






Abstract
摘要
从单目图像估计三维边界框是自动驾驶中的一个重要组成部分,而从这种数据中进行准确的三维物体检测非常具有挑战性。在这项工作中,通过大量的诊断实验,我们量化了每个子任务所引入的影响,发现“定位误差”是限制单目三维检测的关键因素。此外,我们还研究了定位误差背后的深层原因,分析了它们可能带来的问题,并提出了三种策略。首先,我们重新审视了二维边界框中心与三维物体投影中心之间的不对齐,这是导致低定位精度的一个关键因素。其次,我们观察到现有技术几乎不可能准确定位远处的物体,而这些样本会误导所学习的网络。为此,我们提出从训练集中移除这些样本,以提高检测器的整体性能。最后,我们还提出了一种新颖的三维 IoU 取向损失,用于物体大小的估计,这不受“定位误差”的影响。我们在 KITTI 数据集上进行了大量实验,所提出的方法实现了实时检测,并在很大程度上超越了之前的方法。代码将在以下地址提供:https://github.com/xinzhuma/monodle。
这段文本讨论了单目图像(即使用单个摄像头拍摄的图像)中三维边界框估计的挑战及其改进方法。以下是主要分析点:
分析
定位误差的重要性
定位误差被认为是限制单目三维检测精度的关键因素。通过诊断实验,作者量化了各种子任务对检测精度的影响,发现定位误差对最终结果影响最大。
定位误差的原因及解决策略
- 二维与三维中心的不对齐:二维边界框中心与三维物体投影中心的不对齐是导致低定位精度的一个主要原因。作者建议重新审视和调整这一点。
- 远处物体的误导:现有技术难以准确定位远处的物体,这些样本会误导神经网络的学习过程。作者建议在训练集中移除这些远处样本,以提高检测器的整体性能。
- 三维 IoU 取向损失:提出了一种新的三维 IoU 取向损失函数,用于物体大小的估计,该方法不受定位误差的影响。
Introduction
这段文本深入探讨了单目图像三维检测的挑战,并描述了作者通过一系列诊断实验找出问题所在并提出改进方案的过程。以下是主要分析点:
基于LiDAR/立体视觉与单目图像的性能对比:
基于LiDAR或立体视觉的三维检测方法已经取得了显著的进展,其精度明显高于仅使用单目图像的方法。本文的目标是定量识别单目图像三维检测中的问题并提出解决方案。
诊断实验的方法和目的:
作者基于CenterNet构建了基线模型,通过逐步用真实值替换预测值来量化不同因素对检测性能的影响。这些诊断实验帮助识别了限制单目三维检测的关键因素。
关键发现和设计:
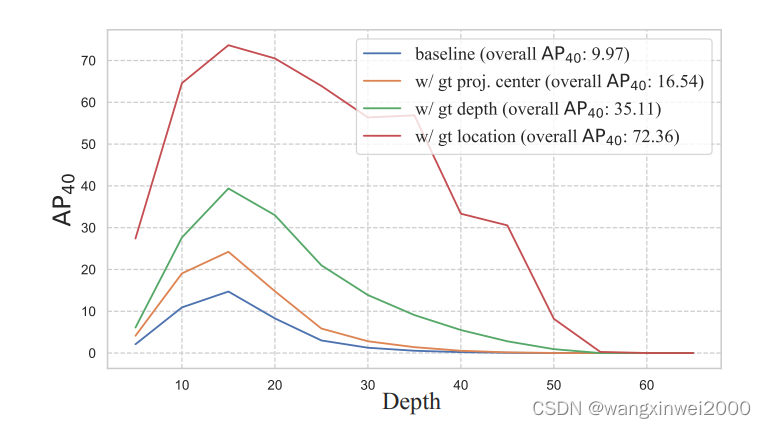
- 观察1:定位误差是关键因素:实验结果显示,使用真实位置时,单目三维检测的性能显著提升,表明定位误差是限制检测性能的主要因素。此外,准确检测三维物体的投影中心对于恢复其三维位置也至关重要。
- 观察2:远处物体检测困难:随着距离增加,检测精度显著降低,远处物体几乎无法被准确检测到。作者提出从训练集中移除远处样本或减少这些样本的训练损失权重,以提高整体检测性能。
- 观察3:尺寸估计的改进:除了定位误差外,尺寸估计也是限制单目三维检测的一个重要因素。作者提出了一种基于IoU的三维尺寸估计损失,通过动态调整损失权重来优化尺寸估计。
Related Work
为了恢复3D物体位置,有两组方法。第一组[44, 10, 36]使用2D边界框来获得3D位置。特别是,CenterNet [44]将2D边界框的中心视为图像平面中的投影3D位置,并利用估计的深度和相机参数将其反投影到3D空间。然而,一般来说,2D框的中心和3D框的中心并不相同。[10, 36]通过回归一个偏移量来补偿它们之间的差异。第二组方法SMOKE [24]移除了2D检测,直接使用投影的3D中心来估计3D位置。这项工作认为2D相关的子任务是多余的,因为可以从3D检测结果生成2D边界框。在这项工作中,我们重新审视了这个问题,并确认用投影的3D中心替换2D中心可以提高定位准确性。此外,我们还发现2D检测是必要的,因为它有助于学习3D检测所需的共享特征。
Approach
Problem Definition
在给定RGB图像及其相应的相机参数的情况下,目标是在3D空间中对感兴趣的物体进行分类和定位。每个物体通过其类别、二维边界框 B2D 和三维边界框 B3D来表示。具体如下:

