







 本文深入解析元学习(Meta-Learning)核心概念,对比MAML、Reptile与Pre-train等方法,阐述元学习在小样本学习中的优势及其实现机制。通过案例分析,展示元学习如何帮助模型在少量样本下快速掌握新任务。
本文深入解析元学习(Meta-Learning)核心概念,对比MAML、Reptile与Pre-train等方法,阐述元学习在小样本学习中的优势及其实现机制。通过案例分析,展示元学习如何帮助模型在少量样本下快速掌握新任务。
感觉李宏毅和网上其他视频都是错的:
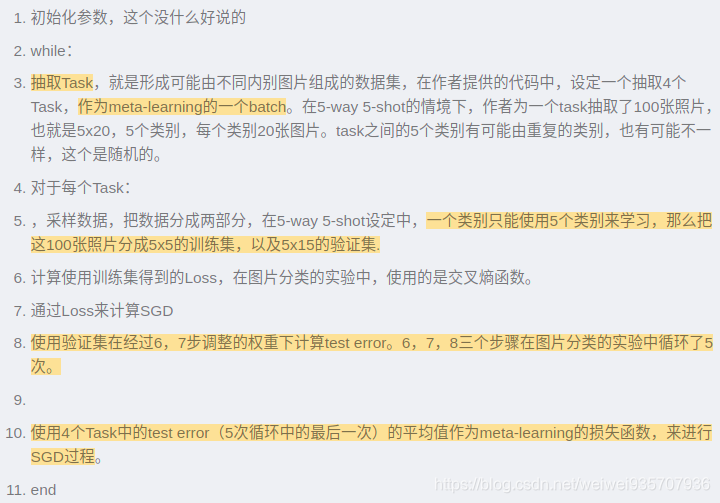
Meta Learning(Few-shot Learning)以及MAML的理解 - 知乎
这个和雨豪的说法一样,应该是对的
元学习中久负盛名的MAML:



下面这段有一个需要注意的点: 就是训练, 测试, 验证的划分并不是简单按照数量划分, 而是划分类别: 即64个类别, 20个类别, 16个类别. 验证和测试集的类别是训练集当中没有的.


下面这段, 元学习的主题: 能够只通过少量样本就是快速学习到知识. 即所谓的学习学习. 而如何实现这点呢?就是靠下面这段, 即: 在训练的过程对模型的要求本来就是快速适应:
用每个任务中, 测试误差作为训练损失, 细细品品


算法过程:(其实, 这个过程还不是很清楚, 到底是在哪一步进行反向传播)
这里还有一个不是很清楚的点: 就是5way 5shot到底是: 前四个做训练, 最后一个做测试吗
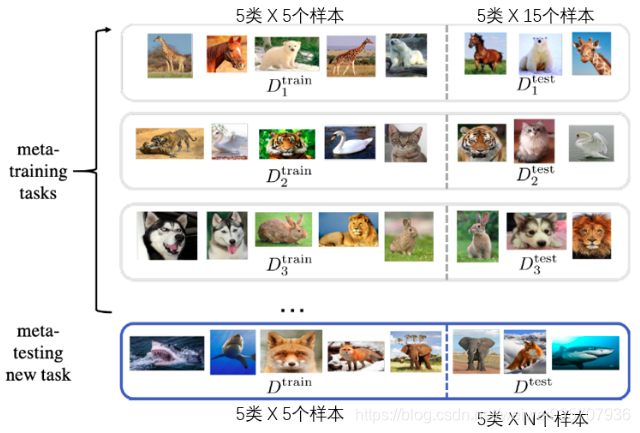
所以, 我看来看去元学习的重点就是, 好好地划分数据集
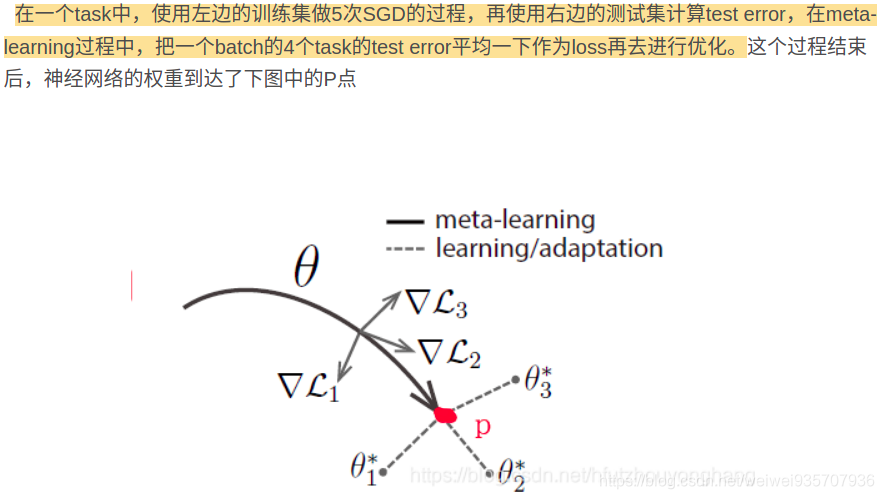
这里有一个疑问, 话说元学习到底是有学习超参吗:

