





深度学习数学基础 讲义
FAU深度学习讲义 (FAU Lecture Notes in Deep Learning)
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
这些是FAU YouTube讲座“ 深度学习 ”的 讲义 。 这是演讲视频和匹配幻灯片的完整记录。 我们希望您喜欢这些视频。 当然,此成绩单是使用深度学习技术自动创建的,并且仅进行了较小的手动修改。 如果发现错误,请告诉我们!
导航 (Navigation)
Previous Lecture / Watch this Video / Top Level / Next Lecture
So, thank you very much for tuning in again and welcome to our second part of the deep learning lecture and in particular the introduction. So, in the second part of the introduction, I want to show you some research that we are doing here in the pattern recognition lab, here at FAU Germany.
因此,非常感谢您再次收看本教程,并欢迎我们进入深度学习讲座的第二部分,尤其是介绍。 因此,在引言的第二部分中,我想向您展示我们在德国FAU的模式识别实验室中正在做的一些研究。

One first example that I want to highlight is a cooperation with Audi and here we are working with assisted and automated driving. We are working on smart sensors in the car. You can see that the Audi A8 today is essentially a huge sensor system that has cameras and different sensors attached. Data is processed in real-time in order to figure out things about the environment. It has functionalities like parking assistance. There are also functionalities to support you during driving and traffic jams and this is all done using sensor systems. So of course, there’s a lot of detection and segmentation tasks involved.
我要强调的第一个例子是与奥迪的合作,在这里我们正在研究辅助和自动驾驶。 我们正在研究汽车中的智能传感器。 您可以看到,今天的奥迪A8本质上是一个巨大的传感器系统,其中装有相机和不同的传感器。 数据是实时处理的,以便找出有关环境的信息。 它具有停车辅助功能。 还有一些功能可以在驾驶和交通拥堵时为您提供支持,而所有这些功能都可以通过传感器系统完成。 因此,当然,其中涉及许多检测和细分任务。

What you can see here is an example, where we show some output of what is recorded by the car. This is a frontal view, where we are actually looking around the surroundings and have to detect cars. You also have to detect — here shown in green — the free space where you can actually drive to and all of this has to be detected and many of these things are done with deep learning. Today, of course, there’s a huge challenge because we need to test the algorithms. Often this is done in simulated environments and then a lot of data is produced in order to make them reliable. But in the very end, this has to run on the road which means that you have to consider different periods of the year and different daylight conditions. This makes it all extremely hard. What you’ve seen in research is that many of the detection results are working with nice day scenes and the sun is shining. Everything is nice, so the algorithms work really well.
您可以在此处看到一个示例,其中我们显示了汽车记录的一些输出。 这是正面视图,我们实际上是在环顾四周并必须检测汽车。 您还必须检测到实际可用的空闲空间(此处显示为绿色),并且必须检测所有这些自由空间,其中许多事情都是通过深度学习完成的。 当然,今天,我们面临着巨大的挑战,因为我们需要测试算法。 通常,这是在模拟环境中完成的,然后生成大量数据以使其可靠。 但最终,这必须继续进行,这意味着您必须考虑一年中的不同时期和不同的日光条件。 这使这一切变得异常困难。 您在研究中看到的是,许多检测结果在晴天时都可以正常工作,并且阳光明媚。 一切都很好,因此算法工作得很好。
But the true challenge is actually to go towards rainy weather conditions, night, winter, snow, and you still want to be able to detect, of course, not just cars but traffic signs and landmarks. Then you analyze the scenes around you such that you have a reliable prediction towards your autonomous driver system.
但是,真正的挑战实际上是要朝着阴雨天气,夜晚,冬天,下雪的方向前进,当然,您仍然希望能够不仅检测汽车,还可以检测交通标志和地标。 然后,您分析周围的场景,以便对自动驾驶系统有可靠的预测。

