







相关数学概念
协方差矩阵

多维高斯分布

其中k=n,即x的维度。
GMM的原理
GMM,高斯混合模型,是一种聚类算法。
1.GMM概念:
-将k个高斯模型混合在一起,每个点出现的概率是几个高斯混合的结果。


-每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数。假设有K个高斯分布,每个高斯对data points的影响因子为πk,数据点为x,高斯参数为theta,则

-要估计的模型参数为每个类的影响因子πk,每个类的均值(μk)及协方差矩阵(Σk)。
如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。
那么如何用 GMM 来做 clustering 呢?其实很简单,现在我们有了数据,假定它们是由 GMM 生成出来的,那么我们只要根据数据推出 GMM 的概率分布来就可以了,然后 GMM 的 K 个 Component 实际上就对应了 K 个 cluster 了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。
2. GMM的似然函数:
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x) ),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于 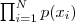 ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和
,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和 ![]() ,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
log-likelihood function:
假设N个点的分布符合i.i.d,则有似然函数

问题是,对于这样的一个似然函数,用gradient descent的方法很难进行参数估计(可证明)
所以用EM(expectation maximization)算法进行估计:

引入中间latent项z(i),其分布为Q,用EM算法,就有上面的恒等,那么为什么是恒等呢?来看看讲EM的这篇文章,第三张的开头写的, =constant,也就是说与z(i)无关了,而等于p(x(i);theta),这也就是说可以用混合高斯模型的概率表示了。
=constant,也就是说与z(i)无关了,而等于p(x(i);theta),这也就是说可以用混合高斯模型的概率表示了。
3. EM具体应用到GMM参数求解问题:
E-step: 根据已有observed data和现有模型估计missing data:Qi(zk)
M-step: 已经得到了Q,在M-step中进行最大似然函数估计(可以直接用log-likelihood似然函数对参数求偏导)
在 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut一文中我们给出了GMM算法的基本模型与似然函数,在EM算法原理中对EM算法的实现与收敛性证明进行了详细说明。本文主要针对如何用EM算法在混合高斯模型下进行聚类进行代码上的分析说明。
1. GMM模型:
每个 GMM 由 K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
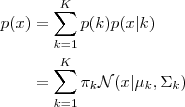
根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。
那么如何用 GMM 来做 clustering 呢?其实很简单,现在我们有了数据,假定它们是由 GMM 生成出来的,那么我们只要根据数据推出 GMM 的概率分布来就可以了,然后 GMM 的 K 个 Component 实际上就对应了 K 个 cluster 了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。
2. 参数与似然函数:
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x) ),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于 ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和 ![]() ,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
,得到 log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
下面让我们来看一看 GMM 的 log-likelihood function :
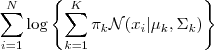
由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,我们采取之前从 GMM 中随机选点的办法:分成两步,实际上也就类似于K-means 的两步。
3. 算法流程:
1. 估计数据由每个 Component 生成的概率(并不是每个 Component 被选中的概率):对于每个数据  来说,它由第
来说,它由第  个 Component 生成的概率为
个 Component 生成的概率为
