







分类算法有两种类型:感知器和适应性线性神经元
神经元的数学表示
w
=
[
w
1
w
2
.
.
.
w
m
]
,
x
=
[
x
1
x
2
.
.
.
x
m
]
w=\begin{bmatrix} w_1 \\ w_2 \\ ... \\ w_m \\ \end{bmatrix} , x=\begin{bmatrix} x_1 \\ x_2 \\ ... \\ x_m\\ \end{bmatrix}
w=⎣⎢⎢⎡w1w2...wm⎦⎥⎥⎤,x=⎣⎢⎢⎡x1x2...xm⎦⎥⎥⎤
z
=
w
1
x
1
+
w
2
x
2
+
⋅
⋅
⋅
+
w
m
x
m
z=w_1x_1 + w_2x_2 + ···+w_mx_m
z=w1x1+w2x2+⋅⋅⋅+wmxm
其中w为权重,x为训练样本
感知机的训练步骤
- 把权重向量初始化为0,或把每个分向量初始化为[0,1]间任意小数
- 把训练样本输入感知机,得到分类结果(-1或1)
- 根据分类结果更新权重向量
激活函数
为了计算方便我们添加
w
0
x
0
w_0x_0
w0x0, 其中
w
0
=
−
θ
,
x
0
=
1
w_0=-\theta,x_0=1
w0=−θ,x0=1 则
z
=
w
0
x
0
+
w
1
x
1
+
.
.
.
+
w
m
x
m
=
w
T
x
,
ϕ
(
z
)
=
{
1
if z>0
−
1
,
otherwise
z=w_0x_0 + w_1x_1+...+w_mx_m = w^Tx , \phi(z)=\begin{cases} 1 & \text {if z>0} \\ -1, & \text{otherwise} \end{cases}
z=w0x0+w1x1+...+wmxm=wTx,ϕ(z)={1−1,if z>0otherwise
这样,当
z
>
0
z>0
z>0时,
ϕ
(
z
)
=
1
\phi(z)=1
ϕ(z)=1,当
z
<
0
z<0
z<0时,
ϕ
(
z
)
=
−
1
\phi(z)=-1
ϕ(z)=−1.
权重的更新算法
- w ( j ) = w ( j ) + Δ w ( j ) w(j)=w(j)+\Delta w(j) w(j)=w(j)+Δw(j)
- Δ w ( j ) = η ∗ ( y − y ′ ) ∗ x ( j ) \Delta w(j)=\eta*(y-y')*x(j) Δw(j)=η∗(y−y′)∗x(j) : y表示x(j)的正确分类,y’表示感知机算出来的分类,x(j)表示训练样本。可以看出来如果感知器的分类结果 y ′ y' y′与正确分类 y y y相同时,那么可以得到 Δ w ( j ) = 0 \Delta w(j)=0 Δw(j)=0,也就可以得到 w ( j ) = 0 w(j)=0 w(j)=0,也就是说如果感知器可以正确对数据样本进行正确分类,那么对权重 w ( j ) w(j) w(j)就不需要进行调整;只有感知器得到了错误的分类结果之后,出需要调整权重向量 w ( j ) w(j) w(j)。
- η \eta η 表示学习率是[0,1]之间的一个小数,一般有使用者自己设置。通过反复运行模型,人为根据经验调整学习率 η \eta η,使得模型训练结果越来越好。
- w ( 0 ) = 0 , Δ w ( 0 ) = η ∗ ( y − y ′ ) w(0)=0, \Delta w(0)=\eta*(y-y') w(0)=0,Δw(0)=η∗(y−y′)阈值的更新
举例说明如何更新权重
假设
- 权重向量初始化为: w = [ 0 , 0 , 0 ] w=[0,0, 0] w=[0,0,0]
- 训练样本的值: x = [ 1 , 2 , 3 ] x=[1,2,3] x=[1,2,3]
- 学习率: η = 0.3 \eta=0.3 η=0.3
- 这个样本的正确分类y=1
- 感知器算出来的分类是y’=-1
调整权重向量 Δ w ( 0 ) = 0.3 ∗ ( 1 − ( − 1 ) ) ∗ x ( 0 ) = 0.3 ∗ 2 ∗ 1 = 0.6 \Delta w(0)=0.3*(1-(-1))*x(0)=0.3*2*1=0.6 Δw(0)=0.3∗(1−(−1))∗x(0)=0.3∗2∗1=0.6, w ( 0 ) = w ( 0 ) + Δ w ( 0 ) = 0.6 w(0) = w(0)+\Delta w(0)=0.6 w(0)=w(0)+Δw(0)=0.6,则权重的第一个分量更新为0.6,即 w = [ 0.6 , 0 , 0 ] w=[0.6,0,0] w=[0.6,0,0]
