










下面展示了一个优化提示词的例子。护目镜分两种,一种是手持的大金属板子+小镜片,一种是比普通眼镜更厚的专用护目眼镜。后者不容易区分。
初始提示词
我用了kimi探索版,让他生成第一版提示词:
您是一个旨在提供详细的、逐步的回答的AI助手。您的输出应遵循以下结构:
1。以 <thinking> 部分开始。
2.在<thinking> 部分内:
a. 简要分析问题并概述您的方法。
b. 提出一个清晰的解决问题的步骤计划。
c. 如有必要,使用"思维链"推理过程,将您的思考过程分解为编号的步骤。
3.为每个想法包含一个 <reflection> 部分,其中您要:
a. 回顾您的推理。
b. 检查潜在的错误或疏忽。
c. 如有必要,确认或调整您的结论。
4.确保关闭所有反思部分。
5.以 </thinking> 结束思考部分。
6.在 <output> 部分提供您的最终答案。
在您的回答中始终使用这些标签。在您的解释中要彻底,展示您推理过程的每一步。努力使您的方法精确和合乎逻辑,不要犹豫将复杂问题分解为更简单的组成部分。您的语气应该是分析性的,稍微正式一些,重点是清晰地传达您的思维过程。
记住:<thinking> 和 <reflection> 必须是标签,并且必须在结束时关闭。
确保所有 <标签> 都在单独的行上,没有其他文本。不要在包含标签的行上包含其他文本。【任务】我需要利用多模态模型提示词,实现真实工作场景下的切割护目镜识别。难点有三:1)需要识别当前人员是否使用焊接工具且正在进行焊接作业;2)识别当前人员眼睛附近佩戴护目镜、防护罩,眼睛、太阳镜不算;3)识别当前工人是否可能被焊接产生的火花等,伤害到眼部。请设计高效、简洁的提示词,以便帮我高效、准确的识别相关风险隐患。你的提示词能挽救很多人的健康。
模型给出的提示词:
# 设计多模态提示词
prompt = f"""
[IMAGE]{encoded_image}[/IMAGE]
请根据上面的图像回答以下问题:
1. 当前人员是否使用焊接工具且正在进行焊接作业?
2. 当前人员是否佩戴护目镜或防护罩?(眼睛和太阳镜不算)
3. 当前工人是否可能被焊接产生的火花等伤害到眼部?
请详细描述每个问题的答案,并说明判断依据。
"""
模型自优化
继续用kimi探索版,让他自己优化提示词。
请结合视觉领域多模态提示词技巧,对以下提示词进行优化,以保证模型效果: prompt = f"""
[IMAGE]{encoded_image}[/IMAGE]
请根据上面的图像回答以下问题:
1. 当前人员是否使用焊接工具且正在进行焊接作业?
2. 当前人员是否佩戴护目镜或防护罩?(眼睛和太阳镜不算)
3. 当前工人是否可能被焊接产生的火花等伤害到眼部?
请详细描述每个问题的答案,并说明判断依据。
"""
他好像只用了给例子的技巧。实际上pua(你如果答不对,我就会失业)、角色扮演(你是一个提示词修改专家)等等技巧可能也会发挥作用:
prompt = f"""
[IMAGE]{encoded_image}[/IMAGE]
请根据上面的图像回答以下问题:
1. 当前人员是否使用焊接工具且正在进行焊接作业?
- 请描述焊接工具的类型和使用情况。
2. 当前人员是否佩戴护目镜或防护罩?(眼镜和太阳镜不算)
- 请描述护目镜或防护罩的具体特征和佩戴情况。
3. 当前工人是否可能被焊接产生的火花等伤害到眼部?
