPL-X
作者创建了一个统一模型,称为SMPL-X,代表SMPL eXpressive,其形状参数是为面部、手部和身体联合训练的。SMPL-X使用标准的基于顶点的线性混合蒙皮,并具有学习的校正混合形状「SMPL-X uses standard vertex-based linear blend skinning with learned corrective blend shapes」,具有N=10,475个顶点和K=54个关节,其中包括颈部、下颌、眼球和手指的关节
- SMPL-X由一个函数
定义:
,以姿势
为参数,其中K是身体关节的数量,外加一个用于全局旋转的关节
- 将姿势参数θ分解为:下颌关节的
、手指关节的
,以及其余身体关节的
身体、面部和手部的形状参数记为
,面部表情参数记为
更正式地说
其中
是形状混合形状函数,β是线性形状系,|β|是它们的数量,
是顶点位移的正交主成分,捕捉由于不同人物身份导致的形状变化
是所有这些位移的矩阵
是姿势混合形状函数,该函数向模板网格T添加校正顶点位移,如在SMPL [47]中所示
其中是一个函数,将姿势向量θ映射到一个连接的部分相对旋转矩阵的向量,使用Rodrigues公式[12,54,64]计算
更多细节参见原论文
3.3.2 SMPLify-X:从单张图像生成SMPL-X
为了将SMPL-X拟合到单张RGB图像(SMPLify-X),作者遵循SMPLify [10]的方法,但对其各个方面进行了改进
比如他们将SMPL-X拟合到图像的问题公式化为一个优化问题,在其中寻求最小化目标函数
其中、
和
分别是身体、面部和双手的姿态向量,而θ是可优化姿态参数的完整集合。身体姿态参数是
的函数,其中
是一个低维姿态空间
是数据项,而
和
是手部姿态、面部姿态、身体形状和面部表情的简单L2先验项,惩罚偏离中性状态的情况
// 待更
第四部分 手势估计HaMeR
Reconstructing Hands in 3D with Transformers在arXiv的提交记录为[Submitted on 8 Dec 2023]

// 待更


















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