We also look into smart devices and of course, some very interesting topic here is renewable energy and power. One problem that we typically face is under production, when there’s not enough wind blowing or when not enough sun is shining. Then, you have to fire up backup power plants and, of course, you don’t want to do overproduction because that would produce energy that cannot be stored very well. The storing of energy is not very efficient right now. There are some ideas to tackle this like real-time prices but what you need are smart devices that can recognize and predict how much power is going to be produced in the near future.
我们还将研究智能设备,当然,这里一些非常有趣的主题是可再生能源和电力。 通常,我们面临的一个问题是生产中,当吹的风不足或阳光不足时。 然后,您必须启动备用发电厂,并且当然,您不想进行超量生产,因为这会产生无法很好存储的能量。 目前,能量存储不是很有效。 有一些解决办法,例如实时价格,但是您需要的是可以识别并预测不久的将来将产生多少电力的智能设备。
So, let’s look at an example of smart devices. So let’s say, you have a fridge or a washing machine and you can program them in a way that they are flexible at the point in time when they consume the energy. You can start the washing also maybe overnight or in one hour when the price is lower. So, if you had smart devices that could predict the current prices, then you would be able to essentially balance the nodes of the energy system and at the same time remove the peak conditions. Let’s say there’s a lot of wind blowing. Then, it would make sense that a lot of people cool down the refrigerator or wash their dishes or their clothes. So this can be done of course with recurrent neural networks and then you predict how much power will be produced and use it on the client-side to level the power production.
因此,让我们看一个智能设备的例子。 因此,假设您有一台冰箱或洗衣机,并且可以对它们进行编程,以使其在消耗能量的时间点灵活。 价格较低时,您也可以隔夜或在一小时内开始洗涤。 因此,如果您拥有可以预测当前价格的智能设备,那么您将能够基本平衡能源系统的各个节点,同时消除峰值条件。 假设有很多风在吹。 然后,有意义的是,许多人将冰箱冷却或洗碗碟或洗衣服。 因此,这当然可以通过递归神经网络来完成,然后您可以预测将产生多少功率,并在客户端使用它来平衡功率产生。

This example here shows a solar power plant. They were interested in predicting the short-term power production in order to inform other devices or to fire up backup power plants. The crucial timeframe here is approximately 10 minutes. So, the idea here was to monitor the sky, to detect the clouds, to estimate the cloud motion, and then directly predict from the current sky image, how much power will be produced within the next 10 minutes. So, let’s say there’s a cloud that is likely to be covering the Sun really soon. Then, you want to fire up generators or inform devices not to consume so much energy. Now clouds are really difficult to describe in terms of an algorithm but what we are doing here is that we are using a deep network to try to learn the representation. These deep learning features are predictive for power production and we actually managed to produce reliable predictions for approximately 10 minutes. With traditional pattern recognition techniques, we could only do predictions of approximately 5 minutes.
此示例显示了一个太阳能发电厂。 他们对预测短期发电量感兴趣,以便通知其他设备或启动备用发电厂。 此处的关键时间约为10分钟。 因此,这里的想法是监视天空,检测云层,估算云层运动,然后直接从当前的天空图像中预测未来10分钟内将产生多少电能。 因此,假设有可能很快覆盖太阳的云。 然后,您要启动发电机或通知设备不要消耗太多能量。 现在真的很难用算法来描述云,但是我们在这里所做的是我们正在使用一个深层网络来尝试学习表示。 这些深度学习功能可预测电力生产,实际上,我们能够在大约10分钟的时间内做出可靠的预测。 使用传统的模式识别技术,我们只能进行大约5分钟的预测。

Another very exciting topic that I want to demonstrate today, is writer recognition. Now here, the task is that you have a piece of writing and you want to find out who wrote actually this text. So, we are not recognizing what was written but who has written the text. The idea here is again to train a deep network and this deep network is then learning abstract features that describe how a person is writing. So it’s only looking at small patches around the letters and these small patches around the letters are used in order to predict who has actually written the text.
我今天要展示的另一个非常令人兴奋的主题是作者认可。 现在,这里的任务是您有一篇文章,并且想知道实际写这篇文章的是谁。 因此,我们无法识别写的是什么,而是谁写的。 这里的想法再次是训练一个深层网络,然后该深层网络将学习描述一个人如何写作的抽象特征。 因此,仅查看字母周围的小补丁,并使用字母周围的这些小补丁来预测谁实际上写过文字。