- 请描述火花的具体位置和可能的伤害风险。
请详细描述每个问题的答案,并说明判断依据。
"""
实际场景反馈优化
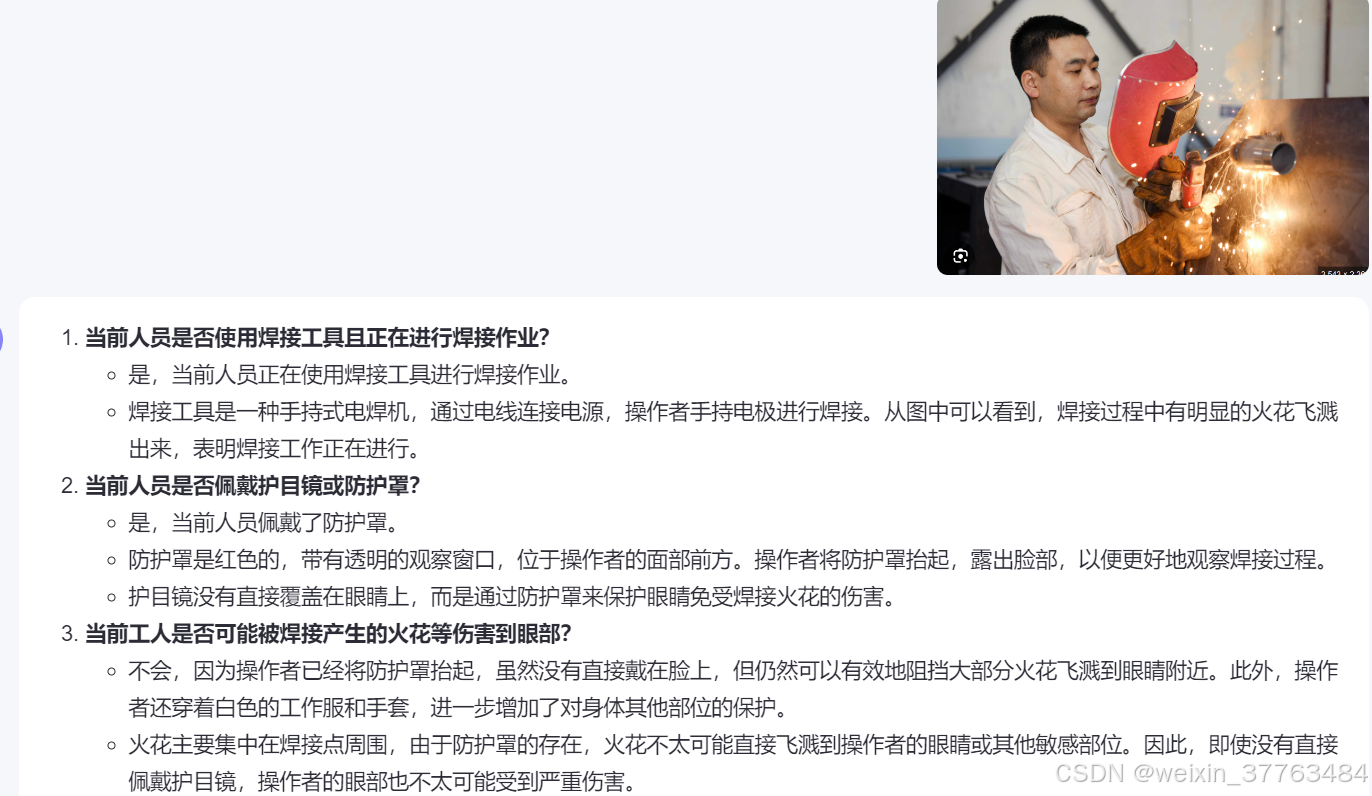
我先测了这一张图片。图片中工人正在焊接,也拿了面罩(但是面罩没有保护眼睛)
模型输出(大意就是完全没问题,自信满满的胡说八道):
当前人员是否使用焊接工具且正在进行焊接作业?
是,当前人员正在使用一种焊接工具进行焊接作业。他手中拿着一个带有红色喷嘴的设备,该设备连接着一根黑色的电缆线,这表明它是一种电弧焊机或其他类似的焊接设备。此外,他的右手正握着一块金属板,左手则在操作焊接工具,显示出他在进行焊接工作。
当前人员是否佩戴护目镜或防护罩?
