






首先,视觉定位指估计拍摄一幅图像时相机的位姿,这可以是六自由度、三自由度或者两自由度的位姿,要想获得准确的位姿估计结果,一般都需要一个地图先验,发展研究至今,出现了许许多多的地图形式,这包括传统的点云地图(稀疏/稠密)、压缩后的点云地图、Mesh地图、CAD地图、线地图、神经网络隐式表征的地图、平面图、无地图等等各种形式地图,所以最近一直在思考什么样的地图形式对于视觉定位来说才是最好的最优的呢?
地图分类:

对各种地图形式的分析:
点云地图:
首先是点云地图,这是目前视觉定位中最常见的一种地图形式,一般由SFM或者SLAM生成构造。
优点是:发展起步很早,各种相关算法都比较成熟,比如点的特征提取、匹配、对极几何、三角化、BA、PNP等等;所以以此为基础的视觉定位算法精度、鲁棒性都很高。
缺点是:由于点云地图中三维点数量庞大,其实相对于视觉定位任务来说是冗余的,所以其地图的存储消耗比较大,计算效率往往不高,这限制了在移动端的应用部署。
相关算法参考文献如下:
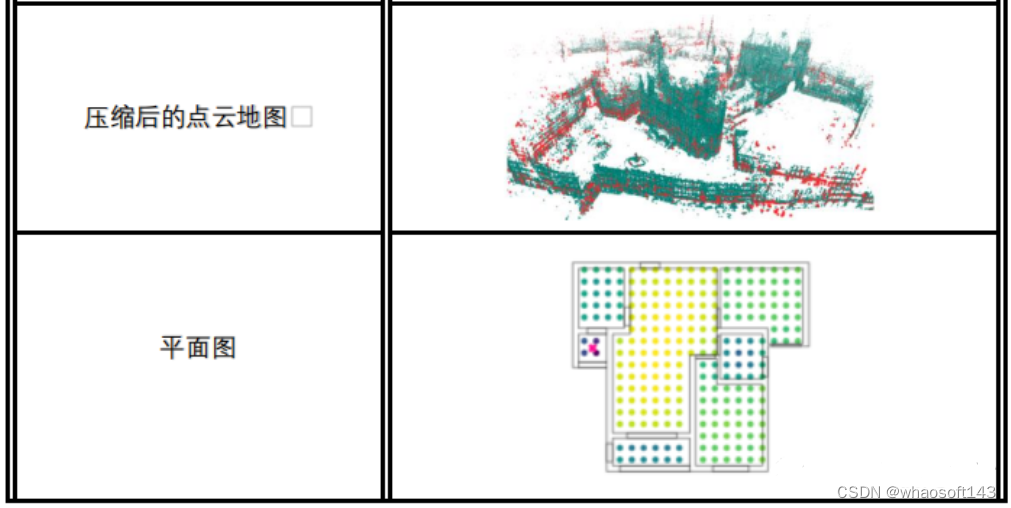
压缩后的点云地图:
由于点云地图存在的限制,基于压缩后的点云地图进行定位的算法被广泛研究,这类地图的最终目标就是为定位服务,即在最大限度压缩点云的同时精度不至于损失太多。
优点是:确实可以很大程度降低地图的内存大小
缺点是:定位精度往往与压缩量成负相关,很自然,越大的压缩量意味着越低的定位精度。从根本上说并没有摆脱点云地图的缺陷。
相关算法参考文献如下:
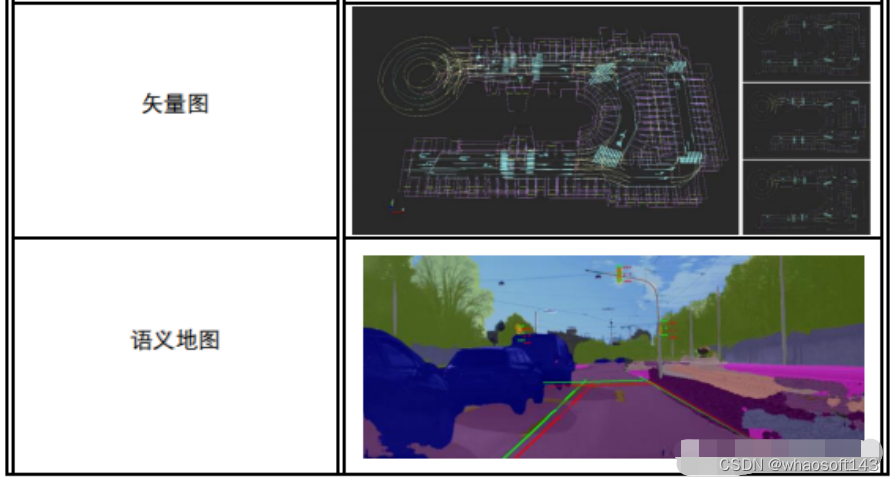
线地图:
通过提取图像中的线段构建3D线地图来执行后续的定位,主要针对点云地图存在的限制提出。线段在某些方面相比于点有诸多好处,比如在光照、环境变换下线段仍可以稳定检测到,其次线段固有的方向及其空间结构信息对定位来说如果利用得当会很有帮助,此外,线地图中3D线段相比于点云地图来说会更少,所占用的内存空间更低。
优点是:轻量紧凑,富含空间中场景结构化信息。
缺点是:只能在人造环境,即建筑物线条丰富的地方执行,目前来看,其精度相比点云地图有待提高。
相关算法参考文献如下:
平面图:
