









原文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_UniTR_A_Unified_and_Efficient_Multi-Modal_Transformer_for_Birds-Eye-View_Representation_ICCV_2023_paper.pdf
包含附录的版本:https://arxiv.org/pdf/2308.07732.pdf
1. 引言
本文提出UniTR,一种能并行处理3D点云与2D多视图图像、学习统一BEV表达的多模态Transformer主干。
目前的BEV感知方法均需要各模态特定的编码器,导致推断延迟。UniTR则是模态无关的编码器,能有效对齐多模态特征,生成通用表达。
Transformer用于相机-激光雷达数据时,会因二者视图差异而遭遇挑战,因此往往用于基于查询的后期融合。本文的UniTR无需额外的融合模块。

UniTR包含两类Transformer块,模态内块(各模态并行学习表达)和模态间块(通过考虑2D透视图和3D几何邻域关系进行跨模态特征交互)。
具体来说,首先使用轻量级token转换器(图像:2D卷积;点云:体素特征编码层)转化为统一的token序列,然后分成大小相同的局部集合,分给不同样本,通过模态无关的DSVT块(处理稀疏数据的、强大且灵活的Transformer结构)并行计算。通过充分利用GPU的并行计算能力和共享不同模态的权重,速度和性能均能得到提升。然后使用跨模态Transformer块进行融合,根据2D和3D的结构关系联系不同的模态(同样基于DSVT)。
3. DSVT回顾
动态稀疏体素Transformer(DSVT)是基于窗口的体素Transformer主干网络。DSVT将窗口注意力重新表示为窗口限制的、大小相同的子集的自注意力。还使用旋转集合分割策略,在连续的注意力层中改变分割配置,以实现跨集合连接。
动态集合分割:给定稀疏token和窗口分割,首先在窗口内根据稀疏性分割出一系列局部区域。设某窗口有
T
T
T个token(非空体素),
T
=
{
t
i
}
i
=
1
T
\mathcal{T}=\{t_i\}_{i=1}^T
T={ti}i=1T;
S
S
S是需求子集的数量,随窗口稀疏性动态变化。均匀将
T
T
T个token分散到
S
S
S个集合中,第
j
j
j个集合对应的token索引为
Q
j
=
{
q
k
j
}
k
=
0
τ
−
1
\mathcal{Q}_j=\{q_k^j\}_{k=0}^{\tau-1}
Qj={qkj}k=0τ−1。则整个过程表达为:
{
Q
j
}
j
=
0
S
=
DSP
(
T
,
L
×
W
×
H
,
τ
)
\{\mathcal{Q}_j\}_{j=0}^{S}=\text{DSP}(\mathcal{T},L\times W\times H,\tau)
{Qj}j=0S=DSP(T,L×W×H,τ)其中
L
×
W
×
H
L\times W\times H
L×W×H为窗口形状,
τ
\tau
τ为集合大小(与
T
T
T无关)。
得到
Q
j
\mathcal{Q}_j
Qj后,会基于窗口内预定义的ID
I
=
{
I
i
}
i
=
1
T
\mathcal{I}=\{I_i\}_{i=1}^{T}
I={Ii}i=1T收集相应的token特征和坐标:
F
j
,
C
j
=
INDEX
(
T
,
Q
j
,
I
)
\mathcal{F}_j,\mathcal{C}_j=\text{INDEX}(\mathcal{T},\mathcal{Q}_j,\mathcal{I})
Fj,Cj=INDEX(T,Qj,I)其中
INDEX
(
)
\text{INDEX}()