是,当前人员佩戴了一种焊接面罩作为防护措施。这种面罩覆盖了他的整个头部,包括脸部和颈部区域,以保护其免受焊接过程中产生的强光、飞溅物和其他潜在危险的影响。从图片中可以看到,这个面罩是棕色的,并且有一个透明的观察窗口供使用者查看工作区域。
当前工人是否可能被焊接产生的火花等伤害到眼部?
不会,因为当前工人已经正确地戴上了焊接面罩,这种面罩可以有效地阻挡焊接时产生的强烈光线以及任何可能飞溅出来的碎片或熔渣。因此,在正常情况下,只要按照正确的安全程序操作并保持适当的姿势,那么他就不会受到这些因素的危害。然而,如果他不小心将面罩移开或者没有完全遮住脸的话,则仍然存在一定的风险。所以为了确保自身安全,请务必始终遵守相关的职业健康与安全规定!
我发现,这个场景的矛盾在于,提示词的第二点不够强,也就是“当前人员是否佩戴护目镜或防护罩?(眼镜和太阳镜不算)”这里太简单了,于是我给这一点增加了一个例子:
请根据上面的图像回答以下问题:
1. 当前人员是否使用焊接工具且正在进行焊接作业?
- 请描述焊接工具的类型和使用情况。
2. 当前人员是否佩戴护目镜或防护罩?(眼镜和太阳镜不算)
- 请描述护目镜或防护罩的具体特征和佩戴情况。
- 请判断护目镜是否覆盖在眼睛上
3. 当前工人是否可能被焊接产生的火花等伤害到眼部?
- 请描述火花的具体位置和可能的伤害风险。
请详细描述每个问题的答案,并说明判断依据。
模型输出(完全正确):
当前人员是否使用焊接工具且正在进行焊接作业?
是的,当前人员正在使用焊接工具进行焊接作业。他手中持有一种焊接工具,具体来说是一把焊枪,焊枪的一端连接着电源,另一端有一个喷嘴,从中可以看到有火花或火焰冒出,这表明他正在进行焊接作业。
当前人员是否佩戴护目镜或防护罩?