同理, Δ w ( 1 ) = 0.3 ∗ ( 1 − ( − 1 ) ) ∗ x ( 1 ) = 0.3 ∗ 2 ∗ 2 = 1.2 \Delta w(1)=0.3*(1-(-1))*x(1)=0.3*2*2=1.2 Δw(1)=0.3∗(1−(−1))∗x(1)=0.3∗2∗2=1.2,则更新权重的第二个分量为 w ( 1 ) = w ( 1 ) + Δ w ( 1 ) = 1.2 w(1)=w(1)+\Delta w(1)=1.2 w(1)=w(1)+Δw(1)=1.2
同理, Δ w ( 2 ) = 0.3 ∗ ( 1 − ( − 1 ) ∗ x ( 2 ) ) = 0.3 ∗ 2 ∗ 3 = 1.8 \Delta w(2)=0.3*(1-(-1)*x(2))=0.3*2*3=1.8 Δw(2)=0.3∗(1−(−1)∗x(2))=0.3∗2∗3=1.8,则更新权重的第三个分量为 w ( 2 ) = w ( 2 ) + Δ w ( 2 ) = 1.8 w(2)=w(2)+\Delta w(2)=1.8 w(2)=w(2)+Δw(2)=1.8
最终可以得到更新后的权重向量为 w = [ 0.6 , 1.2 , 1.8 ] w=[0.6, 1.2, 1.8] w=[0.6,1.2,1.8]
这样就可以再次将新的训练样本输入到模型中,根据分类结果走相同的步骤继续改进权重向量。
感知器算法的适用范围
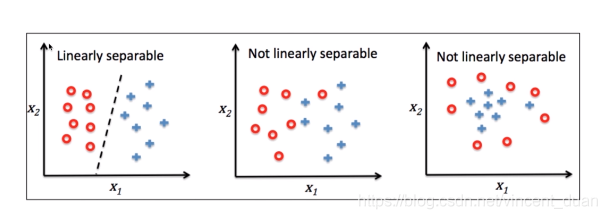
必须要满足上图中第一个图中的情况,也就是预测的数据可以现行分割,感知器的训练目标就是要找出这条线。而后面两个情况,是无法进行线性可分的,不适用于感知器算法进行分类。
代码实现
定义感知器类
import numpy as np
class Perceptron(object):
"""
eta: 学习率
n_iter: 权重向量的训练次数
w_: 神经分叉权重向量
errors_: 用于记录神经元判断出错次数
"""
def __init__(self, eta = 0.01, n_iter = 10):
self.eta = eta
self.n_iter = n_iter
pass
def fit(self, X, y):
"""
输入训练数据,培训神经元,X表示输入样本, y对应样本的正确分类
X: shape[n_samples, n_features]
n_samples:表示有多少个训练样本数量
n_features: 表示有多少个属性
例如:X: [[1,2,3], [4,5,6]] => n_samples=2;n_features=3
y: [1, -1]表示第一个向量的分类是1, 第二个向量的分类是-1
"""
"""
首先初始化权重为0
加一是因为激活函数w0,也就是阈值,这样就只用判断输出结果是否大于0就可以了
"""
self.w_ = np.zero(1 + X.shape[1])
self.errors_ = []
"""
只要出现错误分类,那么反复训练这个样本,次数是n_iter
"""
for _ in range(self.n_iter):
errors = 0
"""
X:[[1,2,3], [4,5,6]]
y:[1, -1]
zip(X, y) => [[1,2,3,1], [4,5,6-1]]
"""
for xi, target in zip(X,y):
"""
update = η * (y-y')
"""
update = self.eta * (target - self.predict(xi))
"""
xi 是一个向量, 例如[1,2,3], target表示1
update 是一个常量
update*xi 等价于 [Δw(1) = X[1]*update, Δw(2) = X[2]*update, Δw(3) = X[3]*update]
"""
# w_[1:]表示w忽略第0个元素,从第一个元素开始往后
self.w_[1:] += update * xi
self.w_[0] += update * 1
errors += int(update != 0.0)
self.errors_.append(errors)
pass
pass
def net_input(self, X):
"""
z = W0*1 + W1*X1 + W2*X2+ ...+ Wn*Xn
"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""
如果self.net_input(X) >= 0.0返回1, 否则返回-1
"""
return np.where(self.net_input(X) >= 0.0 , 1, -1)
目前虽然有了感知器的分类算法,但是还没有运行起来,下面将如何使用这个感知器分类算法,然后将训练样本输入到模型中,最后进行预测数据。
介绍训练数据
