





马斯克神经网络转换器
介绍 (Introduction)
The need to reduce the complexity of a model can arise from multiple factors, often to reduce the computational requirements. However, complexity can’t be arbitrarily reduced because, after many iterations of training and testing, that’s the one model that provided good results. Research on this topic is active, e.g. [Koning et al., 2019] propose a solution to this same problem for CNNs used for exoplanet detection:
降低模型复杂性的需求可能来自多种因素,通常是为了减少计算需求。 但是,复杂度不能任意降低,因为经过多次反复的训练和测试,这就是提供良好结果的一种模型。 关于该主题的研究很活跃,例如,[Koning et al。,2019]针对用于系外行星检测的CNN提出了针对同一问题的解决方案:
Convolutional Neural Networks (CNNs) suffer from having too many trainable parameters, impacting computational performance … We propose and examine two methods for complexity reduction in AstroNet … The first method makes only a tactical reduction of layers in AstroNet while the second method also modifies the original input data by means of a Gaussian pyramid
卷积神经网络(CNN)的可训练参数太多,影响了计算性能…我们提出并研究了两种降低AstroNet复杂度的方法…第一种方法仅战术上减少了AstroNet中的层数,而第二种方法还修改了原始方法通过高斯金字塔输入数据
The second method (modifying or transforming the input data) is common. According to Google’s Crash Course on Machine Learning, transformations are done primarily for two reasons:
第二种方法(修改或转换输入数据)很常见。 根据Google的机器学习速成课程 ,进行转换主要有两个原因 :
Mandatory transformations: it makes the data compatible with the algorithms, e.g. converting non-numeric features into numeric.
强制转换 :它使数据与算法兼容,例如将非数字特征转换为数字。
Quality transformations: it helps the model perform better, e.g. normalizing numeric features.
质量转换 :它可以帮助模型更好地执行,例如规范数值特征。
The kind of transformation proposed by [Koning et al., 2019], and the one proposed in this article, fit in the second category.
[Koning et al。,2019]提出的一种转换类型以及本文提出的一种转换类型,属于第二类。
目的 (Objective)
I present a linear data transformation for the Poker Hand dataset [Cattral et al., 2007] and show how this transformation helps reduce the model complexity for a Multi-layer Perceptron (MLP) Neural Network while maintaining the classifier’s accuracy and reducing the training time up to 50%. The Poker Hand dataset is publicly available and very well-documented at the UCI Machine Learning Repository [Dua et al., 2019].
我介绍了扑克手数据集的线性数据转换[Cattral et al。,2007],并展示了这种转换如何帮助降低多层感知器 (MLP)神经网络的模型复杂性,同时保持分类器的准确性并减少了训练时间高达50%。 扑克之手数据集已公开提供,并且在UCI机器学习存储库中有很好的文档记录[Dua等,2019]。
In a previous story, I talked about the Poker hand dataset. A 3-layers MLP performed relatively well. Today, I show that it is possible to achieve equivalent accuracy with a less complex model by understanding the data we’re working with and transforming it to make it more appropriate for the problem we’re trying to solve.
在前面的故事中,我谈到了扑克手数据集。 3层MLP表现相对较好。 今天,我展示了通过了解我们正在使用的数据并对其进行转换以使其更适合于我们要解决的问题,可以用一个不太复杂的模型来达到等效的准确性。
数据集描述 (Dataset description)
This particular dataset is very human-friendly. It uses 11-dimensional description of poker hands by explicitly listing the suite and rank of each card, and the associated poker hand. Each data instance contains 5 cards.
这个特定的数据集非常人性化。 通过明确列出每张纸牌的套件和等级以及相关的扑克手,它使用了11维的扑克手描述。 每个数据实例包含5张卡。
Encoding
编码方式
The following is the dataset encoding description. For details follow this link.