INDEX()表示索引操作,
F
j
∈
R
τ
×
C
,
C
j
∈
R
τ
×
3
\mathcal{F}_j\in\mathbb{R}^{\tau\times C},\mathcal{C}_j\in\mathbb{R}^{\tau\times 3}
Fj∈Rτ×C,Cj∈Rτ×3(3表示空间坐标
(
x
,
y
,
z
)
(x,y,z)
(x,y,z))。这样就得到了大小相同的、不重叠的子集,用于后续并行注意力计算。
旋转集合注意力:为建立上述不重叠集合间的关系,DSVT提出旋转集合注意力,在连续的注意力层交换空间旋转的分割配置:
F
l
,
C
l
=
INDEX
(
T
l
−
1
,
{
Q
j
}
j
=
0
S
−
1
,
I
x
)
,
T
l
=
MHSA
(
F
l
,
PE
(
C
l
)
)
,
F
l
+
1
,
C
l
+
1
=
INDEX
(
T
l
,
{
Q
j
}
j
=
0
S
−
1
,
I
y
)
,
T
l
+
1
=
MHSA
(
F
l
+
1
,
PE
(
C
l
+
1
)
)
\mathcal{F}^l,\mathcal{C}^l=\text{INDEX}(\mathcal{T}^{l-1},\{\mathcal{Q}_j\}_{j=0}^{S-1},\mathcal{I}_x),\\\mathcal{T}^{l}=\text{MHSA}(\mathcal{F}^l,\text{PE}(\mathcal{C}^l)),\\\mathcal{F}^{l+1},\mathcal{C}^{l+1}=\text{INDEX}(\mathcal{T}^{l},\{\mathcal{Q}_j\}_{j=0}^{S-1},\mathcal{I}_y),\\\mathcal{T}^{l+1}=\text{MHSA}(\mathcal{F}^{l+1},\text{PE}(\mathcal{C}^{l+1}))
Fl,Cl=INDEX(Tl−1,{Qj}j=0S−1,Ix),Tl=MHSA(Fl,PE(Cl)),Fl+1,Cl+1=INDEX(Tl,{Qj}j=0S−1,Iy),Tl+1=MHSA(Fl+1,PE(Cl+1))其中
I
x
\mathcal{I}_x
Ix和
I
y
\mathcal{I}_y
Iy是窗口内根据
x
x
x和
y
y
y坐标排序的体素索引。MHSA和PE表示多头自注意力和位置编码,
F
j
∈
R
S
×
τ
×
C
,
C
j
∈
R
S
×
τ
×
3
\mathcal{F}_j\in\mathbb{R}^{S\times \tau\times C},\mathcal{C}_j\in\mathbb{R}^{S\times\tau\times 3}
Fj∈RS×τ×C,Cj∈RS×τ×3。通过上述操作,原始的稀疏窗口注意力就近似表达为多个集合注意力,能在同一batch内并行处理。注意DSVT的集合分割配置可以适用于任意数据结构和模态。
DSVT论文中对旋转集合划分的图示。对每一个局部窗口,其中的非空体素会分别依照 x x x轴和 y y y轴进行分割( x x x轴分割就是从左上角开始纵向数非空体素的个数,每 τ \tau τ个非空体素划到一个集合中; y y y轴分割就是横向数),每个集合含 τ \tau τ个非空体素(图中 W = H = 12 , τ = 12 , S = 4 W=H=12,\tau=12,S=4 W=H=12,τ=12,S=4)。

4. 方法
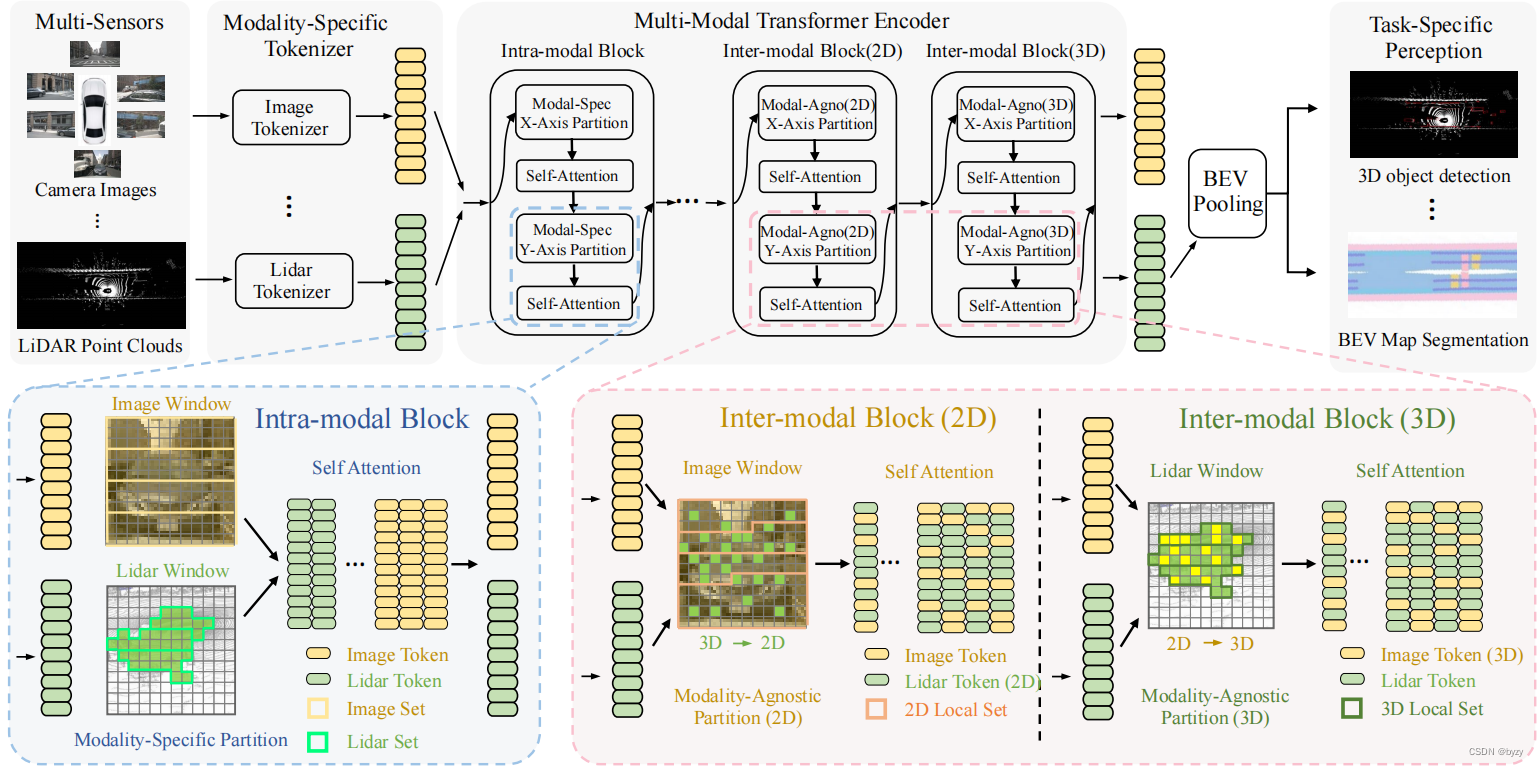
4.1 单一模态表达学习
首先使用token转换器,将输入转化为token序列,然后使用共享参数的DSVT块并行编码模态特征。
Token化:使用图像patch token转换器处理