有了基本模型后,要做的就是要把大量的数据,输入至模型中,让模型通过对大量数据的观察,总结出数据中隐含的某种规律,根据数据特点不断调节模型中神经元权重数值,当神经元的权重数值调节到合适的范围之内后,就可以利用训练后的模型对新的数据进行预测分类。
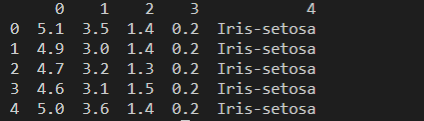
首先需要先介绍训练数据的数据结构。训练数据内容如下:

使用pandas工具,来读取数据,可以很容易的进行抽取数据。
首先安装pandas:pip install pandas -i https://pypi.douban.com/simple
import pandas as pd
file="./iris.csv"
df = pd.read_csv(file, header=None)
print(df.head())
结果输出如下:
可视化展示这个数据,使用matplotlib工具进行展示。
import matplotlib.pyplot as plt
import numpy as np
from test3 import df
# 将df中0到100行的数据的第四列赋值给y向量
y = df.loc[0:100, 4].values
# 将Iris-setosa转为-1,其余转为1
y = np.where(y == 'Iris-setosa', -1, 1)
# print(y)
# 将df0到100行的数据的第0列和第2列抽取出来,赋值给x向量
X = df.iloc[0:100, [0, 2]].values
# print(X)
# 将X向量的钱50条数据的第0列作为x轴,第1列作为y轴坐标,画在二维坐标轴,画出来的点是红色的'o',
plt.scatter(X[:50, 0], X[:50, 1], color = 'red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color = 'blue', marker='x', label='versicolor')
plt.xlabel('花瓣长度')
plt.ylabel('花径长度')
plt.legend(loc='upper left')
# 下面两行解决乱码问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False
plt.show()

可以看出来这两类数据可以线性分割开。
一步一步调试
初始化eta=0.1, w=[0 0 0]
5.1,1.4,target=-1, self.net_input(x)=W0*1+W1*5.1+W2*1.4=0,self.predict(xi)=1,update=eta*(target-self.predict(xi))=0.1*(-2)=-0.2,errors=1,W=[1*(-0.2)5.1*(-0.2)1.4*(-0.2)]=[-0.2 -1.02 -0.28]
4.9,1.4,target=-1, self.net_input(x)=W0*1+W1*4.9+W2*1.4=-0.2*1+(-1.02)*4.9+(-0.28)*1.4=-0.3918432<0,self.predict(xi)=-1,update=eta*(target-self.predict(xi))=0.1*0=0,errors=1,W=[-0.2+1*0-1.02+4.9*0-0.28+1.4*0]=[-0.2 -1.02 -0.28]
4.7,1.3,target=-1, self.net_input(x)=W0*1+W1*4.7+W2*1.3=-0.2+(-4.794)+(-0.364)<0,self.predict(xi)=-1,update=0,errors=1,W=[-0.2 -1.02 -0.28]
5.4,1.7,target=-1,self.net_input(x)<0,self.predict(xi)=-1,update=0,errors=1,W=[-0.2 -1.02 -0.28]
7,4.7,target=1,self.net_input(x)<0,self.predict(xi)=-1,update=0.2,errors=2,W=[(-0.2)+(0.2*1) (-1.02)+(0.2*7) (-0.28)+(0.2*4.7)]=[0 0.38 0.66]
- 首先得到样本数据和分类标签target
- 然后计算预测标签的值predict
- 更新权重W=eta*(target-predict), 将上一次的权重W进行累加w(j)+Δw(j)
- 以此类推















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