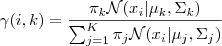
其中N(xi | μk,Σk)就是后验概率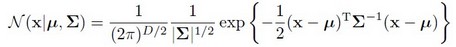 。
。
2. 通过极大似然估计可以通过求到令参数=0得到参数pMiu,pSigma的值。具体请见这篇文章第三部分。
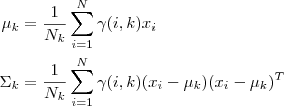
其中 ") ,并且
,并且  也顺理成章地可以估计为
也顺理成章地可以估计为  。
。
3. 重复迭代前面两步,直到似然函数的值收敛为止。
matlab实现
function varargout = newgmm(X, K_or_centroids)
% ============================================================
% Expectation-Maximization iteration implementation of
% Gaussian Mixture Model.
%
% PX = GMM(X, K_OR_CENTROIDS)
% [PX MODEL] = GMM(X, K_OR_CENTROIDS)
%
% - X: N-by-D data matrix.----------NxD的矩阵
% - K_OR_CENTROIDS: either K indicating the number of--------单个数字K/[K] 或者 KxD矩阵的聚类
% components or a K-by-D matrix indicating the
% choosing of the initial K centroids.
%
% - PX: N-by-K matrix indicating the probability of each--------NxK矩阵,第N个数据点占第K个单一高斯概率密度
% component generating each point.
% - MODEL: a structure containing the parameters for a GMM:
% MODEL.Miu: a K-by-D matrix.-------------KxD矩阵,初始化聚类样本,后面循环为每个数据点概率归一化后再聚类概率归一化后的均值矩阵
% MODEL.Sigma: a D-by-D-by-K matrix.------DxDxK矩阵,初始化数据点对于聚类的方差[聚类等概率],后面循环为均值矩阵改变以后的方差
% MODEL.Pi: a 1-by-K vector.-----------1xK矩阵,初始化数据点使用聚类的概率分布,后面循环高斯混合概率系数归一化的分母Nk/N,高斯混合加权系数向量
% ============================================================
% @SourceCode Author: Pluskid (http://blog.pluskid.org)
% @Appended by : Sophia_qing (http://blog.csdn.net/abcjennifer)
%% Generate Initial Centroids
threshold = 1e-15;%阈值
[N, D] = size(X);%矩阵X的行N,列D
if isscalar(K_or_centroids)%判断值是否为1x1矩阵即单个数字
K = K_or_centroids;%取[k]的k
% randomly pick centroids
rndp = randperm(N);%返回一行由1到N个的整数无序排列的向量
centroids = X(rndp(1:K), :);%取出X矩阵行打乱后的矩阵的前K行
else
K = size(K_or_centroids, 1);%取矩阵K_or_centroids的行数
centroids = K_or_centroids;%取矩阵K_or_centroids矩阵
end
% initial values
[pMiu pPi pSigma] = init_params();
%初始化 嵌套函数后面可见。KxD矩阵pMiu聚类采样点,1*K向量pPi使用同一个聚类采样点出现概率,D*D*K的矩阵pSigma矩阵X的列项j对于聚类采样点的协方差
Lprev = -inf; %inf表示正无究大,-inf表示为负无究大
while true
Px = calc_prob();%NxK矩阵Px存放聚类点k(共有聚类点K个)对于全部数据点的正态分布生成样本的概率密度
% new value for pGamma
pGamma = Px .* repmat(pPi, N, 1);%NxK矩阵pGamma在使用聚类采样点k的条件下某个数据点n生成样本概率密度(条件概率密度)
pGamma = pGamma ./ repmat(sum(pGamma, 2), 1, K); %NxK矩阵pGamma对于使用数据点条件概率密度行向归一化。
%求每个样本由第K个聚类,也叫“component“生成的概率)
% new value for parameters of each Component
Nk = sum(pGamma, 1);%1xK矩阵Nk第k个聚类点被数据点使用的概率总和
pMiu = diag(1./Nk) * pGamma' * X;
%KxD矩阵 重新计算每个component的均值 维数变化KxK*KxN*NxD=KxD 数据点进行 聚类概率归一化.条件概率密度.数据点=得到均值(期望)
