






UniTR是第一次针对3D感知的多模态Transformer Backbone,开创统一且一致的多模态3D编码与融合新方案 ,通向3D感知大模型的必由之路!UniTR:统一多模态Transformer Encoder!
针对3D感知的统一多模态transformer encoder
UniTR: A Unified and Efficient Multi-Modal Transformer for Bird's-Eye-View Representation
论文:https://arxiv.org/pdf/2308.07732.pdf
代码:https://github.com/Haiyang-W/UniTR
前置工作:高效的点云transformer encoder
DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
论文:https://arxiv.org/abs/2301.06051
代码:https://github.com/Haiyang-W/DSVT
本文为大家分享一篇ICCV2023中稿论文UniTR: 用于BEV表征的统一高效多模态Transformer Backbone。UniTR是第一次针对3D感知的多模态Transformer Backbone,开创统一且一致的多模态3D编码与融合新方案,为3D感知大模型打下坚实基础,引领新的设计潮流。
问题背景
通用的3D特征表示
随着人工智能的发展,人们对感知周围物理环境的需求越来越大,例如自动驾驶、虚拟增强现实和机器人等,都需要对周围的3D环境有很好的建模感知才能进行之后的决策。另一方面随着NLP领域快速发展,大模型的兴起正在革新人工智能各个领域的科研范式。似乎当有一个比较好的框架后,大部分数据都是data centric的,足够多的数据就可以模型有很好的泛化能力.
那么在3D Vision 领域呢?受到自然语言大模型的启发,越来越多的领域开始设计自己的foundation model。特别是3D vision领域,人们迫切需要一种框架范式能建模所有的3D视觉数据。但这并不是一个简单的事情,对于一个智能体来说,首先其需要接收各种模态的3D数据,例如2D多视角图像以及3D雷达点云,然后建模处理这些异构的数据并执行各种不同的任务。这里问题可以拆解成如下两个子问题:
- General Representation:如何处理不同传感器的异构感知数据并学到通用的特征表示。
- Unified Modeling: 基于得到的通用表示,如何统一各种任务框架。
本文侧重解决目前最关键的unified encoder这一步,这也是3D感知大模型的瓶颈所在,只有得到general representation才能进行接下来的unified modeling。