B
B
B个相机的图像
X
I
X^I
XI,动态体素特征编码token转换器处理激光雷达点云
X
P
X^P
XP。后续的模态内编码器的输入序列
T
∈
R
(
M
+
N
)
×
C
\mathcal{T}\in\mathbb{R}^{(M+N)\times C}
T∈R(M+N)×C由
N
N
N个点云token
T
P
∈
R
N
×
C
\mathcal{T}^P\in\mathbb{R}^{N\times C}
TP∈RN×C和
M
M
M个图像token
T
I
∈
R
M
×
C
\mathcal{T}^I\in\mathbb{R}^{M\times C}
TI∈RM×C组成。
特定模态的集合注意力:为高效并行处理模态内表达的学习,首先对每个传感器分布进行动态集合划分。
给定一个场景下激光雷达与图像的token
T
P
=
{
t
i
P
∣
t
i
P
=
[
(
x
i
P
,
y
i
P
,
z
i
P
)
;
f
i
P
]
}
i
=
1
N
,
T
I
=
{
t
i
I
∣
t
i
I
=
[
(
x
i
I
,
y
i
I
,
b
i
I
)
;
f
i
I
]
}
i
=
1
M
\mathcal{T}^P=\{t_i^P|t_i^P=[(x_i^P,y_i^P,z_i^P);f_i^P]\}_{i=1}^N,\\\mathcal{T}^I=\{t_i^I|t_i^I=[(x_i^I,y_i^I,b_i^I);f_i^I]\}_{i=1}^M
TP={tiP∣tiP=[(xiP,yiP,ziP);fiP]}i=1N,TI={tiI∣tiI=[(xiI,yiI,biI);fiI]}i=1M其中
(
x
i
,
y
i
,
z
i
)
(x_i,y_i,z_i)
(xi,yi,zi)与
f
i
∈
R
C
f_i\in\mathbb{R}^{C}
fi∈RC表示token的坐标与特征,
b
i
I
∈
{
0
,
1
,
⋯
,
B
−
1
}
b_i^I\in\{0,1,\cdots,B-1\}
biI∈{0,1,⋯,B−1}表示所属视图ID。按下式计算局部集合在模态空间内的token索引:
{
Q
n
P
}
n
=
0
N
=
DSP
(
T
P
,
L
P
×
W
P
×
H
P
,
τ
)
,
{
Q
m
I
}
n
=
0
M
=
DSP
(
T
I
,
L
I
×
W
I
×
1
,
τ
)
\{\mathcal{Q}_n^P\}_{n=0}^\mathcal{N}=\text{DSP}(\mathcal{T}^P,L^P\times W^P\times H^P,\tau),\\\{\mathcal{Q}_m^I\}_{n=0}^\mathcal{M}=\text{DSP}(\mathcal{T}^I,L^I\times W^I\times 1,\tau)
{QnP}n=0N=DSP(TP,LP×WP×HP,τ),{QmI}n=0M=DSP(TI,LI×WI×1,τ)其中
N
\mathcal{N}
N与
M
\mathcal{M}
M分别为激光雷达和图像划分子集的数量。
给定划分结果
{
Q
n
P
}
n
=
0
N
\{\mathcal{Q}_n^P\}_{n=0}^\mathcal{N}
{QnP}n=0N与
{
Q
m
I
}
n
=
0
M
\{\mathcal{Q}_m^I\}_{n=0}^\mathcal{M}
{QmI}n=0M,收集每个集合的token特征和坐标,并为各模态进行并行注意力计算:
F
l
,
C
l
=
INDEX
(
[
T
l
−
1
P
,
T
l
−
1
I
]
,
[
{
Q
n
P
}
n
=
0
N
,
{
Q
m
I
}
n
=
0
M
]
)
,
T
~
l
P
,
T