场景的平面图在我们日常生活中其实是很常见的,比如我们在逛商场时或者浏览某个景点时,在入口处都可以看到关于这个场景的二维的平面图。
优点是:地图足够抽象,所以往往很轻很小,而且容易获得。
缺点是:由于信息不够丰富,定位精度往往不高。
相关算法参考文献如下:
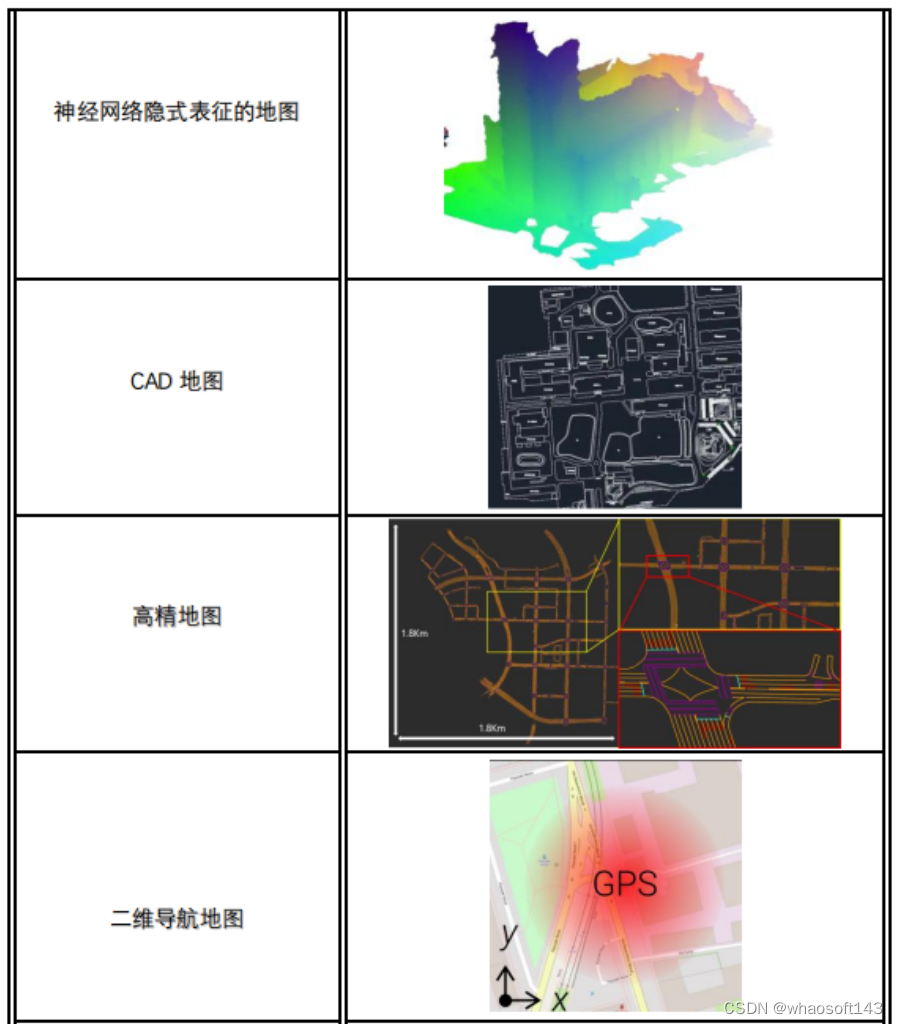
神经网络隐式表征的地图:
此类指代基于深度学习的视觉定位算法,比如通过网络直接回归查询图像的相机姿态信息或者通过网络密集预测查询图像像素的3D坐标,然后放在RANSAC-PNP loop中估计相机姿态。
优点是:通过网络隐式表征场景三维结构,省去了显式构建场景地图的开销。
缺点是:需要较高的硬件资源和大量的数据去训练网络,网络泛化问题,精度相比于点云地图还有差距。
相关算法参考文献如下:
高精地图:
这类地图多用在汽车上,多在自动驾驶场景中见到。
优点是:因为偏向于商业应用,定位精度一般很高。
缺点是:制作地图的成本很高,一般多由大公司搞了。
相关算法参考文献如下:
2D导航地图:
这种地图就是我们平时导航用的地图,比如百度地图、高德地图这些。
优点是:因为其地图也足够抽象,其地图内存占用也很小,而且这种地图形式更符合我们直观上的理解。
缺点是:估计的自由度不高,一般为两自由度。精度也有待提升。
相关算法参考文献如下:
总结
根据以上的分类,用于视觉定位的地图形式多种多样,到底哪一种最优,或者还有其他新颖的地图形式可以被使用?
个人认为:用于视觉定位的地图不用像点云地图那样冗余,即当地图足够抽象,而且对时间变化、环境变换又具有鲁棒性,同时地图中保留了足够的几何和语义信息可以与场景产生高质量的对应关系时,这种地图对于视觉定位来说是最有用的。而且目前视觉定位很多是应用在移动机器人、汽车、消费电子产品上,这类应用更多注重算法的效率、地图的轻量、鲁棒性、实用性、泛化性这些。
而且,从目前顶会顶刊视觉定位相关的研究论文来看,大方向也是朝着这方面发展,即研究基于新颖地图的视觉定位算法以适应各种生产生活需要。















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









