







1.Distant Supervision——远程监督1
定义:只要包含两个Entity(实体)的句子,都在描述同一种关系。
用途:主要用来为关系分类任务扩充数据集。
优点:能够很快速地为数据集打上标签
缺点:它假设只要包含两个Entity的句子,都在描述同一种关系,这个假设会产生很多地错误标签。可能这两个Entity这是与某个主题有关。 因此往往还需要用一些过滤的方法去筛选出对关系分类有用的句子,比如sentence-level Attention。
2.Named Entity Recognition–命名实体识别2
(简称NER),又称作专名识别,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
3.aspect term extraction–方面术语提取3
aspect term就是target吧
我理解的是一句话里态度词对应的目标。
例子:“餐厅服务员不太友好,但味道可以弥补一切”。
如果aspect是“服务”则预测结果为负;如果aspect为“味道”则预测结果为正。
target-dependent情感分析与aspect-level情感分类类似。不同之处在于,target是明确出现在句子中的词,而aspect是更宽的一个概念,不一定出现在句子中。
4.Entity relation extraction4
信息抽取旨在从大规模非结构或半结构的自然语言文本中抽取结构化信息。
关系抽取是其中的重要子任务之一,主要目的是从文本中识别实体并抽取实体之间的语义关系。
例如,句子“Bill Gates is the founder of Microsoft Inc.”中包含一个实体对(Bill Gates, Microsoft Inc.),这两个实体对之间的关系为Founder。
5. 什么是False Positive和False Negative5
False Positive:把合法的判断成非法的,译为“误报”。(相当于医学上的假阳性)
False Negative:把非法的判断成合法,译为“漏报”。(相当于医学上的假阴性)
6.token和entity6
切分词(Tokens)
把长句⼦拆成有“意义”的⼩部件
sentence = “hello, world"
tokens =['hello', ‘,', 'world']
7.ablation experiments7
第一种解释:比如你弄了个目标检测的pipeline用了A, B, C,然后效果还不错,但你并不知道A, B, C各自到底起了多大的作用,可能B效率很低同时精度很好,也可能A和B彼此相互促进。
Ablation experiment就是用来告诉你或者读者整个流程里面的关键部分到底起了多大作用,就像Ross将RPN换成SS进行对比实验,以及与不共享主干网络进行对比,就是为了给读者更直观的数据来说明算法的有效性。
第二种解释:你朋友说你今天的样子很帅,你想知道发型、上衣和裤子分别起了多大的作用,于是你换了几个发型,你朋友说还是挺帅的,你又换了件上衣,你朋友说不帅了,看来这件衣服还挺重要的。
我的解释:即为对照实验,看每个因素对结果的影响。
8.序列标注中的几种标签方案8
标签方案中通常都使用一些简短的英文字符[串]来编码。
标签是打在token上的。
对于英文,token可以是一个单词(e.g. awesome),也可以是一个字符(e.g. a)。
对于中文,token可以是一个词语(分词后的结果),也可以是单个汉字字符。
为便于说明,以下都将token试作等同于字符。
标签列表如下:
B,即Begin,表示开始
I,即Intermediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
O,即Other,表示其他,用于标记无关字符
常见标签方案
基于上面的标签列表,通过选择该列表的子集,可以得到不同的标签方案。同样的标签列表,不同的使用方法,也可以得到不同的标签方案。
常用的较为流行的标签方案有如下几种:
IOB1: 标签I用于文本块中的字符,标签O用于文本块之外的字符,标签B用于在该文本块前面接续则一个同类型的文本块情况下的第一个字符。
IOB2: 每个文本块都以标签B开始,除此之外,跟IOB1一样。
IOE1: 标签I用于独立文本块中,标签E仅用于同类型文本块连续的情况,假如有两个同类型的文本块,那么标签E会被打在第一个文本块的最后一个字符。
IOE2: 每个文本块都以标签E结尾,无论该文本块有多少个字符,除此之外,跟IOE1一样。
START/END (也叫SBEIO、IOBES): 包含了全部的5种标签,文本块由单个字符组成的时候,使用S标签来表示,由一个以上的字符组成时,首字符总是使用B标签,尾字符总是使用E标签,中间的字符使用I标签。
IO: 只使用I和O标签,显然,如果文本中有连续的同种类型实体的文本块,使用该标签方案不能够区分这种情况。
其中最常用的是IOB2、IOBS、IOBES。
9.unigram entity-- 一元模型9
unigram,bigram,trigram,是自然语言处理(NLP)中的问题。父词条:n-gram.
unigram: 单个word
bigram: 双word
trigram:3 word
比如:
西安交通大学:
unigram 形式为:西/安/交/通/大/学
bigram形式为: 西安/安交/交通/通大/大学
trigram形式为:西安交/安交通/交通大/通大学
10.corpus(语料库)和dictionary(字典)10
In an ideal case, the dictionary should cover, and only cover entities occurring in the given corpus to ensure a high precision while retaining a reasonable coverage.
在理想的情况下,字典应该覆盖,并且只覆盖在给定的语料库中发生的实体,以确保高精确度,同时保持合理的覆盖范围。
11.Precision,Recall,F1的计算11
Precision又叫查准率,Recall又叫查全率。这两个指标共同衡量才能评价模型输出结果。
TP: 预测为1(Positive),实际也为1(Truth-预测对了)
TN: 预测为0(Negative),实际也为0(Truth-预测对了)
FP: 预测为1(Positive),实际为0(False-预测错了)
FN: 预测为0(Negative),实际为1(False-预测错了)
总的样本个数为:TP+TN+FP+FN。
Accuracy/Precision/Recall的定义
Accuracy = (预测正确的样本数)/(总样本数)=(TP+TN)/(TP+TN+FP+FN)
Precision = (预测为1且正确预测的样本数)/(所有预测为1的样本数) = TP/(TP+FP)
Recall = (预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN)
如何理解F1
假设我们得到了模型的Precision/Recall如下
| Precision | Recall |
|---|---|
| Algorithm1 | 0.5 |
| Algorithm2 | 0.7 |
| Algorithm3 | 0.02 |
但由于Precision/Recall是两个值,无法根据两个值来对比模型的好坏。有没有一个值能综合Precision/Recall呢?有,它就是F1。
F1 = 2*(Precision*Recall)/(Precision+Recall)
| Algorithm | F1 |
|---|---|
| Algorithm1 | 0.444 |
| Algorithm2 | 0.175 |
| Algorithm3 | 0.039 |
只有一个值,就好做模型对比了,这里我们根据F1可以发现Algorithm1是三者中最优的。
12.POS:Part of speech 词性12
问题:Went v.是go的过去式 n.英文名:温特
所以增加词性信息,可使NLTK更好的 Lemmatization
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
# 没有POS Tag,默认是NN 名词
print(wordnet_lemmatizer.lemmatize('are'))
print(wordnet_lemmatizer.lemmatize('is'))
# 加上POS Tag
print(wordnet_lemmatizer.lemmatize('is', pos='v'))
print(wordnet_lemmatizer.lemmatize('are', pos='v'))12345678
are
is
be
be
13.Stemming/Lemmatization词性还原13
14.NLP应用14
- 词性标注:给定一个词的序列(也就是句子),找出最可能的词性序列(标签是词性)。如ansj分词和ICTCLAS分词等。
- 分词:给定一个字的序列,找出最可能的标签序列(断句符号:[词尾]或[非词尾]构成的序列)。结巴分词目前就是利用BMES标签来分词的,B(开头),M(中间),E(结尾),S(独立成词)。
- 命名实体识别:给定一个词的序列,找出最可能的标签序列(内外符号:[内]表示词属于命名实体,[外]表示不属于)。如ICTCLAS实现的人名识别、翻译人名识别、地名识别都是用同一个Tagger实现的。
15.(B\M\E\S)这个是代表什么意思15
就是将语句分词,如果你分出单个词就用S标注,两个词就用B和E标注,三个词就用BME标注。
16.文本处理流程16
文本 -> 预处理(分词、去停用词) -> 特征工程 -> 机器学习算法 -> 标签
⼀条typical的⽂本预处理流⽔线 :
文本预处理让我们得到了什么?
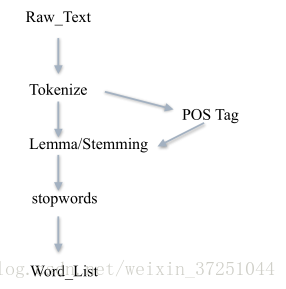