以上都是摘自一篇有代码解读的博客: 小样本学习论文--Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks_smart_hang的博客-CSDN博客
在进行下一篇之前, 我们先放一下台湾大学, 李宏毅教授的几张PPT:
第一张PPT阐述一下, 元学习参数更新的过程:
-
求和符号里面是每一个task的损失函数, 加起来得到训练集的损失函数
-
每一个task都会进行梯度的更新(虽然后面讲, 它只会更新两次)
-
所有, 有了L, 就会有模型这个F的最优解F*
-
将F*作为测试集的初始化(注意: 测试集也包含, 支撑集和查询集)
-
F*经过测试集的支撑集的训练之后, 还会更新参数(当然, 这里的更新次数是不定的)
-
经过更新之后的最优解, 就是f*
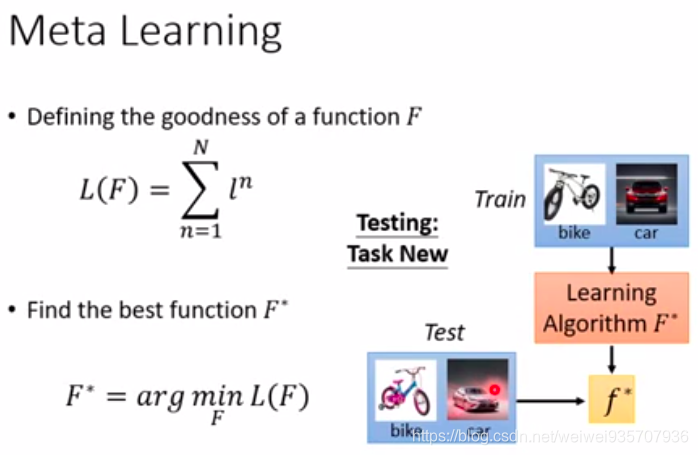
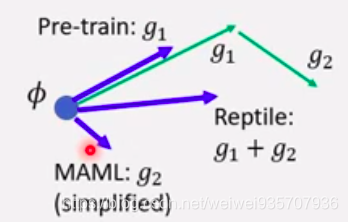
第二张PPT阐述一下, MAML, Reptile, Pre-train的区别:
MAML: 小任务, 两步之后更新参数到大任务
Reptile: 小任务, 任意步(一般是更多步)之后更新到大人物
Pre-train: 小任务, 一步之后, 更新到大任务
另一篇说明元学习的文章:
这一篇文章超级好, 说明了, 元学习是如何更新参数的, 并且还附有的 一文入门元学习(Meta-Learning)(附代码)
本质----找到一个合适的参数初始化的值
为参数学习到一个好的初始化, 然后在这个初始化的基础上利用少量更新来训练新的task.
分两步:
- 第一步: 对不同的任务进行学习
- 第二步: 第一步的模型学习新的任务, 并计算loss来更新初始化参数
一.直接理解
- 作用:解决面对类别不同,模型泛化能力不强的问题
- 直述:并不是通过学习具体任务学会新的任务,而是通过抓住任务的本质以促进新任务的学习
- 方法:
meta training阶段:将数据集分成不同的meta task(即:假设有n个类别,每次取出其中的C个类别进行训练,每个类别K个样本——C-way K-shot problem)
meta test阶段:面对全新的类别,不需要变动已有的模型就可完成训练。
- 好处:这种机制使得模型学会不同meta-task中共性的部分,比如如何提取重要特征,比较相似样本。使得模型面对新的未见过的meta-task时也能较好地进行分类。
- “多任务学习”辅助理解:
- 多个学习任务之间往往会存在一些共性,应利用多任务之间的相关性逐步提升学习效果
- “聚类”辅助理解:
- meta-task(元任务) 相当于 聚类任务中的“聚类中心”
- 举例辅助理解:
- 多任务SVM: 仅在meta-task上做一些微调,或者通过学习 meta-task的线性组合学习
二.领域发展的趋势
人工智能-》机器学习-》深度学习-》深度增强学习-》深度元学习
Artificial Intelligence-->Machine Learning-->Deep learning-->Deep Reinforcement Learning-->Deep Meta Learning
三.元学习和迁移学习的区别
迁移学习:沿用原来的网络和参数
元学习:学会学习,用先验知识
四.元学习的主要方法
大的方法有三:
学习有效的距离度量(基于度量)
使用网络与外部或内部存储器(基于模型)
明确优化参数以进行快速学习(基于优化)
- 基于记忆Memory来学习
- 基于预测梯度的方法
- 利用Attention注意力机制的方法
- 借鉴LSTM的方法
- 面向RL的 Meta Learning方法
- 通过训练一个好的base model的方法,并且同时应用到监督学习和增强学习
- 利用WaveNet的方法
- 预测Loss的方法
五.zero-shot learning 和one-shot learning(few-learning)
zero-shot learning :没有样本也能训练出这个模型,
即,原本的数据集里面没有“这个类别”, 但是还是能学习到相应的映射
one-shot learning: 极少量模型就可以训练出模型
六.半监督学习和few shot的区别
- few shot learning 是一种场景,而semi-supervised learning 是一种具体的解决途径
- few shot learning 的核心需求是,样本量小的时候,模型怎么训练
- 解决方案:
- 数据驱动方案:
- 找外部数据,甚至未标注数据
- 数据增强:加噪声,用GAN生成新数据
- 改参数空间:
- Matching network: full context embedding
- protypical network
- learn to learn: MAML
- 数据驱动方案:
六.参考文章和资料
最前沿:百家争鸣的Meta Learning/Learning to learn - 知乎 (阐述重要性和各家方法的)
元学习(Meta Learning)与迁移学习(Transfer Learning)的区别联系是什么? - 知乎 (和迁移学习的区别)
小样本学习(Few-shot Learning)综述 (小样本学习综述)
与模型无关的元学习,UC Berkeley提出一种可推广到各类任务的元学习方法 | 机器之心 (与模型无关的元学习)
资料:斯坦福大学CS330课程:多任务学习与元学习 CS 330 Deep Multi-Task and Meta Learning

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









