






扫码关注文末“智核工场”公众号,获取更多硬核知识
0 引言
智能驾驶技术飞速发展,数据成为驱动自动驾驶技术进步的关键要素。如何构建高效的数据闭环以优化智驾系统的开发和测试,已成为各大车企关注的重点。
都说数据是核心资产,但是与很多车企的负责人沟通下来,发现尽管他们手头有很多数据,却很难用起来,无法形成真正的闭环,或者闭环运作的效率非常低下。其原因有多方面:

数据闭环的痛点
除了上述痛点外,多数车企没有AI开发团队,不需要利用数据来训练模型;另一方面没有对数据进行有效的治理,无法利用历史数据来服务测试验证。
本文将基于数据闭环体系,聊聊车企如何利用数据来服务于开发和测试。
1 数据闭环概述
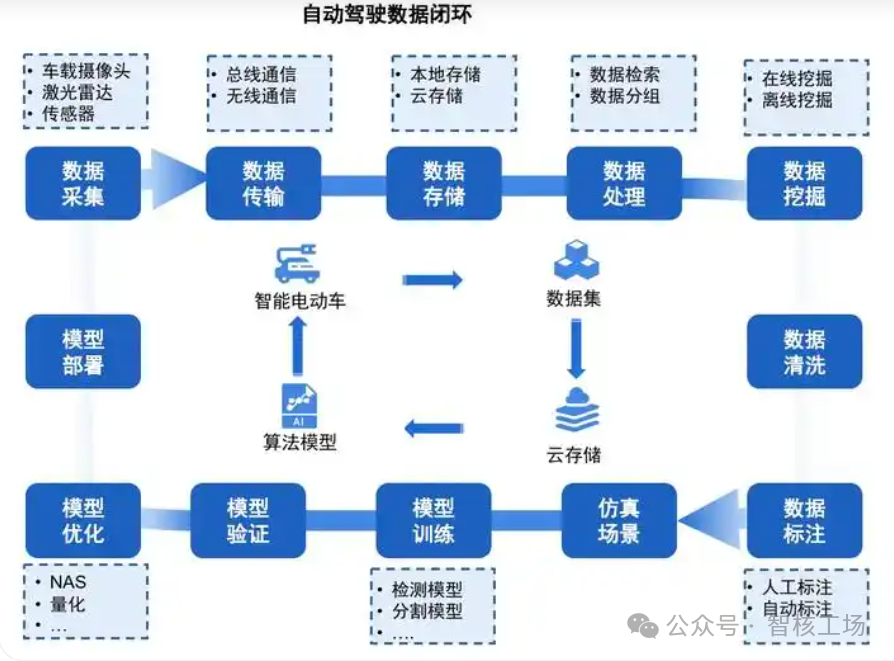
数据闭环(Data Loop)是指通过数据的采集、存储、处理、分析、反馈和优化,使得智能驾驶系统能够不断自我完善的过程。对于车企来说,数据闭环的核心价值在于提高智驾系统的安全性、稳定性和智能化水平。
数据闭环的主要组成部分包括:
-
数据采集:通过车载传感器(如摄像头、雷达、激光雷达等)和ECU(电子控制单元)收集车辆运行数据。
-
数据传输:利用5G/车联网等通信技术,将采集的数据传输到云端或本地数据中心。
-
数据存储与管理:建立高效的分布式数据存储系统,支持PB级别数据存储和场景管理。
-
数据标注:对感知的目标、障碍物、交通标识等进行标注。
-
数据应用:AI模型训练、仿真与回灌测试。
-
数据反馈与优化:基于测试分析结果,对自动驾驶算法进行迭代优化,并重新部署至车辆。
2
数据闭环需要什么资源
做数据闭环可以类比为做一道大菜,云端资源是主要阵地,可以类比为做菜的厨房和锅碗瓢盆。其它关键的要素就是“食材”(数据采集源),“厨师”(工程师)和“菜谱”(软件)。
3 数据云端资源
数据闭环大量的工作都是在云端进行的。这主要依赖云端海量的计算和存储资源。在过去几年,一线车企有的自建,有的与BAT、华为、火山引擎合作建立了计算中心。特斯拉有自己的智算中心Dojo,吉利拥有星睿智算中心,小鹏拥有扶摇智算中心。数据闭环的基础设施资源应该绝大部分是基本满足要求了。
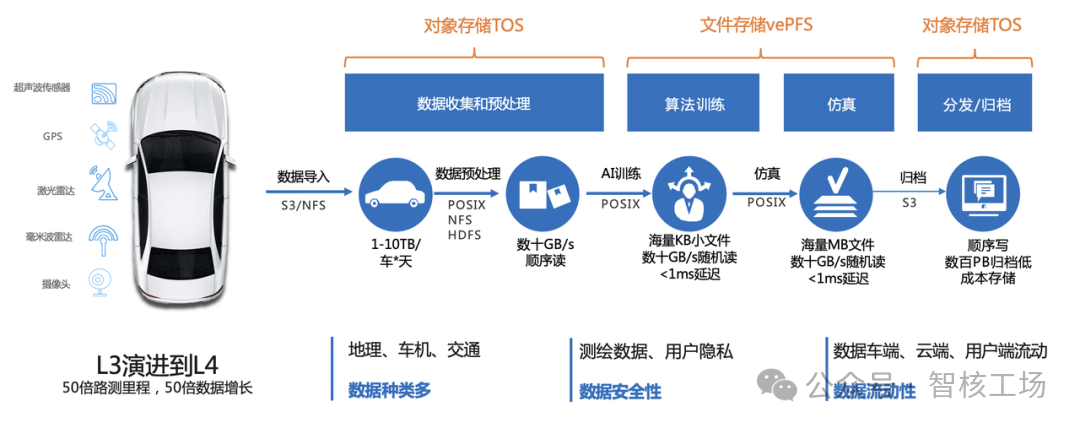