以下是数据集编码说明。 有关详细信息,请单击此链接 。
Suite: 1: Hearts, 2: Spades, 3: Diamonds, 4: ClubsRank: 1: Ace, 2:2, …, 10: Ten, 11: Jack, 12: Queen, 13: KingHand: 0: Nothing 1: Pair 2: Two pairs, …, 8: Straight Flush 9: Royal Flush
套房 : 1 :心脏, 2 :锹, 3 :钻石, 4 :俱乐部等级 : 1 :ace, 2 :2,…, 10 : 10,11 :Jack, 12 :Queen, 13 :King Hand : 0 :无1 :对2 :两对,…, 8 :同花顺9 :皇家同花顺
Example
例
One encoding for the Royal Flush of Hearts (can have multiple representations using this model) is:Data: 1,1,1,10,1,11,1,12,1,13,9Interpretation: Hearts-Ace, Hearts-Ten, Hearts-Jack, Hearts-Queen, Hearts-King, Royal-Flush
皇家同花顺的一种编码(使用该模型可以有多种表示形式)是: 数据 :1,1,1,10,1,11,1,12,1,13,9 解释 :Hearts-Ace,Hearts-十,Hearts-Jack,Hearts-Queen,Hearts-King,皇家同花顺

转型 (Transformation)
The transformation is based in the fact that the order in which the cards appear (in a hand) doesn’t matter (to classify the hand), and that a more important attribute for classifying a hand is the number of cards (i.e. cardinality) with the same rank or suite that appear in the hand. The original dataset model gives an artificial importance to the order in which the cards appear (samples are ordered lists of 5 cards) and it does not explicitly encode the cardinality of each suite or rank. The premise is that by making this attribute explicitly available in the data, a Neural Network is able to better classify the dataset, in comparison to the same Neural Network when using the original model in which the attribute is hidden.
转换基于以下事实:牌(在手中)的出现顺序无关紧要(对手进行分类),而对手进行分类的更重要的属性是牌数(即基数)与手中出现的等级或套件相同。 原始数据集模型人为地重视纸牌的出现顺序(样本是5张纸牌的有序列表),并且未明确编码每个套件或等级的基数。 前提是,与使用隐藏属性的原始模型时,同一个神经网络相比,通过使该属性在数据中显式可用,神经网络可以更好地对数据集进行分类。
Linear transformation
线性变换
The following is a linear transformation from the original 11D space to a new 18D space. A linear transformation is preferable due to its reduced computational requirements. The new dimensions and descriptions are:
以下是从原始11D空间到新18D空间的线性变换 。 线性变换是优选的,因为其减少了计算需求。 新的尺寸和说明为:
Attributes 1 through 13: The 13 ranks, i.e. 1: Ace, 2: Two, 3: Three, …, 10: Ten, 11: Jack, 12: Queen, 13: King. Attributes 14 through 17: The 4 suites, i.e. 14: Hearts, 15: Spades, 16: Diamonds, 17: Clubs Domain: [0–5]. Each dimension represents the rank or suite cardinality in the hand. Last dimension: Poker hand [0–9] (unchanged).
属性1到13:13个等级,即1:王牌,2:2、3:3,…,10:10、11:杰克,12:女王,13:国王。 属性14到17: 4个套间,即14:红心,15:黑桃,16:钻石,17:俱乐部域 :[0-5]。 每个维度代表手中的等级或套房基数。 最后尺寸 :扑克手[0–9](不变)。
Encoding and example
编码与范例
The following is an example transformation for the Royal Flush of Hearts.
以下是皇家同花顺的示例转换。
Representation in original dimensions (11D):
以原始尺寸表示(11D):
Data: 1,1,1,10,1,11,1,12,1,13,9Encodes: Hearts-Ace, Hearts-Ten, Hearts-Jack, Hearts-Queen, Hearts-King, Royal-Flush
数据 :1,1,1,10,1,11,1,12,1,13,9 编码 :Hearts-Ace,Hearts-Ten,Hearts-Jack,Hearts-Queen,Hearts-King,Royal-Flush
Representation in new dimensions (18D):
以新尺寸表示(18D):
Data: 1,0,0,0,0,0,0,0,0,1,1,1,1,5,0,0,0,9Encodes: 1st column = 1 Ace, 2nd through 9th column = nothing (no cards with that suite), 10th through 13th columns = 1 Ten, 1 Jack, 1 Queen and 1 King, 14th column = 5 Hearts, 15th through 17th columns = nothing (no cards with that suite) and 18th column = Royal Flush.