Baseline Model
模型架构
- 骨干网络:使用DLA-34作为骨干网络,旨在达到速度和准确性之间的平衡。
- 轻量级头部:七个轻量级头部用于2D和3D检测,每个头部由一个3×3卷积层和一个1×1卷积层组成。
2D检测
- 热图输出:用于表示分类分数和物体的粗略中心。
- 中心监督:粗略中心由真实的2D边界框中心监督。
- 偏移量预测:用于修正粗略中心到真实中心的偏移量。
- 尺寸估计:用于预测2D边界框的尺寸。
3D检测
- 偏移量预测:用于修正粗略中心到投影3D边界框中心的偏移量。
- 中心恢复:通过相机内参矩阵和深度分支的输出恢复3D世界空间中的物体中心。
- 尺寸和方向角预测:分别用于预测3D边界框的大小和方向角。
损失函数
- 分类损失:采用修改后的Focal Loss。
- 2D检测损失:中心和大小回归采用L1 Loss。
- 3D检测损失:
- 深度估计采用不确定性建模。
- 3D中心精炼采用L1损失。
- 方向角估计采用多箱损失。
- 3D大小估计基准模型中使用L1损失,改进模型中使用IoU损失。
关键点
- 七个损失项:涵盖分类、2D中心和大小回归、3D中心、深度、大小和方向角预测。
- 无锚点策略:中心和大小回归使用L1 Loss时不使用任何锚点。
- 多箱损失:用于方向角估计,考虑12个不重叠的等宽箱。
- IoU损失:在改进模型中用于3D大小估计,提高精度。
Error Analysis
在本节中,我们探讨了限制单目3D检测性能的因素。受到2D检测领域中的CenterNet [44]和CornerNet [21]的启发,我们对KITTI验证集中的不同预测项进行了错误分析,通过将每个预测项替换为真实值并评估性能。具体来说,我们根据[21, 44]的做法,用真实值替换每个输出头。如表1所示,如果将基线模型预测的投影3D中心c_w替换为真实值,准确率从11.12%提高到18.97%。另一方面,深度可以将准确率提高到38.01%。如果同时考虑深度和投影中心,即将预测的3D位置[x, y, z]3D替换为真实结果,那么可以观察到最明显的改进。因此,单目3D检测准确率低的主要原因是定位误差。另一方面,根据公式1,深度估计和中心定位共同决定了物体在3D世界空间中的位置。相比于从单目图像中进行病态的深度估计,改进中心检测的准确率是一个更可行的方法。 表2显示了由不准确的中心检测引入的定位误差。此外,KITTI数据集中汽车的平均尺寸为[h, w, l]3D分别是[1.53m, 1.63m, 3.53m]。假设所有其他量都是正确的,并且定位误差与长度l对齐(导致最大容差),IoU可以通过以下公式计算:
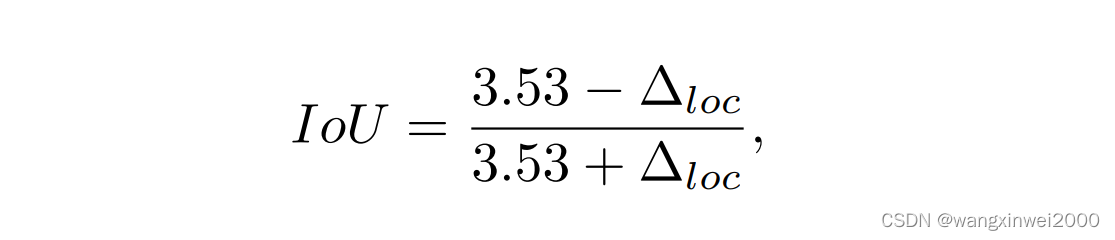
其中Δloc表示定位误差。根据官方设置,IoU阈值应设置为0.7,因此理论上可接受的最大误差是0.62m。然而,在图像中仅有4-8像素(在4×下采样特征图中1-2像素)的误差就会导致无法正确检测到60米外的物体。加上深度估计等其他任务累积的误差(图3显示了深度估计的误差),除非深度估计足够准确(尚未实现),否则从单个单目图像准确估计远处物体的3D边界框几乎是不可能的任务。
Revisiting Center Detection
我们的中心检测设计
为了估计粗略中心c,我们的设计很简单。具体来说,我们1)使用投影3D中心c_w作为估计粗略中心c的分支的真实值,并2)强制我们的模型同时从2D检测中学习特征。这个简单的设计来源于我们的以下分析。
分析1:如图4所示,2D边界框中心c_i和3D边界框的投影中心c_w之间存在不对齐现象。根据公式1,投影3D中心c_w应该是恢复3D物体中心[x, y, z]3D的关键。这里的关键问题是粗略中心c的监督应当是什么。一些工作[10, 36]选择使用2D框中心c_i作为标签,这与3D物体中心无关,使得粗略中心的估计无法意识到物体的3D几何形状。这里我们选择采用投影3D中心c_w作为粗略中心c的真实值。这有助于估计粗略中心的分支了解3D几何形状,并且更与估计3D物体中心的任务相关,这是定位问题的关键(见补充材料中的可视化部分E)。