火山引擎智驾数据闭环方案
4 数据采集

智能驾驶采集车
“食材”(数据源)应该是整个数据闭环最为关键的要素之一。以什么样的平台(采集车辆)采集什么样的数据,决定了后续数据闭环的有效性和成本。
在过去,大多数智能驾驶企业都有独立的数据采集车辆。这类车辆一般配备了高线束的激光雷达(64线或128线)、全方位摄像头、毫米波雷达、高性能GNSS等传感器。同时车辆上安装了采集工控机和容量较大的硬盘。数据采集车不会激活智能驾驶功能(或不具备智能驾驶功能)。这类采集车搭建成本较高(近100万/台),运营和维护成本也很高。获取的数据主要用于后续的模型训练。
我们知道,采集的数据的全面性(或覆盖率)决定了AI模型的性能。但是,要采集完不同天气、不同道路下的动态交通场景,是一个巨大的工程。光依赖某一个企业去完成,是不现实的。所以有第三方机构(如中期数据、智能汽车创新发展平台等)会联合车企共建、共享数据平台。这种模式,理论上是可以为企业节省大量成本,但是挑战也是很大。例如,如何解决数据的兼容性、复用性等问题,将直接影响这种共建共享模式的可执行性。
特斯拉在数据获取上,采用了非常聪明的一种模式:“采测一体化模式”。这是值得所有车企学习的一种模式。特斯拉没有独立的数据采集车,而是直接用了量产车辆固有的传感器和域控,将感兴趣的场景回流到云端。这种模式简便、高效,且成本低廉。但是在法规、用户隐私等方面一定要想办法适配中国国情,在车端做更多的技术处理(后续智核工场将单独分享一期内容,敬请关注)。不过,对于品牌多、产品矩阵大的车企来说,这种模式在成本上也是非常大的。
5 数据基础设施团队
数据采集完成后,接下来就需要剔除无效数据,做好数据清洗、切片工作。就像从田野里采集完食材后,需要剔除腐烂不可食用的部分,并做好清洗、切片工作。这些工作依赖一高高质量的“厨师队伍”——数据工程师,很多企业都称之为基础设施工程师。
不得不承认,互联网造车的企业在这方面有天生的基因,所以在数据基础设施建设上布局很早,且团队规模和整体素质都很高。而传统汽车大多后知后觉,对数据工程团队的建设与投入较少。这一点,传统汽车需要尽快把遗漏的作业补齐。
数据基础设施团队要做的工作很多,除了数据清洗、切片外,还要把完整的数据闭环工具链开发、部署好。几乎所有的智驾工程研发人员(系统、软件、硬件、测试),都依赖于这套工具链。因此,数据闭环工具链的好坏,决定了最终开发的交付物的质量、效率和成本。
现实的情况是比较糟糕的。很多工作在工具链上脱节严重,比如数据标注横跨多个系统,有Camera标注的工具,有点云标注的工具,标注的最终质检又分自动化系统和人工校核系统。数据的分类、流转和可视化也存在诸多障碍。例如,某些公司的数据可视化,需要将数据下载后本地才能播放。光下载时间就得耗费20分钟以上,这还是网络情况最佳的状态。