A colleague of mine just showed in a very nice submission that he just submitted to an international conference that he is also able to generate handwriting that is distinctive for a particular person. Like many methods, you can see that these deep learning approaches can, of course, be used for very good purposes like identifying what a person wrote this in historical texts. But then you can also use very similar methods to produce fakes and to spread misinformation. So you can see that in a lot of technology and of course this is a reason why ethics are very important also in the field of deep learning.
我的一位同事刚刚在一个非常不错的陈述中表示,他刚刚参加了一次国际会议,他还能够产生对于特定人而言独特的笔迹。 与许多方法一样,您可以看到,这些深度学习方法当然可以用于非常好的目的,例如识别一个人在历史文本中写了什么。 但是,然后您也可以使用非常相似的方法来制造假货和散布错误信息。 因此,您可以看到,在很多技术中,这当然是道德在深度学习领域中也非常重要的原因。

Most of the work that we are doing is actually concerning medical applications. A really cool application of deep learning is where you want to screen a really large part of data. So a colleague of mine just started looking into whole slide images. This is for tumor diagnostics, for example where you’re interested to figure out how aggressive a cancer is. You can figure out, how aggressive a cancer is if you look at the number of cell divisions that are going on at a certain point in time. So, you are actually interested in not just finding out the cancer cells, but you want to find how often these cancer cells actually undergo mitosis, i.e. cell division. The number of detected mitoses is indicative of how aggressive this particular cancer is. Now, these whole slide images are very big and you don’t want to look at every cell individually. What you can do, is that you can train a deep network to look at all of the cells and then do the analysis for the entire whole slide in clinical routine. Currently, people are not looking at the entire slide image. They are looking at high power fields, like the small part that you can see here on this image.
我们正在进行的大多数工作实际上都与医疗应用有关。 深度学习的一个非常酷的应用是您要筛选很大一部分数据的地方。 因此,我的一位同事刚刚开始研究整个幻灯片图像。 这是用于肿瘤诊断的,例如,您有兴趣找出癌症的侵略性的地方。 如果查看特定时间点正在进行的细胞分裂的数目,您可以弄清楚癌症的侵袭性。 因此,您实际上不仅对发现癌细胞感兴趣,而且还想找到这些癌细胞实际经历有丝分裂(即细胞分裂)的频率。 检测到的有丝分裂的数量表明该特定癌症的侵略性。 现在,这些完整的幻灯片图像非常大,您不想单独查看每个单元格。 您可以做的是,可以训练一个深层网络来查看所有细胞,然后按照临床常规对整个玻片进行分析。 当前,人们没有看到整个幻灯片图像。 他们正在观察高功率场,就像您可以在此图像上看到的一小部分一样。

This is a high power field. In clinical routine, they count the mitosis within this field of view. So of course, they just don’t do it on a single high power field. They typically look at ten high power fields to assess the aggressiveness of cancer. With the deep learning method, you could process all of the slides.
这是一个高功率领域。 在临床常规中,他们计算该视野内的有丝分裂。 因此,当然,他们只是不在单个高功率场上这样做。 他们通常着眼于十个高功率领域来评估癌症的侵略性。 使用深度学习方法,您可以处理所有幻灯片。

So this is how such a deep learning approach would look like. You have some part in the network that localizes the cells and then a different part of the network that is then classifying the cell, whether it’s a mitosis, a regular cell, or a cancer cell.
这就是这种深度学习方法的样子。 您在网络中有一部分可以对细胞进行定位,然后在网络中可以对细胞进行分类的另一部分,无论是有丝分裂,正常细胞还是癌细胞。

Very interesting things can also be done with defect pixel interpolation. So here, we see a small scene where we show the coronary arteries of the heart. Typically those coronary arteries are not stationary. They are moving and because they are moving it’s very hard to see and analyze them. So what is typically done to create clear images of the coronary arteries is you inject contrast agent and the reason why you can actually see the coronary arteries in this image is because they are right now filled with iodine-based contrast agent. Otherwise, because blood is very close to water in terms of X-ray absorption, you wouldn’t be able to see anything.
缺陷像素插值也可以完成非常有趣的事情。 因此,在这里,我们看到一个小的场景,显示了心脏的冠状动脉。 通常,那些冠状动脉不是固定的。 他们在移动,因为他们在移动,所以很难看到和分析它们。 因此,通常要做的是创建清晰的冠状动脉图像,就是注入造影剂,而之所以可以在该图像中实际看到冠状动脉,是因为它们现在已充满了基于碘的造影剂。 否则,由于血液在X射线吸收方面非常接近水,因此您将看不到任何东西。

