







大语言模型能做什么?能做多好?如何验证?

接上一篇测评大语言模型的自然语言理解能力,这回把关注点放在大语言模型推理能力的测评上。看看大语言模型推理水平有多高,如何测试证实。
本文同样基于十几位中美学者在7月6日发布的《大语言模型测评调查》研究报告(https://arxiv.org/pdf/2307.03109.pdf )展开。
推理以及推论 Reasoning vs Inference

图:大语言模型通过推理过程获得结果推论
"Reasoning"(推理)和 "Inference"(推论)是两个紧密相关又有些许不同的概念。在研究大模型的自然语言理解的工作中,重点往往在自然语言的推论,即推理的结论,所以一般会讲Inference;而在研究大模型的推理能力的工作中,侧重点更多地放在了逻辑和思维的过程。会讲Reasoning多一些。即,通过推理(Reasoning)过程产生推论(Inference)的结果。
举个例子来说明:假设"所有人都需要喝水"(这是一个前提条件),然后得出"约翰需要喝水"这个结论。在这个例子中,推理(Reasoning)是整个过程,包括考虑到前提条件并应用逻辑规则来得出结论。而推论(Inference)是最终的结论,即"约翰需要喝水"。
分析结论对错不能不联系得到结论的方法,而评判方法的有效性根本上也是依赖于结果的好坏。因此,就测评而言,难以非常清晰地划分推理能力的测评与自然语言推论(NLI)能力。前文从自然语言理解的角度出发,分析大语言模型自然语言推论的性能,本文也不纠结于细节的区分和概念的重叠,从推理的角度,梳理一下大语言模型的能力。
大语言模型的推理能力
算术推理(Arithmetic Reasoning)

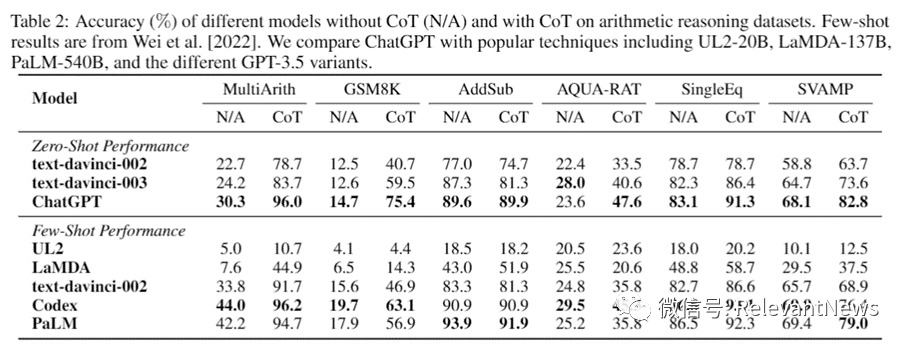
【能力描述】 多步骤推理的基本数学问题进行问答 【测试数据集举例】 MultiArith:600道算术应用题。 GSM8K:8.5K 个高质量小学数学应用题的数据集。。 AQuA: 包含问题、答案和基本原理的 100,000 个样本的代数问答数据集。 AddSub, SingleEq和SVAMP等数据集 【测试实例】 Q: George had 28 socks. If he threw away 4 old ones that didn’t fit and bought 36 new ones, how many socks would he have? A: The answer (arabic numerals) is 60. George would have 60 socks. (28 + 36 = 60) Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. 【相关模型】 ChatGPT 【评估结果】
论文截图:在7个加减乘除运算应用题数据 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









