







前言
上一篇文章着重介绍了数据集相关的内容:数据集的结构、数据集的位置、数据集中的内容被读入计算机的三个阶段以及最后的关于数据集中的数据格式尺寸标准等信息。具体解析请看我的上一篇文章,链接如下:
从数据读取的角度解读YOLOV5源码:如何使用YOLO V5训练自己的数据集?_vindicater的博客-CSDN博客
上一篇的内容从整个模型的角度来说属于准备工作:读入数据,预处理这些信息等等,那么从本文开始,我们就正式进入YOLO V5的模型本身。本文主要介绍的是forward部分,也就是整个模型推理的部分。通过对于整个网络的具体实现的解析,理解了的读者便能具备修改网络结构的能力。
问题一、网络的呈现形式?(yaml文件&common.py的介绍)
1.准备内容:common.py
由于common.py本身就是一个用来引用的仓库,代码本身难度不大,这里仅做列举:
1.Autopad():利用kernel-size自动计算应该补上多少的padding
2.Conv类:有别于conv2d,这里的conv是conv2d,bn,silu三个函数的叠加
(1):Dwconv类继承conv类为程序的基础
3.Bottleneck类:最基础的采用了残差模块的类,forward函数给出了计算结果
4&5.BottleneckCSP&C3类:

原作者对于这两个模块的对比描述
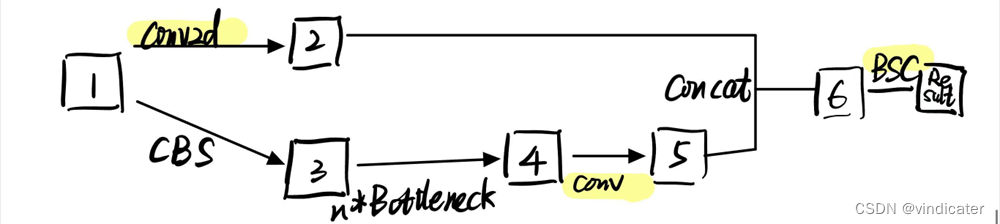
BottleneckCSP
BottleneckCSP对于图片做了两个1*1的卷积操作而没有通过非线性操作,这样导致实际上得到的信息是完完全全保留了原先的图片的特征,而并没有提取到深层的信息,有些浪费计算量。
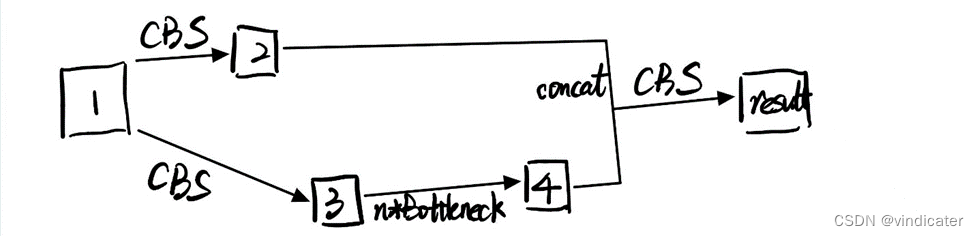
C3
C3模块如同他的名字一样一共只有三个卷积模块,但是好在每一次卷积操作之后都用了非线性层激活。而且BN层和SILU这个激活层的计算量相比而言都很小。如此看来确实称得上是faster and lighter.
6&7.SPP类&Focus类:SPP在之前的文章中已经提到过这里就不加赘述了,若想要学习可以看之前的文章
为YOLO V5铺垫:一文看懂YOLO V1-V4的变化_vindicater的博客-CSDN博客
Focus类实际上就是Passthrough部分,在上面也提到了。
8&9.contract&expand类:目的是在不改变矩阵信息总量的情况之下增加或减少channel数