A very common technique to visualize the arteries is to take two images: one with contrast agent and one without. Now, if you subtract the two you would only see the contrast agent. In a cardiac intervention, this is very difficult because the heart is moving all the time and the patient is breathing. Therefore it is very hard to apply techniques like digital subtraction angiography.
可视化动脉的一种非常常见的技术是拍摄两个图像:一个带有造影剂,另一个没有。 现在,如果将两者相减,则只会看到造影剂。 在心脏介入治疗中,这是非常困难的,因为心脏一直在移动,而患者正在呼吸。 因此,很难应用数字减影血管造影等技术。

Here we propose to segment the detected vessels. So, we use a deep learning framework that is actually segmenting the vessels. Once we have the vessel segmentation, we use this as a mask. Then, we use a deep learning method to predict the pixels of the mask if there were no contrast agent. This will make those pixels disappear from the image. Now, you can take this virtual non-contrast image and subtract from the original projection and you get a digital subtraction angiogram. This technique also works for images in motion. So this is something that could not be done without techniques of deep learning. The actual implementation for the interpolation is done by a U-Net. This is something that you will hear in the latter part of this lecture when we are talking about image segmentation where it’s typically used. The U-Net is a general image to image transformer. You can also use it to produce contrast free images.
在这里,我们建议分割检测到的血管。 因此,我们使用了深度学习框架,该框架实际上是对血管进行了细分。 进行血管分割后,将其用作遮罩。 然后,如果没有造影剂,我们将使用深度学习方法来预测蒙版的像素。 这将使这些像素从图像中消失。 现在,您可以拍摄此虚拟非对比度图像,并从原始投影中减去,即可得到数字减影血管造影照片。 该技术也适用于运动图像。 因此,如果没有深度学习技术,这是无法完成的。 插值的实际实现是通过U-Net完成的。 这是在本讲座的后半部分,当我们谈论通常使用的图像分割时,您会听到。 U-Net是图像到图像转换器的常规图像。 您也可以使用它来产生无对比度的图像。

Another important part that is often done in whole-body images is that you want to localize different organs. My colleague Florin Ghesu developed a smart method in order to figure out where the different organs are. So, the idea is to process the image in a very similar way as you would do as a radiologist: You start off by looking at a small part of the image and then you try to predict where you have to go to find that specific organ of interest. Of course, doing this on a single resolution level is insufficient. Thus, you’re then also refining the search on smaller resolution levels in order to get a very precise prediction of the organ centroid. This kind of prediction is very fast because you only look at a fraction of the volume. So you can do 200 anatomical landmarks in approximately two seconds. The other very interesting part is that you produce a path that can also then be interpreted. Even in cases where the specific landmark is not present in the volume this approach does not fail. So, let’s say you look for the hipbone in a volume that doesn’t even show the hip. Then you will see that the virtual agent tries to leave the volume and it will not predict a false position. Instead, it will show you that the hipbone would be much lower and you have to leave the volume at this place.
通常在全身图像中完成的另一个重要部分是要定位不同的器官。 我的同事弗洛林·格苏(Florin Ghesu)开发了一种聪明的方法,以便弄清不同器官的位置。 因此,我们的想法是按照与放射科医生一样的方式处理图像:首先查看图像的一小部分,然后尝试预测必须去哪里找到该特定器官出于兴趣。 当然,在单个分辨率级别上执行此操作是不够的。 因此,您还可以在较小的分辨率级别上细化搜索,以便对器官质心进行非常精确的预测。 这种预测非常快,因为您只看一小部分体积。 因此,您可以在大约两秒钟内完成200个解剖学界标。 另一个非常有趣的部分是,您生成的路径也可以被解释。 即使在卷中不存在特定地标的情况下,该方法也不会失败。 因此,假设您要寻找的体积甚至不显示臀部的髋骨。 然后您将看到虚拟代理尝试离开该卷,并且不会预测错误的位置。 相反,它将向您显示髋骨要低得多,您必须将音量留在此位置。