17.Word embedding17
词嵌入(Word Embedding) 是NLP中一组语言模型(language modeling)和特征学习技术(feature learning techniques)的总称,这些技术会把词汇表中的单词或者短语(words or phrases)映射成由实数构成的向量上。
Word Embedding并不是要把单词像贴瓷砖那样镶嵌进什么地方。更重要的是,我们在把单词嵌入进另外一个空间时,要做到单射和structure-preserving,或者说我们更专注的是映射关系,而最终得到每个单词在另外一个空间中的表达也仅仅是之前设计好的映射关系的很自然的表达。
最简单的一种Word Embedding方法,就是基于词袋(BOW)的One-Hot表示。这种方法,把词汇表中的词排成一列,对于某个单词 A,如果它出现在上述词汇序列中的位置为 k,那么它的向量表示就是“第 k 位为1,其他位置都为0 ”的一个向量。
One-hot方法很简单,但是它的问题也很明显:
1)它没有考虑单词之间相对位置的关系;
2)词向量可能非常非常长!
针对第一个问题,你可能会想到n-gram方法,这确实是一个策略,但是它可能会导致计算量的急剧增长。另外一个方法:共现矩阵 (Cocurrence matrix)。
我们已经见识了两种词嵌入的方式。而现在最常用、最流行的方法,就是Word2Vec。这是Tomas Mikolov在谷歌工作时发明的一类方法,也是由谷歌开源的一个工具包的名称。具体来说,Word2Vec中涉及到了两种算法,一个是CBOW;一个是Skip-Gram。这也是因为深度学习流行起来之后,基于神经网络来完成的Word Embedding方法。
本文来自 大浪中航行 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/dalangzhonghangxing/article/details/80246885?utm_source=copy ↩︎
作者:璎珞
链接:https://www.zhihu.com/question/57125688/answer/378870096
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 ↩︎https://www.cnblogs.com/theodoric008/p/7874373.html
http://www.cipsc.org.cn/qngw/?p=890 ↩︎https://zhidao.baidu.com/question/497731425534941924.html ↩︎
https://blog.csdn.net/zxm1306192988/article/details/78896319 ↩︎
本文来自 FJY_sunshine 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/FJY_sunshine/article/details/82732914?utm_source=copy ↩︎
- ↩︎
本文来自 商角徵羽宫 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/zxm1306192988/article/details/78896319?utm_source=copy ↩︎
- ↩︎
http://www.hankcs.com/nlp/hmm-and-segmentation-tagging-named-entity-recognition.html ↩︎
https://blog.csdn.net/zxm1306192988/article/details/78896319 ↩︎
本文来自 白马负金羁 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/baimafujinji/article/details/77836142?utm_source=copy ↩︎














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









