






本文基于 huggingface 源码,对 RLHF 的实现过程做一个比较通俗的讲解。
一、RLHF基础知识
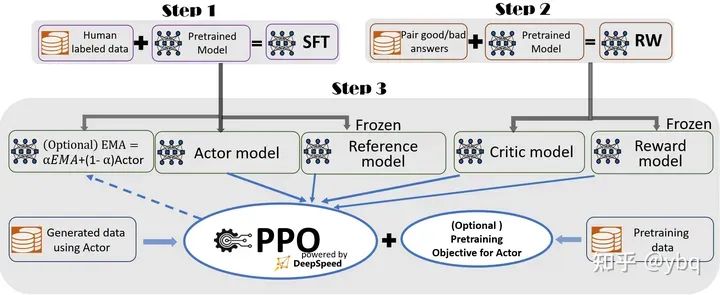
RLHF的核心就是4个模型之间的交互过程
- Actor model:传统的语言模型,最后一层网络是 nn.Linear(hidden_size, vocab_size)
- Reference model(不参与训练):Actor_model的一个复制
- Reward model(不参与训练):
- 将传统语言模型的最后一层网络,由 nn.Linear(hidden_size, vocab_size) 替换成 nn.Linear(hidden_size, 1),也就是说该模型输出的是当前token的得分,而不是对下一个token的预测
- 输入是prompt + answer, 输出是answer中每个token对应的值,answer中最后一个token对应的值即为这条语料的reward
- Critic model:Reward_model 的一个复制
二、强化学习基础知识