%均值=Σ概率Pi*数据点某一属性Xi;而这里还多了个聚类概率Nk
pPi = Nk/N; %更新混合高斯的加权系数
for kk = 1:K %重新计算每个component的协方差矩阵
Xshift = X-repmat(pMiu(kk, :), N, 1);%NxD矩阵Xshift在某一个聚类点的情况下,每个属性在这个聚类下的对均值(期望)差数(X-μi)
pSigma(:, :, kk) = (Xshift' * ...
(diag(pGamma(:, kk)) * Xshift)) / Nk(kk);%DxD矩阵pSigma(::,i) 概率Pi 聚类概率=1/Nk(i)
%第i个方差矩阵= Σ(X-μi)转置*概率Pi*(X-μi)*第i个聚类概率
end
% check for convergence
L = sum(log(Px*pPi')); %求混合高斯分布的似然函数
if L-Lprev < threshold %随着迭代次数的增加,似然函数越来越大,直至不变
break; %似然函数收敛则退出
end
Lprev = L;
end
if nargout == 1 %如果返回是一个参数的话,那么varargout=Px;
varargout = {Px};
else %否则,返回[Px model],其中model是结构体
model = [];
model.Miu = pMiu;
model.Sigma = pSigma;
model.Pi = pPi;
varargout = {Px, model};
end
function [pMiu pPi pSigma] = init_params()
pMiu = centroids;%得X矩阵中的任意K行,KxD矩阵 聚类点
pPi = zeros(1, K);%获取K维零向量[0 0 ...0] 加权系数(每行数据与聚类中点最小距离的概率)
pSigma = zeros(D, D, K);%获取K个DxD的零矩阵
%distmat为D维距离差平方和
% hard assign x to each centroids %X有NxD;sum(X.*X, 2)为Nx1; repmat(sum(X.*X, 2), 1, K)行向整体1倍,列向整体K倍;结果NxK
distmat = repmat(sum(X.*X, 2), 1, K) + ... %distmat第j行的第i个元素表示第j个数据与第i个聚类点的距离,如果数据有4个,聚类2个,那么distmat就是4*2矩阵
repmat(sum(pMiu.*pMiu, 2)', N, 1) - 2*X*pMiu'; %sum(A,2)结果为每行求和列向量,第i个元素是第i行的求和;
[dummy labels] = min(distmat, [], 2); %返回列向量dummy和labels,dummy向量记录distmat的每行的最小值,labels向量记录每行最小值的列号(多个取第一个),即是第几个聚类,labels是N×1列向量,N为样本数
for k=1:K
Xk = X(labels == k, :); %把标志为同一个聚类的样本组合起来
pPi(k) = size(Xk, 1)/N; %求混合高斯模型的加权系数,pPi为1*K的向量
pSigma(:, :, k) = cov(Xk);
%如果X为Nx1数组,那么cov(Xk)求单个高斯模型的协方差矩阵
%如果X为NxD(D>1)的矩阵,那么cov(Xk)求聚类样本的协方差矩阵
%cov()求出的为方阵--《概率论与数理统计》-多维随机变量的数字特征,且是对称矩阵(上三角和下三角对称)--《线性代数》
%pSigma为D*D*K的矩阵
end
end
function Px = calc_prob()
Px = zeros(N, K);%NxK零矩阵
for k = 1:K
Xshift = X-repmat(pMiu(k, :), N, 1); %NxD矩阵Xshift表示为对于一个1xD聚类点向量行向增N倍的样本矩阵-Uk,第i行表示xi-uk
inv_pSigma = inv(pSigma(:, :, k)); %求协方差矩阵的逆,pSigmaD*D*K的矩阵, inv_pSigmaD*D的矩阵,Σ^-1
tmp = sum((Xshift*inv_pSigma) .* Xshift, 2);
%tmp为N*1矩阵,第i行表示(xi-uk)^T*Sigma^-1*(xi-uk) 即-(x-μ)转置x(Σ^-1).(x-μ) ----矩阵有叉乘(矩阵乘)和点乘
coef = (2*pi)^(-D/2) * sqrt(det(inv_pSigma));
%求多维正态分布中指数前面的系数,(2π)^(-d/2)*|(Σ^-(1/2))|
Px(:, k) = coef * exp(-0.5*tmp); %NxK矩阵求单独一个D维正态分布生成样本的概率密度或贡献
end
end
end
%聚类 数据挖掘
%矩阵算法 线性代数
%概率密度,近似然 数理统计函数返回的 Px 是一个 N×K 的矩阵,对于每一个 x_i ,我们只要取该矩阵第 i 行中最大的那个概率值所对应的那个 Component 为 x_i 所属的 cluster 就可以实现一个完整的聚类方法了。
参考网址:
聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
GMM的EM算法实现
matlab注释分析高斯混合模型
维基百科:多元正态分布
维基百科:协方差矩阵

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