数据 : 1,0,0,0,0,0,0,0,0,1,1,1,1,5,0,0,0,9 编码 :第1列= 1 Ace ,第2至9列=什么都没有(没有该套房的卡片),第10列至第13列= 1张十张 , 1张杰克 , 1张女王和1张国王 ,第14列= 5心 ,第15列至第17列=什么(没有该套房的卡片)和第18列= 皇家冲洗 。
The following image shows the visual transformation for this particular example.
下图显示了此特定示例的视觉转换。
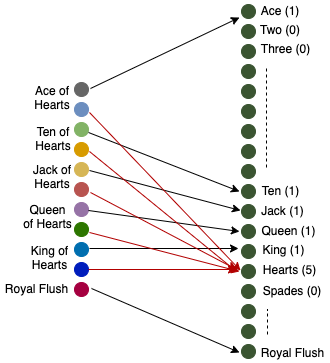
The new model represents any given a combination of 5 cards the same way regardless of order and explicitly exposes information useful for Poker hands such as the number of cards of the same Rank.
新模型以相同的方式表示任何给定的5张牌组合,无论顺序如何,并明确公开了对扑克手有用的信息,例如,相同等级的牌数。
工具类 (Tools)
Scikit-learn, Numpy and Seaborn are used for the Machine Learning, Data Processing and Visualization, respectively.
Scikit-learn , Numpy和Seaborn分别用于机器学习,数据处理和可视化。
代码在哪里? (Where is the code?)
A Jupyter notebook with the MLP, visualization and the linear transformation is here. The Classification Report and Confusion Matrix for each experiment are included in the Jupyter notebook too.
带有MLP,可视化和线性变换的Jupyter笔记本在这里 。 Jupyter笔记本中还包含每个实验的分类报告和混淆矩阵 。
结果 (Results)
In my previous story, I showed that a MLP with 3 hidden layers of 100 neurons each, with alpha=0.0001 and learning rate=0.01 using the original dataset, achieves an ~78% accuracy. These hyper-parameters were found after running an extensive grid-search over a wide range of values. So, the following measurements will be made based on these same values.
在我之前的故事中,我展示了一个MLP,该MLP具有3个隐藏的层,每个层都有100个神经元 ,使用原始数据集时, alpha = 0.0001 , 学习率= 0.01 达到〜78%的精度 。 这些超参数是在对广泛的值进行广泛的网格搜索之后发现的。 因此,将基于这些相同的值进行以下测量。
指标 (Metrics)
The MLP accuracy is measured with the F1 macro-average metric. This is an appropriate metric for the Poker hand dataset as it deals nicely with the fact that this dataset is extremely imbalanced. Scikit-learn’s documentation:
MLP准确性是使用F1 宏平均指标来衡量的。 这是扑克手数据集的适当指标,因为它很好地处理了该数据集极不平衡的事实。 Scikit-learn的文档 :
The F-measure can be interpreted as a weighted harmonic mean of the precision and recall … In problems where infrequent classes are nonetheless important, macro-averaging may be a means of highlighting their performance
F度量可以解释为精度和查全率的加权谐波均值…在仍然很少使用类别的问题中,宏平均可能是突出其性能的一种方式
The Classification Report is shown for the different experiments. It contains the macro-average F1 metric, among others.
分类报告 显示了不同的实验。 它包含宏观平均F1指标等。
In addition, the MLP training time is measured and reported.
此外,还测量并报告了MLP培训时间 。
3个具有原始数据的隐藏层MLP (3 hidden-layers MLP with original data)
Complexity: Each hidden-layer has 100 neurons.