很多NLP出身的同学,经常会因为强化学习的基础概念模糊,导致长期对 RLHF 一知半解,这里我用几个例子来做帮助大家更好的认知。
- 大模型生成完整answer的过程,视为PPO的一次完整的交互,reward_model的打分便是这次交互的reward;
- 大模型每生成一个token,视为PPO中的一步;
- 假设一个汉字等价为一个token。
prompt:中国的首都是哪里?answer:首都是南京
- Reward = Reward_model(‘首都是南京’),如果我们有一个较好的reward_model,这里大概率会输出一个负数,例如-10;
- Q(2, ‘是’) = Q(‘首都’,‘是’) ,意思是在’首都’这个state下,下一步action选择’是’这个token,所能获得的reward,显然这会是一个较大的值;
- V(4) = V(‘首都是南’),意思是在’首都是南’这个state下,能获得的reward,显然这会是一个较小的值。
上面的例子也告诉我们,语言模型的reward,只有看到结束才能确定。有时候一个token预测错误,整个句子的reward都不会很大。
三、RLHF完整流程
有了RLHF 和 RL 的基础知识后,我们来介绍每个模型的作用:
- Reward_model 负责给 LLM 生成的句子打分
- Actor_model 就是我们要优化的 LLM
- Critic_model 负责计算Actor_model的状态动作值矩阵,也就是上面提到的Q函数(Reward模型只负责给最后一个token打分,给之前token打分的重任靠Critic_model 完成)
- Reference_model 是一个标杆,为的是让我们的Actor_model在训练时不要偏离原始模型太远,保证其不会失去原本的说话能力
RLHF的第一个环节:让模型生成答案,并对其打分
- 给定 batch_size 条 prompt
- 调用actor_model生成answer,并进行token化,得到一个 B * L 的矩阵;
- reward_model 对answer进行打分,得到一个 B * 1 的矩阵;
- critic_model 对每个token进行打分,得到一个 B * L 的矩阵;
- actor_model 和 reference_model 对生成的句子进行一遍正向传播,保存output.logits,得到两个 B * L * V 的矩阵
- 利用gather_log_probs() 函数,只保存目标token的logit值,得到两个 B * L 的矩阵
RLHF的第二个环节:修正reward
前面提到,我们不能让 actor_model 偏离 reference_model 太远,因此我们要给rewards矩阵添加一个惩罚项,compute_rewards() 函数的返回是:每个token修正后的rewards:
- 最后一个token的计算方法是 Reward_score + KL_penalty
- 前面的所有的token 的计算方法是 0 + KL_penalty (除了最后一个token,前置token的reward初始值都是0,但是要加上惩罚项)
结合代码看的时候,要始终记住这个变换:
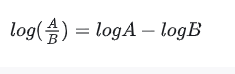
RLHF的第三个环节:计算优势函数和Q函数
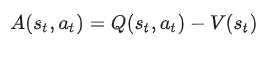
我们再看一下这个公式:
优势函数(Advantage Function)在强化学习中是一个非常关键的概念,通常用于评估在特定状态下采取某个动作比遵循当前策略(Policy)更好或更差的程度。优势函数的主要用途是优化策略,帮助模型明确地了解哪些动作(哪个Token)在当前状态(已生成的token)下是有利的。
get_advantages_and_returns() 函数根据第二个环节修正后的 rewards 和 values 计算优势函数,有两个返回值:
- advantages矩阵
- returns矩阵,等价于 advantages + values,也就是Q函数
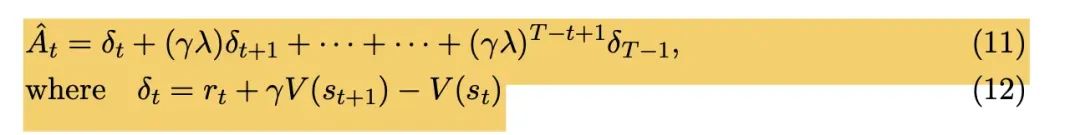
PPO论文中Advantage函数的计算公式
RLHF的第四个环节:更新Actor模型
利用最新的actor模型,重新估算一遍语言模型目标token的logits,然后利用advantages矩阵进行loss计算:
- 输入是新的actor模型的语言模型logits,旧的actor模型的语言模型logits,advantages矩阵
- 在clip_loss,和原始loss之间,选择一个最小的loss进行返回
重要性采样
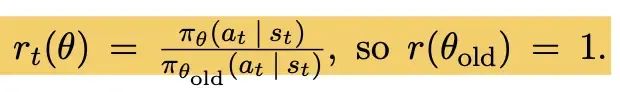
PPO论文中Actor模型loss
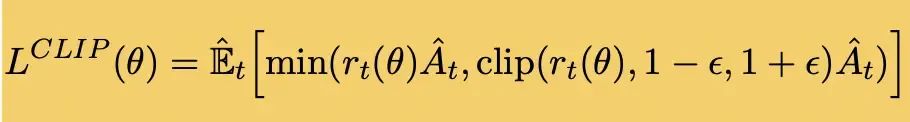
注意上文的一句话,“利用最新的actor模型”,这里涉及到一个重要的概念:重要性采样!
简单来说,我们的 Actor_model 只要训了一条语料,就会变成一个新的模型,那也就是说:我们在第一个环节所构造的语料都无法使用了,因为现在的 actor_model 已经无法生成出之前的answer。
重要性采样的变换公式:
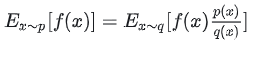
因此,我们是在用另外一个模型的模拟轨迹,来优化我们当前的模型。利用上述公式,我们可以完整这样的近似转化操作,这就是重要性采样的简单理解。
这里不懂也无所谓,就当是引入了一个新的系数来修正 reward 即可。log_ratio = (logprobs - old_logprobs) * mask 这一行代码对应着重要性采样的修正实现。
RLHF的第五个环节:更新Critic模型
同理,利用最新的critic模型,重新估算一遍Q矩阵,然后利用returns矩阵(其实就是真实的Q矩阵)进行loss计算:
- 输入是新的critic模型计算的Q矩阵,旧的critic模型计算的Q矩阵,returns矩阵
- 在clip_loss,和原始loss之间,选择一个最小的loss进行返回

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