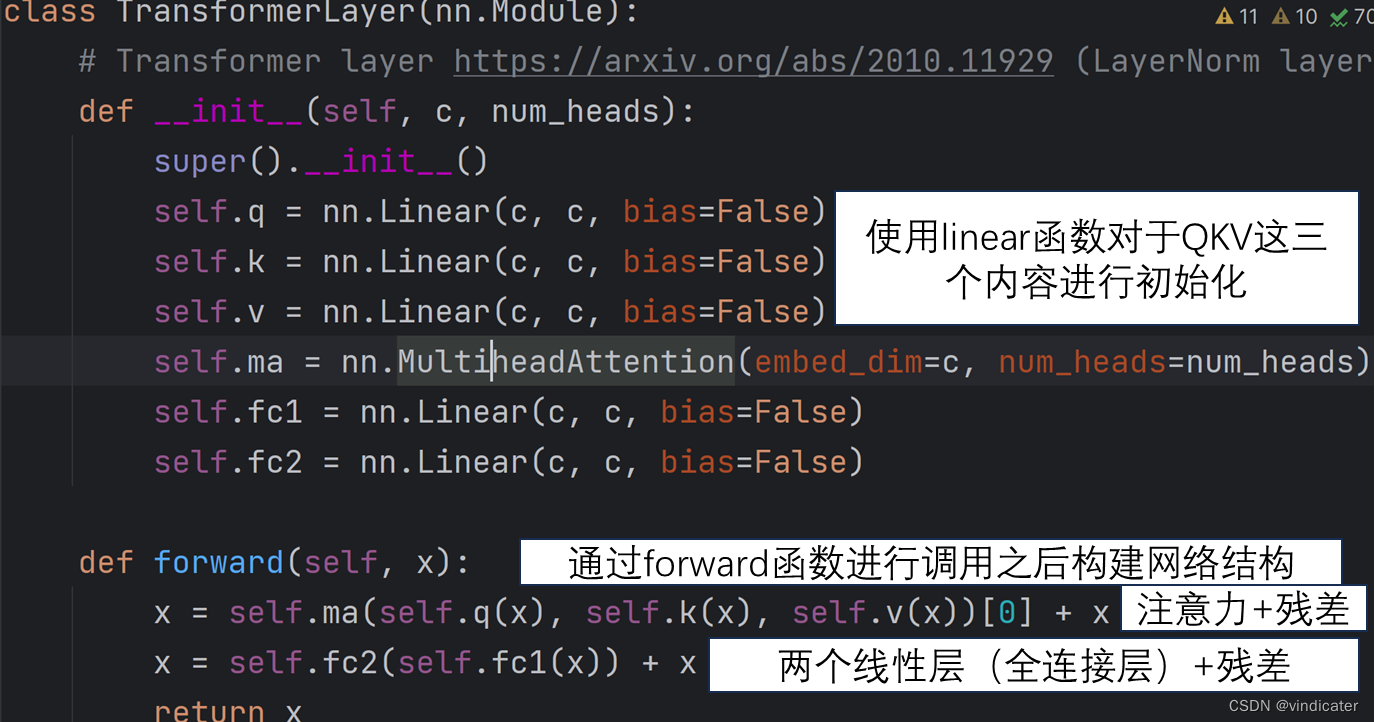
10.Transformers类:注意力机制
关于这一块的内容其实是从NLP领域搬过来的机制,注意力机制,自注意机制等等内容展开都足够单独写一篇文章了这里就不展开了。若想要了解,在我的另一个NLP专栏中会详细介绍。
以上是common.py中的准备内容。事实上,在YOLO V5的网络结构中只使用了寥寥几种上述结构,其余的是给读者用来改进和创新使用的。
2.网络结构的直接载体:yolov5s.yaml
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32Part 1:参数内容
nc:number of classes:物体种类
depth_multiple :影响网络深度的参数。

比如在yolov5s中的backbone的某一层网络,记录的层数是3,但是事实上计算机执行的是1,是记录的层数*depth_multiple,在这个语境下也就是3*0.33=1
存在的意义是什么?
对于网络结构,似乎卷积层之间是存在着一个比例关系的,比如从后续的代码中就可以看出对于yolov5s来说通过直接调整depth_multiple 这个参数,就可以做到不改变基本结构的情况下增加网络深度。
width_multiple:影响输入输出通道数的参数
后续网络中所有关于通道数的数据都要乘上这个比例参数得到最终的通道数的数据。
anchors:事先指定的三种尺寸下的Anchor框的大小
Part 2:网络结构信息
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)YOLO V5s的结构
参数1:from
from给出的是参数来源相关的信息。其中的-1指的是从上一层前来,其余正数就意味着具体从哪一层输入。如果是数组形式,那么就意味着来源是某几层。比如其中的concat是拼接的操作,一定需要多个层的结果拼接,相应其输入内容应该来源于多层。
参数2:number
number给出的是网络的深度。正如前面讲参数所说的一样,实际深度是这里记录的深度乘上前面的参数。
参数3&4:module&args
类别1:直接在nn.module 中包含的计算方式
例子:上图中的nn.Upsample 等。由于其在python的某些包中有可以直接调用的函数,这里通过这个方式书写,计算机可以直接读取调用,参数提供在后面。
类别2:自己定义的计算方式
比如上文中定义的Conv,3C等等。
这里采用的自定义的计算方式必须在Common.py中有详细的展开方式,同时名称必须一样,以此,机器凭借名字到common.py中寻找对应函数并且执行相应内容。
问题2:如何修改网络结构?(具体修改措施)
基于上述的第一个问题介绍,主要要做几点修改
1.如果想改变网络深度和数量
对应的修改depth_multitude 或者直接在backbone中的number处修改。
2.如果想增加一些新的处理层
1.如果common.py中存在这个模块,直接修改yaml文件中的网络结构即可
2.如果common.py或者nn.module 等都没有相关内容,则需要再common.py中创造再在yaml文件之中添加
问题三、以上的网络结构具体读入模型的流程?(代码解析)
调用代码:
pred = model(imgs) 进入yolo.py文件中进行模型推演
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize)可以从上述代码中看出实际上模型是一步一步读取内容的。下面进入forward_once函数分析
forward_once函数分析
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x1.用for循环遍历yolov5s.yaml文件中的所有步骤
2.取出一个步骤之后判断这个步骤是否需要从别的层中取出元素(对应的就是m.i是否为-1)
3.对于m中每一个步骤都对应到common.py的某一个类的forward函数完成运算,参数就是前面第二步所取出的值
4.对于这一层的结果如果还需要使用就保存到y中,如果不需要就在y中置为none
5.把经历过整个模型操作的结果x返回,这个时候的x就是上面的pred,也就是经历过推理之后的预测结果。
总结
实际上ultralytics在开源这个项目之后做了很多为后来者铺路的事情(我真的哭死)。这些方便的调用确实能方便很多熟练的学者,但是在没有思路的情况下理解这么大一个程序就变得相当困难,很有可能和笔者的经历一样研究了很久发现看懂的是一个仓库。希望本文的内容能切实的帮助到初学者。















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