前人方法与问题
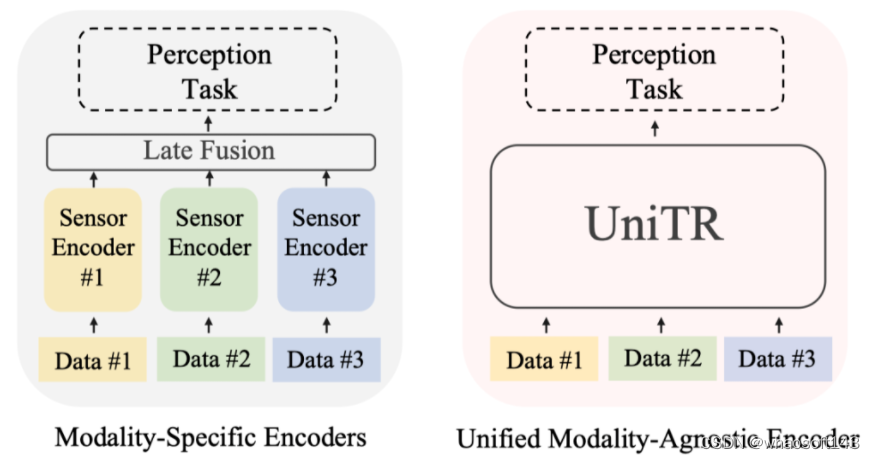
3D感知数据主要侧重多视角图像和雷达点云,这两种数据分布非常不一样,前者是2D Dense的图像,后者是3D稀疏的点云分布,用一种通用的框架处理挑战较大。之前的工作都是分别用各自领域的Encoder串行处理各自的模态,最后再用一个复杂耗时的后处理融合步骤得到通用的特征表示。这种方式大大拖慢的运行速度并且没有解决一个模型处理多种模态的需求。一种Unified Multi-Modal Encoder也可以对齐不同模态的信息,迫使网络学习到更本质的场景理解表示。
本文贡献
- 提出了一种用于各自模态内特征学习的Transformer Block,可以参数共享的并行处理不同模态的感知数据。
- 为了高效融合来自不同传感器的异构数据,我们设计了一个强大的跨模态Transformer Block,通过考虑2D透视和3D几何结构关系,实现了不同模态的高效融合。
- 借助以上设计,我们第一次针对3D感知提出真正意义上的统一多模态Transformer Backbone,用于处理各种模态数据。
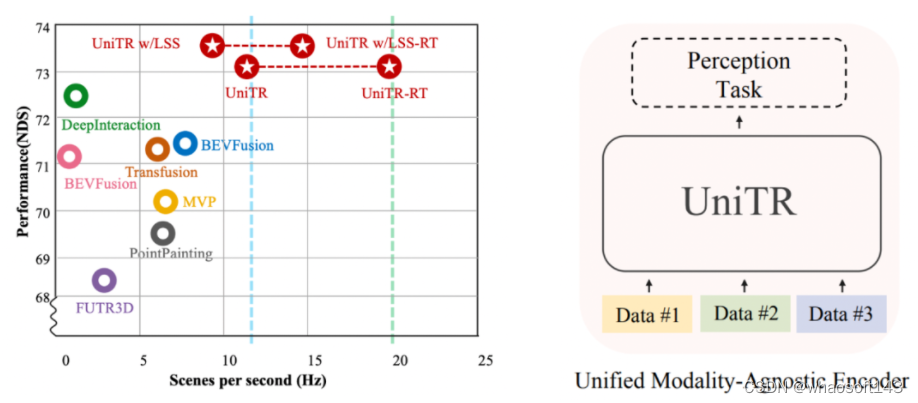
- UniTR在nuScenes多种3D感知任务的测试中取得了最好的性能,包括3D Object Detection(+1.1)和BEV Map Segmentation(+12.0),并且具有更低的延迟。
我们希望UniTR的出色性能和新颖结构可以作为一个强大且简单的baseline,促进3D Foundation Model和通用框架的发展。
预备知识:DSVT
3D感知主要关注多视角图像和激光雷达这两种模态数据,前者被广泛研究,2D image的技术可以被直接应用过来,但后者由于稀疏的数据特性,难以利用之前成熟的视觉技术。Transformer天然适合处理稀疏变长数据,并且适合针对不同模态灵活设计结构,但把Transformer用来处理大规模点云数据并不是一个简单的事情。我们首先回顾一下DSVT, CVPR2023的关于Efficient Point Cloud Transformer的工作。UniTR是在DSVT的基础上搭建的。
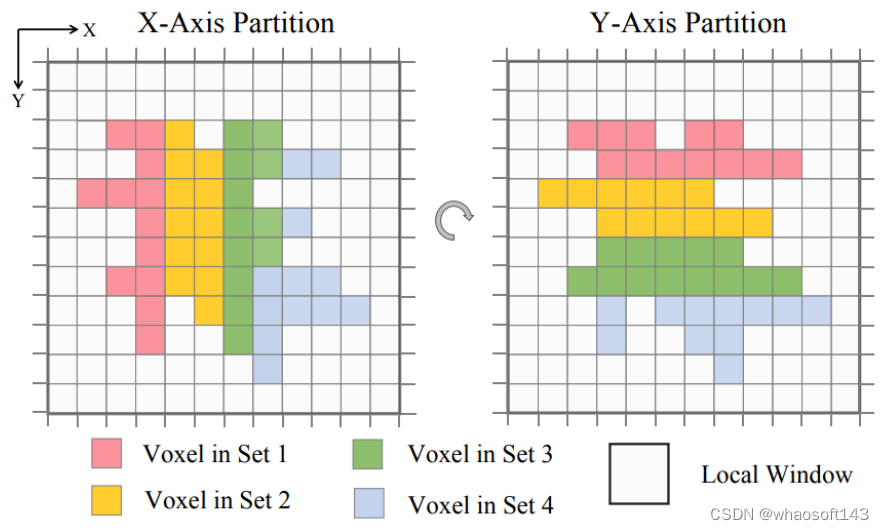
Dynamic Sparse Voxel Transformer (DSVT) 是一种用于从点云进行室外三维感知的window-based Transformer Backbone。为了以完全并行的方式高效处理稀疏数据,他们将标准window attention重新定义为在一系列window-bounded和size-equivalent 的local set内进行并行计算的自注意力策略。为了允许跨子集的交互,DSVT设计了一种旋转的子集划分策略,该策略在连续的注意力层之间交替使用两种切分配置,实现了不同set的体素在不同层之间交互。
