






Point Transformer V3
abstract
本篇论文不是寻求注意力机制的新的创新,而是平衡点云处理中准确性和效率的trade-offs。借鉴3D large-scale表示学习,作者认识到模型性能更受规模scale的影响,而不是复杂设计。因此作者提出Point Transformer V3 (PTv3),优先考虑简单性和效率。例如,将KNN替换成序列化的邻域映射*。这一准则支持大规模scaling,将感受野receptive field从16个点扩展到1024个点,同时保持高效(与PTv2相比,处理速度提高了3倍,内存效率提高了10倍)。PTv3在室内外场景的20多个下游任务中取得了最新的结果。通过多数据集联合训练multi-dataset joint training*进一步增强,PTv3将这些结果推向了更高的水平。
- PTv3改变传统的K-Nearest Neighbors(KNN)查询定义的空间proximity(占用28% forward time ),相反,它探索点云序列化邻域。
- PTv3用适合序列化点云的改进方法替换更复杂的注意力块交互机制attention patch interaction mechanisms,如shift-window(妨碍注意力操作的融合)和邻域机制(导致内存消耗大)。
- PTv3消除了对相对位置编码的依赖(占用26% forward time ),支持更简单的预置稀疏卷积层prepositive sparse convolutional layer。
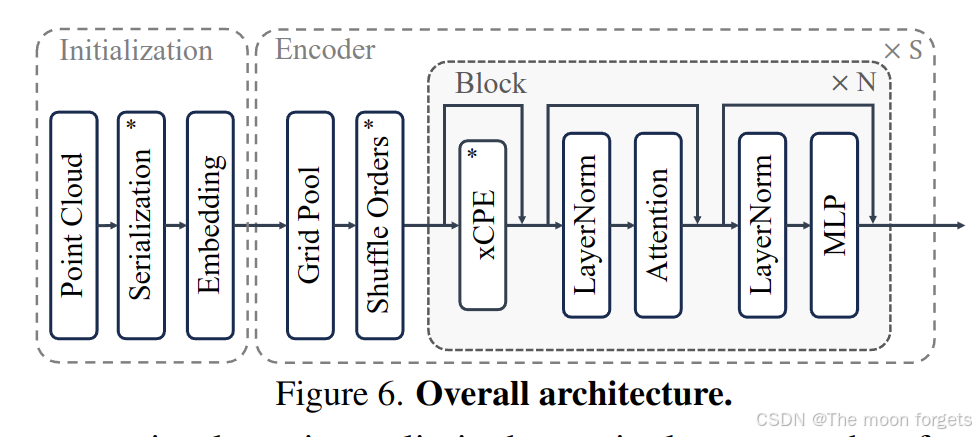
Main method
Point Cloud Serialization
点云序列化/结构化,利用结构化数据的简单性和效率提升点云的处理速度。
Space-filling curves
Space-filling curves会在高维离散空间中遍历点云中的所有点,并使其保持一定的空间临近性。可以表征为双射函数:
$ \varphi : \mathbb{Z} \rightarrow \mathbb{Z}^nKaTeX parse error: Expected 'EOF', got '&' at position 49: … z-order curve &̲& Hilbert curve…g \in{\mathbb{R}}$ 的离散空间上,将这个代码表示为
φ
−
1
(
⌊
p
/
g
⌋
)
\varphi^{-1}\left(\left\lfloor \textbf{p} / g \right\rfloor\right)
φ−1(⌊p/g⌋)。这种编码encoding也适用于批处理的点云数据。通过为每个点分配一个64位整数来记录序列化代码serialization code,作者将末尾的 k 位分配给由
φ
−
1
\varphi^{-1}
φ−1 编码的位置,将剩余的前导位分配给批次索引batch index。根据这个序列化代码serialization code对点进行排序,使得批处理的点云在每个批次内按照所选的空间填充曲线模式有序*。整个过程可以写成如下形式:
E
n
c
o
d
e
r
(
p
,
b
,
g
)
=
(
b
≪
k
)
∣
φ
−
1
(
⌊
p
/
g
⌋
)
Encoder(\textbf{p}, b, g) = (b \ll k) | \varphi^{-1}\left(\left\lfloor \textbf{p} / g \right\rfloor\right)
Encoder(p,b,g)=(b≪k)∣φ−1(⌊p/g⌋)
Serialization
根据曲线的先后顺序对点云进行重序列化,同时也可以保留点云的空间临近性。
Serialized Attention
patch attention
相比于KNN,序列化数据会导致点云丧失一些空间临近的信息,但是序列化数据的可扩展性潜力会弥补这一劣势。
-
Patch grouping
直接按照存储的序列化的字典顺序进行分组,同时对每个patch的数据进行padding补齐 -
Patch interaction
此处有不同的交互方式,如偏移膨胀、偏移,随机顺序等,此处选用优化的随机顺序作为patch interaction的方式。 -
Positional encoding
引入条件位置编码(CPE), 利用八叉树(octree)的深度可分离卷积实现,来降低计算复杂度。xCPE: 添加了一个额外跳连的稀疏卷积层
Result
![[图片]](https://i-blog.csdnimg.cn/direct/f147046a9bb948d7993218f7448a9890.png)
Visualization
![[图片]](https://i-blog.csdnimg.cn/direct/41fd790f09664b4187fe4624be17a8d7.png)

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