Landmark detection can also be used in projection images as demonstrated by my colleague Bastian Bier. He developed a very interesting method where you are using the 3-D position of landmarks. With the 3-D position, you create virtual projections of the landmark and train a projection image-based classifier. With the projection image-based classifier, you can detect the landmark in arbitrary views of the specific anatomy under interest. So here, we show an example for the hipbone and you can see that if we forward project it and try to detect the landmarks, it’s actually a pretty hard task. With the method that Bastion has devised, we are able to track the entire hip bone and to find the specific landmarks on the hip bone directly from the projection views. So the idea here is that you use a convolutional pose machine. Here we essentially process each landmark individually and then you inform the different landmarks that have been detected in the first part about the respective other landmarks’ positions. Then, you process again and again until you have a final landmark position.
正如我的同事巴斯蒂安·比尔(Bastian Bier)所展示的,地标检测也可以用于投影图像中。 他开发了一种非常有趣的方法,您可以在其中使用地标的3D位置。 在3-D位置,您可以创建地标的虚拟投影并训练基于投影图像的分类器。 使用基于投影图像的分类器,可以在感兴趣的特定解剖结构的任意视图中检测界标。 因此,在这里,我们展示了一个有关髋骨的示例,您可以看到,如果我们向前投影它并尝试检测界标,这实际上是一项艰巨的任务。 使用Bastion设计的方法,我们可以跟踪整个髋骨并直接从投影视图中找到髋骨上的特定界标。 因此,这里的想法是使用卷积姿势机。 在这里,我们实际上是分别处理每个地标,然后您将在第一部分中检测到的不同地标告知各个其他地标的位置。 然后,您一次又一次地处理,直到获得最终的地标位置。

My colleague Xia Zhong has been working on prediction of organ positions and what he has been doing is he is essentially using a 3-D camera to detect the surface of the patient. Then, he wants to predict where the organs are actually located inside the body. Now, this is very interesting because we can use the information to predict how much radiation dose will be applied to different organs. So if I knew where the organs are, then I can adjust my treatment for radiation planning or even for imaging in order to select a position of the x-ray device that has a minimum dose to the organs of risk. This can help us to reduce the dose to the organs and the risk of developing cancer after the respective treatment.
我的同事夏忠一直在进行器官位置的预测,而他所做的基本上是使用3-D照相机来检测患者的表面。 然后,他想预测器官实际上在体内的位置。 现在,这非常有趣,因为我们可以使用该信息来预测将对不同器官施加多少辐射剂量。 因此,如果我知道器官在哪里,那么我可以针对放射线计划甚至成像调整我的治疗方法,以便选择对风险器官具有最小剂量的X射线设备的位置。 这可以帮助我们减少对器官的剂量以及相应治疗后患上癌症的风险。
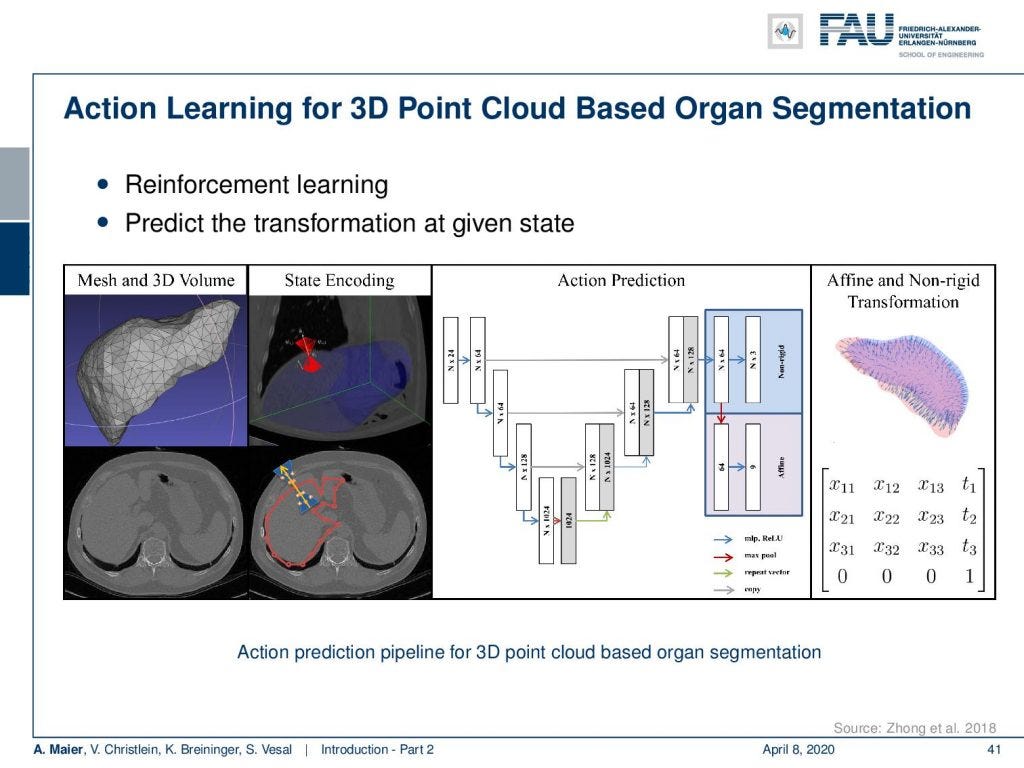
Now, this approach of prediction of organ positions from only surface information can also be used to perform organ segmentation in interventional CT. So, the idea here is that you start with an initial point-cloud of the organ and then refine it similar to the previous agent-based approach. We modify the mesh step-by-step such that it matches the organ shape in a particular image. So here you see some preoperative CT image on the left and from this, we can train algorithms and produce point clouds.
现在,这种仅根据表面信息预测器官位置的方法也可以用于在介入CT中执行器官分割。 因此,这里的想法是从器官的初始点云开始,然后类似于以前的基于代理的方法对其进行完善。 我们逐步修改网格,使其与特定图像中的器官形状匹配。 因此,在这里您可以在左侧看到一些术前CT图像,然后我们就可以训练算法并生成点云。