~
l
I
=
MHSA
(
F
l
,
PE
(
C
l
)
)
\mathcal{F}_l,\mathcal{C}_l=\text{INDEX}([\mathcal{T}_{l-1}^P,\mathcal{T}_{l-1}^I],[\{\mathcal{Q}_n^P\}_{n=0}^\mathcal{N},\{\mathcal{Q}_m^I\}_{n=0}^\mathcal{M}]),\\\tilde{\mathcal{T}}_{l}^P,\tilde{\mathcal{T}}_{l}^I=\text{MHSA}(\mathcal{F}_l,\text{PE}(\mathcal{C}_l))
Fl,Cl=INDEX([Tl−1P,Tl−1I],[{QnP}n=0N,{QmI}n=0M]),T~lP,T~lI=MHSA(Fl,PE(Cl))其中
F
∈
R
(
M
+
N
)
×
τ
×
C
,
C
∈
R
(
M
+
N
)
×
τ
×
3
\mathcal{F}\in\mathbb{R}^{(\mathcal{M}+\mathcal{N})\times \tau\times C},\mathcal{C}\in\mathbb{R}^{(\mathcal{M}+\mathcal{N})\times\tau\times 3}
F∈R(M+N)×τ×C,C∈R(M+N)×τ×3;各模态自注意力权重是共享的。
4.2 跨模态表达学习
图像透视空间:使用相机内外参将激光雷达token转换到图像平面。为建立一对一的投影,仅选择3D激光雷达token的第一视图投影,并取其投影得到的2D位置:
T
P
→
T
2
D
P
:
(
x
P
,
y
P
,
z
P
)
→
(
x
2
D
P
,
y
2
D
P
,
b
2
D
P
)
\mathcal{T}^P\rightarrow\mathcal{T}^P_{2D}:(x^P,y^P,z^P)\rightarrow(x_{2D}^P,y_{2D}^P,b_{2D}^P)
TP→T2DP:(xP,yP,zP)→(x2DP,y2DP,b2DP)
然后使用传统的动态集合划分生成
M
~
\tilde{\mathcal{M}}
M~个跨模态2D局部集合:
{
Q
m
2
D
}
m
=
0
M
~
=
DSP
(
[
T
2
D
P
,
T
I
]
,
L
I
×
W
I
×
1
,
τ
)
\{\mathcal{Q}_m^{2D}\}_{m=0}^{\tilde{\mathcal{M}}}=\text{DSP}([\mathcal{T}^P_{2D},\mathcal{T}^I],L^I\times W^I\times 1,\tau)
{Qm2D}m=0M~=DSP([T2DP,TI],LI×WI×1,τ)并使用DSVT处理子集,进行2D跨模态交互。
3D几何空间:使用高效鲁棒的视图投影将图像patch映射到3D空间。本文使用非学习、预先可计算的方法进行2D到3D的转换。
首先预定义3D网格点
V
P
∈
R
L
S
×
W
S
×
H
S
×
3
\mathcal{V}^P\in\mathbb{R}^{L^S\times W^S\times H^S\times3}
VP∈RLS×WS×HS×3,然后投影得到到相应的图像坐标
V
I
=
{
v
k
∣
(
x
k
,
y
k
)
;
b
k
;
d
k
}
k
=
0
ν
\mathcal{V}^I=\{v_k|(x_k,y_k);b_k;d_k\}_{k=0}^\nu
VI={vk∣(xk,yk);bk;dk}k=0ν,其中
d
k
d_k
dk为深度值。此处仅考虑能投影到图像内的点。
然后对每一个投影点,检索图像内最近的图像token(设距离为
l
l
l),将投影点的深度视为图像token的深度后,将图像token反投影到3D空间:
T
I
→
T
3
D
I
:
(
x
I
,
y
I
,
b
I
)
→
(
x
3
D
I
,
y
3
D
I
,
z
3
D
I
)
\mathcal{T}^I\rightarrow\mathcal{T}^I_{3D}:(x^I,y^I,b^I)\rightarrow(x_{3D}^I,y_{3D}^I,z_{3D}^I)
TI→T3DI:(xI,yI,bI)→(x3DI,y3DI,z3DI)并根据距离
l
l
l生成偏移特征:
f
I
→
f
I
+
MLP
(
l
)
f^I\rightarrow f^I+\text{MLP}(l)
fI→fI+MLP(l)。使用动态集合划分模块得到3D跨模态局部集合:
{
Q
n
3
D
}
n
=
0
N
~
=
DSP
(
[
T
P
,
T
3
D
I
]
,
L
P
×
W
P
×
H
P
,
τ
)
\{\mathcal{Q}_n^{3D}\}_{n=0}^{\tilde{\mathcal{N}}}=\text{DSP}([\mathcal{T}^P,\mathcal{T}^I_{3D}],L^P\times W^P\times H^P,\tau)
{Qn3D}n=0N~=DSP([TP,T3DI],LP×WP×HP,τ)并使用DSVT在3D激光雷达空间中进行跨模态交互。
4.3 感知任务设置
将BEVFusion的主干和融合模块替换为本文的UniTR主干,分别进行3D检测与分割任务。
5. 实验
5.2 3D目标检测
UniTR能达到SotA性能,且有更快的推断时间。引入BEVFusion中基于LSS的BEV融合可以进一步提高性能。使用部署工具(如TensorRT)之后,可以达到接近实时运行的水平。
5.3 BEV地图分割
本文的方法能性能能大幅超过BEVFusion。
5.4 消融研究
2D&3D融合的影响:在保证Transformer块总数不变的情况下,与激光雷达单一模态方法相比,仅使用2D跨模态表达学习和仅使用3D跨模态表达学习均能显著提高性能。同时使用两者能进一步提高性能。这表明语义丰富的2D透视图和几何丰富的3D视图是提高3D感知性能的两个互补空间。
并行的模态内Transformer块的影响:为评估模态内编码器的权重共享有效性,本文去掉2D与3D融合算法,仅保留最后的晚期融合模块,并将主干网络限制在仅进行模态内表达学习。实验表明,权重共享的并行主干会比上述顺序主干有略高的性能,但推断时间大幅减少。这说明统一编码器能自然对齐不同模态的表达,更容易克服模态间隙、学到通用表达。
不同块配置的影响:若先进行模态间交互,再进行模态内交互,性能较差,因为浅层特征的融合会遇到挑战。若先进行3D交互,再进行2D交互,也会略微影响性能,这可能是3D感知需要最后一个模块在3D空间中融合特征。
5.5 对传感器失效的鲁棒性
当相机图像丢失或卡帧、以及激光雷达检测到的物体点云丢失时,UniTR的性能均能超过其余方法,表明了UniTR的鲁棒性。使用低线数激光雷达与图像融合时,本文的统一建模能更好地利用多模态的互补信息,从而有最好的性能。
附录
A. 实施细节
token转换器:对于图像,类似ViT的方法将其划分为不重叠的patch,每个patch被视为一个token,其特征是所有像素的RGB值拼接(即若一个patch包含 K K K个像素,则token的特征维度为 3 K 3K 3K)。使用线性层进一步转换特征维度为 C C C。
B. 对传感器失效的鲁棒性
当测试时激光雷达检测到的物体点云丢失,若模型经过相应的鲁棒增广微调训练,UniTR的性能能大幅超越BEVFusion。


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