通过这种方式,原始的sparse window attention将近似地重构为多个set attention,这些注意力计算可以在同一batch内并行处理。值得注意的是,DSVT 中使用的集合划分配置是通用的,可以灵活地适应不同的数据结构和模态。
UniTR的流程图
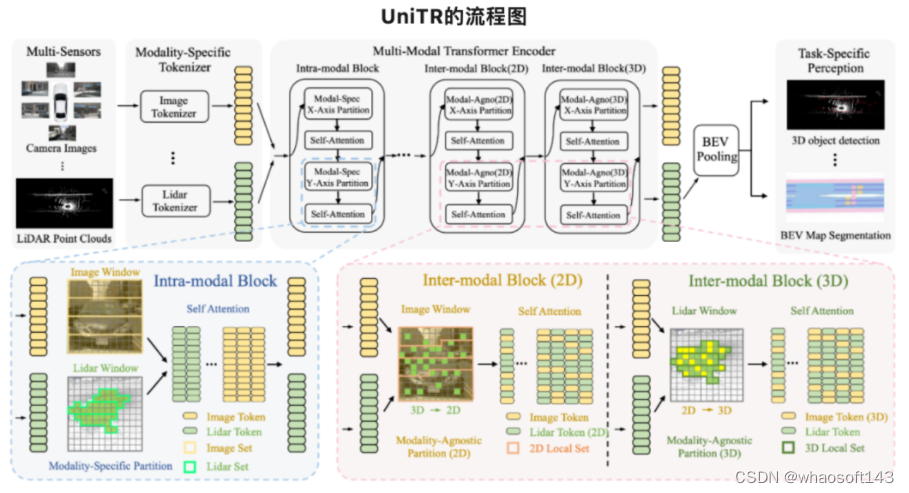
本节将描述我们的统一架构,用于处理各种不同的传感器模态(多视角摄像头和激光雷达)和任务(检测和分割)。上图展示了这一架构。在给定不同的传感器输入后,模型首先使用特定于模态的Tokenizer将不同模态输入转换成相应的Token Embeddings。然后,采用与模态无关的Transformer backbone来并行的执行单模态和跨模态表示学习,以用于各种下游三维感知任务。
单模态表示学习模块
在自动驾驶场景中感知三维场景需要可靠的多模态表示,例如多视角图像和稀疏点云。由于它们的不同表示方式,先前的方法通常通过单独的编码器对每种模态的特征进行编码,这些编码器一般按顺序处理,降低了推理速度,限制了它们在现实世界中的应用。为了解决这些问题,我们提出了使用统一架构并行处理每个传感器的模态内特征,其参数对所有模态共享。
- Tokenization
给定Images和Point Clouds后,每个模态对应的轻量的tokenizer会将输入的原始数据转换成对应的token embedding。这里对于image采用的是常用的image patch tokenizer,对于point clouds采用的是Dynamic Voxel Feature Encoding。
- 与模态有关的Set Attention
为了高效并行的学习各自模态内部的特征学习,我们在得到image和point clouds的tokens之后,

值得注意的是上述模块所有模态对应的计算参数都是共享的,并行的模态特征学习也比之前传统的串行方式快将近两倍,大大提升了推理速度。
多模态表示学习模块
为了有效地整合自动驾驶场景中来自多个传感器的视角不一致的信息,现有的方法通常涉及为每个传感器设计单独的encoder,并通过复杂的后处理方法融合信息,大大拖慢了运行的速率并且用多个分支,增加了训练难度。为了允许在encoder 前传过程中有效的跨模态交互并充分利用2D-3D互补的信息,我们设计了两种模态无关Transformer block。这两种block分别用于在2D image和3D Lidar space中不同模态的信息交互,并随着网络加深交替配置自动融合多模态数据。