复杂度 :每个隐藏层都有100个神经元。
Accuracy: For the 3-layers MLP and the original data (no transformation applied yet), a ~80% accuracy in the F1-score macro-average is obtained. Refer to the previous post for details on how this result was achieved.
精度 :对于3层MLP和原始数据(尚未应用任何转换),F1分数宏平均精度约为〜80% 。 有关如何获得此结果的详细信息,请参阅上一篇文章。
Training time: 20+ seconds
训练时间 :20+秒
Classification report
分类报告
precision recall f1-score support
0 1.00 0.99 0.99 501209
1 0.99 0.99 0.99 422498
2 0.96 1.00 0.98 47622
3 0.99 0.99 0.99 21121
4 0.85 0.64 0.73 3885
5 0.97 0.99 0.98 1996
6 0.77 0.98 0.86 1424
7 0.70 0.23 0.35 230
8 1.00 0.83 0.91 12
9 0.04 0.33 0.07 3
accuracy 0.99 1000000
macro avg 0.83 0.80 0.78 1000000
weighted avg 0.99 0.99 0.99 10000002个具有转换数据的隐藏层MLP (2 hidden-layers MLP with transformed data)
In this experiment, the model complexity is reduced by dropping one hidden-layer of 100 neurons, and the transformed (18D) data is being used. Everything else remains identical.
在此实验中,通过删除100个神经元的一个隐藏层来降低模型的复杂性,并使用转换后的(18D)数据。 其他所有内容都相同。
Accuracy: For the 2-layer MLP with the transformed data, it can be observed that ~85% accuracy is obtained.
精度:对于具有转换数据的2层MLP,可以观察到获得〜85%的精度 。
Training time: 10–15 seconds
训练时间 :10-15秒
precision recall f1-score support 0 1.00 1.00 1.00 501209
1 1.00 1.00 1.00 422498
2 1.00 1.00 1.00 47622
3 0.97 1.00 0.98 21121
4 1.00 0.99 1.00 3885
5 1.00 0.98 0.99 1996
6 0.83 0.48 0.61 1424
7 1.00 0.41 0.58 230
8 0.38 0.75 0.50 12
9 0.50 1.00 0.67 3 accuracy 1.00 1000000 macro avg 0.87 0.86 0.83 1000000
weighted avg 1.00 1.00 1.00 10000001个具有转换后的原始数据的隐藏层MLP (1 hidden-layer MLP with transformed and original data)
Accuracy:With a single layer of 100 neurons, the MLP with the transformed data achieved ~70% accuracy. With the original dataset it achieved ~30% accuracy.
准确性:通过单层100个神经元,具有转换数据的MLP达到了约70%的准确性 。 使用原始数据集,它可以达到〜30%的准确性 。
Training time:~10 seconds for the transformed dataset, ~12 seconds with the original data.
训练时间 :转换后的数据集约10秒,原始数据约12秒。
其他实验 (Other experiments)
Feel free to take a look at the Jupyter notebook that has the code and results for these and other experiments.
随时查看Jupyter笔记本 ,其中提供了这些实验和其他实验的代码和结果。
结论 (Conclusions)
By applying a simple linear transformation that makes the dataset less human-friendly but more ML-friendly, I show that a simpler MLP model provides equivalent results in less computational time. Specifically, a hidden-layer of 100 neurons is removed without compromising the performance of the classifier. The results show that the Neural Network accuracy is similar or better than the one achieved by the more complex model, and the training time is reduced by 25% to 50%.
通过应用一个简单的线性变换,该变换使数据集对人类的友好程度降低,但对ML的友好程度越来越高,我证明了更简单的MLP模型可以在更少的计算时间内提供等效的结果。 具体而言,在不影响分类器性能的情况下,删除了100个神经元的隐藏层。 结果表明,神经网络的准确性与更复杂的模型所达到的准确性相近或更好,并且训练时间减少了25%至50%。
马斯克神经网络转换器















 2448
2448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