Then you can train a network that operates a deformation on those point clouds and produces new shapes such that they match the actual image appearance. Now the interesting thing about this is that this approach is pre-informed about the organ shape and does only slight changes to the organ in order to match the current image. This allows us to produce very fast and very accurate organ segmentation in interventional data. So, we train with regular CT data, but it will then also work on images that are done with a mobile C-arm or an angiography system that has a much lower image quality. These images are used in interventional settings for guidance purposes. We can apply our method in let’s say 0.3 to 2.6 seconds and this is approximately 50 to 100 times faster than a conventional U-Net approach where you do full 3-D processing.
然后,您可以训练一个网络,该网络在这些点云上进行变形并生成新形状,以使其与实际图像外观匹配。 现在,有趣的是,此方法已预先了解了器官的形状,并且仅对器官进行了微小的更改以匹配当前图像。 这使我们能够在介入数据中产生非常快速和非常准确的器官分割。 因此,我们使用常规的CT数据进行训练,但是它也将在使用移动C臂或血管造影系统(其图像质量要低得多)完成的图像上工作。 这些图像用于介入设置中以进行指导。 我们可以在0.3到2.6秒的时间内应用我们的方法,这比执行完整3D处理的传统U-Net方法快约50到100倍。

So, next time in deep learning we will talk a bit about not just the successes, but also the limitations of deep learning. Furthermore, we also want to discuss a couple of future directions that may help to reduce these limitations. So, thank you very much for watching and hope to see you in the next video.
因此,下一次在深度学习中,我们将不仅讨论成功的方面,还讨论深度学习的局限性。 此外,我们还希望讨论一些将来的方向,这些方向可能有助于减少这些限制。 因此,非常感谢您的收看,并希望在下一个视频中见到您。
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep Learning Lecture. I would also appreciate a clap or a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
如果你喜欢这篇文章,你可以找到这里更多的文章 ,更多的教育材料,机器学习在这里 ,或看看我们的深入 学习 讲座 。 如果您想在以后了解更多文章,视频和研究信息,也欢迎在YouTube , Twitter , Facebook或LinkedIn上进行拍手或追随。 本文是根据知识共享4.0署名许可发布的 ,如果引用,可以重新打印和修改。
翻译自: https://towardsdatascience.com/lecture-notes-in-deep-learning-introduction-part-2-acabbb3ad22
深度学习数学基础 讲义















 3195
3195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