- 图像透视空间
为了利用语义丰富的2D图像邻接关系,我们首先利用相机的内外参,将所有点云token投影到图像平面,并将它们放置在相应的2D位置如下:

这一步采用一种与模态无关的切分方式,根据在image space中的位置将多种模态的tokens分组到相同的2D local set中,然后这些混合模态的子集将由若干DSVT block进行跨模态交互。
- 三维几何空间
为了在三维空间中统一多模态输入,需要一个高效且稳健的视图投影,来将图像patch唯一地映射到3D space中。然而,由于与每个图像像素相关的深度具有不确定性,从2D到3D的变换是一个病态问题。尽管之前的可学习深度估计器可以预测出具有可接受精度的深度图像,但它们需要额外的计算密集型预测模块,并且通用性能较差。为了克服这些限制,受到MVP[2]的启发,我们提出了一种非可学习且可预先计算的方法,用于将图像patch高效地转换到3D space以用来后续的3D切分
首先,我们在3D space 采样生成一些伪点, 然后将所有虚拟伪点投影到2D image space生成它们相应的虚拟图像坐标。得到这些虚拟图像点后,我们可以从每个图像patch的最近图像虚拟邻居中检索深度估计,

考虑2D和3D的跨模态的Transformer Block被实验验证是有效的,能很好地利用语义丰富的2D邻接关系和几何意义丰富的3D邻接关系。另外,因为cross-modal和single-modal的transformer block都是以DSVT为基础,所以两者可以无损的结合在一起组成真正意义上的多模态3D网络。
实验结果
我们在室外多模态标准数据集NuScenes进行了一系列实验来验证模型的性能如下:
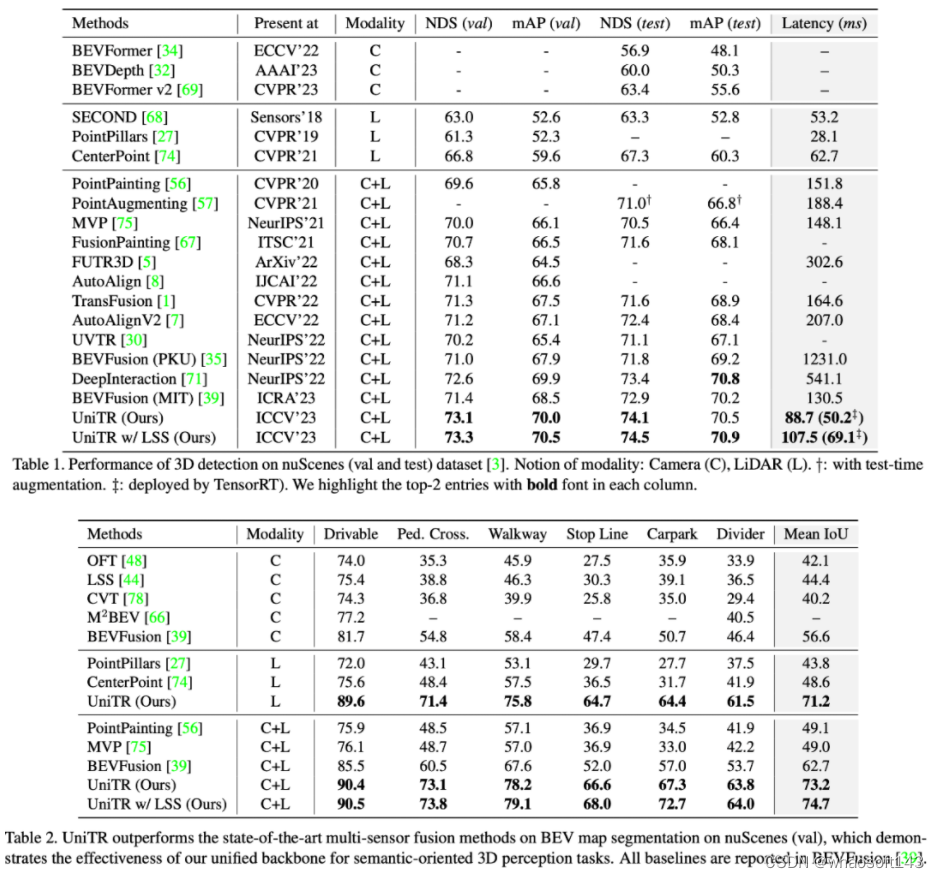
由图中所示,我们的模型在NuScenes上多个3D感知任务都表现很好,远超之前最好的方法。更多实验结果和分析请参考原文。
总结
在本论文中,我们第一次针对3D感知提出了一个统一的多模态Transformer backbone,用单一模型和共享参数处理不同模态的数据。通过专门设计的用于模态内和模态间的表示学习Transformer block,我们的方法在标准的nuScenes数据集上取得了多种3D感知任务的SOTA性能,获得了显著的提升。相信UniTR可以为促进更高效和通用的三维感知大模型的发展提供坚实的基础。















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