分析2:注意到SMOKE[24]也使用投影3D中心c_w作为粗略中心c的标签。然而,他们丢弃了与2D检测相关的分支,而我们保留了它们。在我们的设计中,粗略中心c由投影3D中心c_w监督,也用于估计2D边界框中心c_i。通过我们的设计,我们强制2D检测分支估计真实2D中心与粗略2D中心之间的偏移o_i = c_i - c。这使得我们的模型能够意识到物体的几何信息。此外,另一个分支用于估计2D边界框的大小,这样共享特征可以通过透视投影学习一些有助于深度估计的线索。这样,2D检测作为一个辅助任务,有助于学习更好的3D感知特征。
Training Samples
与[35, 23]不同的是,它们迫使网络关注“困难”样本,我们认为忽略一些极端“困难”的情况可以提高单目3D检测任务的整体性能。图1所示的结果和第4.4节进行的分析表明,目标距离与检测难度之间存在很强的关系。根据这一点,我们提出了两种生成样本i的目标级训练权重 wi 的方案。

IoU Oriented Optimization
单目3D检测面临一个主要挑战:确定物体的3D中心。由于单目图像中深度估计的病态性,定位误差通常很大,影响了3D尺寸估计等其他任务的准确性。如果直接应用基于IoU的损失函数,可能会使定位相关的任务占据主导地位,导致训练过程不稳定甚至崩溃。因此,需要一种能够平衡各任务的重要性的方法。
现有方法的问题
- 直接应用IoU损失: 在单目3D检测中,定位误差较大,直接应用IoU损失会导致定位相关任务压倒其他任务。
- 独立优化各损失项: 虽然可以将各损失项独立优化,但这忽略了它们之间的相关性,可能影响最终结果的整体性能。
提出的解决方案
为了平衡各子任务的重要性,并解决定位误差大的问题,提出了一种针对3D尺寸估计的IoU导向优化方法:

提出的IoU导向优化方法,通过偏导数调整权重、动态补偿权重等方式,有效解决了单目3D检测中定位误差大的问题,平衡了各子任务的重要性,提高了整体检测性能。

















 3050
3050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