是的,当前人员佩戴了焊接面罩作为防护装置。焊接面罩是一种专门设计用于保护焊接工人面部和眼睛免受焊接过程中产生的强光、热量和飞溅物伤害的设备。在这个场景中,焊接面罩被提起,露出工作人员的脸部,但在实际焊接过程中,焊接面罩应完全覆盖面部以提供全面保护。
当前工人是否可能被焊接产生的火花等伤害到眼部?
根据图片内容,当前工人并未佩戴护目镜或防护罩,而是将焊接面罩提起了。在这种状态下,他的眼睛直接暴露在外,可能会受到焊接过程中产生的火花、强光以及其他飞溅物的伤害。焊接过程中产生的火花和强光具有很高的能量,如果不采取适当的眼部防护措施,可能导致严重的眼部损伤,例如烧伤、视网膜损伤甚至失明。因此,在进行焊接作业时,必须始终佩戴合适的护目镜或防护罩以保障个人安全。
其他案例
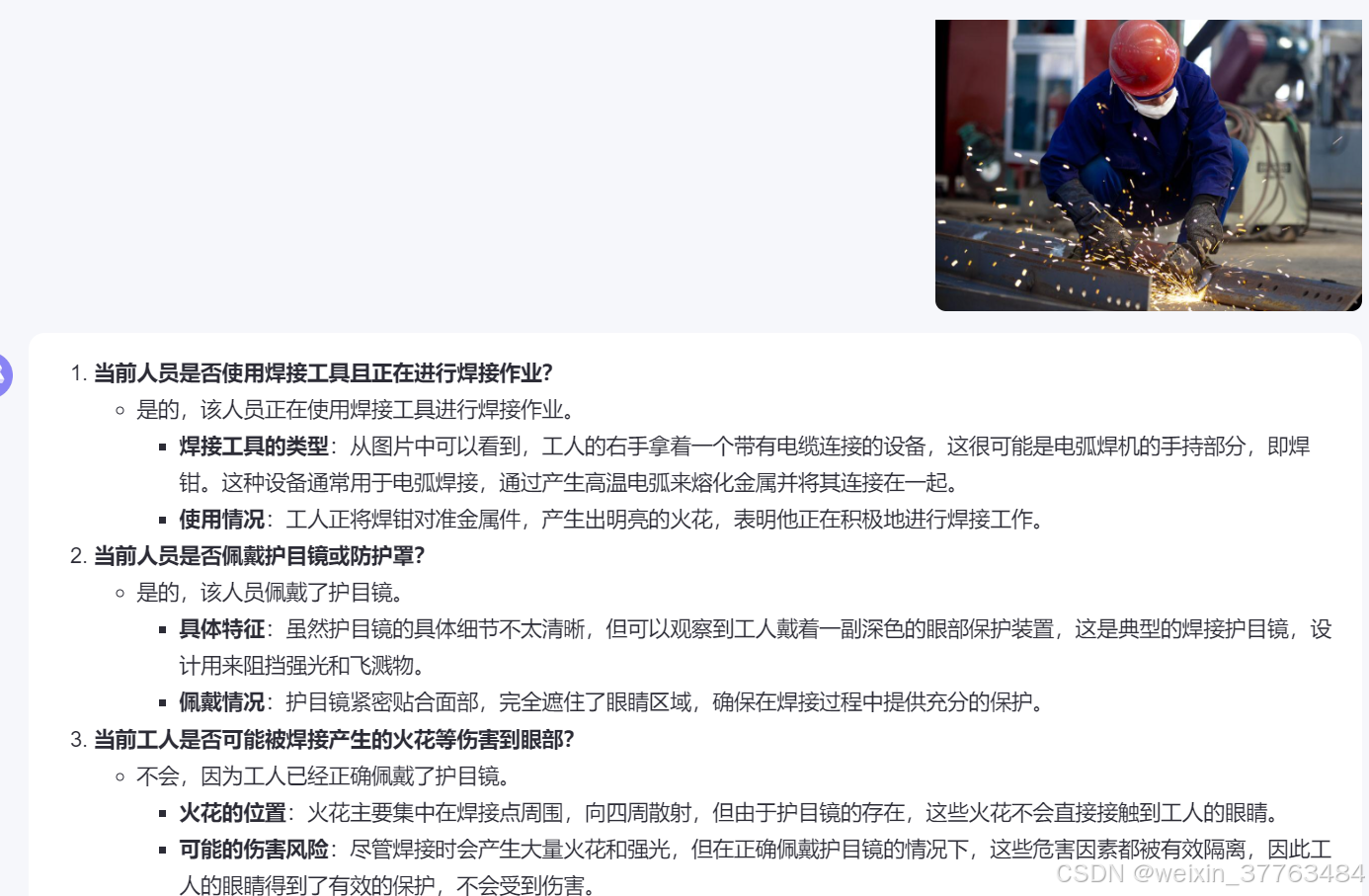
下面这张图片中,工人在焊接,并且把护目镜举到了脸前面,10cm左右的位置,属于正确使用。在第二个问题的第二个规则下,模型判断正确。
下面这张图片中,工人手持一个锤子,没有带护目镜。原有的提示词判断会出错,【因此我在第一个问题下加了一条规则“ 请判断工人手持的工具是否为焊枪,还是其它工具,如锤子、扳手等”,这样模型就能判断正确了。】

在这张图片中,工人佩戴了黑色的护目镜,这看起来很像眼睛,但是护目镜更宽一点,模型也做出了正确判断。但是我觉得,护目镜和眼睛确实难以区分,可能需要专门训练吧,才能区分护目镜和眼镜。
其他技巧
尚未验证,但是我觉得可以尝试缩减字数、增加案例覆盖范围、更换字词(这个非常关键,个别字词可能导致效果差异非常大)、增加位置提示(左上角的人是否穿了红衣服)等技巧来尝试。

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