总而言之,做好数据闭环的工具链,需要有非常专业的团队来执行,且需要自顶向下做好架构设计。拆东墙、补西墙的事,越少越好。另外,一定要多听听用户的声音,快速调整工具链的短板。
6 数据闭环工具链
前面章节提到了数据闭环的流程。流程中每一个关键节点,都离不开工具的使用。如果每一个工具都要依赖“自研”,其效率一定是低下、且成本极高的。如果是Google、特斯拉或华为这类超级企业另当别论,其余企业采用第三方方案肯定是最优解。
既然用了第三方工具,那还需要基础设置团队干嘛?
其实这个问题很容易回答:工具链的整合。
如果去看看阿里、百度、火山引擎的智驾数据闭环方案,我们会发现这类大公司也并不是提供完整的数据闭环工具链,他们也集成了第三方的一些应用工具,自身聚焦于数据平台底座(计算与存储)的建设。例如数据采集、仿真测试等,都是和第三方合作完成(百度除外)。而企业内部的基础设置团队,要做的就是做好数据平台上的应用工具链整合,少部分工具可以依据企业实际需求做自研。
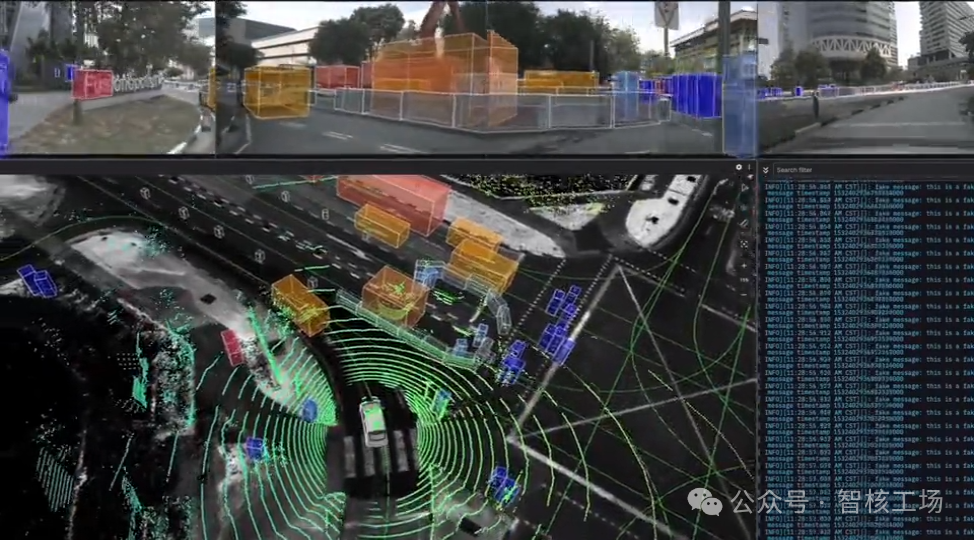
数据可视化工具
7 数据的应用
数据闭环服务于多个智驾工程开发环节。首要的任务还是服务于AI模型的训练。高质量、高数量的数据可以给AI模型带来非常不错的性能提升。正如马斯克所说:“100 万个视频训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 “嚯!”;到了 1000 万个,就变得难以置信了。”

另一个应用是场景数据分析。毕竟不是所有车企都有自己的AI模型开发团队。这些数据用于问题的分析就显得非常宝贵。比如路采团队发现了一个缺陷,不清楚具体的Root Cause。那么系统工程师、软件工程师、硬件工程师就可以基于回流的数据进行分析判断,以定位并解决缺陷。当然,这里有一个前提,这些数据并不是“采集专属车”获取的数据,而是带有智驾功能车辆采集的数据。
另一个重要应用是测试验证。数据服务于测试也是数据闭环必不可少的内容。回灌和仿真都是非常好的测试方式。回灌是一种开环测试方式,需要依赖标注后的真值,来评估新版本软件感知识别的性能。仿真是一种闭环测试方式,不需要利用真值,主要用来评估软件的规控或者利用高置信度仿真器来评估端到端系统。

8 总结
以上是对智能驾驶“数据闭环”粗浅的一些介绍,希望能带给阅读者一些启发。如果要构建强大的数据闭环体系,可以参加“智核工场”组织的数据闭环研学活动。


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











